We’re excited to announce the winners of the EA Criticism and Red Teaming Contest. We had 341 submissions and are awarding $120,000 in prizes to our top 31 entries.
We[1] set out with the primary goals of identifying errors in existing work in effective altruism, stress-testing important ideas, raising the average quality of criticism (in part to create examples for future work), and supporting a culture of openness and critical thinking. We’re pleased about the progress submissions to this contest made, though there’s certainly still lots of work to be done. We think the winners of the contest are both valuable in their own right as criticisms, and as helpful examples of different types of critique.
We had a large judging panel. Not all panelists read every piece (even among the winners), and some pieces have won prizes despite being read by relatively few people or having some controversy over their value. Particularly when looking at challenges to the basic frameworks of effective altruism, there can be cases where there is significant uncertainty about whether a contribution is ultimately helpful. But if it is, it’s often very important, so we didn’t want to exclude cases like this from winning prizes when they had some strong advocates.[2] You can read about our process and overall thoughts on the contest at the end of this post. Prize distribution logistics are also discussed at the end of this post.
An overview of the winners
- Top prizes [see more]
- A critical review of GiveWell's 2022 cost-effectiveness model and Methods for improving uncertainty analysis in EA cost-effectiveness models by Alex Bates (Froolow) ($25,000 total)
- Biological Anchors external review by Jennifer Lin ($20,000)
- Population Ethics without Axiology: A Framework by Lukas Gloor ($20,000)
- Second prizes (runners up) — $5,000 each [see more]
- Are you really in a race? The Cautionary Tales of Szilárd and Ellsberg by Haydn Belfield
- Against Anthropic Shadow by Toby Crisford
- An Evaluation of Animal Charity Evaluators by eaanonymous1234
- Red Teaming CEA’s Community Building Work by AnonymousEAForumAccount
- A Critical Review of Open Philanthropy’s Bet On Criminal Justice Reform by Nuño Sempere
- Effective altruism in the garden of ends by Tyler Alterman
- Notes on effective altruism by Michael Nielsen
- Honorable mentions — $1,000 for each of the 20 in this category [see more]

Top prizes
A critical review of GiveWell's 2022 cost-effectiveness model and Methods for improving uncertainty analysis in EA cost-effectiveness models by Alex Bates (Froolow[3]) ($25,000 prize in total)
We’re awarding a total of $25,000 for these two submissions by the same author covering similar ground. A critical review of GiveWell’s 2022 cost-effectiveness model is a deep dive into the strengths and weaknesses of GiveWell’s analysis, and how it might be improved. Methods for improving uncertainty analysis in EA cost-effectiveness models extracts some more generalizable lessons.[4]
Summary of A critical review of GiveWell’s 2022 cost-effectiveness model: The submission replicates GiveWell’s cost-effectiveness models, critiques their design and structure, notes some minor errors, and suggests some broader takeaways for GiveWell and effective altruism. The author emphasizes GiveWell’s lack of uncertainty analysis as a weakness, notes issues with the models’ architectures (external data sources appear as inputs on many different levels of the model, elements from a given level in the model “grab” from others on that level, etc.), and discusses ways in which communication of the models is confusing. Overall, though, the author seems impressed with GiveWell’s work.
You can also see the author’s own picture-based summary of their findings:
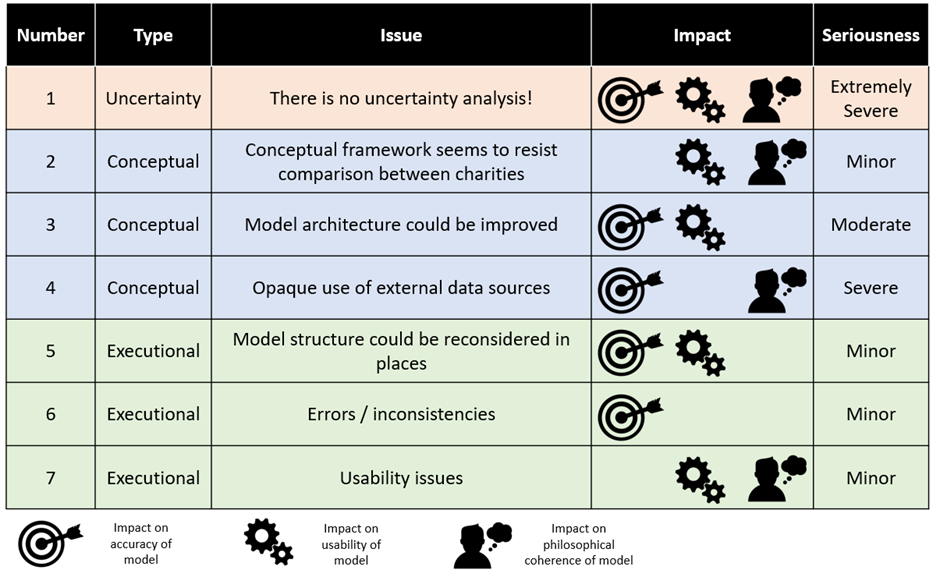
Summary of Methods for improving uncertainty analysis in EA cost-effectiveness models: This post argues that the EA community seriously undervalues uncertainty analysis in economic modelling (that a common attitude in EA is to simply plug in “best we can do” numbers and move on, whereas state-of-the-art models in Health Economics use specific tools for uncertainty analysis). The submission explains specific methods that should be applied in different cases, proposes that developing better tools for uncertainty modeling could be useful,[5] notes that a deep-dive into GiveWell’s model suggests that resolving “moral” disagreements is more impactful than resolving empirical disagreements, and generally shares a lot of expertise about different tools for uncertainty analysis. You can see the author’s summary of these tools here:

What we liked in these posts: The author was rigorous in trying to understand what is actually important (for GiveWell and for effective altruism more broadly).[6] They rebuilt GiveWell’s model, allowing them to understand critical inputs and features of the model and to suggest many concrete improvements.[7] These suggestions seem to focus on key weaknesses, not minor sidetracks that are unlikely to be decision-relevant. The author also made these posts an easy and enlightening experience for readers. The inclusion of clear and information-packed diagrams, and the addition of a second post explaining how people can approach such analyses in general, were both exemplary. We also appreciated that they drew out broader conclusions for effective altruism.
When we asked an external expert reviewer to assess these posts, they wrote:
It’s hard to overstate what a gift the author of this post has provided to GiveWell – replicating a complex model is tedious, time-consuming, and often thankless work.
(In case you’re considering contributing similar work, note that GiveWell recently announced the “Change Our Mind Contest” to encourage (more) critiques of their cost-effectiveness analyses.)
