Confidence check: This is my field of expertise, I work in the field and I have a PhD in the subject. However I am not an expert in every sub-field that I’m covering here, and in particular I do not have much machine learning experience. This is a blog post and I do not guarantee complete accuracy.
I have done my best to make this readable and enjoyable for a general audience (on the nerdy side), but certain parts are very difficult to explain, so apologies in advance

Introduction
Both AI skeptics and AI boosters sometimes operate on the “breaking news” model of assessing capabilities. Boosters who think powerful AI is imminent can point to a steady stream of breakthrough achievements. Skeptics counter this with an steady stream of AI mistakes and flops. I think both things are important to keep track of, but they won’t give you an accurate idea of AI capabilities. Things that look promising at first glance often turn to be impractical later, while things that flop at first sometimes work out the kinks and become useful later.
What makes more sense for me is to take deep dives into specific subjects and fields, and honestly assess what they are using AI for, and what they are not using AI for. And then track how that changes over time.
In this post, I will summaries an attempt at this in my own field, that of computational atomic-scale electronic structure, a field that sort of awkwardly hangs out on the intersection of physics, chemistry, and material science. This field frustratingly, doesn’t really have an agreed upon easy to write name or acronym, so I’m just going to invent one for this post: CEST, for “computational electronic structure theory”.
The challenge of the field is this: How can we use computational simulations to usefully predict and understand things about the properties of materials at the atomic level? We will make computer simulations of crystals or models, and solve approximations that will yield a variety of predictions about the material, like it’s electronic conductivity, bandgap, toughness, etc. Computational physicists sometimes work with experimentalists, and these simulations are generally meant to help guide and elucidate aspects of experimental work. The dream is that someone can present you the structure of a completely new, unstudied material, and you can predict accurately the properties of said material using computation alone. If you want to select a material with a desired property, you could try out thousands of materials computationally,
If you think this sounds like a good field to use AI in, you are not alone. People have been investigating the use of machine learning methods in this field for decades, and researchers have been eager to apply any AI breakthroughs in the field. So if AI takes over material science, it’s coming here first. So is it?
Well I recently attended a conference for the development of methods in CEST which was attended by a few hundred top academics in the field. I thought this was an excellent opportunity to take an overview of the use of machine learning and other AI tools within the field. As a bonus, at the conference there was a panel specifically on the state of AI and quantum computing as it applied to CEST.
How CEST works:
As a kid, you may have been introduced to the structure of an atom as a nucleus of protons and neutrons being orbited around by electrons, like a planet. Then, when class got sufficiently advanced, you would have been informed that that was merely a simplification. In truth, the location of electrons is given by these weird blob shapes called “orbitals”:

Hydrogen orbitals From wikipedia.
These mysterious blob shapes come directly from solving the Schrodinger equations in quantum mechanics. You can think of it as a graph showing where the electrons like to be, with them hanging out in the denser part of the image more.[1] These blobs aren’t just for single atoms, but for molecules and crystals too, where they blend together into new, more complex blobs. Calculating the shape of these electron blobs exactly would allow you to predict pretty much every property of a material in it's natural (non-excited) state, such as it’s physical structure, electronic structure, forces between atoms, etc.
So, if we know the exact equation for determining the exact position of electrons, and all these properties come out of that, then why do we need to bother with material science at all? Can’t we just determine everything about every material from first principles, just by solving the equation?
There’s just one small problem: Solving the equation for any complex system is impossible. You can solve it analytically for very simple cases like the hydrogen atom, but anything beyond that you have to do numerically: which means carving up a simulation into discrete points and solving for the value at each point. And thanks to the quantum mechanical nature of the equation, the number of terms in the equation you have to solve blows up exponentially with the number of electrons. Solving the exact equation for a single salt crystal on a classical computer would break the laws of physics themselves. I go into more detail on this point in this article.
So what CEST is actually about is finding approximations to the Schrodinger equation that can be run on classical supercomputers. The current workhorse for this is a method called density functional theory, or “DFT” for short. This method turns the exponentially growing number of terms into a manageable amount, by only discussing the density of electrons at each point, rather than talking about each electron separately. This allows you to simulate hundreds of atoms, and get reasonable results in a matter of seconds.
However, in order to get this working, you have to rip out quite an important part of the equation, and replace it with an approximate kludge term that we call a “functional”. There are various types of “functionals”, with some being fast and relatively inaccurate, some being slow and relatively accurate[2]. None of them are perfectly accurate: even the most widely regarded and computationally murderous method will still get the band gaps wrong, in an unpredictable way, often by a couple percentage points. Again, see my previous article for some more on that.
There are fairly large limitations on the field. First, even the very best methods can be off by 10% or more on properties like band gaps, and there is no known way to prevent this. Second, these calculations are mostly simulating ground state properties: simulating perturbations to the system adds huge computational cost. They are also mostly on pure, isolated systems frozen at absolute zero: there are ways to move beyond this but they are again costly. They are also restricted to a small number of atoms: simulations of hundreds of atoms are computationally infeasible, requiring a switch to a different, less accurate simulation method such as molecular dynamics.
I haven’t talked about AI yet. This is because AI is just not playing that big a role at the moment (with one or two exceptions that I’ll cover later). If you’re a conventional CEST researcher, like in a company, you will use some sort of DFT software package, which follows a set solving procedure using one of the functional DFT methods that already exists, and at no point in the process is any machine learning used.
AI failures
If you’re on the AI hype train, it might seem to you like CEST is a prime target for AI disruption. And indeed, Deepmind themselves tried to ride in on the train in 2021, releasing their own functional using ML methods to solve for the exact parameters of the approximate functional. In a much touted paper in one the most prestigious journal in the world, Science, Deepmind declared they had made a revolutionary ML powered DFT functional, in a paper entitled “Pushing the frontiers of density functionals by solving the fractional electron problem”.
There turned out to be only mild problem: the functional sucks. In one of my favorite genres of papers, the “diss paper”, a research group released a paper evaluating Googles model on a specific wider test set of materials. They found that for about 70% of the materials, the functional gave pretty good accuracy. But here’s the kicker: for the remaining 30% of materials, the code did not converge at all, essentially giving no answer. There was no way of making the code work for these materials, even trying very hard optimization procedures. The authors conclude that “The major convergence issues with DM21 not only limit its practical applicability for TMC but could also render its use impossible in this area.”[3] A 30% failure rate is just too high for the code to be functionally useful. This is reflected in the usership for the functional, which is very small: in fact the code has not received an update in almost two years. There’s no trace of it on Deepmind’s breakthroughs page.
A similar story played out when it came to AI generation of compounds. Google created an automated materials discovery lab, starting with CEST simulations fed into machine learning software, and claimed that they had found millions of new theoretical materials, and synthesized 43 completely new materials. This very impressive feat got them another highly prestigious publication, in the journal Nature. But then last year, another team poked into it, and released a paper pointing out that the novel material claim was… entirely bullshit. To quote the paper: “we believe that at time of publication, none of the materials produced by A-lab were new: the large majority were misclassified and a smaller number were correctly identified but already known”. It’s a surprisingly readable paper for the topic area.
So, we can score two points for the AI skeptics here. But that’s not the whole story. As we will see in the article ahead, machine learning is alive and kicking in this field. It is one of the largest areas of study and it is achieving things that were straight up impossible to do before.
