Forethought[1] is a new AI macrostrategy research group cofounded by Max Dalton, Will MacAskill, Tom Davidson, and Amrit Sidhu-Brar.
We are trying to figure out how to navigate the (potentially rapid) transition to a world with superintelligent AI systems. We aim to tackle the most important questions we can find, unrestricted by the current Overton window.
More details on our website.
Why we exist
We think that AGI might come soon (say, modal timelines to mostly-automated AI R&D in the next 2-8 years), and might significantly accelerate technological progress, leading to many different challenges. We don’t yet have a good understanding of what this change might look like or how to navigate it. Society is not prepared.
Moreover, we want the world to not just avoid catastrophe: we want to reach a really great future. We think about what this might be like (incorporating moral uncertainty), and what we can do, now, to build towards a good future.
Like all projects, this started out with a plethora of Google docs. We ran a series of seminars to explore the ideas further, and that cascaded into an organization.
This area of work feels to us like the early days of EA: we’re exploring unusual, neglected ideas, and finding research progress surprisingly tractable. And while we start out with (literally) galaxy-brained schemes, they often ground out into fairly specific and concrete ideas about what should happen next. Of course, we’re bringing principles like scope sensitivity, impartiality, etc to our thinking, and we think that these issues urgently need more morally dedicated and thoughtful people working on them.
Research
Research agendas
We are currently pursuing the following perspectives:
* Preparing for the intelligence explosion: If AI drives explosive growth there will be an enormous number of challenges we have to face. In addition to misalignment risk and biorisk, this potentially includes: how to govern the development of new weapons of mass destr