What we didn’t like: It’s not clear that GiveWell’s charity recommendations should change based on the submission’s findings (although the broader lessons seem important). Given this, some panelists worried that classifying the lack of uncertainty analysis as an “extremely severe” error is overstating things. And within EA, GiveWell is a strong example of the type of work that can most benefit from this type of analysis; it is unclear whether the lessons are meaningfully generalizable areas in which highly sophisticated measurement and quantification are less central.
Biological Anchors external review by Jennifer Lin ($20,000)
Summary: This is a summary and critical review of Ajeya Cotra’s biological anchors report on AI timelines.[8] It provides an easy-to-understand overview of the main methodology of Cotra’s report. It then examines and challenges central assumptions of the modelling in Cotra’s report. First, the review looks at reasons why we might not expect 2022 architectures to scale to AGI. Second, it raises the point that we don’t know how to specify a space of algorithmic architectures that contains something that could scale to AGI and can be efficiently searched through (inability to specify this could undermine the ability to take the evolutionary anchors from the report as a bound on timelines).
What we liked: AI timelines are important in a great deal of strategic thinking in EA, especially in the longtermist context, and Cotra’s report has become a standard reference, so reviewing it is engaging with central and sophisticated thinking in EA. Lin’s submission is clearly written despite being on a difficult technical topic, and we appreciated its straightforwardness about its own uncertainties and confusions. The critiques that it raises seem to be of central importance rather than just nitpicking or missing the point — if the biological anchors forecasts are misleading or uninformative, this may well be why. And the review provides suggestions for further research that could improve our understanding of these key uncertainties.
What we didn’t like: A lot of this review was focused on understanding which of Cotra’s arguments could be made most legible and strong. While this outlined important gaps in the arguments in Cotra’s report (explaining why readers are not compelled to adopt certain views on timelines), the submission didn’t really discuss how we could reasonably form certain important views on AI timelines (like the likelihood that small extensions of current architectures could scale to AGI, or how probable it is that the first few evolutionary approaches might contain something that works). While we admire the project of putting arguments on as firm foundations as possible (and attempting to undermine foundations others have proposed), we think this review could have done more to position itself to be helpful to people needing to make decisions in light of the current lack of fully-supported arguments.
Population Ethics without Axiology: A Framework by Lukas Gloor ($20,000)
Summary: Population ethics is relevant for decisions that could affect large groups of people, some of whom might or might not exist depending on our actions. It is usually discussed with axiologies – accounts of the objective good. Gloor introduces an alternative framework that considers population ethics from the perspective of individual decision-makers. He introduces the notion of minimal morality (“don’t be a jerk”) that all moral agents should follow, and proposes that what to do beyond that is up to the individual in important ways.
What we liked: This is an ambitious reconceptualization of a key field of ethics. It makes space to capture the powerful intuitions people often have that standard ethical discourse doesn’t allow room for. It proposes a conceptualization of person-affecting views which don’t have the same problems that these views are commonly understood to have (in axiological frameworks). And it provides space for scope-sensitive effective altruism to have moral force without that creating an overwhelming moral pressure to optimize.
What we didn’t like: This is very abstract and at times speculative. Although there are a few practical suggestions for how EA (especially longtermist EA) might present its ideas, these suggestions seem predicated on the ideas of the post being at least plausibly correct. It would have been nice to see a discussion of the likelihood that this framing would actually help people relate to EA ideas in healthier and more valuable ways.
Second prizes (runners up — $5,000 each)
Note: We didn’t deliberately select winners in different categories, but we wanted to structure this announcement post a bit (rather than just listing all the runners up in one large section). So for this post, we’re organizing them by their broad subject.
Critiques of specific concepts and assumptions
Are you really in a race? The Cautionary Tales of Szilárd and Ellsberg by Haydn Belfield
This post tells a compelling story of how even smart people with the best intentions can end up in a harmful arms-race dynamic, and extends this lesson to effective altruism and AI safety: “I am concerned that at some point in the next few decades, well-meaning and smart people who work on AGI research and development, alignment and governance will become convinced they are in an existential race with an unsafe and misuse-prone opponent.” (You can see a brief summary that goes into more detail here.)
We think many people might do well to internalize this point more strongly, and think the post helps by providing a clear example. We also loved the concrete description of a dynamic that could plausibly lead to an existential catastrophe and the fact that this description was grounded in a relevant historical analogy. On the other hand, we thought the post’s suggestions for the effective altruism community were vague, and it’s unclear to what extent its implicit recommendations are already understood.
Against Anthropic Shadow by Toby Crisford
This post digs into some toy examples to challenge the concept of anthropic shadow. This post argues that anthropics is not an important factor to adjust for in assessing the world we find ourselves in; it claims that people have fallen into the (oh-so-easy) trap of confusing themselves with arguments about the idea.
We liked how the post went step-by-step through the thinking to help the reader build intuitions about what’s going on, and we’d love to be able to throw away an unnecessary concept (which might plausibly be the right response here). On the other hand, the idea of anthropic shadow has always been a niche one, and we suspect it has a limited impact on actual prioritization decisions.
Criticisms of (work by) specific organizations
A note: This category is for critiques people have made of (important) organizations working in the EA space. We think outside scrutiny can be valuable. It can help alert organizations to their blindspots, and it can also help the broader community to understand the strengths and weaknesses of those organizations. At the same time, we’re aware that it’s a hard game to play since there’s often a lot of context outsiders aren’t aware of, so it can be unusually easy for them to miss the point. (In several of these cases one of the panelists had inside context which altered their perception of the criticism. However, they recognized a potential conflict of interest and recused themselves. For example, multiple panelists are affiliated with CEA.)
An Evaluation of Animal Charity Evaluators by eaanonymous1234
This post argues that Animal Charity Evaluators (ACE) communicates poorly about which charities it recommends, insufficiently evaluates charities across different types of interventions (thus losing information about big differences in impact), underrates the effectiveness of animal welfare reforms, and tries to fill too many roles at the same time. It also suggests some concrete improvements, like changes to the language on ACE’s website and a recommendation for ACE to pivot towards having more emphasis on producing original research (leaning into the “evaluator” side of its role) relative to functioning as a fund.
We were impressed by the level of detail in the post, its focus on big problems in ACE’s work and explanations of which issues it felt were more important, and the amount of constructive work done by the author (e.g. diving into research into animal welfare reforms and outlining how this compares to other interventions ACE recommends). On the other hand, we’re not sure how much of the post is novel. We’re also aware of minor errors in the post, like suggesting that an organization that disbanded in 2022 is able to take on some of the roles that ACE is currently holding.