The conference statistics
I recently attended a materials science conference. It had around 250 attendees, 24 speakers (mostly invited professors), and 122 academic posters. This is a nice sweet spot: small enough that I can realistically go to every talk and inspect every poster, but large enough to be reasonably representative of the field. This isn’t the largest conference in my field, and it is more focused on the cutting edge of developing computational physics methods, rather than on their applications. However there were some very prestigious professors there, considered top figures in the field. These people are at the cutting edge of computational material science.
The conference in question is specifically about methods development for CEST. The conference is large enough to get a good feel for the state of the field, but small enough that I could go to every talk and at least glance at every poster (when I wasn’t presenting my own).
The conference had 25 official invited talks, and I went to all of them. I can’t promise I paid attention to all of them though, some were way, way outside of my wheelhouse. I did try and keep track of whether the talk was about AI or not, and whether it mentioned AI. I did a similar attempt for the posters, although I there were a few I missed, so I can’t guarantee that final number is completely accurate.
First the speakers:
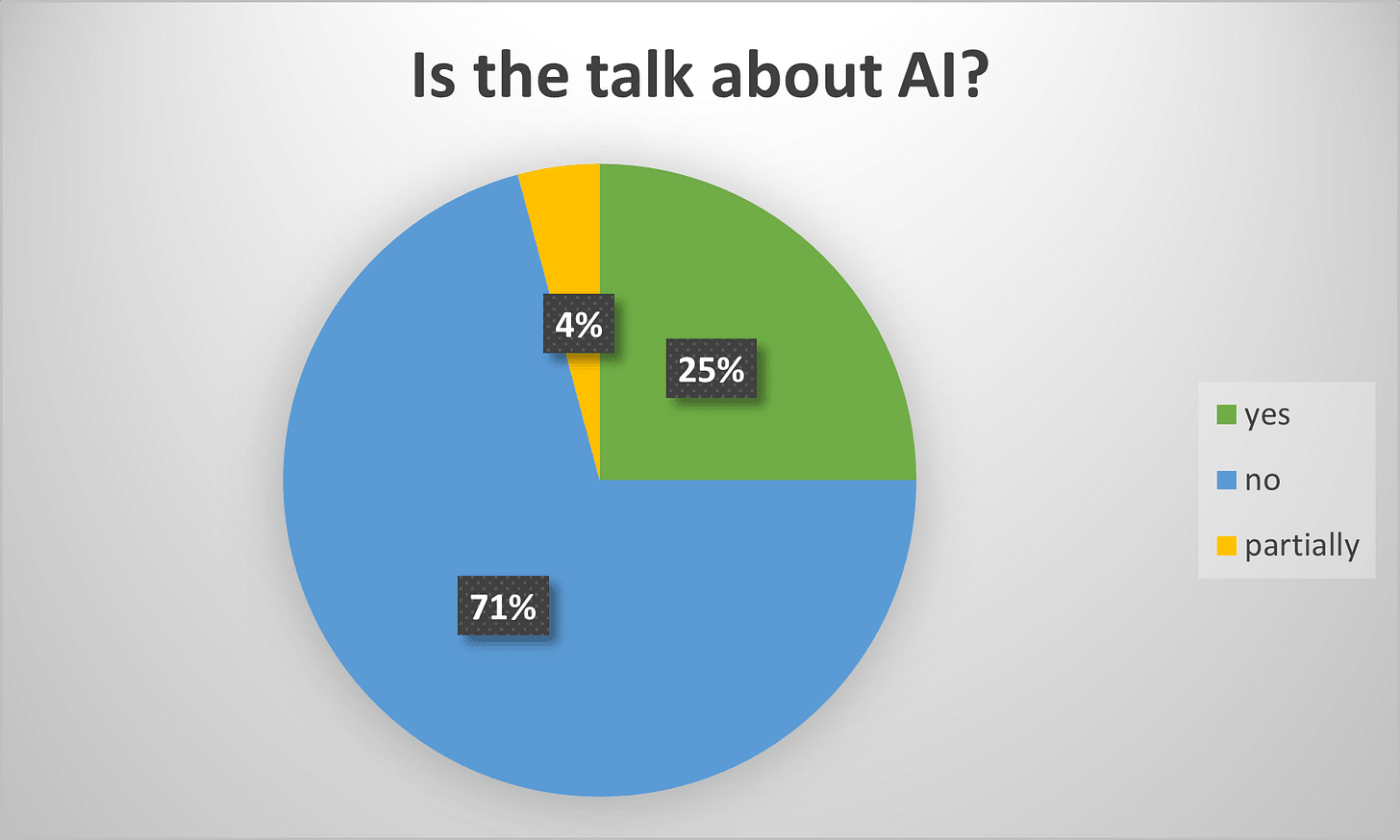
About 25% of the talks were fully about AI, which everyone still calls machine learning here, like they have for the last few decades. Some guy from a big tech company was there and he did try to call things by investor friendly AI names, but the academics did not seem very receptive.
Finally: Did they talk about LLMs?
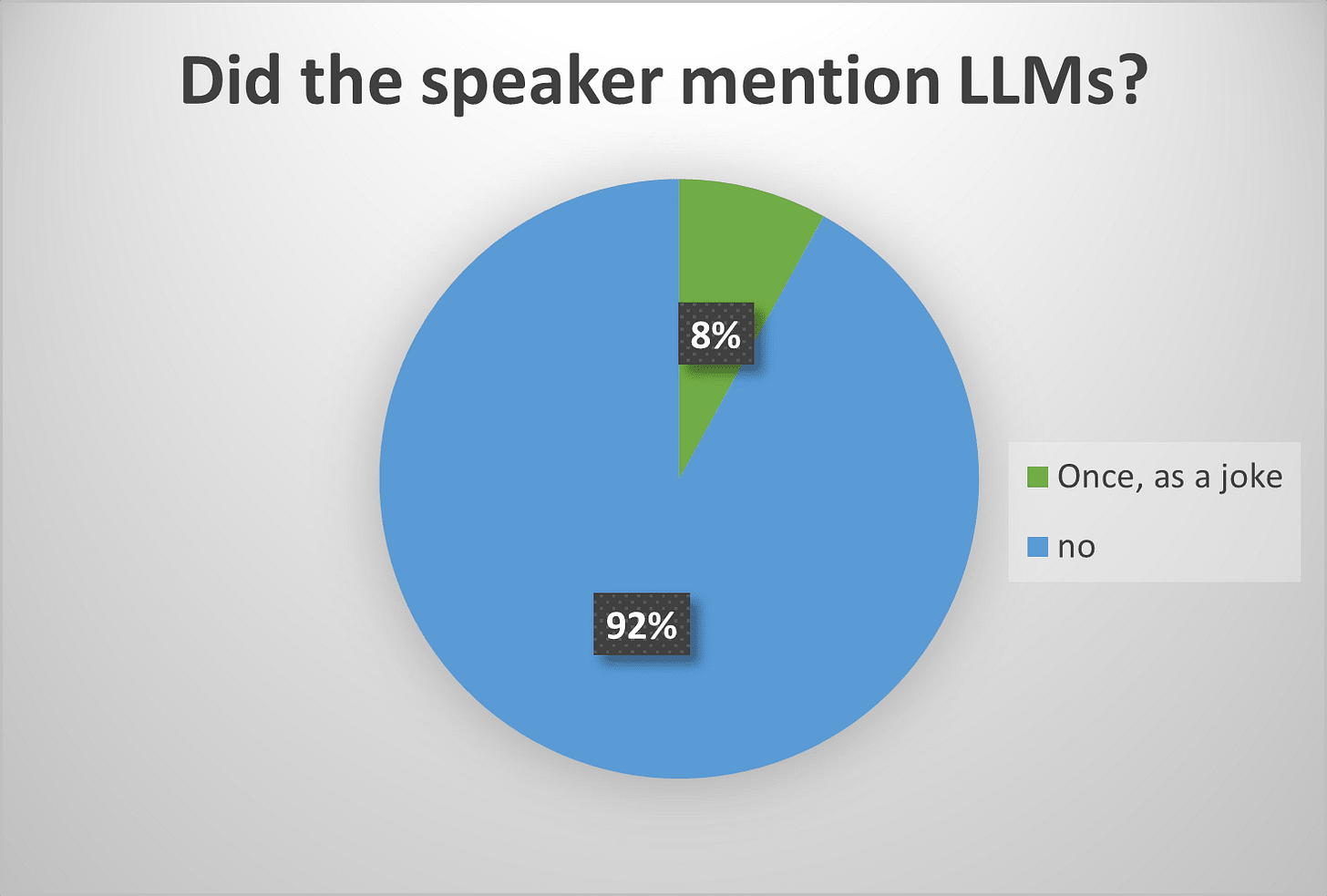
The sum total of mentions of LLMs or other generative AI was… two offhand jokes. Nobody, and I mean nobody, mentioned them. This doesn’t mean that nobody is using them (as I will explain later), but that none of them were important enough to be included in a half hour presentation.
