The people arguing against stopping (or pausing) either have long timelines or low p(doom).
The tl;dr is the title. Below I try to provide a succinct summary of why I think this is the case (read just the headings on the left for a shorter summary).
Timelines are short
The time until we reach superhuman AI is short.
“While superintelligence seems far off now, we believe it could arrive this decade.” - OpenAI
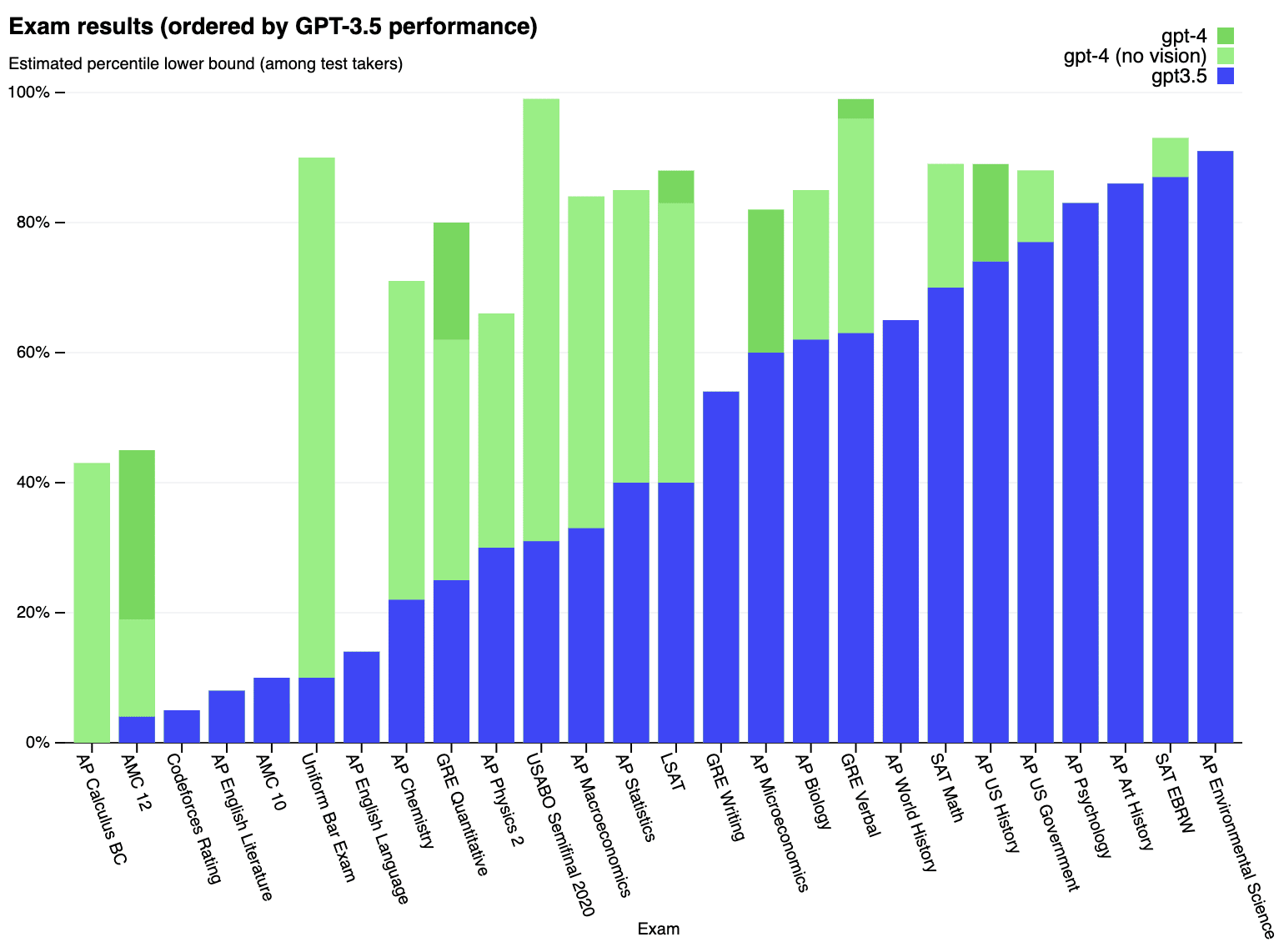
GPT-4
Artificial General Intelligence (AGI) is now in its ascendency. GPT-4 is already ~human-level at language and image recognition, and is showing sparks of AGI. This was surprising to most, and led to many people reducing their AI timelines.