Red Teaming CEA’s Community Building Work by AnonymousEAForumAccount
This post lists a number of issues found in different projects run by the Centre for Effective Altruism (CEA), like understaffing, a shortage of project evaluations, and poor public communications.
We were impressed by the thoroughness of the post, the fact that it was critically reviewing an influential organization, and the fair and constructive spirit of the post. We think it’s helpful to give the community the perspective of issues in a historical context, so they can better assess present and historical work. On the other hand, the recommendations err in the direction of generic, and since many of the issues it lists are from a past period of turbulence at CEA (which the post acknowledges), it’s unclear how actionable these elements of the critique still are.
A Critical Review of Open Philanthropy’s Bet On Criminal Justice Reform by Nuño Sempere
This post analyzes $200M in grants spent by Open Philanthropy on criminal justice reform, and estimates that these grants were worse than their other grants in global health and development. It then draws conclusions about Open Philanthropy’s policies and procedures and suggests some improvements.
We appreciated that the post built a rough (but useful) model for estimating the effectiveness of interventions for criminal justice reform, that it listed different reasons why Open Philanthropy might have made the grants in the first place (like value of information), that the errors it focuses on are major (cost-effectiveness of big grants), and that it targeted an extremely important entity in effective altruism — it’s a good example of hitting up. On the other hand, we think it’s possible that second-order effects might be especially important in US criminal justice reform (disagreeing with the author, who claims that they’re comparable to those of malaria prevention), and were disappointed that these were not considered in the analysis. At least one panelist felt that the arguments and conclusions in the section on why Open Philanthropy donated to criminal justice were overly speculative and insinuated more than was warranted.
Broad criticism of effective altruism as a phenomenon
Effective altruism in the garden of ends by Tyler Alterman
This post tells the story of the author’s journey through EA, and in particular into (and later out of) a totalizing consequentialist attitude. Even hardcore consequentialists will want to do lots of things that we regard as everyday goods because they are instrumentally useful. But the post warns us that approaching these things with an attitude of because they’re useful can lead to them being less useful, as we engage with them less wholeheartedly. (“By analogy, imagine (a) reading your favorite book for its own sake vs (b) reading the same book only to get an A+ on a test. You can feel what’s different about these experiences. What is it?”)
We liked the rich texture of the author’s account, and the conceptual underpinning offered for avoiding totalizing attitudes. The post is a clear account of how a highly involved person in EA became disillusioned. It also gives the historical example of JS Mill’s breakdown, which should be widely known since it prefigures a great deal of “EA disillusionment”. On the other hand, we weren’t very compelled by the alternative vision the author offers of how EA should work and felt that many of the recommendations were vague.
Notes on effective altruism by Michael Nielsen
This post cautions against new moral systems, describes a phenomenon of “EA judo” (whereby people in effective altruism respond to valid outside criticism by saying the critic has simply made the case for EA even stronger, by making EA more effective), and suggests ways for people in effective altruism to avoid “misery traps” — high levels of stress due to worries that one is living wrongly.[9]
We felt that this was a very strong holistic critique of effective altruism that approached EA with curiosity, knowledge, and a focus on significant problems (a number of which seemed not to have been discussed before). Several panelists have referred to “EA judo” multiple times since reading the post, and feel that it is putting words to an important phenomenon (that is relevant for discussions of criticism). We thought that the lack of suggestion of an alternative to EA (a lack the author acknowledges) made the post weaker. Several panelists also believe that some of the author’s points in the “Summing up” section were not well justified.

Honorable mentions ($1,000 for each of these 20 submissions)
Disclaimer: Some submissions below only got two scores from the panel. This means that many of the panelists have not vetted each submission, and this should not be viewed as a strong endorsement of the claims made (even more than for the winners above). These are organized by the type of criticism they represent (although we didn’t deliberately select winners in different categories — these all got rankings that made them honorable mentions).
Philosophical work
- Better vaguely right than precisely wrong in effective altruism: the problem of marginalism by Nicolas Côté and Bastian Steuwer
- We liked: the construction of a clear model that identifies interventions for which a classic approach of estimating value per additional unit of resources fails (because they have discontinuous benefits).
- We didn’t like: that this submission seems to conflate effective altruism with global health and development (or perhaps with GiveWell), and we thought that a number of points made were not very original (or were misguided, by criticizing something that wasn’t quite true).
- Wheeling and dealing: An internal bargaining approach to moral uncertainty by Michael Plant
- We liked: how it explored the intuitions for how moral bargaining might work while avoiding some of the traps people worry about.
- We didn’t like: that the post took a long time to get to its points and didn’t make it clear how its proposal differed from the parliamentary approaches that have been discussed a number of times before.
- Longtermism, risk, and extinction by Richard Pettigrew
- We liked: that the post introduced and clearly summarized important arguments against expected utility theory (in particular, by incorporating risk-aversion), which is very relevant to work inspired by longtermism.
- We didn’t like: that some of the premises seemed unconvincing and that the takeaways weren't very actionable (although future work might build on this paper).
- Existential risk pessimism and the time of perils by David Thorstad
- We liked: that it developed a concrete model for the value of the future, and drew implications for positions one would have to adopt to reach certain conclusions.
- We didn’t like: the lack of engagement with object-level reasons to find the assumptions reasonable or not. In fact, we thought the top comment on the post did a fantastic job of making these counterpoints, and we decided to award it an extra $1,000 prize (although the comment was not formally submitted to the contest, and the funds for this come from the Forum team’s budget).
- Prioritizing x-risks may require caring about future people by Eli Lifland
- We liked: that the post addressed a narrative that has been growing in influence — that the case for mitigating existential risks should be introduced without discussing the idea that future people have moral value — and pointed out serious mistakes (or misleading oversimplifications) in this idea.
- We didn’t like: that the numbers cited in the post were extremely rough — we felt like the post made its points too strongly given how fragile the numbers it used were.
- Critique of MacAskill’s “Is It Good to Make Happy People?” by Magnus Vinding
- We liked: that the post critiques an influential work and theory in effective altruism, and uses specific evidence against the theory.
- We didn’t like: as a comment points out, that some of the evidence is incredibly sensitive to different framings of a study. Some of the arguments presented were also not very new.
- Tensions between moral anti-realism and effective altruism by Spencer Greenberg
- We liked: that the post addresses a particular combination of beliefs that a group of people holds (and is explicit about addressing the post to this group of people), and that it draws out a potential contradiction while exploring other possible explanations.
- We didn’t like: that the conclusion is a little vague.