Next, the posters. I was presenting my own poster, so half of these I had to kinda speedrun, but I was able to at least look over most of the posters at the conference. Counting up the ones that I saw a mention of ML on:
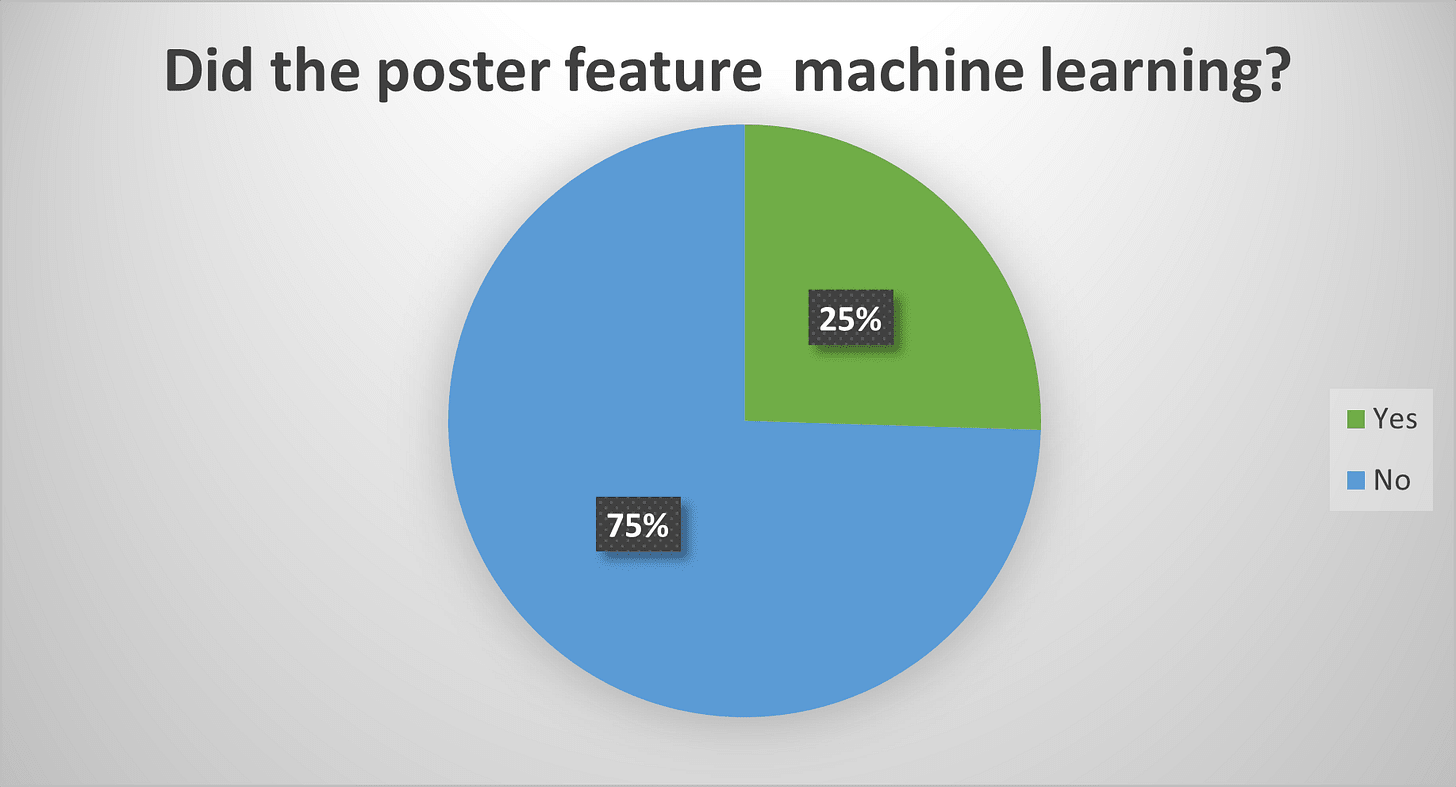
This matches pretty well with speakers: 3/4 of the projects are not involving AI, while 25% do. I’m not going to bother with the LLM thing for the posters: I’ll just say I didn’t see a single mention of LLMs or GenAI. Again, I could have missed something, but I don’t think this is out of line with what I know of from talking to co-workers.
One thing I definitely noticed from multiple people was a generalized annoyance at the big tech companies for the flops I covered earlier. Publishing in highly prestigious journals is a big boost to a scientists career, so it is viewed as extremely annoying that an external company with very little expertise can get handed one of these prestigious publications for substandard work, while good experts within the field can make legitimately great and useful work and not get accepted into the prestige journals.
So what is AI being used for?
I’m going to outline a few areas that seem interesting for AI in our field. This is by no means meant to be comprehensive.
ML for force potentials:
There is one area where Machine learning is well established and could feasibly take over: the area of machine learned force potentials (MLFP). This comes when you are zoomed out a bit, and just want to look at the movement of atoms next to each other, without solving for the locations of all the individual electrons. So instead of using DFT, you use a custom approximations for the forces between atoms in various configurations, called “force fields”. An example code that was shown off at the conference can be found here.
There can be large amount of parameters involved in defining such force fields for each atom type and between different atom types. MLFP uses machine learning to learn these parameters. The basis for this data is DFT simulations . Large numbers of DFT simulations are conducted, and used to generate huge amounts of data about inter-atomic forces and potentials, and the force fields are then machine learned to match this data, which can then be used in a large, molecular dynamics simulation: allowing a simulation with roughly DFT accurate forces, but at a timescale significantly larger than what is possible with those techniques.