Massive investment
Following GPT-4, the race to superhuman AI has become frantic. Google DeepMind has heavily invested in a competitor (Gemini), and Amazon has recently invested $4B into Anthropic, following the success of its Claude models. We now have 7 of the world’s 10 largest companies heavily investing into frontier AI[1]. Inflection and xAI have also entered the race.
Scaling continues unabated
It’s looking highly likely that the current paradigm of AI architecture (Foundation models), basically just scales all the way to AGI. There is little evidence to suggest otherwise. Thus it’s likely that all that is required to get AGI is throwing more money (compute and data) at it. This is ready happening to the point where AGI is likely "in the post" already, with a delivery time of 2-5 years[2].
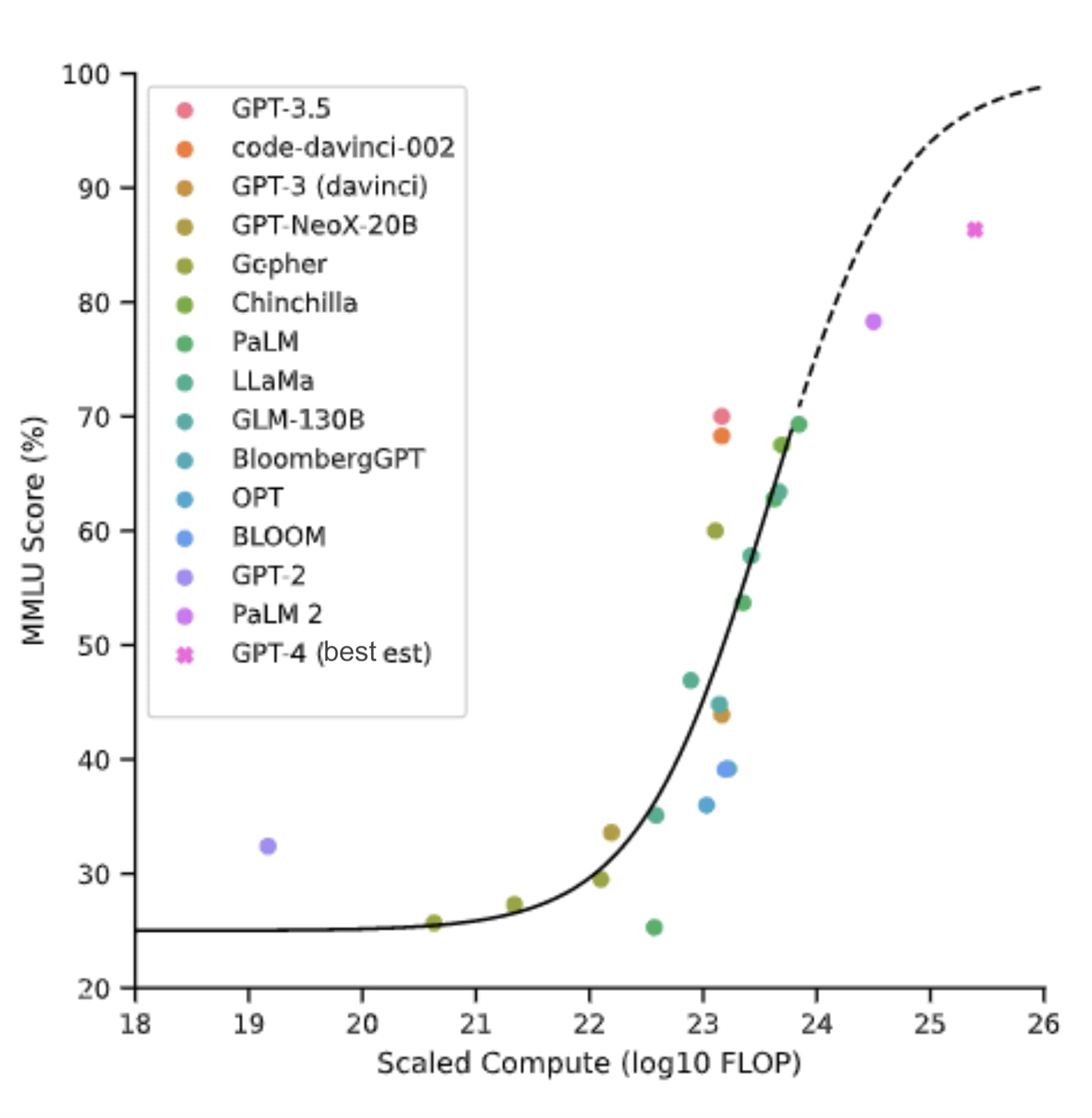
Graph adapted[3] from Extrapolating performance in language modeling benchmarks [Owen, 2023]. An MMLU score of 90% represents human expert level across many (57) subjects.
