Key Takeaways
- The evidence that animal welfare dominates in neartermism is strong.
- Open Philanthropy (OP) should scale up its animal welfare allocation over several years to approach a majority of OP's neartermist grantmaking.
- If OP disagrees, they should practice reasoning transparency by clarifying their views:
- How much weight does OP's theory of welfare place on pleasure and pain, as opposed to nonhedonic goods?
- Precisely how much more does OP value one unit of a human's welfare than one unit of another animal's welfare, just because the former is a human? How does OP derive this tradeoff?
- How would OP's views have to change for OP to prioritize animal welfare in neartermism?
Summary
- Rethink Priorities (RP)'s moral weight research endorses the claim that the best animal welfare interventions are orders of magnitude (1000x) more cost-effective than the best neartermist alternatives.
- Avoiding this conclusion seems very difficult:
- Rejecting hedonism (the view that only pleasure and pain have moral value) is not enough, because even if pleasure and pain are only 1% of what's important, the conclusion still goes through.
- Rejecting unitarianism (the view that the moral value of a being's welfare is independent of the being's species) is not enough. Even if just for being human, one accords one unit of human welfare 100x the value of one unit of another animal's welfare, the conclusion still goes through.
- Skepticism of formal philosophy is not enough, because the argument for animal welfare dominance can be made without invoking formal philosophy. By analogy, although formal philosophical arguments can be made for longtermism, they're not required for longtermist cause prioritization.
- Even if OP accepts RP's conclusion, they may have other reasons why they don't allocate most neartermist funding to animal welfare.
- Though some of OP's possible reasons may be fair, if anything, they'd seem to imply a relaxation of this essay's conclusion rather than a dismissal.
- It seems like these reasons would also broadly apply to AI x-risk within longtermism. However, OP didn't seem put off by these reasons when they allocated a majority of longtermist funding to AI x-risk in 2017, 2019, and 2021.[1]
- I request that OP clarify their views on whether or not animal welfare dominates in neartermism.
Thanks to Michael St. Jules for his comments.
The Evidence Endorses Prioritizing Animal Welfare in Neartermism
GiveWell estimates that its top charity (Against Malaria Foundation) can prevent the loss of one year of life for every $100 or so.
We’ve estimated that corporate campaigns can spare over 200 hens from cage confinement for each dollar spent. If we roughly imagine that each hen gains two years of 25%-improved life, this is equivalent to one hen-life-year for every $0.01 spent.
If you value chicken life-years equally to human life-years, this implies that corporate campaigns do about 10,000x as much good per dollar as top charities. … If one values humans 10-100x as much, this still implies that corporate campaigns are a far better use of funds (100-1,000x).
Holden Karnofsky, "Worldview Diversification" (2016)
"Worldview Diversification" (2016) describes OP's approach to cause prioritization. At the time, OP's research found that if the interests of animals are "at least 1-10% as important" as those of humans, then "animal welfare looks like an extraordinarily outstanding cause, potentially to the point of dominating other options".[2] After the better part of a decade, the latest and most rigorous research funded by OP has endorsed a stronger claim: Any significant moral weight for animals implies that OP should prioritize animal welfare in neartermism. This sentence is operationalized in the paragraphs that follow.
In 2021, OP granted $315,500 to RP for moral weight research, which "may help us compare future opportunities within farm animal welfare, prioritize across causes, and update our assumptions informing our worldview diversification work" [emphasis mine].[3] RP assembled an interdisciplinary team of experts in philosophy, comparative psychology, animal welfare science, entomology, and veterinary research to review the literature's latest evidence.[4] RP's moral weights and analysis of cage-free campaigns suggest that the average cost-effectiveness of cage-free campaigns is on the order of 1000x that of GiveWell's top charities.[5] Even if the campaigns' marginal cost-effectiveness is 10x worse than the average, that would be 100x.
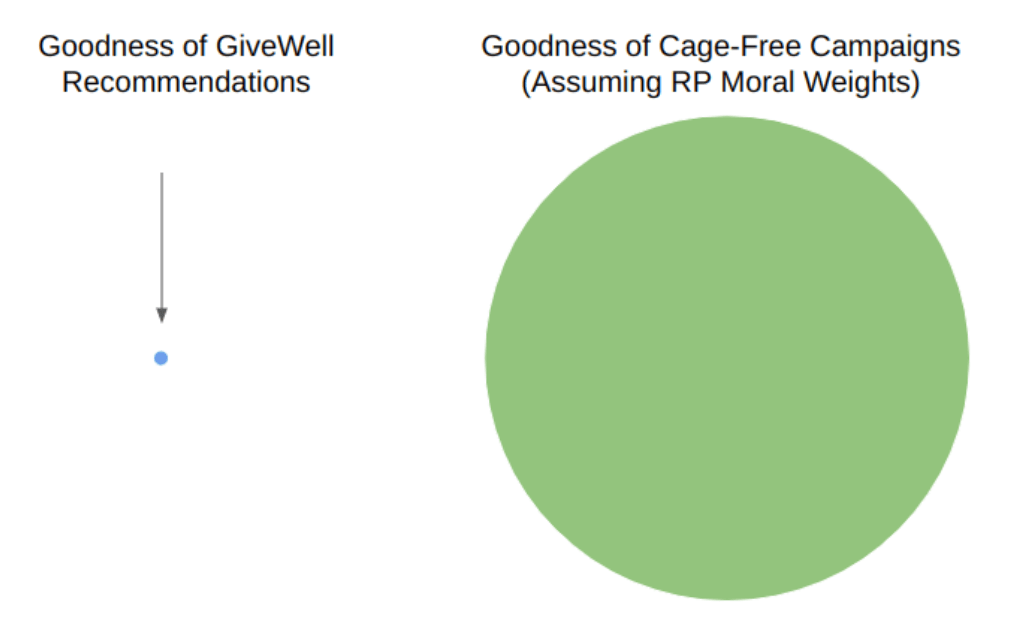
In 2019, the mean EA leader endorsed allocating a majority of neartermist resources over the next 5 years to animal welfare.[6] Given the strength of the evidence that animal welfare dominates in neartermism by orders of magnitude, this allocation seems sensible for OP. In actuality, OP has allocated an average of 17% of its neartermist funding to animal welfare each year, with 83% going to other neartermist causes.[7] Since OP funded RP's moral weight research specifically in order to "prioritize across causes, and update our assumptions informing our worldview diversification work", one might have expected OP to update their allocations in response to RP's evidence. However, OP's plans for 2023 give no indication that this will happen.
The EA movement currently spends more on global health than on animal welfare and AI risk combined. It clearly isn't even following near-termist ideas to their logical conclusion, let alone long-termist ones.
If you didn't want animals to dominate, maybe you shouldn't have been a utilitarian! … When people want to put the blame on these welfare range estimates, I think that's just not taking seriously your own moral commitments.
Bob Fischer, EAG Bay Area 2023
Objections
Animal Welfare Does Not Dominate in Neartermism
OP may reject that animal welfare dominates in neartermism. If so, I'm unaware of any public clarification of OP's beliefs on the topic. In the following sections, I attempt to deduce what views OP may hold in order for animal welfare to not dominate in neartermism, and show that such views would be highly peculiar and dubious. If OP doesn't think animal welfare dominates, I ask them to publicly clarify their views, so that they can be constructively engaged with.
RP's Project Assumptions are Incorrect
If OP rejects RP's conclusions, they must reject some combination of RP's project assumptions: utilitarianism, valence symmetry, hedonism, and unitarianism. I don't think OP rejects utilitarianism or valence symmetry, so the following will focus upon OP's possible objections to:
- Hedonism: The view that welfare derives only from happiness and suffering.
- Unitarianism: The view that the moral importance of welfare doesn't depend upon species membership.
Crucially, rejecting hedonism is not enough to avoid animal welfare dominating in neartermism. As Bob Fischer points out, "Even if hedonic goods and bads (i.e., pleasures and pains) aren't all of welfare, they’re a lot of it. So, probably, the choice of a theory of welfare will only have a modest (less than 10x [i.e. at least 10 % weight for hedonism]) impact on the differences we estimate between humans' and nonhumans' welfare ranges".[8] One would need to endorse an overwhelmingly non-hedonic theory, and/or an overwhelmingly hierarchical theory, such that the combined views discount three orders of magnitude of animal welfare impact. For example, OP could hold an overwhelmingly non-hedonic view where almost none (0.1%) of the human welfare range comes from pleasure and pain.