Climate change and energy issues
- The most important climate change uncertainty by cwa
- We liked: that it pushes back against the tendency in EA to focus mostly on extreme-warming scenarios (>6°C), outlining reasons for why most of the uncertainty comes from poor models of the effects of much more probable medium-warming scenarios. We also liked that the post notes potential points of disagreement and how they might affect readers’ conclusions.
- We didn’t like: that we’re more unsure than usual about whether the conclusions are accurate. For instance, a comment from John Halstead points to literature from climate economics that suggests that harms from medium-warming scenarios can be constrained (although this is disputed in further comments). We also appreciate this comment.
- The great energy descent (short version) - An important thing EA might have missed by Corentin Biteau
- We liked: that this makes the case for a really-big-if-true feature of the world that could impact a lot of EA prioritization.
- We didn’t like: that it seemed weak in its engagement with arguments about how the world might adapt to avoid the worst outcomes described (we recommend the top comments for more discussion of these issues).
Critiques of work by specific organizations
- Quantifying Uncertainty in GiveWell's GiveDirectly Cost-Effectiveness Analysis by Sam Nolan (Hazelfire[10])
- We liked: listing specific reasons for performing uncertainty analyses, developing one for GiveWell’s cost-effectiveness estimates for GiveDirectly, the use of this work to support future similar projects by demonstrating Squiggle’s capabilities, and the inclusion of some concrete takeaways (like the fact that GiveDirectly seems to perform better if a different utility measure is used).
- We didn’t like: that we’re not sure how decision-relevant the specific criticisms were (although the broader takeaways seemed useful), and, as a comment points out, that the analysis used some parameters that were out of distribution (numbers from the UK instead of numbers from LMICs, which we might expect to be very different).
- A philosophical review of Open Philanthropy’s Cause Prioritisation Framework by Michael Plant
- We liked: that it explicitly called out possible implicit assumptions and spelled out their implications; that it made concrete recommendations for possible alternate approaches.
- We didn’t like: that it said “I don’t understand what OP means by worldview so I’ll assume it means a set of philosophical assumptions” when this is at odds with how OP describes it (the interpretation is explicitly disavowed in the top comment).
- Deworming and decay: replicating GiveWell’s cost-effectiveness analysis by Joel McGuire, Samuel Dupret, and Michael Plant
- We liked: that this submission points out real issues; Alex Cohen responded on behalf of GiveWell, agreeing that incorporating decay more into their model would reduce the cost-effectiveness of deworming (they plan on conducting more research into this), and noting that making this change earlier would have redirected $2-8M in grants. (The comment notes that the submission will likely change some future funding recommendations and improve GiveWell’s decision-making, which seems like a strong positive signal.) We also liked the post’s discussion on reasoning transparency.
- We didn’t like: As the comment linked above notes, it’s unclear that the authors’ approach to incorporating decay is accurate (it might overestimate the effect of decay due to issues with measurement) — it seems like this could lead to systematic underestimation of the effectiveness of programs with long-term benefits (due to increased uncertainty).
- [A private submission] by Nuño Sempere
- We have discussed internally and with Nuño the fact that this submission is private, and are sufficiently compelled by the claim that keeping it private will lead to a better outcome than a public submission. The author has shared it directly with the organization in question.
- We have also encouraged Nuño to share how his critique has been addressed within 12 months, or to make his original piece public if its core claims have not been addressed by then.
Critiques of real-world dynamics in effective altruism
- Critiques of EA that I want to read by Abraham Rowe
- We liked: that this post lists many issues that could be quite serious and deserve more consideration, and that it inspired more discussion.
- We didn’t like: that the critiques are quite vague (which is natural, given that this is a list), that some were unoriginal, and that the critiques’ relative importance isn’t discussed in the post (i.e. the list is basically flat — it’s not clear what should be prioritized).
- EA Criticism: Vegan Nutrition by Elizabeth Van Nostrand
- We liked: that the submission identifies an extremely specific issue that seems potentially incredibly important (and like a bad sign about the community’s epistemics), and suggests a number of changes and projects that could help address the issue.
- We didn’t like: that it didn’t have an estimate of the potential harm from the lack of guidance for vegan nutrition in EA, and we’re not sure about some of the factual claims.
- Ways money can make things worse by Jan Kulveit
- We liked: that this is a pretty comprehensive list of issues that funders should potentially pay attention to.
- We didn’t like: that the post didn’t explain how some of the phenomena it lists could become real issues (it generally relied on “stylized examples”), or how likely it is that they’re happening.
- Senior EA 'ops' roles: if you want to undo the bottleneck, hire differently by AnonymousThrowAway
- We liked: that the post had extremely specific and actionable takeaways in an area that’s important for effective altruism (hiring).
- We didn’t like: that the takeaways from this post didn’t seem as novel or critical as some of the other winners.
- Criticism of EA Criticism Contest by Zvi
- We liked: that the submission criticizes a concrete thing (this competition) as a way to get at broader, often unspoken assumptions in the EA community. We particularly liked the list of 21 implicit assumptions as a jumping-off point for discussion.
- We didn’t like: that the post is long, a bit convoluted, and doesn't make concrete recommendations that many in the EA community are likely to find actionable. And many on our panel disagreed with the object-level claims about criticism.[11]
- Leaning into EA Disillusionment by Helen
- We liked: that this post describes (and names) a real and under-discussed phenomenon, and suggested actions members of the community could take to improve (e.g. maintaining non-EA connections, viewing EA-the-community as only one of the possible paths to impact, notice disagreements and areas where you’re uncomfortable with something).
- We didn’t like: large parts of this post were pretty vague, and some of the ideas were not very new.
- Aesthetics as Epistemic Humility by Étienne Fortier-Dubois
- We liked: that it identified a potentially important blindspot for EA (aesthetics), noted that it’s a symmetric weapon, and suggested a number of specific reasons that aesthetics could be important (and flagged pitfalls for those in EA who might start paying attention to aesthetics).
- We didn’t like: that a number of claims seemed unjustified or too strong and some key arguments seemed incorrect.

Notes on the judging process
We got more submissions than we were expecting — 341 submissions (105 of which were submissions via the form). A few of them were entirely private (we’re awarding one private prize, listed above). Some submissions (about 45) were disqualified, usually for being written earlier than our March cutoff. Approximately 60 submissions became finalists.[12] Panelists cast nearly 800 votes across the 341 submissions (all submissions got at least 2 votes, and top and second prizes got at least 4). When we were out of our depth, we tried to reach out to experts in relevant fields. We also tried to discuss disagreements on the panel as much as possible, but a number of disagreements about which submissions we should reward were unresolved, so the fact that we’re awarding a prize does not mean that everyone on the panel endorses the submission.