General cognition
Foundation model AIs are “General Cognition Engines”[4]. Large multimodal models – text-, image-, audio-, video-, VR/games-, robotics[5]-manipulation by a single AI – will arrive very soon and will be ~human-level at many things: physical as well as mental tasks; blue collar jobs[6] in addition to white collar jobs.
Takeoff to Artificial Superintelligence (ASI)
Regardless of whether an AI might be considered AGI (or TAI) or superhuman AI, what’s salient from an extinction risk (x-risk) perspective is whether it is able to speed up AI research. Once an AI becomes as good at AI engineering as a top AI engineer (reaches the “Ilya Threshold”), then it can be used to rapidly speed up further AI development. Or, an AI that is highly capable at STEM could pose an x-risk as is - a “teleport” to x-risk as opposed to a “foom”. Worrying developments pushing in these directions include larger context windows, plugins, planners and early attempts at recursive self-improvement.
There are no bottlenecks
Compute: Following Epoch, it looks like there is currently a 10.5x[7] growth of effective training FLOP every year. So if we were at 1E25 FLOP in 2022 (GPT-4), then that is 1E28 effective FLOP in 2025 and 1E31 in 2028. And 1E28-1E31 is probably AGI (near perfect performance on human-level tasks)[8].
This isn’t just a theoretical projection: Inflection are claiming to be on for having 100x GPT-4 (2E27 FLOP) in 18 months[9]. Google may well have a Zettaflop (1E21) cluster by 2025; 4 months of runtime (1E7s) gives 1E28 FLOP[10]. It’s plausible that an actor spending $10B on compute now could get a 1E28 FLOP model in months.
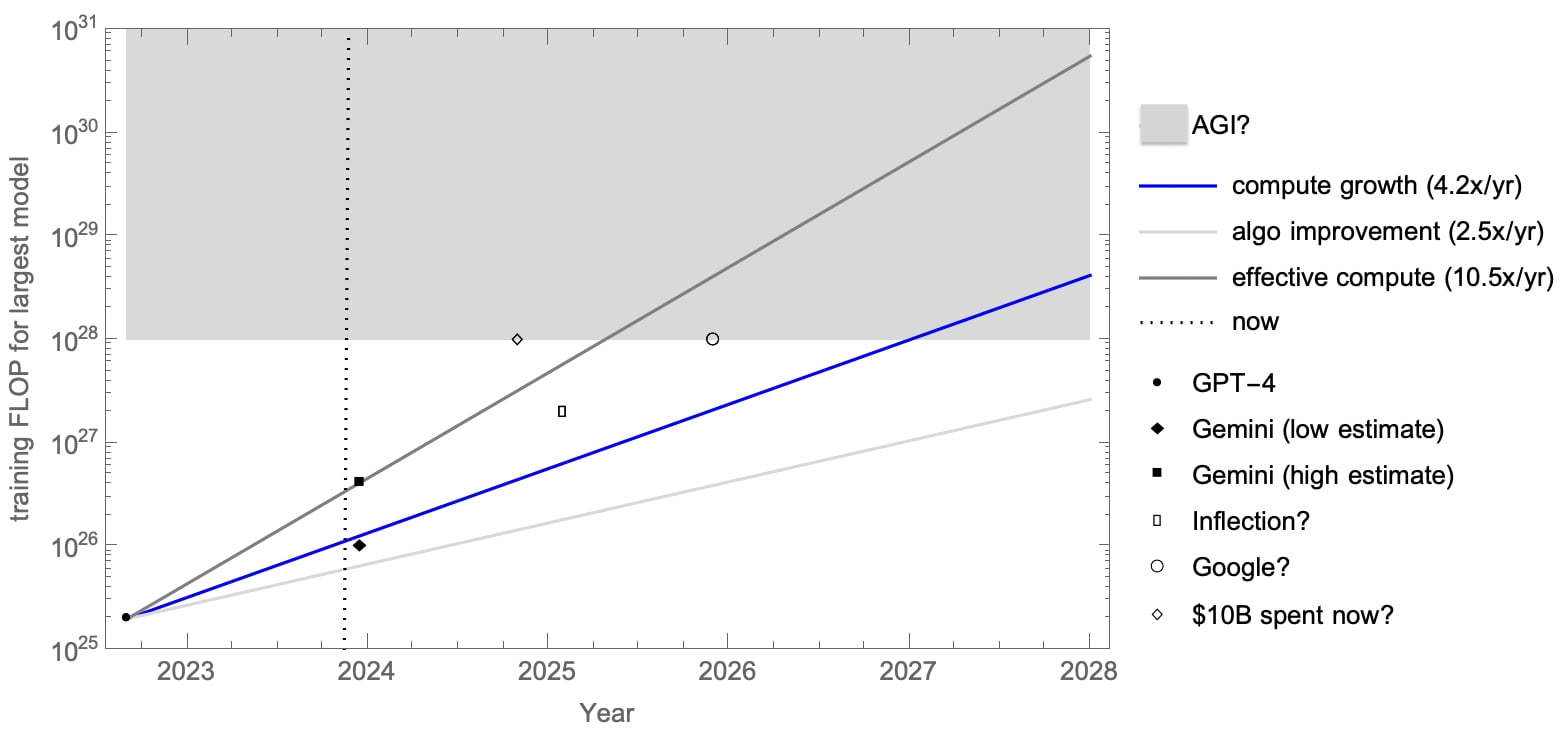
Projection of training FLOP for frontier AI over the next 4 years (see the above two paragraphs for a detailed explanation).
Data: There are billions of high-res video cameras (phones), and sensors in the world. There is YouTube (owned by Google). There is a fast-growing synthetic data industry[11]. For specific tasks that require a high skill level, there is training data provided by narrow AI specialised in the skill. Regarding the need for active learning for AGI, see DeepMind's Adaptive Agent and the Voyager "lifelong learning" Minecraft agent, significant steps in this direction. Also, humans reach human level performance with a fraction of the data used by current models, so we know this is possible.