OP could also hold an overwhelmingly hierarchical view where just for being a human, one unit of a human's welfare is considered vastly (1000x) more important than the same amount of welfare in another animal. OP could also hold a combination of less-overwhelming versions of the two, such as 1% of human welfare coming from pleasure/pain and one unit of human welfare being 10x as important as one unit of animal welfare, so long as the combined views discount three orders of magnitude of animal welfare impact.
The following two sections will critique overwhelming non-hedonism and overwhelming hierarchicalism respectively. If the overwhelming views were significantly less overwhelming, my critique would be substantially the same. Therefore, I request that the reader consider the following critiques to also address whichever combination of less-overwhelming views OP may hold.
Endorsing Overwhelming Non-Hedonism
We [OP] think that most plausible arguments for hedonism end up being arguments for the dominance of farm animal welfare. … If we updated toward more weight on hedonism, we think the correct implication would be even more work on FAW, rather than work on human mental health.
Alexander has stated that "Hedonism doesn't seem very compelling to me".[9] Overwhelming non-hedonism, combined with the implicit premise that humans are vastly more capable of realizing non-hedonic goods than animals, may explain OP's neartermist cause prioritization: Enabling humans to realize non-hedonic goods may be better than reducing extreme suffering for orders of magnitude more animals.
The implicit premise seems non-obvious. It's plausible that both humans and other animals would have "not being tortured" pretty high in their preferences/objective list.
Even if the implicit premise is assumed, there's substantial empirical evidence that overwhelmingly non-hedonic theories are dubious:
- Extreme pain or discomfort reduces health-related quality of life by 41%.[10]
- Nerve damage results in a loss of health-related quality of life between 39% for diabetes-caused nerve damage and 85% for failed back surgery syndrome.[11]
- Suffering from cluster headaches is associated with greatly increased suicidality.[12]
- Patients suffering from chronic musculoskeletal pain would rather take a gamble with a ⅕ chance of dying and a ⅘ chance of being cured than continue living with their condition.[13]
Evidently, many people who experience severe suffering find it to outweigh many of the non-hedonic goods in life. If one endorses an overwhelmingly non-hedonic view, they’d have to argue persuasively that these people’s revealed preferences are deeply misguided.
Furthermore, if one accepts RP’s findings given hedonism but rejects prioritizing animals due to an overwhelmingly non-hedonic theory, they must endorse deeply unintuitive conclusions. To endorse human interventions over animal interventions, the human welfare range under the overwhelmingly non-hedonic view would have to be ~1000x the human welfare range under hedonism. Imagine a world with hundreds of people in extreme hedonic pain (e.g. drowning in lava) but one person with extreme non-hedonic good (e.g. love, knowledge, friendship). The overwhelming non-hedonist would consider this world net good.
An overwhelmingly non-hedonic view would also be out of step with much of the EA community. A poll of EAs found that most respondents would give up years of extreme good, whether from hedonic or non-hedonic sources, to avoid a day of extreme hedonic pain (drowning in lava). Nearly a third responded that "No amount of happiness could compensate".
I experienced "disabling"-level pain for a couple of hours, by choice and with the freedom to stop whenever I want. This was a horrible experience that made everything else seem to not matter at all.
A single laying hen experiences hundreds of hours of this level of pain during their lifespan, which lasts perhaps a year and a half - and there are as many laying hens alive at any one time as there are humans. How would I feel if every single human were experiencing hundreds of hours of disabling pain?
A single broiler chicken experiences fifty hours of this level of pain during their lifespan, which lasts 4-6 weeks. There are 69 billion broilers slaughtered each year. That is so many hours of pain that if you divided those hours among humanity, each human would experience about 400 hours (2.5 weeks) of disabling pain every year. Can you imagine if instead of getting, say, your regular fortnight vacation from work or study, you experienced disabling-level pain for a whole 2.5 weeks? And if every human on the planet - me, you, my friends and family and colleagues and the people living in every single country - had that same experience every year? How hard would I work in order to avert suffering that urgent?
Every single one of those chickens are experiencing pain as awful and all-consuming as I did for tens or hundreds of hours, without choice or the freedom to stop. They are also experiencing often minutes of 'excruciating'-level pain, which is an intensity that I literally cannot imagine. Billions upon billions of animals. The numbers would be even more immense if you consider farmed fish, or farmed shrimp, or farmed insects, or wild animals.
If there were a political regime or law responsible for this level of pain - which indeed there is - how hard would I work to overturn it? Surely that would tower well above my other priorities (equality, democracy, freedom, self-expression, and so on), which seem trivial and even borderline ridiculous in comparison.
Endorsing Overwhelming Hierarchicalism
I don't know whether or not OP endorses overwhelming hierarchicalism. However, after overwhelming hedonism, I think overwhelming hierarchicalism is the next most likely crux for OP's rejection of animal welfare dominating in neartermism.
Many properties of the human condition have been proposed as justifications for valuing one unit of human welfare vastly (1000x) more than one unit of another animal's welfare. For every property I know of that's been proposed, a case can be constructed where a person lacks that property, but we still have the intuition that we shouldn't care much less about them than we do about other people:
- Intelligence: The intelligence of human infants and adult chickens isn't very different, but we should care for infants.
- Capacity for future intelligence: Terminally ill children or people with severe mental disabilities may never be more intelligent than adult pigs, but we should care deeply for these people.
- Species membership: If we learned that Danish people were actually an offshoot of a hominid which wasn't homo sapiens, should we care for them 1000x less than we do other people?
- Capacity for creativity, or speech, or dignity, etc: If a person is uncreative, or mute, or undignified, are they worth 1000x less?
I personally feel much more empathy for humans than for chickens, and a benefit of believing in overwhelming hierarchicalism would be that I could prioritize helping humans over chickens. It might also make eating meat permissible, which would make life much easier. However, the losses would be real. I'd feel like I'm compromising on my epistemics by adding an arbitrary line to my moral system which lets me ignore a possible atrocity of immense scale. I'd be doing this for the sake of the warm fuzzies I'd feel from helping humans, and convenience in eating meat. That's untenable to a mind built the way mine is.
It's Strongly Intuitive that Helping Humans > Helping Chickens
I agree! But many also find it strongly intuitive that saving a child drowning in front of them is better than donating 10k to AMF, and that atrocities happening right now are more important than whatever may occur billions of years from now. In both of these cases, strong arguments to the contrary have persuaded many EAs to revise their intuitions.
If the latest and most rigorous research points to cage-free campaigns being 1000x as good as AMF, should a strong intuition to the contrary discount that by three orders of magnitude?
Skepticism of Formal Philosophy
Though this section has invoked formal philosophy for the purpose of rigor, formal philosophy isn't actually required to make the high-level argument for animal welfare dominating in neartermism:
- If you hurt a chicken, that probably hurts the chicken on the order of ⅓ as much as if you hurt a human similarly.
- Extreme suffering matters enough that reducing it can sometimes be prioritized over cultivating friendship, love, or other goods.
- Reducing an animal's suffering isn't overwhelmingly less important than reducing a human's suffering.
- Therefore, if one's $5000 can either (a) prevent serious suffering for 50,000 hens for 1 year[14] or (b) enable a single person to realize a lifetime of love and friendship, (a) seems orders of magnitude more cost-effective.
By analogy, one might be skeptical of many longtermists' use of formal philosophy to justify rejecting temporal discounting, rejecting person-affecting views, and accepting the repugnant conclusion. However, the high-level case for longtermism doesn't require formal philosophy: "I think the human race going extinct would be extra bad, even compared to many billions of deaths".
Even if Animal Welfare Dominates, it Still Shouldn't Receive a Majority of Neartermist Funding
Even if OP accepts that animal welfare dominates in neartermism, they may have other reasons for not allocating it a majority of neartermist funding.
Worldview Diversification Opposes Majority Allocations to Controversial Cause Areas
OP might state that on principle, worldview diversification shouldn’t allow a majority allocation to a controversial cause area. However, in 2017, 2019, and 2021, OP allocated a majority of longtermist funding to AI x-risk reduction.[15] While OP and I myself think AI x-risk is a major concern, thoughtful people within and outside the EA community disagree. Those who don’t think AI x-risk is a concern may consider nuclear war, pandemics, and/or climate change to be the most pressing x-risks.[16] Those who think AI x-risk is a concern often regard it as ~10x more pressing than other x-risks. In 2017, 2019, and 2021, OP judged that the 10x importance of AI x-risk reduction, under the controversial view that AI x-risk is a concern, was high enough to warrant a majority of longtermist funding.