I will just quote this review paper on what these methods have enabled:
“While routinely performing computational studies of condensed phase systems (e.g., proteins in solution) at the highest levels of theory is still beyond reach, ML methods have already made other “smaller dreams” a reality. Just a decade ago, it would have been unthinkable to study the dynamics of molecules like aspirin at coupled cluster accuracy. Today, a couple hundred ab initio reference calculations are enough to construct ML-FFs that reach this accuracy within a few tens of wavenumbers. In the past, even if suitable reference data was available, constructing accurate force fields was labor-intensive and required human effort and expertise. Nowadays, by virtue of automatic ML methods, the same task is as effortless as the push of a button. Thanks to the speed-ups offered by ML methods over conventional approaches, studies that previously required supercomputers to be feasible in a realistic time frame can now be performed on a laptop computer.”
There has also been work on universal models, that are not trained by the user, but trained by a company on a huge dataset, then released to researchers to use. Of course, this is dependent on the quality of the initial DFT simulations used for training: there are large collections of DFT calculations available, but they are not always the best quality.
ML for solving the Schrodinger Equation
Earlier I explained the problem with the machine learned Deepmind 21 functional, that turned out to not give any answer at all for 30% of the materials it was tested on. But the first version of a lot of things is buggy. Is it possible that later versions will crack this problem and be reliable?
I asked my co-worker who is working directly on this topic, and he was extremely skeptical. To simplify (and possibly butcher) his explanation, the DFT functionals we use are smooth and simple, but the actual energy landscape is filled with jagged edges and discontinuities. If you replace the simple equation with some machine learned sludge, you introduce this jaggedness back in to the landscape, making it implausible to reliably find the global minimum. He suggested that the most plausible path forward was a mixed system, like machine learning just a few parameters for existing, well proven DFT techniques with smooth convergence.
It’s not the only technique out there: others, like the group from this paper, are using neural networks to directly solve the wavefunctions of the Schrodinger equation. I haven’t looked into this much, but it seems limited to small number of atoms (no more than 50 or so), but useful for certain properties that aren’t well captured by regular DFT. I’ll also note that while this seems like the type of thing well suited to quantum computing, someone asked the professor in charge of the project about it and they were very skeptical that it would actually help with the problem anytime soon.
ML for generation:
Okay, we can return now to the other high profile Deepmind setback. While it seems pretty clear that the automated synthesis lab was overhyped, that doesn’t necessarily mean the whole enterprise should be thrown out. In particular the first step, where ML is used to generate large numbers of potentially stable materials, is still an area of active study.
There are a few groups doing this, so I’ll just focus on the google one, Gnome, detailed in this article. The goal is to generate completely new crystal structures that are theoretically stable. The theoretical stability can be calculated using “convex hull” calculations. If I’m reading it right, Gnome uses DFT simulations to machine learn what type of structures are stable, then they use this machine learning algorithm to predict new materials, which they then in turn evaluate for stability using DFT. The ones that pass the stability test are placed into their database, which is available online. Using this, they produced 2.2 million theoretically stable materials.
How many of these would actually be stable if fabricated? That’s a good question that we don’t really know the answer to. Certainly some portion of them are not actually stable: These calculations are done using the cheapest form of DFT out there, and do not take into account some things that affect stability, like spin orbit coupling or the effect of finite temperature.
To validate the results, they claimed that 736 of the generated materials match with the experimental results compiled in the ICSD crystallography database, which was not used at all in training the model. For context, the ICSD contains roughly 300 thousand entries, and adds about 12000 entries a year. I honestly couldn’t figure out from the paper whether this 736 was matched from the entire database or just from the ones added since the last snapshot: either way the Gnome process is only capturing a fraction of the experimentally realizable materials out there. 2.2 million may sound like a lot of materials, but it’s a miniscule fraction of the number of possible materials that could exist.
The problem with testing these things experimentally is that just showing a chemist a crystal structure does not tell them how to actually synthesize the material. And even if you do synthesize something, it’s actually not at all easy to verify that you synthesized the correct thing. This is what this diss paper was pointing out: at least 40 out of the 43 supposedly novel materials were likely not the material they were claiming they were.
I’m probably sounding harsh here, but I don’t actually think this is a waste of time. I think it’s a good start for a high throughput screening process: you start with a shitty, fast simulation of a huge number of candidate materials, then throw away any material that is nowhere near the right ballpark for some figure of merit like material bandgap. Then you have less materials, so you can use a somewhat slower, more accurate method, and then filter with those results, and so on and so forth, until you have a handful of materials that you have modelled expensively with high accuracy, that match what you desire out of the material. I think AI could be quite useful here if you only use it in the early steps of the process, and avoid the pitfalls that Google fell into.
non-AI innovations:
There’s some cool stuff here, but I want to remind you that ML was only like 25% of the conference. To balance it out, I just want to give you some super broad tastes of other things unrelated to AI that are going on in the field that were presented at the conference:
- One group found a clever updating method for expensive “hybrid” molecular dynamics simulations, that sped up the results by a factor of 7.
- One group demonstrated a specially designed functional with incredibly high band gap accuracy, with a very low mean average error of only 0.07 eV.
- One group demonstrated a different type of special function that gave very good ionisation potential and bandgaps.
- One group unvealed a new technique to improve calculations of interactions between electrons and phonons(lattice vibrations), which are crucial for many material properties such as electronic mobility.
- Another group demonstrated a tutorial and code for using those electron phonon coupling to predict whether a material would be superconducting.
- Another group identified a strange property in a material from a regular DFT calculation, which upon further study yielded an entirely new phase of magnetism.
None of these used ML at all in their work, and there was some very impressive stuff in there.
Panel on AI and quantum computing.
During the conference, they conveniently held a panel specifically on the topic of the promise of AI as well as quantum computing. The panel was comprised of three eminent professors who lead massive research groups. M, G, and N.
On the whole, the professors were quite optimistic about AI in the field going forward. ML techniques were described as revolutionary, transformative, and a paradigm shift. Primarily they were impressed by the ML force potentials, which seem to be maturing pretty fast, but they were also interested in some of the other projects I mentioned above. All 3 professors mentioned MLFP when asked about promising AI avenues.
One of the professors mentioned that prospective PhD students are really focused on working on AI or quantum computing, which causes problems because they were less excited by both fields.
Quantum computing was basically laughed off as overhyped and useless. M said no effect on the field “in my lifetime” (he’s like, 50). N said it was “far away”, and G said it was “hype”, and that it is “absolutely not true” that QC material science will happen soon. They were very disdainful, and this matches what I’ve heard through the grapevine of the wider physics community: there is a large expectation that quantum computing is in a bubble that will soon burst.
M said not much is concrete about ML outside of force potentials. G said we are very far from understanding how to make a material from ML generator base. N was excited about spectral applications (which I didn’t cover here) and seemed more keen on ML in general. In general, there seems to be cautious optimism about the prospects for ML, tempered by a number of practical challenges with the methods.
There was a concern about lack of funding for the field in general, attributed to a lack of salesmanship for the problem: a little bemoaning that astrophysics people can get mass funding for telescopes, but there is comparitively little funding for trying to improve theoretical techniques that could actually be much more useful for practical industry.
When asked if AI was coming for “our jobs”, ie the role of computational material scientists, there was laughter in the conference hall. None of the panel thought there was any chance of AI replacement in the foreseeable future: M instead said that ML will just open up new opportunities and more jobs, by expanding the areas that ML could be universally deployed. One of the professors said that AI job loss was a concern for other areas of society, but not for our own.
What about LLMs and GenAI
Now you’ll note that basically none of the analysis above is about generative AI, the subject of most of the current day AI hype. This is because nobody actually mentioned it, except for as a joke. There were people using innovative ML architectures like transformers, of course, but no mentions of LLMs, AI image generation, etc. In this section, I’ll try and give a feeling for how GenAI is used in our field.