After the original announcement, one panelist (Nicole Ross) had to step down from the panel due to other commitments. Because of this and the volume of submissions we got, we invited two other people to join the panel: Aaron Gertler and Bruce Tsai. I’m extremely grateful to everyone who spent time and energy making this happen, and I want to give a special shout-out to Gavin Leech and Bruce Tsai, who collectively gave more than a quarter of the total panelist scores.
How winners will get their prizes
We’ll be emailing or messaging all winners (and referrers, when relevant) about how they should claim their prizes. If you haven’t been contacted by October 8 and you think you should have gotten a prize, please email forum@centreforeffectivealtruism.org.
We don’t plan to reach out to people who did not get prizes.
Closing thoughts
It was fascinating to see the wide range of criticisms that people submitted to this contest. There were many submissions that we felt could have been finalists, and multiple panelists remarked that they learned something important from a post that didn’t end up getting a prize. And although we tried to be critical in our reviews, we were impressed by the quality of the winning submissions. It’s been touching to see people who clearly care deeply about effective altruism put so much into suggesting how it could be even better.
Although we didn’t ask for submissions in particular categories, we did find that there was some natural clustering into similar types of work.[13] We are slightly more confident in our comparisons within clusters than between clusters.
We also want to note that we deeply appreciate a lot of the projects (ranging from research to the work that organizations in effective altruism do) that got criticized by the winning submissions. We hope that readers don’t come away with the sense that everything that got criticized by a winning entry in this contest is bad — we think everything criticized here has some flaws, but to a first approximation everything has flaws, and when things are valuable enough it’s worth taking the time to identify and learn from those flaws (in practice that sometimes means fixing the issues, and sometimes throwing things away and starting again). Moreover, there are some laudable qualities that a certain project can have that make it more amenable to (especially useful) criticism, like reasoning transparency and epistemic legibility. (We think that GiveWell is a good example of this.)
Of course, the existence of criticism (and the selection of some especially high-quality criticism) doesn’t solve all our problems. Most importantly, criticisms are only useful if they lead to actual changes and improvements.
So we would be excited to see changes in response to these criticisms. (These could be changes suggested by submissions to the contest, changes that are prompted by submissions’ identification of certain issues — even if the people running the relevant projects disagree with the recommendations made by submissions, or other kinds of changes entirely.) Changes could include:
- Corrections of concrete errors listed in the winning submissions (e.g. faults in models, confusing language, incorrect research conclusions, etc.)
- Shifts in mindset of people in EA
- Shifts in prioritization decisions (by organizations and by individuals)
- Development of more uncertainty analyses for important research in EA
- Better feedback loops[14]
Finally, one of our goals was to accelerate meaningful discussion in these areas, and (of course) awarding the critiques funding does not mean we think they are entirely correct or the final word on the subject. So we strongly encourage further discussion on the topics brought up by the criticisms we’re highlighting here.
Thank you all so much!

- ^
This announcement was written by Lizka, with significant help from Owen Cotton-Barratt and more help from Bruce Tsai, and Fin Moorhouse. Other panelists got the chance to review it and some shared feedback, but most didn't have time to read it carefully. In general, views stated here do not represent views of everyone on the panel.
- ^
In particular, we wanted to avoid vetoes, or rewarding submissions that satisfied everyone, which would bias us towards uncontroversial submissions.
- ^
These were published under the name “Froolow,” and we learned the author’s real name after scoring was over.
- ^
We think that each post was individually very valuable, and having both adds to this — but is less than twice as valuable, as the posts cover similar ground. We have therefore decided to award a prize to this pair equal to the sum of a first ($20,000) and second ($5,000) prize.
- ^
Like the new programming language for probabilistic estimation, Squiggle.
- ^
We were also impressed by the fact that the author — a self-described relative outsider to EA — first posted a question on the Forum to make sure that they’d avoid straw-manning the “state of the art” in EA cost-effectiveness analysis and check that GiveWell’s models are the best thing to critique. We think this is a brilliant example to follow.
- ^
These suggestions included adding an uncertainty analysis, developing a system for prioritizing key inputs in their models (which would make it clearer which data is most important to check more carefully) [1], and re-organizing the presentation of their data, e.g. by fixing inconsistent markup in important sheets [2].
- ^
Here’s a summary of the original report: Forecasting transformative AI: the "biological anchors" method in a nutshell
- ^
Readers who are interested in this submission might also benefit from listening to this podcast episode: A podcast episode exploring critiques of effective altruism (with Michael Nielsen and Ajeya Cotra)
- ^
This was published under the name “Hazelfire,” and we learned the author’s real name after scoring was over.
- ^
Many members of the panel don't agree with a number of the claims the post makes (though opinions were divided), including the list of 21 assumptions. For an alternative take on criticisms, see Criticism Of Criticism Of Criticism. While we recused panelists with a conflict of interest for other posts, we were unable to do that in this case (since all panelists had a conflict of interest, by definition) but at least one panelist did recuse themselves.
- ^
We don’t plan on publishing a full list of finalists, as we haven’t vetted these submissions enough for us to feel comfortable highlighting them so prominently. However, I (Lizka) encourage panelists to share any submissions they particularly liked in the comments of this post.
You can also see a lot of the submissions here.
- ^
One panelist speculates that there was a negative correlation between how much pieces criticized the foundational assumptions of EA, and how much they made crisp or actionable recommendations. They thought this may be because there is a lot of work required for deriving clear actions as well as for laying new foundations, so it’s rare to see a piece do both.
- ^
Including for this contest; we’d love to hear general feedback, and are also interested in hearing about any cases where a submission (or our reviews) changed your mind or actions. You might also want to tell the author(s) of the submission if this happens.
- ^
This is a link to a public Google Document.
What would have been really interesting is if someone wrote a piece critiquing the EA movement for showing little to no interest in scrutinizing the ethics and morality of Sam Bankman-Fried's wealth.
To put a fine point on it, has any of his wealth come from taking fees from the many scams, Ponzi schemes, securities fraud, money laundering, drug trafficking, etc. in the crypto markets? FTX has been affiliated with some shady actors (such as Binance), and seems to be buying up more of them (such as BlockFi, known for securities fraud). Why isn't there more curiosity on the part of EA, and more transparency on the part of FTX? Maybe there's a perfectly good explanation (and if so, I'll certainly retract and apologize), but it seems like that explanation ought to be more widely known.