Similarly, thoughtful people within and outside the EA community disagree on whether animals merit moral consideration. If animals do, then the most impactful animal welfare interventions are likely ~1000x as cost-effective as the most impactful alternatives. Just as controversy regarding whether AI x-risk is a concern should not preclude OP allocating AI x-risk a majority of longtermist funding, controversy regarding whether animals merit moral concern should not preclude allocating animal welfare a majority of neartermist funding.
OP is Already a Massive Animal Welfare Funder
OP is the world’s largest funder in many extremely important and neglected cause areas. However, this should not preclude OP updating its prioritization between those cause areas if given sufficient evidence. For example, if a shocking technological breakthrough shortened TAI forecasts to 2025, even though OP is already the world’s largest funder of AI x-risk reduction, OP would be justified in increasing its allocation to that cause area.
Animal Welfare has Faster Diminishing Marginal Returns than Global Health
I agree that if OP prematurely allocated a majority of neartermist funding to animal welfare, then the marginal cost-effectiveness of OP's animal welfare grants would drop substantially. Instead, I suggest that OP scale up animal welfare funding over several years to approach a majority of OP's neartermist grantmaking.
To absorb such funding, many ambitious animal welfare megaprojects have been proposed. Even if these megaprojects would be an order of magnitude less cost-effective than corporate chicken campaigns, I've argued above that they'd likely be far more cost-effective than the best neartermist alternatives.
Even so, it seems that OP's Farm Animal Welfare program may currently be able to allocate millions more without an order of magnitude decrease in cost-effectiveness:
Although tens of millions of dollars feels like a lot of money, when you compare it to the scope of the problem it quickly feels like not that much money at all, so we are having to make tradeoffs. Every dollar we give to one project is a dollar we can’t give to another project, and so unfortunately we do have to decline to fund projects that probably could do a lot of good for animals in the world.
Amanda Hungerford, Program Officer for Farm Animal Welfare for OP (8:12-8:34).
Increasing Animal Welfare Funding would Reduce OP’s Influence on Philanthropists
Over time, we aspire to become the go-to experts on impact-focused giving; to become powerful advocates for this broad idea; and to have an influence on the way many philanthropists make choices. Broadly speaking, we think our odds of doing this would fall greatly if we were all-in on animal-focused causes. We would essentially be tying the success of our broad vision for impact-focused philanthropy to a concentrated bet on animal causes (and their idiosyncrasies) in particular. And we’d be giving up many of the practical benefits we listed previously for a more diversified approach. Briefly recapped, these are: (a) being able to provide tangibly useful information to a large set of donors; (b) developing staff capacity to work in many causes in case our best-guess worldview changes over time; (c) using lessons learned in some causes to improve our work in others; (d) presenting an accurate public-facing picture of our values; and (e) increasing the degree to which, over the long run, our expected impact matches our actual impact (which could be beneficial for our own, and others’, ability to evaluate how we’re doing).
Though this is unfortunate, it makes sense, and Holden should be trusted here. That said, there’s a world of difference between being “all-in on animal-focused causes” and allocating a majority of OP’s neartermist funding to animal welfare, while continuing to fund many other important neartermist cause areas. It doesn’t seem to me that the latter proposal runs nearly as much risk of alienating philanthropists. Some evidence of this is that OP is the world’s largest funder of AI x-risk reduction, another niche cause area which few philanthropists are concerned with. In spite of this, OP seems to have maintained its giving capacity. Given the overwhelming case for prioritizing animal welfare in neartermism, OP may be able to communicate its change in cause prioritization in a way which maintains the donor relationships which have done so much good for others.
Request for Reasoning Transparency from OP
Though I've endeavored to critique whichever views OP may plausibly hold that preclude prioritizing animal welfare in neartermism, I'm still deeply unsure about what OP's views actually are. Here are several reasons why OP should clarify their views:
- OP believes in reasoning transparency, but their reasoning has not been transparent.
- OP's prioritization seems out of step with the mean EA leader.[17] Clarifying OP's view could kindle a conversation which could update OP or other EA leaders.
- The only views I can currently think of where animal welfare wouldn't be prioritized in neartermism (overwhelming non-hedonism or overwhelming hierarchicalism) seem rather dubious. If OP has strong arguments for those views, or OP reveals a plausible alternative view I hadn't thought of, I and many others could be updated.
- Historically, OP's decisionmakers' statements about the moral worth of animals haven't been easy to reconcile. A cohesive statement of OP's view would put this to rest.
- For example, in 2017, Holden's personal reflections "indicate against the idea that e.g. chickens merit moral concern". In 2018, Holden stated that "there is presently no evidence base that could reasonably justify high confidence [that] nonhuman animals are not 'conscious' in a morally relevant way". Did Holden's view change? If so, for what reasons?
It's also possible that OP lacks a formal theory for why animal welfare doesn't dominate in neartermism. As Alexander Berger has said, "I’ve always recognized that my maximand is under-theorized". If so, it would seem even more important for OP to clarify their view. If there's a chance that 1 million dollars to corporate campaigns is actually worth 1 billion dollars to GiveWell-recommended charities, understanding one's answers to the relevant philosophical questions seems very important.
Here are some specific questions I request that OP answer:
- How much weight does OP's theory of welfare place on pleasure and pain, as opposed to nonhedonic goods?
- Precisely how much more does OP value one unit of a human's welfare than one unit of another animal's welfare, just because the former is a human? How does OP derive this tradeoff?
- How would OP's views have to change for OP to prioritize animal welfare in neartermism?
Conclusion
When I started as an EA, I found other EAs' obsession with animal welfare rather strange. How could these people advocate for helping chickens over children in extreme poverty? I changed my mind for a few reasons.
The foremost reason was my realization that my love for another being shouldn't be conditional on any property of the other being. My life is pretty different from the life of an African child in extreme poverty. We likely have different cultural values, and I'd likely disagree with many of the decisions they'll make over their lives. But those differences aren't important—each and every one of them is a special person whose feelings matter just the same.
The second reason was understanding the seriousness of the suffering at stake. When I think about the horrors animals experience in factory farms, it makes me feel horrible.
When a quarter million birds are stuffed into a single shed, unable even to flap their wings, when more than a million pigs inhabit a single farm, never once stepping into the light of day, when every year tens of millions of creatures go to their death without knowing the least measure of human kindness, it is time to question old assumptions, to ask what we are doing and what spirit drives us on.
Matthew Scully, "Dominion"
Thirdly, I've been asked whether the prospect of helping millions of beings cheapens the value of helping a single being. If I can save hundreds of African children over the course of my life, does each individual child matter proportionally less? Absolutely not. If helping a single being is worth so much, how much more is helping billions of beings worth? I can't make a difference for billions of beings, but you can.
We aspire to radical empathy: working hard to extend empathy to everyone it should be extended to, even when it’s unusual or seems strange to do so. As such, one theme of our work is trying to help populations that many people don’t feel are worth helping at all.
- ^
Simnegar, Ariel (2023). "Open Phil Grants Analysis". https://github.com/ariel-simnegar/open-phil-grants-analysis/blob/main/open_phil_grants_analysis.ipynb
- ^
Karnofsky, Holden (2016). "Worldview Diversification". https://www.openphilanthropy.org/research/worldview-diversification/
- ^
Open Philanthropy. "Rethink Priorities — Moral Patienthood and Moral Weight Research". https://www.openphilanthropy.org/grants/rethink-priorities-moral-patienthood-and-moral-weight-research/
- ^
"Our team was composed of three philosophers, two comparative psychologists (one with expertise in birds; another with expertise in cephalopods), two fish welfare researchers, two entomologists, an animal welfare scientist, and a veterinarian." Fischer, Bob (2022). "The Welfare Range Table". https://forum.effectivealtruism.org/s/y5n47MfgrKvTLE3pw/p/tnSg6o7crcHFLc395
- ^
Grilo, Vasco (2023). "Prioritising animal welfare over global health and development?". https://forum.effectivealtruism.org/posts/vBcT7i7AkNJ6u9BcQ/prioritising-animal-welfare-over-global-health-and
- ^
Gertler, Aaron (2019). "EA Leaders Forum: Survey on EA priorities (data and analysis)". https://forum.effectivealtruism.org/posts/TpoeJ9A2G5Sipxfit/ea-leaders-forum-survey-on-ea-priorities-data-and-analysis
For the question "What (rough) percentage of resources should the EA community devote to the following areas over the next five years", the mean EA leader answered 10.7% for global health and 9.3% + 3.5% = 12.8% for farm and wild animal welfare respectively. No other neartermist cause areas were listed.