Ability to influence the real world: Error correction; design iteration; trial and error[12]. All are clearly not insurmountable, given the evidence we have of human success in the physical world. But can it happen quickly with AI? Yes. There are many ways that AI can easily break out into the physical world, involving hacking networked machinery and weapons systems, social persuasion, robotics, and biotech.
p(doom|AGI) is high
"I haven't found anything. Usually any proposal I read about or hear about, I immediately see how it would backfire, horribly." "My position is that lower level intelligence cannot indefinitely control higher level intelligence" - Roman Yampolskiy
The most likely (default) outcome of AGI is doom[13][14]. Superhuman AI is near (see above), and viable solutions for human safety from extinction (x-safety) are nowhere in sight[15]. If you apply a security mindset (Murphy’s Law) to the problem of securing x-safety for humans in a world with smarter-than-human AI, it should quickly become apparent that it is very difficult.
Slow alignment progress
The slow progress of the field to date is further evidence for this. The alignment paradigms used for today’s frontier models only appear to make them relatively safe because they are (currently) weaker than us[16]. If the “grandma’s bedtime story napalm recipe” prompt engineering hack actually led to the manufacture of napalm, it would be immediately obvious how poor today’s level of practical AI alignment is[17].
4 disjunctive paths to doom
There are 4 major unsolved disjunctive components to x-safety: outer alignment, inner alignment, misuse risk, multi-agent coordination. And a variety of corresponding threat models.
Any given approach that might show some promise on one or two of these still leaves the others unsolved. We are so far from being able to address all of them. And not only do we have to address them all, but we have to have totally watertight solutions, robust to AI being superhuman in its capabilities (in contrast to today’s “weak methods”). In the limit of superintelligent AI, alignment and other x-safety protections (those against misuse or conflict) need to be perfect. Else all the doom flows through the tiniest crack in our defence[18].
The nature of the threat
The Shoggoth meme.
X-risk-posing AI will be:
- A General Cognition Engine (see above); an AGI.
- Superhumanly capable at STEM.
- Alien (merely very good at imitating humans).