First, let’s dispense with AI art: it’s useless. I asked the Chatgpt image generator (DALL-E 3 I believe) to create an image of 3 p orbitals. This type of diagram is trivial and is all over the internet. Here’s the result:
After I begged it strenuously for just a textbook illustration of one p-orbital, it produced the following:
The image generator has access to all the p orbital images on the internet, so I’m actually baffled as to how it fucks up this badly. Perhaps experienced AI prompters could find a prompt to achieve this: but for someone like me it would take more time and effort than just drawing the diagram myself. And that’s just a well established orbital, there’s no way would I trust this to draw something unique and specific: which is the whole point of images in scientific papers.
Okay, let’s move on to Chatgpt and other AI chatbots: These are indeed in widespread use. However, they are almost exclusively used for very basic scripting and coding. The code quality in computational physics is already fairly poor, as we are often working with other peoples code and just modifying it or doing scripting on top: in this context chatbots are a more efficient alternative to asking questions on stack exchange. For example, I can ask it for the python code to generate a p orbital, it actually gives me working code and instructions to produce an image like the following:
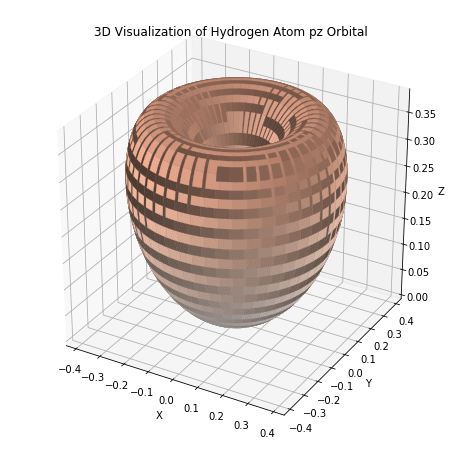
I mean, that’s not a p-orbital either, but we’re getting closer. If I turn on reasoning and ask for specifically the equation for a hydrogen p orbital, and then turn on reasoning and ask for python code to plot that orbital, I do get an actual working plot like the following:
Granted, I could easily find code online that does the same thing, but the Chatgpt route is often the faster option. And even if it’s somewhat wrong I can modify it. For basic tasks, it’s absolutely a time saver, and most people in my office are using it in this capacity.
I assume some non-native English speakers are also using it for grammar improvements. However, you should remember that every sentence is theoretically going to be looked at by a reviewer, so you don’t want to accidentally say something incorrect: academia often sacrifices readability for precision.
Lastly, people use it for grant applications and thing that are tedious but will not be published. Grant applications often already have plenty of bullshit, so it doesn’t matter as much if AI adds more.
If I ask it something more advanced, like writing basic input files for some less popular software, it starts making subtle errors and inventing flags that don’t exist (or were only in previous versions). Again, a useful tool for productivity boosting, as long as you are aware of it’s limitations, but it’s not something I would trust for critical simulations. These jobs can take days or even weeks to run fully: it’s incredibly important that the inputs be error-free, to a standard I would not trust to a contemporary chatbot.
I have also heard of specialized LLM systems being built for extracting information from the scientific literature. There are a huge amount of scientific papers out there, and it is often hard to sort through them for important results. For example if we want to find the experimental bandgap of a material, we have to rely on the whims of google scholar metrics and then follow citation chains: relevant papers that didn’t get cited much can often slip through the cracks. It seems promising that specially built AI could play a role in improving this search process, and I know a researcher working on this.
But will it come for our job later?
Now, it’s hard to deny that these tools are much, much, better than they were two years ago when they burst onto the scene. So how can most of our purely computational field, including me, be so confident that our jobs won’t be replaced in the future?
Agents
One reason AI hasn’t taken over yet is that while LLMs may be able to write a script, but it can’t actually run the code. This is the problem that “AI agents” are meant to solve: code that would hook up the output of LLMs to actual actions like running code. These agents are the newest hype, but are still fairly untested and their actual usefulness or effectiveness remains to be seen. Will AI agents radically change computational physics research?
When you think about the capabilities of future AI agents, you can picture some pretty complex and versatile tools. I asked Chatgpt to help come up with a pitch for an advanced material science tool, and here is an edited version of it’s response:
Imagine a tool that allows you to seamlessly build and execute complex, auto-documenting workflows across multiple computational codes, whether on local machines or remote high-performance clusters. A tool that could handle tens of thousands of processes per hour while ensuring check-pointing and reliability, featuring a flexible plugin interface, allowing you to integrate virtually any computational code, data analytics tool, or scheduler.
The tool works seamlessly with remote clusters and supporting all major HPC schedulers, allows you to export entire databases or selected data subsets for collaboration. The tool enables lightning-fast searches across millions of data points, giving you deep insights with ease. The tool works for heterogeneous computing environments, working seamlessly with remote clusters and supporting all major HPC schedulers. It allows you to export entire databases or selected data subsets for seamless collaboration—whether sharing with colleagues or making your results openly available through online repositories.
Stop for a second, and think about what actual effect you would expect such a tool to have on the computational physics ecosystem. Would it revolutionize the field?
I don’t think it would. A few years after such a tool is released, it would be considered useful, but the vast majority of working scientists would not use it, and it would have little effect on the pace of research.
I am 100% confident in the answer to the previous paragraph, for one simple reason:
This tool already exists.
The paragraph in italics above didn’t come from asking for an imagined future system: I actually just fed it the advertised features for the Aiida software and asked it to come up with a marketing pitch, then edited it down a bit. The software is already open source and free for anybody to use, and was released in 2020. As far as I know, it works fine, I haven’t really heard any problems with it.
Why would anyone go for an AI agent, with all it’s associated hallucinations and so on, when I could just use Aiida, which is repeatable, reliable, and has a dedicated userbase and support team?
And even the reliable Aiida isn’t that popular. I only saw a handful of posters at the conference that used it: I don’t use it either. Why? Because I don’t have that much computational resources, and I’m not studying that many different materials, and I’m not submitting that many computational jobs. An automated workflow would not save me much time overall, and I find it easier to keep track of what’s going on if I modify input files directly, rather than through an extra layer of abstraction. An extra layer of code gives an extra avenue for things to screw up and go wrong: and I have a set computational budget, so I can’t afford to risk it.
All the objections above would be just as salient, probably way more so, for an AI agent system. If I was forced to use LLMs to do this stuff, I would just ask Chatgpt for instructions on preparing Aiida scripts.
Complexity and language.
Someone might say that the advantage of LLMs, compared to something like Aiida, is that you can ask it what to do in ordinary language, rather than having to input it via code.
Unfortunately, for many problems, especially very complex problems, translating what you want to do into ordinary language is harder than just doing the damn thing yourself.
For a trivial example, take the code above to produce a pz orbital: If I wanted to change the isosurface values, I could copy paste the code back into chatgpt, ask it “please modify the code to increase the isosurface maximum to 0.08”, then copy the result back and run it.
Or… I could just change the isosurface value in the code from 0.04 to 0.08 and run it instantly.
A less trivial example: Say you want to place a defect in an approximate position relative to a lattice, like placing the black ball in the space shown below, relative to the purple balls (two different views shown).