- ^
Simnegar, Ariel (2023). "Open Phil Grants Analysis". https://github.com/ariel-simnegar/open-phil-grants-analysis/blob/main/open_phil_grants_analysis.ipynb
- ^
Fischer, Bob (2023). "Theories of Welfare and Welfare Range Estimates". https://forum.effectivealtruism.org/posts/WfeWN2X4k8w8nTeaS/theories-of-welfare-and-welfare-range-estimates
- ^
Rob Wiblin, Kieran Harris (2021). "Alexander Berger on improving global health and wellbeing in clear and direct ways".
- ^
Rencz et al (2020). "Parallel Valuation of the EQ-5D-3L and EQ-5D-5L by Time Trade-Off in Hungary". https://www.sciencedirect.com/science/article/pii/S1098301520321173
- ^
Doth et al (2010). "The burden of neuropathic pain: A systematic review and meta-analysis of health utilities". https://www.sciencedirect.com/science/article/abs/pii/S0304395910001260
- ^
Lee et al (2019). "Increased suicidality in patients with cluster headache". https://pubmed.ncbi.nlm.nih.gov/31018651/
- ^
Goossens et al (1999). "Patient utilities in chronic musculoskeletal pain: how useful is the standard gamble method?". https://www.sciencedirect.com/science/article/abs/pii/S0304395998002322
- ^
Simcikas, Saulius (2019). "Corporate campaigns affect 9 to 120 years of chicken life per dollar spent". https://forum.effectivealtruism.org/posts/L5EZjjXKdNgcm253H/corporate-campaigns-affect-9-to-120-years-of-chicken-life
- ^
Simnegar, Ariel (2023). "Open Phil Grants Analysis". https://github.com/ariel-simnegar/open-phil-grants-analysis/blob/main/open_phil_grants_analysis.ipynb
- ^
Toby Ord's x-risk table from The Precipice has AI 3x greater than pandemics, 100x greater than nuclear war, and 100x greater than climate change.
- ^
Gertler, Aaron (2019). "EA Leaders Forum: Survey on EA priorities (data and analysis)". https://forum.effectivealtruism.org/posts/TpoeJ9A2G5Sipxfit/ea-leaders-forum-survey-on-ea-priorities-data-and-analysis
(Hi, I'm Emily, I lead GHW grantmaking at Open Phil.)
Thank you for writing this critique, and giving us the chance to read your draft and respond ahead of time. This type of feedback is very valuable for us, and I’m really glad you wrote it.
We agree that we haven’t shared much information about our thinking on this question. I’ll try to give some more context below, though I also want to be upfront that we have a lot more work to do in this area.
For the rest of this comment, I’ll use “FAW” to refer to farm animal welfare and “GHW” to refer to all the other (human-centered) work in our Global Health and Wellbeing portfolio.
To date, we haven’t focused on making direct comparisons between GHW and FAW. Instead, we’ve focused on trying to equalize marginal returns within each area and do something more like worldview diversification to determine allocations across GHW, FAW, and Open Philanthropy’s other grantmaking. In other words, each of GHW and FAW has its own rough “bar” that an opportunity must clear to be funded. While our frameworks allow for direct comparisons, we have not stress-tested consistency for that use case. We’re also unsure conceptually whether we should be... (read more)
Hi Emily,
Thanks so much for your engagement and consideration. I appreciate your openness about the need for more work in tackling these difficult questions.
Holden has stated that "It seems unlikely that the ratio would be in the precise, narrow range needed for these two uses of funds to have similar cost-effectiveness." As OP continues researching moral weights, OP's marginal cost-effectiveness estimates for FAW and GHW may eventually differ by several orders of magnitude. If this happens, would OP substantially update their allocations between FAW and GHW?
Along with OP's neartermist cause prioritization, your comment seems to imply that OP's moral weights are 1-2 orders of magnitude lower than Rethink's. If that's true, that is a massive difference which (depending upon the details) could have big implications for how EA should allocate resources between FAW charities (e.g. chickens vs shrimp) as well as between F... (read more)
If OpenPhil’s allocation is really so dependent on moral weight numbers, you should be spending significant money on research in this area, right? Are you doing this? Do you plan on doing more of this given the large divergence from Rethink’s numbers?
Here, you say, “Several of the grants we’ve made to Rethink Priorities funded research related to moral weights.” Yet in your initial response, you said, “We don’t use Rethink’s moral weights.” I respect your tapping out of this discussion, but at the same time I’d like to express my puzzlement as to why Open Phil would fund work on moral weights to inform grantmaking allocation, and then not take that work into account.
One can value research and find it informative or worth doing without being convinced of every view of a given researcher or team. Open Philanthropy also sponsored a contest to surface novel considerations that could affect its views on AI timelines and risk. The winners mostly present conclusions or considerations on which AI would be a lower priority, but that doesn't imply that the judges or the institution changed their views very much in that direction.
At large scale, Information can be valuable enough to buy even if it only modestly adjusts proportional allocations of effort, the minimum bar for funding a research project with hundreds of thousands or millions of dollars presumably isn't that one pivots billions of dollars on the results with near-certainty.
Thank you for engaging. I don’t disagree with what you’ve written; I think you have interpreted me as implying something stronger than what I intended, and so I’ll now attempt to add some colour.
That Emily and other relevant people at OP have not fully adopted Rethink’s moral weights does not puzzle me. As you say, to expect that is to apply an unreasonably high funding bar. I am, however, puzzled that Emily and co. appear to have not updated at all towards Rethink’s numbers. At least, that’s the way I read:
If OP has not updated at all towards Rethink’s numbers, then I see three possible explanations, all of which I find unlikely, hence my puzzlement. First possibility: the relevant people at OP have not yet given the Rethink report a thorough read, and have therefore not updated. Second: the relevant OP people have read the Rethink report, and have updated their internal models, but have not yet gotten around to updating OP... (read more)
Fair points, Carl. Thanks for elaborating, Will!
Interestingly and confusingly, fitting distributions to Luke's 2018 guesses for the 80 % prediction intervals of the moral weight of various species, one gets mean moral weights close to or larger than 1:
It is also worth noting that Luke seemed very much willing to update on further research in 2022. Commenting on the above, Luke said (emphasis mine):
Welfare ranges are a crucial input to determining moral weights, so I assume Luke would also have agreed that it w... (read more)
I can't speak for Open Philanthropy, but I can explain why I personally was unmoved by the Rethink report (and think its estimates hugely overstate the case for focusing on tiny animals, although I think the corrected version of that case still has a lot to be said for it).
Luke says in the post you linked that the numbers in the graphic are not usable as expected moral weights, since ratios of expectations are not the same as expectations of ratios.
[Edited for clarity] I was not satisfied with Rethink's attempt to address that central issue, that you get wildly different results from assuming the moral value of a fruit fly is fixed and reporting possible ratios to elephant welfare as opposed to doing it the other way around.
It is not unthinkably improbable that an elephant brain where reinforcement from a positive or negative stimulus adjust millions of times as many neural computations could be seen as vastly more morally important than a fruit fly, just as one might think that a f... (read more)
Thanks for your discussion of the Moral Weight Project's methodology, Carl. (And to everyone else for the useful back-and-forth!) We have some thoughts about this important issue and we're keen to write more about it. Perhaps 2024 will provide the opportunity!
For now, we'll just make one brief point, which is that it’s important to separate two questions. The first concerns the relevance of the two envelopes problem to the Moral Weight Project. The second concerns alternative ways of generating moral weights. We considered the two envelopes problem at some length when we were working on the Moral Weight Project and concluded that our approach was still worth developing. We’d be glad to revisit this and appreciate the challenge to the methodology.
However, even if it turns out that the methodology has issues, it’s an open question how best to proceed. We grant the possibility that, as you suggest, more neurons = more compute = the possibility of more intense pleasures and pains. But it's also possible that more neurons = more intelligence = less biological need for intense pleasures and pains, as other cognitive abilities can provide the relevant fitness benefits, effectively muting ... (read more)
Thank you for the comment Bob.