- Fast (we’ll be like plants to it).
- Very difficult to stop if open sourced (or leaked).
- Unstoppable if put on the blockchain.
- Capable of world model building.
- Situationally aware (and deceptive).
- Capable of goal mis-generalisation[19] (mesa-optimisation).
- Misaligned (see above).
- Uncontrollable (see below).
X-safety from ASI might be impossible
We don’t even know for sure at this stage whether x-safety from superhuman AI is even possible. A naive prior would actually suggest that it may not be. Since when has a more intelligent species indefinitely controlled a less intelligent species? And there is in fact currently ongoing work to establish impossibility proofs for ASI alignment[20]. These being accepted could go a long way to securing a moratorium on further frontier AI development.
A global stop to frontier AI development is our only reasonable hope
I had referred to this as an “indefinite global pause” in a draft, but following Scott Alexander’s taxonomy of pause debate positions, I realise that a stop (and restart when safe) is a cleaner way of putting it[21].
“There are only two times to react to an exponential: too early, or too late.” - Connor Leahy[22]
X-safety research needs time to catch up
X-safety research is far behind relative to AI capabilities and shortened timelines. This creates a dire need for extra time to be bought for it to catch up. There are 100s of PhDs that could be done just on getting closer to perfect alignment for current sota models. We could stop for at least 5 years before coming close to running out of useful x-safety research that needs doing.
The pause needs to be indefinite (i.e. a stop) and global
No serious, or (I think) realistic, pause is going to be temporary or local (confined to one country). Many of the posts arguing against a pause seem to be making unrealistic assumptions along these lines. A pause needs to be global and indefinite, until either there is a global consensus on x-safety (amongst ~all experts), or a global democratic mandate to resume scaling of AI (this could happen even if expert consensus on x-risk is 1%, or 10%, I guess, if there are other problems that require AGI to fix, or just a majority desire to make such a gamble for a shot at utopia). This is not to say that it may not start off as local, partial (e.g. regulation based on existing law) or finite, but the goal remains for it to be global and indefinite.
Restart slowly when there is a consensus on AI x-safety
Worries about overhangs in terms of compute and algorithms are also based on unreasonable assumptions: if there are strict limits on compute (and data), they aren’t suddenly going to be lifted. Assuming that there is a global consensus on a way forward that has a high chance of being existentially safe, ratcheting up slowly would be the way to go, doing testing and evals along the way.
Ideally, the consensus on x-safety should be extended to a global democratic mandate to proceed with AGI development, given that it affects everyone on the planet. A global referendum would be the aspiration here. But the initial agreement to stop should have baked into it a mechanism for determining consensus on x-safety and restarting. I hope that the upcoming UK AI Safety Summit can be a first step toward such an agreement.
Consider that maybe we should just not build AGI at all
The public doesn’t want it[23]. Uncertainty over extreme risks alone justifies a stop. It’s almost a cliche now for climate change and cancer cures to be trotted out as reasons to pursue AGI. EAs might also think about solutions to poverty and all disease. But we are already making good progress on these (including with existing narrow AI), and there’s no reason that we can’t solve them without AGI. We don’t need AGI for an amazing future.
Objections answered
We don’t need to keep scaling AI capabilities to do good alignment research.
The argument by the big AI labs that we need to advance capabilities to be able to better work on alignment is all too conveniently aligned with their money-making and power-seeking incentives. Responsible Scaling policies are deeply flawed; it’s basically an oxymoron when AGI is so close. The danger is already apparent enough (see above) to stop scaling now. The same applies to conditional pauses, trying to predict when we will get dangerous AI, or notice “near-dangerous” AI. Also, as mentioned above, there is plenty of AI Safety research that is possible during a stop[24] (e.g. mech. interp.).
We don’t need a global police state to enforce an indefinite moratorium.
The worry is about world-ending compute becoming more and more accessible as it continues to become cheaper, and algorithms keep advancing. But hardware development and research can also be controlled. And computers already report a lot of data - adding restrictions along the lines of “can’t be used for training dangerous frontier AI models” would not be such a big change. More importantly, a taboo can go a long way to reducing the need for enforcement. Take for example, human reproductive cloning. This is so morally abhorrent that it is not being practised anywhere in the world. There is no black market in need of a global police state to shut it down. AGI research could become equally uncool once the danger, and loss of sovereignty, it represents is sufficiently well appreciated. Nuclear non-proliferation is another example - there is a lot of international monitoring and control of enriched uranium without a global police state. The analogy here is GPUs being uranium and large GPU clusters being enriched uranium.