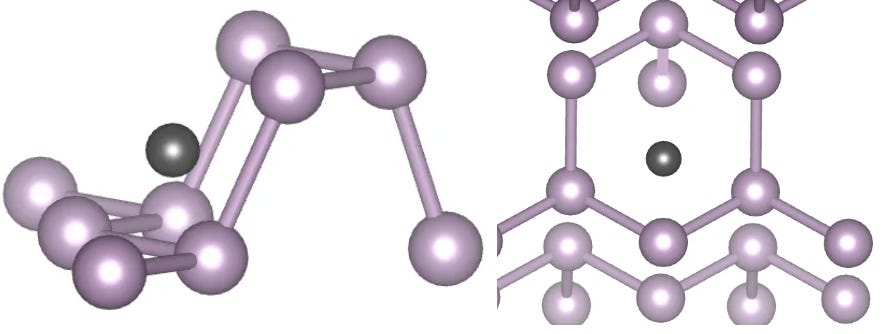
{kind=link}
I did this manually using a 3d atom visualisation tool called Vesta. I averaged the position of two atoms to get a starting point, then just nudged the position by shifting each coordinate until it looked like it was in the right spot. I timed it and it took like 2 minutes.
Trying to do the same thing with a chatbot felt like pulling teeth out. I ended up copy pasting the position of several atoms around the place, and awkwardly specifying the black balls position relative to them along several different axis directions. The process took 7 minutes, and involved doing most of the same steps as the previous process, just with an unnecessary AI middleman inserted into the process.
If you are trying to do code, usually the best and most efficient way to do code is to input code. If you are trying to do math, usually the best and most efficient way to do math is to input math. Beyond a certain level of competence, natural language is just massively inefficient for achieving precision tasks.
Black boxes
One of the professors on the panel pointed out that our field is actually pretty well prepared for AI systems: because we’re already used to dealing with black box calculations.
If you are doing a regular DFT simulation, you will input the structure you want to investigate, and feed it to a prebuilt DFT software package, which will take it and run an energy minimization algorithm using large matrices and linear algebra. It will then spit out your final structure and some material properties of interest such as material bandgap.
If in the future Deepmind or whatever comes up with a more efficient ML alternative to DFT, how would we use it? We would input our structure into Deepminds prebuilt ML software package, which would take it and run an ML minimization algorithm using large matrices and linear algebra, which will then spit out your final structure and some material properties of interest such as material bandgap.
So from our perspective, is there really much of a change?
The thing is, it’s not that hard to get a DFT calculation to run and to spit out a number for something like the bandgap of a new material. But just getting a number out isn’t that useful on it’s own: there are any number of ways that the resulting number could be spurious. The actual value of a researcher is their ability to interpret the results of the calculation, and to be able to tell if the number is a good simulation, or if something has gone horribly wrong along the way. A large part of that is being able to poke into all the data that is generated, and extracting sanity checks to ensure that nothing has gone terribly wrong, to do experiments to ensure that your convergence parameters are sufficiently high, etc. And the things you need to do are dependent on previous literature and the whims of the highly specific material you are studying.
Perhaps some of these steps could be automated by AI. But the only people who would know what to tell the AI to do are… us, the researchers. And as long as AI’s continue to hallucinate every once and a while, we’re the only ones who can tell you whether or not an AI calculation has screwed up, and where it did so. Machine learning is sometimes a case of stirring a pile of linear algebra until it starts looking right: but we need the physicist to be there to tell us what “looking right” even is.
Usefulness and hype:
The funding of academic research is not equal between fields. To get lots of funding, you need to be perceived as either useful for society (like medicine or renewable energy), or be seen as cool (particle physics, astronomy).
This applies to science funding from both government grants and from private companies. Companies will only fund it if they think there’s a chance of ultimate profit to be made out of it, and governments generally are wary of funding things which look too wasteful to the public.
As a result, scientists who are fully aware that their research will almost certainly have no effect on wider society still are somewhat obligated to shoehorn potential applications into grant applications.
The reason I bring this all up is that if AI enables a revolution in CEST, it is very likely to boost the real or perceived usefulness of our field as a whole, which in turn should boost the funding and demand for computational physicists.
So far from being scared about job loss, we should perhaps be hopeful for breakthroughs. I’m not saying the current state of the field is useless: there are large companies that hire people for DFT research. But there’d be a lot more of them if the field expanded it’s areas of effectiveness.
Fundamentals of science:
Sometimes people will point to the lack of major breakthroughs in fundamental physics and declare it’s the “end of physics” or whatever. This is a load of nonsense. We can see this CEST: This is a field where we know precisely the fundamental equations governing everything: but the actual knowledge resulting from this is locked away from us under the barrier of computational complexity.
Imagine if AI came up with a technique that made computational simulations run a hundred times faster across the board. Would this spell the end of the field? Of course not! Instead we’d get a massive flurry of activity as everybody mines the now low-hanging fruit as best as possible… and then we’d move on to new, more computationally complex challenges until we end up using up our computing quota again. The range of difficulty in physics problems is seemingly endless: there are plenty of simulation challenges that are barely even tried due to their difficulty.
Scientists live on the edge of scientific knowledge: if that edge expands, we simply move on to the new edge of knowledge. Until an AI can replace a scientist entirely, giving them super powerful tools will just boost the frontiers of science, with little effect on the scientists themselves. The main change would be a need for scientists to become more and more familiar with ML: but there are professors around who have been working in the field since before the world wide web: adaptation is a natural part of a scientific career.
And it’s worth saying: the emphasis on looking at new things, that haven’t been done before by anyone else ever, seems like it would be an area that LLM style learners will have difficulty breaking into. I don’t think it’s uncommon for scientists to run into problems unique to their specific niche subfield that have never been encountered by anybody else in human history. I can foresee a world where an AI is able to help a lot with these problem. I cannot foresee a world anytime soon where AI can solve these problems without an expert present.
General skepticism:
Now, one could say that the physicists will be replaced, because all of science will be replaced by an automated science machine. The CEO of a company can just ask in words “find me a material that does X”, and the machine will do all the necessary background research, choose steps, execute them, analyse the results, and publish them.
I’m not really sure how to respond to objections like this, because I simply don’t believe that superintelligence of this sort is going to happen anytime soon. AI companies are running out of easily scrapeable data, and seem to be running into diminishing returns. They also seem to be extremely unprofitable.
I’m not going to state any certainty that there will not be large improvements for AI in the next couple of years. But we need more than a large shift to think about replacing physicists: we need a gargantuan one, and that does not seem to be on the horizon.
More importantly, I think it’s impossible that such a seismic shift would occur without seeing any signs of it a computational physics conference. Before AGI takes over our jobs completely, it’s extremely likely that we would see sub-AGI partnered with humans, able to massively speed up the pace of scientific research, including the very hard parts, not just the low-level code. These are insanely smart people who are massively motivated to make breakthroughs through whatever means they can: if AI did enable massive breakthroughs, they’d be using it.
I’m not going to make any long term predictions, but in the next decade and probably beyond, I do not think we will see either of the above two cases coming to fruition. I think AI will remain a productivity tool, inserted to automate away parts of the process that are rote and tedious.
Conclusion:
This article contains an overview of AI in my field of computational atomic scale simulations (CEST)[4]. Let’s summarize what I covered here:
First, I explained that machine learning methods are very much not the standard at the moment. We know the fundamental equations, so we usually use solving methods that are informed by physics knowledge.
I covered two examples of people trying to disrupt the field with AI, which both were exposed later on as flops, although not worthless endeavors.