I agree that I also am disagreeing on the object-level, as Michael made clear with his comments (I do not think I am talking about a tiny chance, although I do not think the RP discussions characterized my views as I would), and some other methodological issues besides two-envelopes (related to the object-level ones). E.g. I would not want to treat a highly networked AI mind (with billions of bodies and computation directing them in a unified way, on the scale of humanity) as a millionth or a billionth of the welfare of the same set of robots and computations with less integration (and overlap of shared features, or top-level control), ceteris paribus.
Indeed, I would be wary of treating the integrated mind as though welfare stakes for it were half or a tenth as great, seeing that as a potential source of moral catastrophe, like ignoring the welfare of minds not based on proteins. E.g. having tasks involving suffering and frustration done by large integrated minds, and pleasant ones done by tiny minds, while increasing the amount of mental activity in the former. It sounds like the combination of object-level and methodological takes a... (read more)
This consideration is something I had never thought of before and blew my mind. Thank you for sharing.
Hopefully I can summarize it (assuming I interpreted it correctly) in a different way that might help people who were as befuddled as I was.
The point is that, when you have probabilistic weight to two different theories of sentience being true, you have to assign units to sentience in these different theories in order to compare them.
Say you have two theories of sentience that are similarly probable, one dependent on intelligence and one dependent on brain size. Call these units IQ-qualia and size-qualia. If you assign fruit flies a moral weight of 1, you are implicitly declaring a conversion rate of (to make up some random numbers) 1000 IQ-qualia = 1 size-qualia. If you assign elephants however to have a moral weight of 1, you implicitly declare a conversion rate of (again, made-up) 1 IQ-qualia = 1000 size-qualia, because elephant brains are much larger but not much smarter than fruit flies. These two different conversion rates are going to give you very different numbers for the moral weight of humans (or as Shulman was saying, of each other).
Rethink Priorities assigned humans a moral weight of 1, and thus assumed a certain conversion rate between different theories that made for a very small-animal-dominated world by sentience.
This specific kind of account, if meant to depend inherently on differences in reinforcement, is very improbable to me (<0.1%), and conditional on such accounts, the inherent importance of reinforcement would also very probably scale very slowly, with faster scaling increasingly improbable. It could work out that the expected scaling isn't slow, but that would be because of very low probability possibilities.
The value of subjective wellbeing, whether hedonistic, felt desires, r... (read more)
(I'm not at Rethink Priorities anymore, and I'm not speaking on their behalf.)
RP did in fact respond to some versions of these arguments, in the piece Do Brains Contain Many Conscious Subsystems? If So, Should We Act Differently?, of which I am a co-author.
Thanks for elaborating, Carl!
Let me try to restate your point, and suggest why one may disagree. If one puts weight w on the welfare range (WR) of humans relative to that of chickens being N, and 1 - w on it being n, the expected welfare range of:
You are arguing that N can plausibly be much larger than n. For the sake of illustration, we can say N = 389 (ratio between the 86 billion neurons of a humans and 221 M of a chicken), n = 3.01 (reciprocal of RP's median welfare range of chickens relative to humans of 0.332), and w = 1/12 (since the neuron count model was one of the 12 RP considered, and all of them were weighted equally). Having the welfare range of:
- Chickens as the reference, E("WR of humans"/"WR of chickens") = 35.2. So 1/E("WR of humans"/"WR of chickens") = 0.0284.
- Humans as the reference (as RP did), E("WR of chick
... (read more)I'm not planning on continuing a long thread here, I mostly wanted to help address the questions about my previous comment, so I'll be moving on after this. But I will say two things regarding the above. First, this effect (computational scale) is smaller for chickens but progressively enormous for e.g. shrimp or lobster or flies. Second, this is a huge move and one really needs to wrestle with intertheoretic comparisons to justify it:
Suppose we compared the mass of the human population of Earth with the mass of an individual human. We could compare them on 12 metrics, like per capita mass, per capita square root mass, per capita foot mass... and aggregate mass. If we use the equal-weighted geometric mean, we will conclude the individual has a mass within an order of magnitude of the total Earth population, instead of billions of times less.
Hi Emily, Sorry this is a bit off topic but super useful for my end of year donations.
I noticed that you said that OpenPhil has supported "Rethink Priorities ... research related to moral weights". But in his post here Peter says that the moral weights work "have historically not had institutional support".
Do you have a rough very quick sense of how much Rethink Priorities moral weights work was funded by OpenPhil?
Thank you so much
We mean to say that the ideas for these projects and the vast majority of the funding were ours, including the moral weight work. To be clear, these projects were the result of our own initiative. They wouldn't have gone ahead when they did without us insisting on their value.
For example, after our initial work on invertebrate sentience and moral weight in 2018-2020, in 2021 OP funded $315K to support this work. In 2023 they also funded $15K for the open access book rights to a forthcoming book based on the topic. In that period of 2021-2023, for public-facing work we spent another ~$603K on moral weight work with that money coming from individuals and RP's unrestricted funding.
Similarly, the CURVE sequence of WIT this year was our idea and we are on track to spend ~$900K against ~$210K funded by Open Phil on WIT. Of that $210K the first $152K was on projects related to Open Phil’s internal prioritization and not the public work of the CURVE sequence. The other $58K went towards the development of the CCM. So overall less than 10% of our costs for public WIT work this year was covered by OP (and no other institutional donors were covering it either).
I assume that even though your answers are within one order of magnitude, the animal-focused work is the one that looks more cost-effective. Is that right?
Assuming so, your answer doesn't make sense to me because OP funds roughly 6x more human-focused GHW relative to farm animal welfare (FAW). Even if you have wide uncertainty bounds, if FAW is looking more cost-effective than human work, surely this ratio should be closer to 1:1 rather than 1:6? It seems bizarre (and possibly an example of omission bias) to fund the estimated less cost-effective thing 6x more and justify it by saying you're quite uncertain.
Long story short, should we not just allocate our funding to the best of our current knowledge (even by your calculations, more towards FAW) and then update accordingly if things change?
Thanks for the feedback, Emily!
I am a little confused by the above. You say my analysis implies a much wider welfare range than the one you use, but in my analysis I just used point estimates. I relied on Rethink Priorities' median welfare range for chickens of 0.332, although Rethink's 5th and 95th percentile are 0.002 and 0.869 (i.e. the 95th percentile is 434 times the 5th percentile).
Are you saying Rethink's interval for the welfare range of chickens is much wider than Open Phil's? I think that would imply some disagreement with Luke's guess. Following his 2017 report on consciousness and moral pa... (read more)
For those who agree with this post (I at least agree with the author's claim if you replace most with more), I encourage you to think what you personally can do about it.
I think EAs are far too willing to donate to traditional global health charities, not due to them being the most impactful, but because they feel the best to donate to. When I give to AMF I know I'm a good person who had an impact! But this logic is exactly what EA was founded to avoid.
I can't speak for animal welfare organizations outside of EA, but at least for the ones that have come out of Effective Altruism, they tell me that funding is a major issue. There just aren't that many people willing to make a risky donation a new charity working on fish welfare, for example.
Those who would be risk-willing enough to give to eccentric animal welfare or global health interventions, tend to also be risk-willing enough with their donations to instead give it to orgs working on existential risks. I'm not claiming this is incorrect of them to do, but this does mean that there is a dearth of funding for high-risk interventions in the neartermist space.
I donated a significant part of my personal runway to help fund a new animal welfare org, which I think counterfactually might not have gotten started if not for this. If you, like me, think animal welfare is incredibly important and previously have donated to Givewell's top charities, perhaps consider giving animal welfare a try!
<3 This is super awesome / inspirational, and I admire you for doing this!
Given it is the Giving Season, I'd be remiss not to point out that ACE currently has donation matching for their Recommended Charity Fund.
I am personally waiting to hear back from RC Forward on whether Canadian donations can also be made for said donation matching, but for American EAs at least, this seems like a great no-brainer opportunity to dip your feet in effective animal welfare giving.
Strongly, strongly, strongly agree. I was in the process of writing essentially this exact post, but am very glad someone else got to it first. The more I thought about it and researched, the more it seemed like convincingly making this case would probably be the most important thing I would ever have done. Kudos to you.