Someone has written something related: https://medium.com/@sven_rone/the-effective-altruism-movement-is-not-above-conflicts-of-interest-25f7125220a5
Just also want to emphasise Lizka's role in organising and spearheading this, as well as her conscientiousness and clear communication at every step of the process - I've enjoyed being part of this, and am personally super grateful for all the work she has put into this contest.
Enormous +1
As requested, here are some submissions that I think are worth highlighting, or considered awarding but ultimately did not make the final cut. (This list is non-exhaustive, and should be taken more lightly than the Honorable mentions, because by definition these posts are less strongly endorsed by those who judged it. Also commenting in personal capacity, not on behalf of other panelists, etc):
Bad Omens in Current Community Building
I think this was a good-faith description of some potential / existing issues that are important for community builders and the EA community, written by someone who "did not become an EA" but chose to go to the effort of providing feedback with the intention of benefitting the EA community. While these problems are difficult to quantify, they seem important if true, and pretty plausible based on my personal priors/limited experience. At the very least, this starts important conversations about how to approach community building that I hope will lead to positive changes, and a community that continues to strongly value truth-seeking and epistemic humility, which is personally one of the benefits I've valued most from engaging in the EA community.
Seven Questions for Existential Risk Studies
It's possible that the length and academic tone of this piece detracts from the reach it could have, and it (perhaps aptly) leaves me with more questions than answers, but I think the questions are important to reckon with, and this piece covers a lot of (important) ground. To quote a fellow (more eloquent) panelist, whose views I endorse: "Clearly written in good faith, and consistently even-handed and fair - almost to a fault. Very good analysis of epistemic dynamics in EA." On the other hand, this is likely less useful to those who are already very familiar with the ERS space.
Most problems fall within a 100x tractability range (under certain assumptions)
I was skeptical when I read this headline, and while I'm not yet convinced that 100x tractability range should be used as a general heuristic when thinking about tractability, I certainly updated in this direction, and I think this is a valuable post that may help guide cause prioritisation efforts.
The Effective Altruism movement is not above conflicts of interest
I was unsure about including this post, but I think this post highlights an important risk of the EA community receiving a significant share of its funding from a few sources, both for internal community epistemics/culture considerations as well as for external-facing and movement-building considerations. I don't agree with all of the object-level claims, but I think these issues are important to highlight and plausibly relevant outside of the specific case of SBF / crypto. That it wasn't already on the forum (afaict) also contributed to its inclusion here.
I'll also highlight one post that was awarded a prize, but I thought was particularly valuable:
Red Teaming CEA’s Community Building Work
I think this is particularly valuable because of the unique and difficult-to-replace position that CEA holds in the EA community, and as Max acknowledges, it benefits the EA community for important public organisations to be held accountable (and to a standard that is appropriate for their role and potential influence). Thus, even if listed problems aren't all fully on the mark, or are less relevant today than when the mistakes happened, a thorough analysis of these mistakes and an attempt at providing reasonable suggestions at least provides a baseline to which CEA can be held accountable for similar future mistakes, or help with assessing trends and patterns over time. I would personally be happy to see something like this on at least a semi-regular basis (though am unsure about exactly what time-frame would be most appropriate). On the other hand, it's important to acknowledge that this analysis is possible in large part because of CEA's commitment to transparency.
I suspect that Bad Omens will be looked back on as a highly influential post, and certainly has changed my mind more than any other community building post.
I agree with you on the Bad Omens post.
My thoughts and picks from judging the contest.
Many of my picks narrowly missed prizes and weren't upvoted much at the time, so check it out.
Personal highlights from a non-consequentialist, left-leaning panelist
(Cross-posted from Twitter.)
Another judge for the criticism contest here - figured I would share some personal highlights from the contest as well! I read much fewer submissions than the most active panelists (s/o to them for their hard work!), but given that I hold minority viewpoints in the context of EA (non-consequentialist, leftist), I thought people might find these interesting.
I was initially pretty skeptical of the contest, and its ability to attract thoughtful foundational critiques. But now that the contest is over, I've been pleasantly surprised!
To be clear, I still think there are important classes of critique missing. I would probably have framed the contest differently to encourage them, perhaps like what Michael Nielsen suggests here:
I also basically agree with the critiques made in Zvi's criticism of the contest. All that said, below are some of my favorite (1) philosophical (2) ideological (3) object-level critiques.
(1) Philosophical Critiques
Lukas Gloor's critique of axiological thinking was spot-on IMO. It gets at heart of why utilitarian EA/longtermism can lead to absurd conclusions, and how contractualist "minimal morality" addresses them. I think if people took Gloor's post seriously, it would strongly affect their views about what it means to "do good" in the first place: In order to "not be a jerk", one need not care about creating future happy people, whereas one probably should care about e.g. (global and intergenerational) justice.
I also liked this critique of several EA arguments for consequentialism by Will MacAskill and AFAIK shared by other influential EAs like Holdern Karnofsky and Nick Beckstead. Korsgaard's response to Parfit's argument (against person-affecting views) was new to me!
Speaking of non-consequentialism, this one is more niche, but William D'Alessandro's refutation of Mogensen & MacAskill's "paralysis argument" that deontologists should be longtermists hit the spot IMO. The critique concludes that EAs / longtermists need to do better if they want to convince deontologists, which I very much agree with.
A few other philosophical critiques I've yet to fully read, but was still excited to see:
(2) Ideological Critiques
I'm distinguishing these from the philosophical critiques, in that they are about EA as a lived practice and actually existing social movement. At least in my experience, the strongest disagreements with EA are generally ideological ones.
Unsurprisingly, there wasn't participation from the most vocal online critics! (Why make EA better if you think it should disappear?) But at least one piece did examine the "EA is too white, Western & male" and "EA is neocolonialist" critiques in depth:
The piece focuses on GiveWell and how it chooses "moral weights" as a case study. It then makes recommendations for democratizing ethical decision-making, power-sharing and increasing relevant geographic diversity.
IMO this was a highly under-rated submission. It should have gotten a prize (at least $5k)! The piece doesn't say this itself, but it points toward a version of the EA movement that is majority non-white and non-Western, which I find both possible and desirable.
There was also a slew of critiques about the totalizing nature of EA as a lived practice (many of which were awarded prizes):
I particularly liked this critique for being a first-person account from a (formerly) highly-involved EA about how such totalizing thinking can be really destructive.
I also appreciated Michael Nielsen's critique, which discusses the aforementioned "EA misery trap", and also coins the term "EA judo" for how criticisms of EA are taken to merely improve EA, not discredit it.