Scott Alexander has the caveat “absent much wider adoption of x-risk arguments” when talking about enforcement of a pause. I think that we can get that much wider adoption of x-risk arguments (indeed we are already seeing it), and a taboo on AGI / superhuman AI to go along with it.
Fears over AI leading to more centralised control and a global dictatorship are all the more reason to shut down AI now.
Even if your p(doom) is (still) low (despite considering the above), we need a global democratic mandate for something as momentous as AGI
Whilst I think AGI is 0-5 years away and p(doom|AGI) is ~90%[25], I want to remind people that a p(doom) of ~10% is ~1B human lives lost in expectation. I know many people working on AI, and EAs, and rationalists, would happily play a round of Russian Roulette for a shot at utopia; but it’s outrageous to force this on the whole world without a democratic mandate. Especially given the general public do not want the “utopia” anyway: they do not want smarter than human AI in the first place.
The benefits are speculative, so they don’t outweigh the risks.
Assumptions of wealth generation, economic abundance and public benefit from AGI are ungrounded without proof that they are even possible - and they aren’t (yet), given a lack of scalable-to-ASI solutions to alignment, misuse, and coordination. A stop isn’t taking away the ladder to heaven, for such a ladder does not exist, even in theory, as things stand[26]. Yes, it is a bit depressing realising that the world we live in may actually be closer to the Dune universe (no AI) than the Culture universe (friendly ASI running everything). But we can still have all the nice things (including a cure for ageing) without AGI; it might just take a bit longer than hoped. We don’t need to be risking life and limb driving through red lights just to be getting to our dream holiday a few minutes earlier.
There is precedent for global coordination at this level.
Examples include nuclear, biological, and chemical weapons treaties; the CFC ban; and taboos on human reproductive cloning and Eugenics. There are many other groups already in opposition to AI due to ethical concerns. A stop is a common solution to most concerns[27].
There aren’t any better options
They all seem far worse:
Superalignment - trying to solve a fiendishly difficult unsolved problem, with no known solution even in theory, to a deadline, sounds like a recipe for failure (and catastrophe).
Pivotal act - requires some minimal level of alignment to pull off. Again, pretty hubristic to expect this to not end in disaster.
Hope for the best - not going to cut it when extinction is on the line and there is nowhere to run or hide.
Hope for a catastrophe first - given human history and psychology (precedents being Covid, Chernobyl), it unfortunately seems likely that the bodies will have to start piling up before sufficient action is taken on regulation/lockdown. But this should not be an actual strategy. We really need to do better this time. Especially when there may not actually be a warning shot, and the first disaster could send us irrevocably toward extinction.
Acknowledgements: For helpful comments and suggestions that have improved the post, I thank Miles Tidmarsh, Jaeson Booker, Florent Berthet and Joep Meindertsma. They do not necessarily endorse everything written in the post, and all remaining shortcomings are my own.
- ^
Including NVidia, Meta, Tesla; and Apple.
- ^
See section below - “There are no bottlenecks” - for more details.
- ^
Rather than max and min estimates for GPT-4 compute, the best estimate from Epoch (2E25) is taken.
- ^
Perhaps if they were actually called this, rather than misnomered as Large Language Models (or Foundation models), then people would be taking this more seriously!
- ^
See also: Tesla’s Optimus, Fourier Intelligence’s GR-1.
- ^
Although scaling general-purpose robotics to automate most physical jobs would likely take a number of years, by which point it is likely to be eclipsed by ASI.
- ^
4.2x from growth in training compute, and 2.5x from algorithm improvements.
- ^
Note also that Ajeya Cotra in her “Bio Anchors” report has ~1E28 and 1E31 FLOP estimates for the Lifetime Anchor and Short horizon neural network hypotheses (p8). And see also the graph above from Owen (2023).
- ^
15 months from now if taken from Mustafa Suleyman’s first pronouncement of this.
- ^
Factoring a continued 2.5x/yr effective increase from algorithmic improvements makes this 1E29 effective FLOP in 2025.