A few points to add
- Under standard EA "on the margin" reasoning, this shouldn't really matter, but I analyzed OP's grants data and found that human GCR has been consistently funded 6-7x more than animal welfare (here's my tweet thread this is from)
- @Laura Duffy's (for Rethink Priorities) recently published risk aversion analysis basically does a lot of the heavy lifting here (bolding mine):
... (read more)FYI, I made a spreadsheet a while ago which automatically pulls the latest OP grants data and constructs summaries and pivot tables to make this type of analysis easier.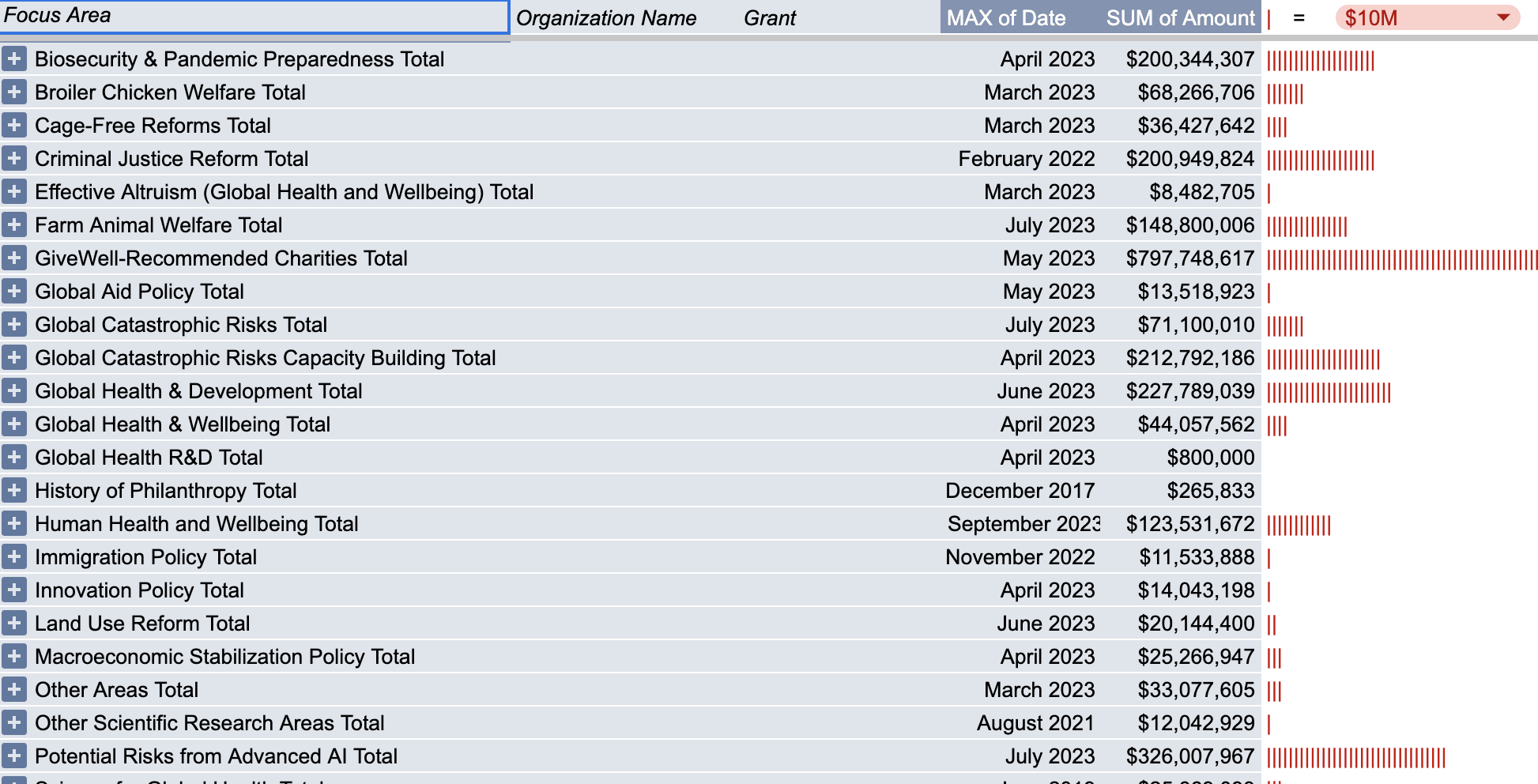
I also made these interactive plots which summarise all EA funding:
Regardless of what Open Phil ends up doing, would really appreciate them to at least do this :)
I would qualify this statement by saying that it would be nice for OP to have more reasoning transparency, but it is not the most important thing and can be expensive to produce. So it would be quite reasonable for additional marginal transparency to not be the most valuable use of their staff time.
I think if there's anything they should bother to be publicly transparent about in order to subject to further scrutiny, it's their biggest cruxes for resource allocation between causes. Moral weights, theory of welfare and the marginal cost-effectiveness of animal welfare seem pretty decisive for GHD vs animal welfare.
This seems to be the key claim of the piece, so why isn't the "1000x" calculation actually spelled out?
The "cage-free campaigns analysis" estimates
This analysis gives chicken years affected per dollar as 9.6-120 (95%CI), with 41 as the median estimate.
The moral weights analysis estimates "welfare ranges", ie, the difference in moral value between the best possible and worst possible experience for a given species. This doesn't actually tell us anything about the disutility of caging chickens. For that you would need to make up some additional numbers:
... (read more)Thanks for all this, Hamish. For what it's worth, I don't think we did a great job communicating the results of the Moral Weight Project.
- As you rightly observe, welfare ranges aren't moral weights without some key philosophical assumptions. Although we did discuss the significance of those assumptions in independent posts, we could have done a much better job explaining how those assumptions should affect the interpretation of our point estimates.
- Speaking of the point estimates, I regret leading with them: as we said, they're really just placeholders in the face of deep uncertainty. We should have led with our actual conclusions, the basics of which are that the relevant vertebrates are probably within an OOM of humans and shrimps and the relevant adult insects are probably within two OOMs of the vertebrates. My guess is that you and I disagree less than you might think about the range of reasonable moral weights across species, even if the centers of my probability masses are higher than yours.
- I agree that our methodology is complex and hard to understand. But it would be surprising if there were a simple, easy-to-understand way to estimate the possible differences in the intensit
... (read more)Thanks for responding to my hot takes with patience and good humour!
Your defenses and caveats all sound very reasonable.
So given this, you'd agree with the conclusion of the original piece? At least if we take the "number of chickens affected per dollar" input as correct?
I agree with Ariel that OP should probably be spending more on animals (and I really appreciate all the work he's done to push this conversation forward). I don't know whether OP should allocate most neartermist funding to AW as I haven't looked into lots of the relevant issues. Most obviously, while the return curves for at least some human-focused neartermist options are probably pretty flat (just think of GiveDirectly), the curves for various sorts of animal spending may drop precipitously. Ariel may well be right that, even if so, the returns probably don't fall off so much that animal work loses to global health work, but I haven't investigated this myself. The upshot: I have no idea whether there are good ways of spending an additional $100M on animals right now. (That being said, I'd love to see more extensive investigation into field building for animals! If EA field building in general is cost-competitive with other causes, then I'd expect animal field building to look pretty good.)
I should also say that OP's commitment to worldview diversification complicates any conclusions about what OP should do from its own perspective. Even if it's true that a straightforward utilita... (read more)
700/100=7, not 0.7.
oh true lol
ok, animal charities still come out an order of magnitude ahead of human charities given the cage-free campaigns analysis and neuron counts
but the broader point is that the RP analyses seem far from conclusive and it would be silly to use them unilaterally for making huge funding allocation decisions, which I think still stands
Hi Hamish! I appreciate your critique.
Others have enumerated many reservations with this critique, which I agree with. Here I'll give several more.
As you've seen, given Rethink's moral weights, many plausible choices for the remaining "made-up" numbers give a cost-effectiveness multiple on the order of 1000x. Vasco Grilo conducted a similar analysis which found a multiple of 1.71k. I didn't commit to a specific analysis for a few reasons:
- I agree with your point that uncertainty is really high, and I don't want to give a precise multiple which may understate the uncertainty.
- Reasonable critiques can be made of pretty much any assumptions made which imply a specific multiple. Though these critiques are important for robust methodology, I wanted the post to focus specifically upon how difficult it seems to avoid the conclusion of prioritizing animal welfare in neartermism. I believe that given Rethink's moral weights, a cost-effectiveness multiple on the order of 1000x will be found by most plausible choices for the additional assumptions.