A related piece is about disillusionment with EA, and how to lean into it. I liked how it creates more space for sympathetic critics of EA with a lot of inside knowledge - including those of us who've never been especially "illusioned" in the first place!
That's it for the ideological critiques. This is the class of critique that felt the most lacking in my opinion. I personally would've liked more well-informed critiques from the Left, whether socialist or anarchist, on terms that EAs could appreciate. (Most such critiques I've seen are either no longer as relevant or feel too uncharitable to be constructive.)
There was one attempt to synthesize leftism and EA, but IMO not any better than this old piece by Joshua Kissel on "Effective Altruism and Anti-Capitalism". There have also been some fledgling anarchist critiques circulating online that I would love to see written up in more detail.
(And maybe stay tuned for The Political Limits of Effective Altruism, the pessimistic critique I've yet to write about the possibility of EA ever achieving what mass political movements achieve.)
(3) Object-Level Critiques
On AI risk, I'd be remiss not to highlight Jennifer Lin's review of the influential Biological Anchors report on AI timelines. I appreciated both the arguments against the neural network anchor, and the evolutionary anchor, and have become less convinced by the evolutionary anchor as a prediction for transformative AI by 2100.
I also appreciated James Fodor's critique of AI takeover scenarios put forth by influential EAs like Holden Karnofsky and Ajeya Cotra. I share the skepticism about the takeover stories I've seen so far, which have often seemed to me way too quick and subjective in their reasoning.
And of course, there's Haydn Belfield's cautionary tale about how nuclear researchers mistakenly thought they were in an arm's race, and how the same could happen (has happened?) with the race to "AGI".
Outside of AI risk, I was glad to see this piece on climate change get an honorable mention! It dissects the disconnect between EA consensus and non-EAs about climate risk, and argues for more caution. (Disclosure: This was written by a friend, so I didn't vote on it.)
Finally, I also appreciated this extensive critique of CEA's community-building work. I've yet to read it in full, but it resonates with challenges working with CEA I've witnessed while on the board of another EA organization.
There's of course tons more that I didn't get the chance to read. I wish I'd had the time! While the results of the contest of won't please everyone - much less the most trenchant EA critics - I still think the world is still better for it, and I'm now more optimistic about this particular contest format and incentive scheme than I was previously.
The BioAnchors review by Jennifer Lin is incredible. Has it ever been shared as an independent post to LessWrong or EAF? I think many people might learn from it, and further discussion could be productive.
Hi, I'm the author of the piece. Thanks for the kind comment! I planned to share it on LW/AF after finishing a companion piece on the work by Roberts et al. that I use in the technical section, and I fell a bit behind schedule on writing the second piece, but I'll put both on LW/AF next week.
+1 for posting!
I would weakly recommend posting immediately, given most of the site hits on this criticism contest may be over the next few days. So you might get more engagement if you post now. Can always post the second piece later.
Thanks, that's a good point. Just posted it here: https://www.lesswrong.com/posts/TMHWfRE7zZkzgFDSo/a-review-of-the-bio-anchors-report
This is Miranda Kaplan, a communications associate at GiveWell. We want to thank everyone who submitted reviews of GiveWell's analyses as contest entries! It's extremely valuable to us when people outside our organization engage deeply and critically with our work. We will always do our best to consider and respond to such critiques, though, given other pressures on staff time, we may not be able to publish a full response.
Although CEA's done it in the post above, we'll take this opportunity to again plug our Change Our Mind Contest, which closes on October 31. Entries submitted to the Criticism and Red Teaming Contest are eligible, as long as they meet all other Change Our Mind Contest requirements (described here). We look forward to reading your work and thank you in advance for your participation!
Thanks for launching the contest!
It will be interesting to dig through this list and read through these posts, many seem to raise good points.
As the writer of the post (well, 4 of them) on energy depletion, I will try to integrate the feedback you gave here. I shall make a follow-up post addressing the common counters given against claims of energy depletion, then - and explain why I'm still worried about this topic in spite of that. While I think that societies will try to adapt, my biggest concern is that there will be little time to transition if peak oil is already past us (a likely possibility). I will try to express more clearly why I think this way.
Glad to see your great posts about energy depletion in this list! Congratulations.
Thanks !
Congratulations, Corentin! Having just read part 1 in detail, I'm looking forward to more of your material.
Time and scale, as you said are the biggest concerns around adaptation. A virtue of not adapting with new infrastructure is that we save on carbon and energy put toward creating that infrastructure. Conservation could help more than anyone else believes, but it's the least sexy approach. I want to comment on these issues, but now I don't know where. Should I comment on the part 2 post, or in the google doc, or on the short contest version post?
Thanks for the feedback!
Yeah, I'd really like conservation of energy to take place, using only what we really need. Unfortunately, we are in an economic system that values using something as precious as oil as fast as possible in order to grow - meaning it will be harder for future generations to produce stuff like mosquito nets, antiseptics or aspirin, as they are all derived from oil. I talk about it in part 3.
For comments, it depends. For general comments that everyone could find more interesting, the summary post is probably more adapted (probably where conservation could go). For comments related more particularly to data related to one topic (transition or the economy or actions), then go part 1/2/3. If you think there is a useful comment to make in the Google Docs, go ahead because it allows to target specifically one sentence in particular.
OK, I will put my conservation thoughts in the comments of the summary post.
The speed of posting and conversation changes on this forum is way faster than I can match, by the time I have something decent written up, conversation will have moved on.
Keep an eye out for my reply though, I'll come around when I can. Your work on this parallels a model I have of a pathway for our civilization coping with global warming. I call it "muddling through." I know, catchy, right? How things go this century is very sensitive to short time scales, I'm thinking 10-20 year differences make all kinds of difference, and in my view, most needed changes are in human behavior and politics, not technology developments. So, good and bad.
Ok, take your time !
I think the next 10-20 years will indeed be decisive. And yes, most needed changes are in human behavior and politics, not technology development. Reminds me of an essay called "There's no App for That" by Richard Heinberg, where he exposes that, for problems of climate, energy, inequality of biodiversity loss :
Hi, Lizka.
I'm curious about your mention of reviews. Were reviews written for each contest submission?
I think she means the little blurbs in this post.
oohh, got it. thx.
This is very useful both for the content and for examples of how to effectively structure constructive criticism. Will there be a write up on lessons learned from the contest?
I think that could be quite useful as well since there is interest in running more contests, like the FTX FF AI Worldview Prize.
Here's mine
Wow, I'm glad I noticed Vegan Nutrition in among the winners. Many thanks to Elizabeth for writing, and I hope it will eventually appear as a post. A few months ago I spent some time looking around the forum for exactly this and gave up—in hindsight, I should've been asking why it didn't exist!