I showed that in a leading conference focused on methodology development of the field, about a quarter of the talks and posters were AI focused, with some interesting development particularly in the field of Machine learned force potentials, which allow for more accurate molecular simulations.
I covered a panel by leading experts in the field, who were excited about the potential for ML, but did not expect any of our jobs to be in danger: LLMs were largely absent from discussions and not thought highly of.
I then explained why I agree that our jobs are not really under threat: Existing AI is not particularly good and I’m skeptical they will get much better. It’s not actually very useful to use prompts to do scientific tasks rather than code, and high throughput “agents” already exist with regular, reliable coding methods.
Overall, I continue to view machine learning methods as fantastic tools with a lot of useful, practical applications, but they are far from a magic bullet that just solves all problems for you. AI art is useless. LLM’s continue to be primarily a productivity tool for low-level tasks, but potentially could branch out to other easy tasks, as long as you are aware of their limitations. I see no signs of a singularity coming for our field in the near future, and I don’t think material scientists of any kind should be concerned about AI job loss. Or at least, if our jobs are replaced, it will be with AI that is worse than us.
- ^
There’s a whole bunch of quantum stuff I’m leaving out here. I am not getting into quantum mechanic interpretations here because I value my sanity.
- ^
There are also plenty of failed functionals that are both not fast and not accurate, but they don’t get used much.
- ^
“TMC” refers to “transition metal compound”, the wider class of materials that they were testing it on.
- ^
Again, I invented this acronym, this field really needs a catchy name!
Do you think that it’s going to happen eventually? Do you think it might happen in the next 30 years? If so, then I think you’re burying the lede! Think of everything that “M, G, and N” do, to move the CEST field forward. A future AI could do the same things in the same way, but costing 10¢/hour to run at 10× speed, and thousands of copies of them could run in parallel at once, collectively producing PRL-quality novel CEST research results every second. And this could happen in your lifetime! And what else would those AIs be able to do? (Like, why is the CEO human, in that story?)
The mood should be “Holy #$%^”. So what if it’s 30 years away? Or even longer? “Holy #$%^” was the response of Alan Turing, John von Neumann, and Norbert Wiener, when they connected the dots on AI risk. None of them thought that this was an issue that would arise in under a decade, but they all still (correctly) treated it as a deadly serious global problem. Or as Stuart Russell says, if there were a fleet of alien spacecraft, and we can see them in the telescopes, approaching closer each year, with an estimated arrival date of 2060, would you respond with the attitude of dismissal? Would you write “I am skeptical of alien risk” in your profile? I hope not! That would just be crazy way to describe the situation viz. aliens!
I too think it’s likely that “real AGI” is more than 10 years out, and will NOT come in the form of a foundation model. But I think your reasoning here isn’t sound, because you’re not anchoring well on how quickly AI paradigm shifts can happen. Seven years ago, there was no such thing as an LLM. Thirteen years ago, AlexNet had not happened yet, deep learning was a backwater, and GPUs were used for processing graphics. I can imagine someone in 2000 making an argument: “Take some future date where we have AIs solving FrontierMath problems, getting superhuman scores on every professional-level test in every field, autonomously doing most SWE-bench problems, etc. Then travel back in time 10 years. Surely there would already be AI doing much much more basic things like solving Winograd schemas, passing 8th-grade science tests, etc., at least in the hands of enthusiastic experts who are eager to work with bleeding-edge technology.” That would have sounded like a very reasonable prediction, at the time, right? But it would have been wrong! Ten years before today, we didn’t even have the LLM paradigm, and NLP was hilariously bad. Enthusiastic experts deploying bleeding-edge technology were unable to get AI to pass an 8th-grade science test or Winograd schema challenge until 2019.
And these comparisons actually understate the possible rate that a future AI paradigm shift could unfold, because today we have a zillion chips, datacenters, experts on parallelization, experts on machine learning theory, software toolkits like JAX and Kubernetes, etc. This was much less the case in 2018, and less still in 2012.
Again, I'm not sure exactly how to respond to comments like this. Like, yeah, if AI could reliably do everything a top researcher does, it could enable a lot of breakthroughs. But I don't believe that an AI will be able to do that anytime soon. All I can say is that there is a massive gap between current AI capabilities and what they would need to fully automate a material science job. 30 years sounds like a long time, but AI winters have lasted that long before: there's no guarantee that because AI has rapidly advanced recently that it will not stall out at some point.
I will say that I just disagree that an AI could suddenly go from "no major effect on research productivity" to "automate everything" in the span of a few years. The scale of difficulty of the latter compared to the former is just too massive, and in all new technologies it takes a lot of time to experiment and figure out how to use it effectively. Ai researchers have done a lot of work to figure out how to optimise and get good at the current paradigm: but by definition, the next paradigm will be different, and will require different things to optimize.
Thanks for the reply!
I agree with “there’s no guarantee”. But that’s the wrong threshold.
Pascal’s wager is a scenario where people prepare for a possible risk because there’s even a slight chance that it will actualize. I sometimes talk about “the insane bizarro-world reversal of Pascal’s wager”, in which people don’t prepare for a possible risk because there’s even a slight chance that it won’t actualize. Pascal’s wager is dumb, but “the insane bizarro-world reversal of Pascal’s wager” is much, much dumber still. :) “Oh yeah, it’s fine to put the space heater next to the curtains—there’s no guarantee that it will burn your house down.” :-P
That’s how I’m interpreting you, right? You’re saying, it’s possible that we won’t have AGI in 30 years. OK, yeah I agree, that’s possible! But is it likely? Is it overwhelmingly likely? I don’t think so. At any rate, “AGI is more than 30 years away” does not seem like the kind of thing that you should feel extraordinarily (e.g. ≥95%) confident about. Where would you have gotten such overwhelming confidence? Technological forecasting is very hard. Again, a lot can happen in 30 years.
If you put a less unreasonable (from my perspective) number like 50% that we’ll have AGI in 30 years, and 50% we won’t, then again I think your vibes and mood are incongruent with that. Like, if I think it’s 50-50 whether there will be a full-blown alien invasion in my lifetime, then I would not describe myself as an “alien invasion risk skeptic”, right?
OK, let’s talk about 15 years, or even 30 years. In climate change, people routinely talk about bad things that might happen in 2055—and even 2100 and beyond. And looking backwards, our current climate change situation would be even worse if not for prescient investments in renewable energy R&D made more than 30 years ago.
People also routinely talk 30 years out or more in the context of science, government, infrastructure, institution-building, life-planning, etc. Indeed, here is an article about a US military program that’s planning out into the 2080s!
My point is: We should treat dates like 2040 or even 2055 as real actual dates within our immediate planning horizon, not as an abstract fantasy-land to be breezily dismissed and ignored. Right?
Yes, but 30 years, and indeed even 15 years, is more than enough time for that to happen. Again, 13 years gets us from pre-AlexNet to today, and 7 years gets us from pre-LLMs to today. Moreover, the field of AI is broad. Not everybody is working on LLMs, or even deep learning. Whatever you think is necessary to get AGI, somebody somewhere is probably already working on it. Whatever needs to be optimized for those paradigms, I bet that people are doing the very early steps of optimization as we speak. But the systems still work very very badly! Maybe they barely work at all, on toy problems. Maybe not even that. And that’s why you and I might not know that this line of research even exists. We’ll only start hearing about it after a lot of work has already gone into getting that paradigm to work well, at which point there could be very little time indeed (e.g. 2 years) before it’s superhuman across the board. (See graph here illustrating this point.) If you disagree with “2 years”, fine, call it 10 years, or even 25 years. My point would still hold.