... (read more)As something of an aside, I think this general point was demonstrated and visualised well here.
Disclaimer: I work RP so may be biased.
I think your BOTEC is unlikely to give meaningful answers because it treats averting a human death as equivalent to moving someone from the bottom of their welfare range to the top of their welfare range. At least to me, this seems plainly wrong - I'd vastly prefer shifting someone from receiving the worst possible torture to the greatest possible happiness for an hour to extending someone's ordinary life for an hour.
The objections you raise are still worth discussing, but I think the best starting place for discussing them is Duffy (2023)'s model (Causal model, report), rather than your BOTEC.
"If an animal can already experience excruciating pain, presumably near the extreme of their welfare range, what do humans have that would make excruciating pain far worse for us in general, or otherwise give us far wider welfare ranges? And why?"
We have a far more advanced consciousness and self awareness, that may make our experience of pain orders of magnitude worse (or at least different) than for many animals - or not.
I think there is far more uncertainty in this question than many ackhnowledge - RP acknowledge the uncertainty but I don't think present it as clearly as they could. Extreme pain for humans could be a wildly different experience than it is for animals, or it could be quite similar. Even if we assume hedonism (which I don't), we can oversimplify the concepts of "Sentience" and "welfare ranges" to feel like we have more certainty over these numbers than we do.
I agree that that's possible and worth including under uncertainty, but it doesn't answer the "why", so it's hard to justify giving it much or disproportionate weight (relative to other accounts) without further argument. Why would self-awareness, say, make being in intense pain orders of magnitude worse?
And are we even much more self-aware than other animals when we are in intense pain? One of the functions of pain is to take our attention, and it does so more the more intense the pain. That might limit the use of our capacities for self-awareness: we'd be too focused on and distracted by the pain. Or, maybe our self-awareness or other advanced capacities distract us from the pain, making it less intense than in other animals.
(My own best guess is that at the extremes of excruciating pain, sophisticated self-awareness makes little difference to the intensity of suffering.)
They won't be literally identical: they'll differ in many ways, like physical details, cognitive expression and behavioural influence. They're separate instantiations of the same broad class of functions or capacities.
I would say the number of times a function or capacity is realized in a brain can be relevant, but it seems pretty unlikely to me that a person can experience suffering hundreds of times simultaneously (and hundreds of times more than chickens, say). Rethink Priorities looked into these kinds of views here. (I'm a co-author on that article, but I don't work at Rethink Priorities anymore, and I'm not speaking on their behalf.)
FWIW, I started very pro-neuron counts (I defended them here and here), and then others at RP, collaborators and further investigation myself moved me away from the view.
There are other simple methodologies that make vaguely plausible guesses (under hedonism), like:
In my view, 1, 2 and 3 are more plausible and defensible than views that would give you (cortical or similar function) neuron counts as a good approximation. I also think the actually right answer, if there's any (so excluding the individual-relative interpretation for 1), will look like 2, but more complex and with possibly different functions. RP explicitly considered 1 and 3 in its work. These three models give chickens >0.1x humans' welfare ... (read more)
Strong upvoted. I think this is correct, important and well-argued, and I welcome the call to OP to clarify their views.
This post is directed at OP, but this conclusion should be noted by the EA community as a whole which still prioritises global poverty over all else.
The only caveat I would raise is that we need to retain some focus on global poverty in EA for various instrumental reasons: it can attract more people into the movement, allows us to show concrete wins etc.
I strongly agree with this post and strongly upvoted it. I also talked a lot with Ariel in the making of this post. I think the arguments are good and I think EA in general should be focusing a lot more on animal welfare than GHW.
That said, I think it's important to note that "EA" doesn't own the money being given away by Open Phil. It's Dustin/Cari's money that is being given away and Open Phil was set up (by them, in a joint venture between Givewell and Good Ventures) to advise them where their money should go and they are inspired/wish to give away their money by EA principles.
The people at Open Phil are heavily influenced by Dustin/Cari's values so it isn't surprising that the people at Open Phil might value animals less than the general movement and if Dustin/Cari don't want to give their money to non-human animal causes, that's well within their rights. The "EA movement", however you define it, doesn't get to control the money and there are good reasons for this.
Like @MathiasKB, I want to generally encourage people to see how they can affect the funding landscape, primarily via their own donations as opposed to simply telling other people how they should donate. A very unstable equilibrium would result from a bunch of people steering and not a lot of people rowing.
I disagree, for the same reasons as those given in the critique to the post you cite. Tl;dr: Trades have happened, in EA, where many people have cast aside careers with high earning potential in order to pursue direct work. I think these people should get a say over where EA money goes.
This is from 2016, but worth looking into if you're curious how this works:
"At least 50% of each program officer’s grantmaking should be such that Holden and Cari understand and are on board with the case for each grant. At least 90% of the program officer’s grantmaking should be such that Holden and Cari could easily imagine being on board with the grant if they knew more, but may not be persuaded that the grant is a good idea. (When taking the previous bullet point into account, this leaves room for up to 40% of the portfolio to fall in this bucket.) Up to 10% of the program officer’s grantmaking can be done without meeting either of the above two criteria, though there are some basic checks in place to avoid grantmaking that creates risks for Open Philanthropy. We call this “discretionary” grantmaking. Grants in this category generally follow a different, substantially abbreviated approval process. Some examples of discretionary grants are here and here."
(https://www.openphilanthropy.org/research/our-grantmaking-so-far-approach-and-process/)
Thanks for sharing, MvK!
In general, I would still say Open Phil's grantmaking process is very opaque, and I think it would be great to have more transparency about how grants are made, including the influence of Dustin and Cari, at least for big ones. Just to illustrate how little information is provided, here is the write-up of a grant of 10.7 M$ to Redwood Research in 2022:
There was nothing else. Here is the write-up regarding the 2021 support, 9.42 M$, mentioned just above:
I think this post is on the right track, the request for reasoning transparency especially so.
I personally worry about how weird effective altruism will seem to the outside world if we focus exclusively on topics that most people don't think are very important. A sister comment argues that the average person's revealed preference about the value of a hen's life relative to a human's is infinitesimal. Likewise, however much people say they worry about AI (as a proxy for longtermism, which isn't really on people's radar in general), in practice, it tends to be relatively low on their list of concerns, even among potential existential threats.
If our thinking takes us in weird directions, that's not inherently a reason to shy away. But I think there's something to be said for considering the implications of having increasingly niche opinions, priorities, and epistemology. A movement that's a little more humble/agnostic about what the most important cause is might broadly be able to devote more resources, on net, to a wider range of causes, including the ones we think most important.
(For context I am a vegan who believes that animal welfare is broadly neglected -- I recently... (read more)
Also worry about the weirdness. Ariel said themselves:
This might not be realistic for Ariel, but it would have been ironic if this obsession was even greater and enough to cause Ariel to shy away from EA, so that they never contributed to shifting priorities more to animal welfare.
But I also agree this isn't necessarily a reason to shy away. Being disingenuous about our personal priorities to seem more mainstream seems wrong - like a bait-and-switch or cult-like tactics of getting people in the door and introducing heavier stuff as they get more emotionally invested. I like the framing of being more humble/agnostic, but maybe we (speaking as individuals) need to be careful that is genuine epistemological humility and not an act.
100% agree. I think it is almost always better to be honest, even if that makes you look weird. If you are worried about optics, "oh yeah, we say this to get people in but we don't really believe it" looks pretty bad.
I think that revealed preference can be misleading in this context, for reasons I outline here.
It's not clear that people's revealed preferences are what we should be concerned about compared to, for example, what value people would reflectively endorse assigning to animals in the abstract. People's revealed preference for continuing to eat meat, may be influenced by akrasia, or other cognitive distortions which aren't relevant to assessing how much they actually endorse animals being valued.[1] We may care about the latter, not the former, when assessing how much we should value animals (i.e. by taking into account folk moral weights) or how much the public are likely to support/oppose us allocating more aid to animals.
But on the specific question of how the public would react to us allocating more resources to animals: this seems like a directly tractable empirical question. i.e. it would be relatively straightforward through surveys/experiments to assess whether people would be more/less hostile towards if we spent a greater share on animals, or if we spent much more on the long run future vs supporting a more diverse portfolio, or more/less on climate change etc.
&nbs... (read more)
Thanks a lot for this post!
I was thinking of doing something similar myself.