There is a full post planned, but I wanted actual data, which means running nutrition tests on the population I think is hurting, treating any deficiencies, and retesting. I have a grant for this (thanks SFF!) but even getting the initial tests done is taking months so the real post is a very long ways out.
PS. I have no more budget to pay for tests but if anyone wants to cover their own test ($613, slightly less if you already have or want to skip a genetic test) and contribute data I'd be delighted to have you. Please PM me for details.
Some of the winning entries from the EA Criticism and Red Teaming Contest have now been narrated:
You can listen via the [EA Forum Podcast](https://forum.effectivealtruism.org/posts/K5Snxo5EhgmwJJjR2/announcing-audio-narrations-of-ea-forum-posts-1) or on the individual post pages themselves.
I'm concerned my entry was not read. I submitted via the form. I pointed out two typos on a particular EA website (not as part of my criticism but clearly and prominently attached as an aside) and one was fixed and one was not. Since one was fixed I assume someone else pointed that one out. The typo is not ambiguously wrong so there would be no reason not to fix it.
Hey anonagainanon, if you DM me I can look into this for you.
I have lots of questions about the paper “Biological Anchors external review”.
I think this paper contains a really good explanation of the biological anchors and gives good perspective in plain English.
But later in the paper, the author seems to present ideas that seem briefly handled, and to me they appear like intuitions. Even if these are intuitions, these can be powerful, but I can’t tell how insightful they really are with the brief explanation given, and I think they need more depth to be persuasive.
One example is when the author critiques using compute and evolutionary anchors as an upper bond:
(Just to be clear I don’t actually read any of the relevant papers and I just guess the content based on the title) but the only way I can imagine “biological anchors” can be used is as a fairly abstract model, a metaphor, really.
People won't really simulate a physical environment and physical brains literally. In a normal environment, actual evolution rarely selects for “intelligence” (no mutation/phenotype, environment has too many/no challenges). So you would skip a lot of features, and force mutation and construct challenges. I think a few steps along these lines means the simulation will use abstract digital entities, and this would be wildly faster.
It seems important to know more about why the author thinks that more literal, biological brains need to be simulated. This seems pretty core to the idea of her paper, where she says a brain-like models needs to be specified:
But I think it’s implausible to expect a brain-like model to be the main candidate to emerge as dangerous AI (in the AI safety worldview) or useful as AGI for commercial reasons. The actual developed model will be different.
Another issue is that (in the AI safety worldview) specifying this “AGI model” seems dangerous by itself, and wildly backwards for the purpose of this exercise. Because of normal market forces, by the time you write up this dangerous model, someone would be running it. Requiring to see something close to the final model is like requiring to see an epidemic before preparing for one.
I don’t know anything about machine learning, AI or math, but I’m really uncertain about the technical section in the paper, on “Can 2020 algorithms scale to TAI?.”
One major issue is that in places in her paper, the author expresses doubt that “2020 algorithms” can be the basis for computation for this exercise. However, she only deals with feed forward neural nets for the technical section.
This is really off to leave out other architectures.
If you try using feed forward neural nets, and compare them to RNN/LSTM for things like sequence like text generation, it’s really clear they have a universe of difference. I think there’s many situations where you can’t get similar functionality in a DNN (or get things to converge at all) even with much more "compute"/parameter size. On the other hand, plain RNN/LTSM will work fine, and these are pretty basic models today.
Hi Charles, thanks for all the comments! I'll reply to this one first since it seems like the biggest crux. I completely agree with you that feedforward NNs != RNN/LSTM... and that I haven't given a crisp argument that the latter can't scale to TAI. But I don't think I claim to in the piece! All I wanted to do here was to (1) push back against the claim that the UAT for feedforward networks provides positive evidence that DL->TAI, and (2) give an example of a strategy that could be used to argue in a more principled way that other architectures won't scale up to certain capabilities, if one is able to derive effective theories for them as was done for MLPs by Roberts et al. (I think it would be really interesting to show this for other architectures and I'd like to think more about it in the future.)
Is the UAT mentioned anywhere in the bio anchors report as a reason for thinking DL will scale to TAI? I didn't find any mentions of it quickly ctrl-fing in any of the 4 parts or the appendices.
Yes, it's mentioned on page 19 of part 4 (as point 1, and my main concern is with point 2b).
Ah, thanks for the pointer
Nested inside of the above issue, another problem is that the author seems to use “proof-like" rhetoric in arguments, when she needs to provide broader illustrations that could generalize for intuition, because the proof actually isn’t there.
Sometimes some statements don't seem to resemble how people use mathematical argumentation in disciplines like machine learning or economics.
To explain, the author begins with an excellent point that it’s bizarre and basically statistically impossible that a feed forward network can learn to do certain things through limited training, even though the actual execution in the model would be simple.
One example is that it can’t learn the mechanics of addition for numbers larger than it has seen computed in training.
Basically, the most “well trained”/largest feed forward DNN that uses backprop training, will never add 99+1 correctly, if it was only trained on adding smaller numbers like 12+17 if these calculations never total 100. This is because in backprop, the network literally needs to see and create processes for the 100 digits. This is despite the fact that it’s simple (for a vast DNN) to “mechanically have” the capability to perform true logical addition.
Immediately starting from the above point, I think author wants to suggests that, in the same way it’s impossible to get this functionality above, this constrains what feed forward networks would do (and these ideas should apply to deep learning or 2020 technology for biological anchors).
However, everything sort of changes here. The author says:
I’s not clear what is being claimed or what is being built on above.
Regarding the questions about feedforward networks, a really short answer is that regression is a very limited form of inference-time computation that e.g. rules out using memory. (Of course, as you point out, this doesn't apply to other 2020 algorithms beyond MLPs.) Sorry about the lack of clarity -- I didn't want to take up too much space in this piece going into the details of the linked papers, but hopefully I'll be able to do a better job explaining it in a review of those papers that I'll post on LW/AF next week.
(I also want to reply to your top-level comments about the evolutionary anchor, but am a bit short on time to do it right now (since for those questions I don't have cached technical answers and will have to remind myself about the context). But I'll definitely get to it next week.)
Thanks for the responses, they give a lot more useful context.
If it frees up your time, I don't think you need to write the above, unless you specifically want to. It seems reasonable to interpret that point on "evolutionary anchors" as a larger difference on the premise, and that is not fully in scope of the post. This difference and its phrasing is more disagreeable/overbearing to answer, so it's also less worthy of a response.
Thanks for writing your ideas.