- ^
Whilst Epoch have gathered some data showing that the stock high quality text data might soon be exhausted, their overall conclusion is that there is only a “20% chance that the scaling (as measured in training compute) of ML models will significantly slow down by 2040 due to a lack of training data.”
- ^
Examples along these lines already in use are prompt engineering to increase performance, and code generation to solve otherwise unsolvable problems.
- ^
p(doom|AGI) means probability of doom, given AGI; “doom” means existential catastrophe, or for our purposes here, human extinction.
- ^
I have yet to hear convincing arguments against this.
- ^
See “4 disjunctive paths to doom” below.
- ^
I’ve linked to some of my (and others’) criticisms of other posts in the AI Pause Debate throughout this post.
- ^
Note that the RepE approach only stops ~90% of the jailbreaks. The nature of neural networks suggests that progress in their alignment is statistical in nature and can only asymptote toward 100%. A terrorist intent on misuse isn’t going to be thwarted by having to try prompting their model 10 times.
- ^
One could argue that watertight solutions aren’t necessary, given the example of humans not value loading perfectly between generations, but I don’t think this holds, given massive power imbalances and large amounts of subjective time for accidents to happen, and the likelihood of a singleton emerging given first mover advantage. At the very least we would need to survive the initial foom in order for secondary safeguard systems to be put in place. And imperfect value loading could still lead to non-extinction existential catastrophes of the form of being only left a small amount of the cosmos (e.g. just Earth) by the AI; in which case the non-AGI counterfactual world would probably be better.
- ^
See also The Alignment Problem from a Deep Learning Perspective, p4.
- ^
Although the above caveat from fn. 16 about imperfect value loading (and astronomical waste) might still apply. As might a caveat about the possibility of limited ASI.
- ^
That also makes it easier to distinguish from the other positions. Yudkowsky’s TIME article articulates this view forcefully.
- ^
- ^
Note this is mostly based on a recent survey of the US public. Attitudes in other countries may be more in favour.
- ^
Scott Alexander: “a lot hinges on whether alignment research would be easier with better models. I’ve only talked to a handful of alignment researchers about this, but they say they still have their hands full with GPT-4.”
- ^
The remaining ~10% for “we’re fine” is nearly all exotic exogenous factors (related to the simulation hypothesis, moral realism being true - valence realism?, consciousness, DMT aliens being real etc), that I really don't think we can rely on to save us!
- ^
- ^
Although we should beware the failure mode of a UBI/profit share being accepted as a solution to mass unemployment, as this doesn’t prevent x-risk!
Thanks for sharing your thoughts, Greg!
Assuming you believe there is a 75 % chance of AGI within the next 5 years, the above suggests your median time from now until doom is 3.70 years (= 0.5*(5 - 0)/0.75/0.9). Is your median time from now until human extinction also close to 3.70 years? If so, we can set up a bet similar to the one between Bryan Caplan and Eliezer Yudkowsky:
Hi Vasco, sorry for the delay getting back to you. I have actually had a similar bet offer up on X for nearly a year (offering to go up to $250k) with only one taker for ~$30 so far! My one is you give x now and I give 2x in 5 years, which is pretty similar. Anyway, happy to go ahead with what you've suggested.
I would donate the $10k to PauseAI (I would say $10k to PauseAI in 2024 is much greater EV than $19k to PauseAI at end of 2027).
[BTW, I have tried to get Bryan Caplan interested too, to no avail - if anyone is in contact with him, please ask him about it.]
Definitely seek legal advice in the country and subdivision (e.g., US state) where Greg lives!
You may think of this as a bet, but I'll propose an alternative possible paradigm: it's may be a plain old promissory note backed by a mortgage. That is, a home-equity loan with an unconditional balloon payment in five years. Don't all contracts in which one party must perform in the future include a necessarily implied clause that performance is not necessary in the event that the human race goes extinct by that time? At least, I don't plan on performing any of my future contractual obligations if that happens . . . .
So even assuming this wouldn't be unenforceable as gambling, it might run afoul of the rules for mortgage lending (e.g., because the implied interest rate [~14.4%?] is seen as usurious, or because it didn't comply with local or national laws regulating mortgage lending). That is a pretty regulated industry in general. It would definitely need to follow all the formalities for secured lending against real property: we require those formalities to make sure the borrower knows what he is getting into, and to give notice to other would-be lenders that they would be further back i... (read more)
I tend to put P(doom) around 80%, so I think I'm on the pessimistic side, and I tend to think short timelines are at least a real and serious possibility that we should be planning for. Nevertheless, I disagree with a global stop or a pause being the "only reasonable hope"—global stops and pauses seem basically unworkable to me. I'm much more excited about governmentally enforced Responsible Scaling Policies, which seem like the "better option" that you're missing here.