And I must admit I agree with the conclusion, especially as I have trouble seeing how their ability to suffer can be much lower than ours (I mean, we have a lot of evolutionary history in common. I can't really justify how my cat would be able to feel an amount of pain ten times lower than mine).
Since animals are far more numerous than humans, they have much worse living conditions, much less money is spent on their welfare than on human well-being, and animal charities are more funding-constrained, it's hard to see how working on them can be less cost-effective.
In fact, it has been suggested by Richard Dawkins that less intelligent animals might experience greater suffering, as they require more intense pain to elicit a response. The evolutionary process would have ensured they feel sufficient pain.
Thanks for writing this post! I think it's thoughtful and well-reasoned, and I think public criticism of OP (and leading institutions in effective altruism in general) is good and undersupplied, so I feel ike this writeup is commendable. I work at a global health nonprofit funded by OP, so I should say I'm strongly biased against moving lots of the money to animal welfare.
An argument I've heard in the past (not the point of your post I know) is that because humans (often) eat factory-farmed animals, expanding human lifespan is net negative from a welfarist perspective (because it increases the net amount of suffering in the world). 1. Is this argument implausible (i.e. is there a good way to disprove it?) and 2. If the argument were true, would it imply OP should not fund global health work at all (or restrict it very seriously)?
There's a related tag Meat-eater problem, with some related posts. I think this is less worrying in low-income countries where GiveWell-recommended charities work, because animal product consumption is still low and factory farming has not yet become the norm. That being said, factory farming is becoming increasingly common, and it could be common for the descendants of the people whose lives are saved.
Then, there are also complicated wild animal effects from animal product consumption and generally having more humans that could go either way morally, depending on your views.
One thought is that it may be a mistake to categorize GHD work as purely "neartermist". As Nick Beckstead flagged in his dissertation, the strongest reason for favoring GHD over animal welfare is that the former, by increasing overall human capacity, seems more likely to have positive "ripple effects" beyond the immediate beneficiaries.
One may object that GHD has lower expected value than explicitly longtermist work. But GHD may be more robustly good, with less risk of proving long-term counterproductive. So it may help to think of the GHD component of Worldview Diversification as stemming from a concern for robustness, rather than a concern for the nearterm per se.
Admittedly, we weren't factoring in the (ostensible) ripple effects, but our modeling indicates that if we're interested in robust goodness, we should be spending on chickens.
Also, for the reasons that @Ariel Simnegar already notes, even if there are unappreciated benefits of investing in GHD, there would need to be a lot of those benefits to justify not spending on animals. Could work out that way, but I'd like to see the evidence. (When I investigated this myself, making the case seemed quite difficult.)
This seems quite low, at least from a perspective of revelead preferences. If one indeed rejects unitarism, I suspect that the actual willingness to pay is something like 1000x - 10,000x to prevent the death of an animal vs. a human.
Also, if we defer to people's revealed preferences, we should dramatically discount the lives and welfare of foreigners. I'd guess that Open Philanthropy, being American-funded, would need to reallocate much or most of its global health and development grantmaking to American-focused work, or to global catastrophic risks.
EDIT: For those interested, there's some literature on valuing foreign lives, e.g. https://scholar.google.ca/scholar?hl=en&as_sdt=0%2C5&q="valuing+foreign+lives"+OR+"foreign+life+valuation"
But isn't the relevant harm here animal suffering rather than animal death? It would seem pretty awful to prefer that an animal suffer torturous agony rather than a human suffer a mild (1000x less bad) papercut.
I think comparisons to paper cuts and other minor harms don't work very well with people's intuitions: a lot of people feel like (and sometimes explicitly endorse that) no number of paper cuts can outweigh torturous agony. See this old LW post and the disagreements around it.
Instead, my experience is people's intuitions work better when thinking in probabilities or quantities: what chance of suffering for a human would balance against that for a chicken? Or how many chickens suffering in that way would be equivalent to one human?
Revealed preference is a good way to get a handle on what people value, but its normative foundation is strongest when the tradeoff is internal to people. Eg when we value lives vs income, we would want to use people's revealed preference for how they trade those off because those people are the most affected by our decisions and we want to incorporate their preferences. That normative foundation doesn't really apply to animal welfare where the trade-offs are between people and animals. You may as well use animals revealed preferences for saving humans (ie not at all) and conclude that humans have no worth; it would be nonsensical.
I think that's basically right, but also rejecting unitarianism and discounting other animals through this seems to me like saying the interests of some humans matter less in themselves (ignoring instrumental reasons) just because of their race, gender or intelligence, which is very objectionable.
People discount other animals because they're speciesist in this way, although also for instrumental reasons.
This is a masterpiece.
These were the key points for me from the article:
- Unitarianism: the view that the moral value of welfare is independent of a being's species. Even if we value one unit of human welfare one hundred times more than one unit of another animal's welfare, the conclusion still supports prioritizing animal welfare
- 1$=200 hens: corporate campaigns can spare over 200 hens from cage confinement for each dollar spent, according to GiveWell.
- 1,000: The average cost-effectiveness of cage-free campaigns is on the order of 1,000 times that of GiveWell
... (read more)I haven't read the other comments yet but I just want to share my deep appreciation for writing this post! I've always wondered why animal welfare gets so little funding compared to global health in EA. I'm thankful you're highlighting it and starting a discussion, whether or not OP's reasons might be justified.
Very good points made! One objection I think you didn’t mention that might be on OP’s mind in neartermist allocations has to do with population ethics. One reason many people are near termist is because they subscribe to a person-affecting view whereby the welfare of “merely potential” beings does not matter. Since basically all animal welfare interventions either 1. Cause fewer animals to exist, or 2. Change welfare conditions for entire populations of animals, it seems extremely unlikely the animals who would otherwise have lived the higher suffering lives will have the same identity (eg same genes) as the higher welfare ones. To a person affecting view, this implies animal welfare interventions like corporate campaigns or alt protein investment merely change who or how many animals there are but don’t benefit any animal in particular and thus have no impact on this moral view. I personally don’t subscribe to this view, and I am not sure if most people at OP with a person affecting view have taken this idea seriously although it does seem like the right conclusion from this view.
Generally, people with person-affecting views still want it to be the case that we shouldn't create individuals with awful lives, and probably also that we should prefer the creation of someone with a life that is net-negative by less over someone with a life that is net-negative by more. (This relates to the supposed procreation asymmetry, where, allegedly, that a kid would be really happy is not a reason to have them, but that a kid would be in constant agony is a reason not to have them.) One way to justify this would be the thought that, if you don't create a happy person, no one has a complaint, but if you do create a miserable person, someone does have a complaint (i.e., that person).
Where factory-farmed animals have net-negative lives, I'm not sure person-affecting views would justify neglecting animal welfare, then. (Similarly, re: longtermism, they might justify neglecting long-term x-risks, but not s-risks.)
Hi Ariel,
Not strictly related to this post, but just in case you need ideas for further posts ;), here are some very quick thoughts on 80,000 Hours.
I wonder whether 80,000 Hours should present "factory-farming" and "easily preventable human [human] diseases" as having the same level of pressingness.
80,000 Hours' thinking the above have similar pressingness is probably in agreement with a list they did in 2017, when factory-farming came out 2 points above (i.e. 10 times as pressing as) developing world health.
It is also interesting that 3 of 80,000 Hours' c... (read more)
Thank you so much for putting this together, Ariel!
Ariel, thank you for taking the time to put this together. It's encouraging to see both constructive and meaningful conversations unfolding around a topic that I believe is essential if we're to see a shift in both OP and EA's FAW funding priorities.
Most points I had in mind have been covered by others in this thread already— but I wanted to extend my support either way.
In the summary you mention that "Skepticism of formal philosophy is not enough". I’m new to the forum, could you (or anyone else) clarify what is meant by formal philosophy? Is the statement equivalent to just saying "Skepticism of philosophy is not enough" or "Skepticism of philosophical reasoning is not enough"?
Also, in the section "Increasing Animal Welfare Funding would Reduce OP’s Influence on Philanthropists" you make a comparison of AI x-risk and FAM. While AI x-risk reduction is also a niche cause area, I think you underestimate how niche FAW... (read more)
It is unclear in the first figure whether to compare the circles by area or diameter. I believe the default impression is to compare area, which I think is not what was intended and so is misleading.
Does this just apply to wild animals or stray domestic animals?