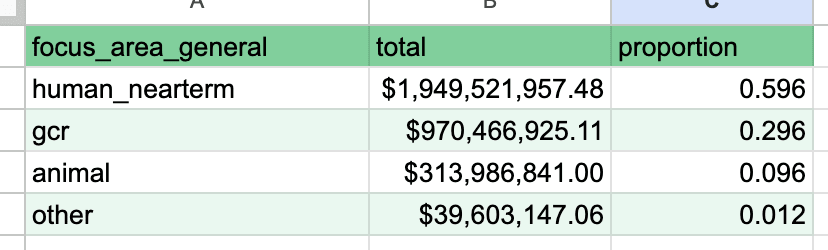
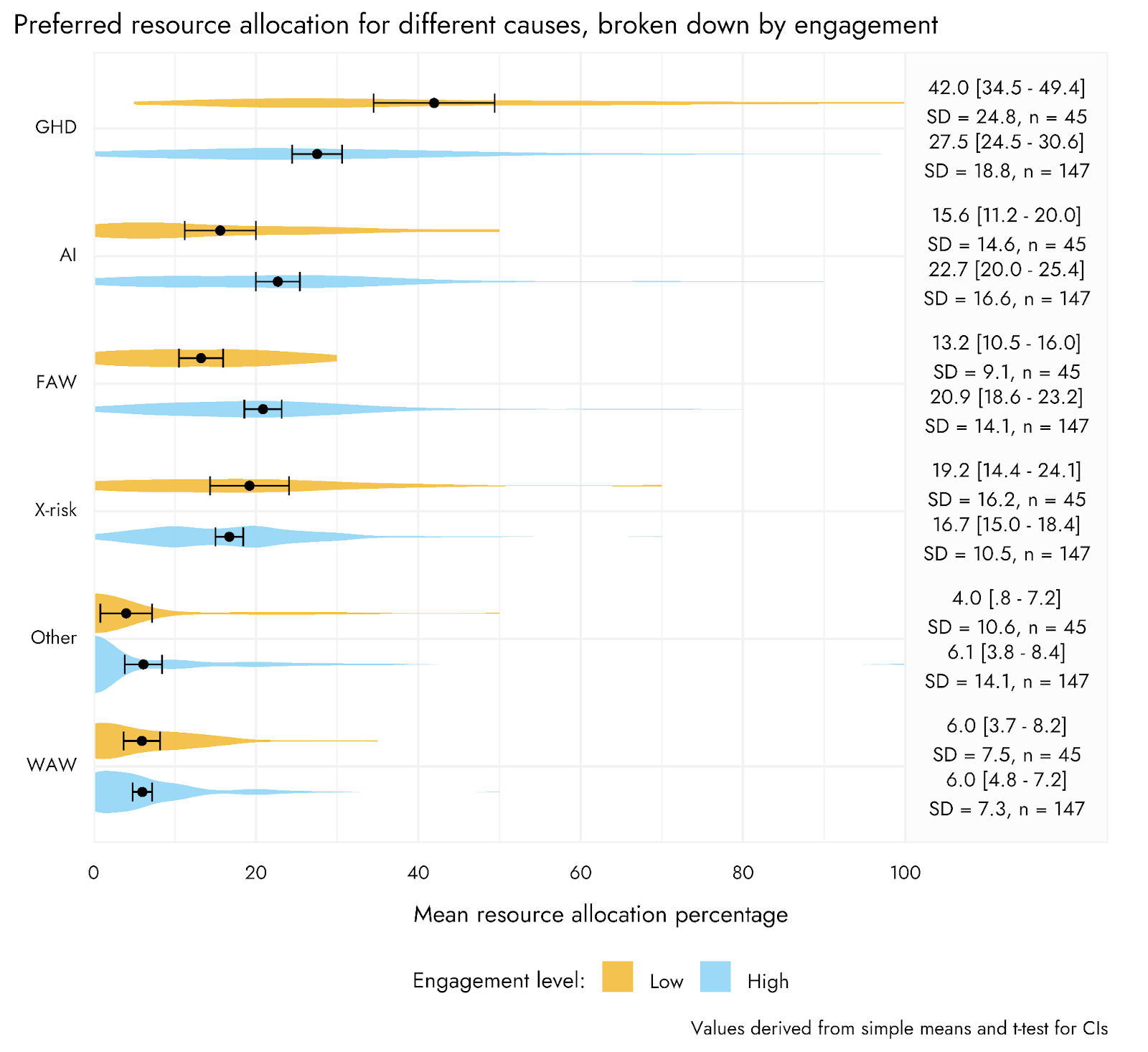
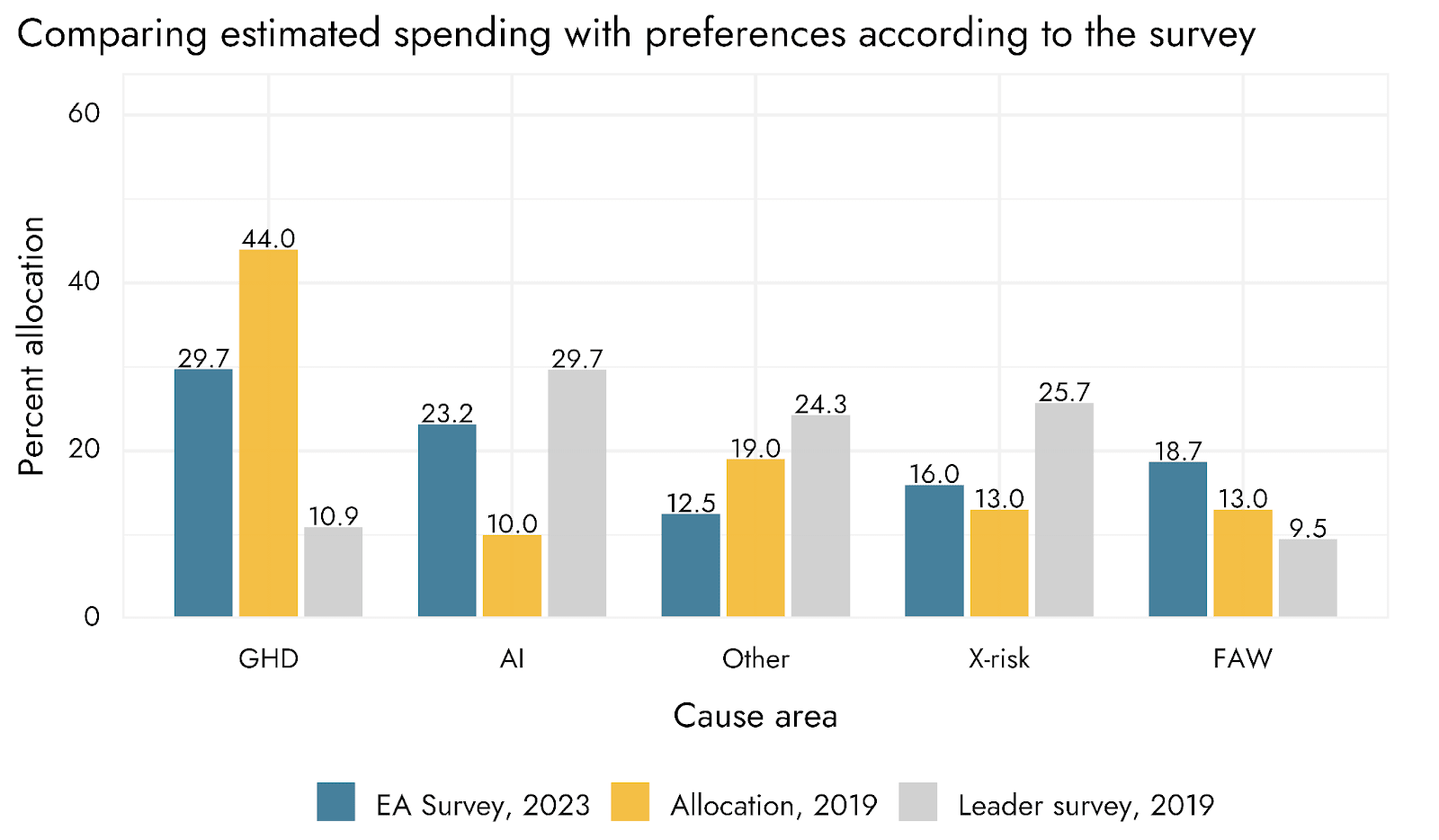


A few theses that may turn into a proper post:
1. Marginal animal welfare cost effectiveness seems to robustly beat global health interventions. It may look more like 5x or 1000x but it is very hard indeed to get that number below 1 (I do think both are probably in fact good ex ante at least, so think the number is positive).
To quote myself from this comment:
2. The difference in magnitude of cost effectiveness (under any plausible understanding of what that means) between MakeAWish (or personal consumption spending for that matter) and AMF is smaller than between AMF (or pick your favorite) and The Humane League or AWF.
So it is more important to convince someone to give to e.g. the EA animal welfare fund if they were previously giving to AMF than to convince a non-donor to give that same amount of money to AMF.
At least to me, this seems counterintuitive, contrary to vibes and social/signaling effects, and also robustly true.
3. What people intuitively think of as the "certainty" that comes along with AMF et al doesn't really exist. To quote my own tweet:
4. The tractability of the two cause areas is similar...
5. But animal welfare receives way less funding. From the same comment as above:
Bees feel like an easy case for thinking RP might be wildly wrong in a way that doesn't generalise to all animal interventions, since bees might not be conscious at all, whereas it's much less likely that pigs or even chickens aren't. (I'm actually a bit more sympathetic to pigs not being conscious than most people are, but I still think its >50% likely that they are conscious enough to count as moral patients.)