I guess I'm not really sure what your objection is to Responsible Scaling Policies? I see that there's a bunch of links, but I don't really see a consistent position being staked out by the various sources you've linked to. Do you want to describe what your objection is?
I guess the closest there is "the danger is already apparent enough" which, while true, doesn't really seem like an objection. I agree that the danger is apparent, but I don't think that advocating for a pause is a very good way to address that danger.
I mean, yes, obviously we should be doing everything we can right now. I just think that a RSP-gated pause is the right way to do a pause. I'm not even sure what it would mean to do a pause without an RSP-like resumption condition.
Because it's more likely to succeed. RSPs provides very clear and legible risk-based criteria that are much more plausibly things that you could actually get a government to agree to.
This seems extremely disingenuous and bad faith. That's obviously not the tradeoff and it confuses me why you would even claim that. Surely you know that I am not Sam Altman or Dario Amodei or whatever.
The actual tradeoff is the probability of success. If I thought e.g. just advocating for a six month pause right now was more effective at reducing existential risk, I would do it.
Re p(doom) being high, I don't think you need to commit to the view that the most likely outcome of AGI is doom. Surveys of AI researchers put the risk from rogue AI at 5%. In the XPT survey professional forecasters put the risk of extinction from AI at 0.03% by 2050 and 0.38% by 2100, whereas domain experts put the chance at 1.1% and 3%, respectively. Though they had longer timelines than you seem to endorse here.
I think your argument goes through even if the risk is 1% conditional on AGI and that seems like an estimate unlikely to upset too many people, so I would just go with that
I think you come across as over-confident, not alarmist, and I think it hurts how you come across quite a lot. (We've talked a bit about the object level before.) I'd agree with John's suggested approach.
Thanks for this post Greg.
Re your point about scaling, the Michael et al survey of NLP researchers suggests that researchers don't think scaling will take us all the way there.
Figure 4.
Based on my limited understanding I agree with you that it seems pretty plausible that scaling does take us to human level AI and beyond, but the experts seem to disagree and I'm not sure why
I agree with most of the points in this post (AI timelines might be quite short; probability of doom given AGI in a world that looks like our current one is high; there isn't much hope for good outcomes for humanity unless AI progress is slowed down somehow). I will focus on one of the parts where I think I disagree and which feels like a crux for me on whether advocating AI pause (in current form) is a good idea.
You write:
... (read more)I'm not an expert on most of the evidence in this post, but I'm extremely suspicious of the claim that GPT-4 represents AI that is "~ human level at language", unless you mean something by this that is very different from what most people would expect.
Technically, GPT-4 is superhuman at language because whatever task you are giving it is in English, and the median human's English proficiency is roughly nil. But a more commonsense interpretation of this statement is that a prompt-engineered AI and a trained human can do the task roughly as well.
What you lin... (read more)
I agree with most of your conclusions in this post. I feel uncomfortable. I'll write more once I have processed some of my emotions and can think in a more clear manner.
Strong upvote.
GPT-1 was released 2018. GPT-4 has shown sparks of AGI.
We have early evidence of self-improvement -- or conservatively -- positive feedback loops are evident.
Open AI intends to build ~AGI to automate alignment research. Sam Altman is attempting to raise $7T USD to build more GPUs.
Anthropic CEO estimates 2-3 years until AGI.
Meta has gone public about their goal of open-sourcing AGI.
Superalignment might even be impossible.
It seems to be difficult to defend a world against rouge AGIs, it seems difficult for al... (read more)
I'm skeptical about the tractability of making AGI development taboo within a very few years. It seems like this plan would require moderate timelines in order to be viable.
That said, I'm starting to wonder whether we should be trying to gain support for a pause in theory: specifically, people to agree that in an ideal world, we would pause AI development where we are now.
That could help open up the Overton window.
I've now made post this into an X thread (with some slight edits and some condensing).
Upvoted your post because you made some good points, but I think your analogy between human cloning and AI training is totally wrong.
There is no black market in human cloning, and no police state trying to stop it, because n... (read more)