Also, I think it’s worth keeping in mind that humans are very much better than chimps at rocketry, and better at biology, and better at quantum mechanics, and better at writing grant applications, and better at inventing “new techniques to improve calculations of interactions between electrons and phonons”, etc. etc. And there just wasn’t enough time between chimps and humans for a lot of complex algorithmic brain stuff to evolve. And there wasn’t any evolutionary pressure for being good at quantum mechanics specifically. Rather, all those above capabilities arose basically simultaneously and incidentally, from the same not-terribly-complicated alteration of brain algorithms. So I think that’s at least suggestive of a possibility that future yet-to-be-invented algorithm classes will go from a basically-useless obscure research toy to superintelligence in the course of just a few code changes. (I’m not saying that’s 100% certain, just a possibility.)
Interesting points, Steven.
I would say the median AI expert in 2023 thought the median date of full automation was 2073, 48 years (= 2073 - 2025) away, with a 20 % chance before 2048, and 20 % chance after 2103.
Automation would increase economic output, and this has historically increased human welfare. I would say one needs strong evidence to overcome that prior. In contrast, it is hard to tell whether aliens would be friendly to humans, and no past evidence based on which one can establish a strong pessimistic or optimistic prior.
I could also easily imagine the same person predicting large scale unemployment, and a high chance of AI catastrophes once AI could do all the tasks you mentioned, but such risks have not materialised. I think the median person in the general population has historically underestimated the rate of future progress, but vastly overestimated future risk.
Why use automation as your reference class for AI and not various other (human) groups of intelligent agents though? And if you use the later, co-operation is common historically but so are war and imperialism.
Thanks, David. I estimate the annual conflict deaths as a fraction of the global population decreased 0.121 OOM/century from 1400 to 2000 (R^2 of 8.45 %). In other words, I got a slight downwards trend despite lots of technological progress since 1400.
Even if historical data clearly pointed towards an increasing risk of conflict, the benefits could be worth it. Life expectancy at birth accounts for all sources of death, and it increases with real GDP per capita across countries.
The historical tail distribution of annual conflict deaths also suggests a very low chance of conflicts killing more than 1 % of the human population in 1 year.
I think you misunderstood David’s point. See my post “Artificial General Intelligence”: an extremely brief FAQ. It’s not that technology increases conflict between humans, but rather that the arrival of AGI amounts to the the arrival of a new intelligent species on our planet. There is no direct precedent for the arrival of a new intelligent species on our planet, apart from humans themselves, which did in fact turn out very badly for many existing species. The arrival of Europeans in North America is not quite “a new species”, but it’s at least “a new lineage”, and it also turned out very badly for the Native Americans.
Of course, there are also many disanalogies between the arrival of Europeans in the Americas, versus the arrival of AGIs on Earth. But I think it’s a less bad starting point than talking about shoe factories and whatnot!
(Like, if the Native Americans had said to each other, “well, when we invented such-and-such basket weaving technology, that turned out really good for us, so if Europeans arrive on our continent, that’s probably going to turn out good as well” … then that would be a staggering non sequitur, right? Likewise if they said “well, basket weaving and other technologies have not increased conflict between our Native American tribes so far, so if Europeans arrive, that will also probably not increase conflict, because Europeans are kinda like a new technology”. …That’s how weird your comparison feels, from my perspective :) .)
Hi there, I am a quantum algorithm researcher at one of the large startups in the field and I have a couple of comments, one to back up the conclusion on ML for DFT, and another to push back a bit on the quantum computing end
For the ML for DFT, one and a half years ago we tried (code here) to replicate and extend the DM21 work, and despite some hard work we failed to get good accuracy training ML functionals. Now, this could be because I was dumb or lacked abundant data or computation, but we mostly concluded that it was unclear how to make ML-based functionals work.
On the other hand, I feel this paragraph is a bit less evidence-based.
I think there are genuine reasons to believe QC can become a pretty useful tool once we figure out how to build large-scale fault-tolerant quantum computers. In contrast to logistics, finance, optimization, etc which are poor target areas for quantum computing, material science is where (fault-tolerant) quantum computing could shine brightest. The key reason is that we could numerically integrate the Schrodinger equation to large system sizes with polynomial scaling in the system size and polylogarithmic cost in the (guaranteed) precision, without the vast majority of the approximations needed in classical methods. I would perhaps argue that some of the following represent roughly the state of the art on the quantum algorithms we may be able to run:
The takeaway of these papers is that with a few thousand logical qubits and logical gates that run at MHz (something that people in the field believe to be reasonable), it may be possible to simulate relatively large correlated systems with high accuracy in times of the order of days. Now, there are of course very important limitations. First and foremost, you need some rough approximation to the ground state that we can prepare (here, here) and project with quantum computing methods. This limits the size of the system that we can model because there is a dependence on classical methods, but it extends the range of accurate simulations efficiently.
Second, as noted in the post, classical methods are pretty good are modeling ground state. Thus, it makes sense to focus most of the quantum computing efforts on modeling strongly correlated systems, excited states, or dynamic processes involving light-matter interaction and the sort. I would argue we still have not found good ways to go beyond the Born-Oppenheimer approximation though, except if you are willing to model everything (nuclei, electrons) in plane waves and first quantization, which is feasible but may make the simulation perhaps one or two orders of magnitude more costly.
This is all assuming fault-tolerant quantum computing. I can't say much on the timelines though because I am an algorithmic researcher so I do not have a very good understanding of the hardware challenges, but I would not find it unsurprising to see companies building fault-tolerant quantum computers with hundreds of logical qubits in 5 to 15 years from now. For example, people have been making good progress and Google recently showed the first experiment where they can reliably reduce the error with quantum error correction. The next step for them is to build a logical qubit that can be corrected for arbitrary time scales.
Overall, I think the field of fault-tolerant quantum computing is putting forward solid science, and it would be overly dismissive to say it is just hype, or a bubble.
Hey, thanks for weighing in, those seem like interesting papers and I'll give them a read through.
To be clear, I have very little experience in quantum computing, and haven't looked into it that much and so I don't feel qualified to comment on it myself (hence why this was just an aside there). All I am doing is relaying the views of prominent professors in my field, who feel very strongly that it is overhyped and were willing to say so in the panel, although I do not recall them giving much detail on why they felt that way. This matches with the general views I've had with other physicists in casual conversations. If I had to guess the source of these views, I'd say it was skepticism of the ability to actually build such large scale fault-tolerant systems.
Obviously this is not strong evidence and should not be taken as such.
I agree there is certainly quite a lot of hype, though when people want to hype quantum they usually target AI or something. My comment was echoing that quantum computing for material science (and also chemistry) might be the one application where there is good quality science being made. There are also significantly less useful papers, for example those related to "NISQ" (non-error-corrected) devices, but I would argue the QC community is doing a good job at focusing on the important problems, not just hyping around.
Thanks for this detailed overview; I've been interested to learn about AI for materials science (after hearing about stuff like Alphafold in biology), and this is the most detailed exploration I've yet seen.
Executive summary: AI has not taken over the field of computational electronic structure theory (CEST) in material science, with only selective applications proving useful, while attempts by major AI companies like DeepMind have largely failed; experts remain cautiously optimistic about AI’s potential but see no immediate risk of AI replacing human researchers.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.