Since writing The Precipice, one of my aims has been to better understand how reducing existential risk compares with other ways of influencing the longterm future. Helping avert a catastrophe can have profound value due to the way that the short-run effects of our actions can have a systematic influence on the long-run future. But it isn't the only way that could happen.
For example, if we advanced human progress by a year, perhaps we should expect to see us reach each subsequent milestone a year earlier. And if things are generally becoming better over time, then this may make all years across the whole future better on average.
I've developed a clean mathematical framework in which possibilities like this can be made precise, the assumptions behind them can be clearly stated, and their value can be compared.
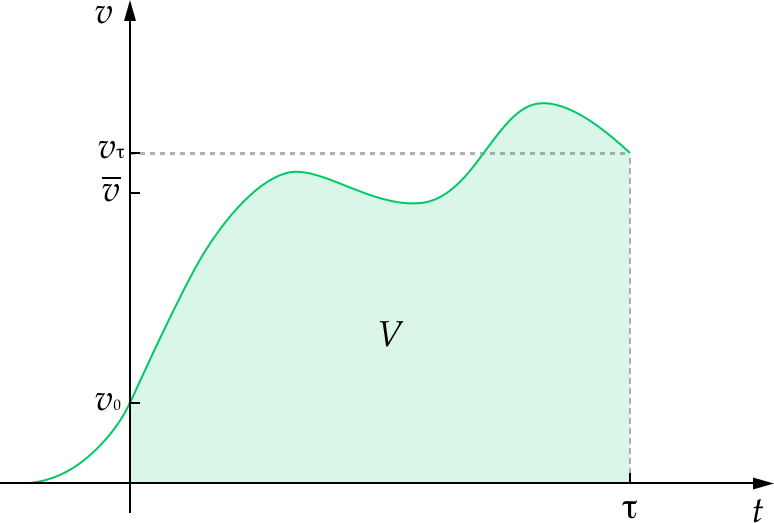
The starting point is the longterm trajectory of humanity, understood as how the instantaneous value of humanity unfolds over time. In this framework, the value of our future is equal to the area under this curve and the value of altering our trajectory is equal to the area between the original curve and the altered curve.
This allows us to compare the value of reducing existential risk to other ways our actions might improve the longterm future, such as improving the values that guide humanity, or advancing progress.
Ultimately, I draw out and name 4 idealised ways our short-term actions could change the longterm trajectory:
- advancements
- speed-ups
- gains
- enhancements
And I show how these compare to each other, and to reducing existential risk.
My hope is that this framework, and this categorisation of some of the key ways we might hope to shape the longterm future, can improve our thinking about longtermism.
Some upshots of the work:
- Some ways of altering our trajectory only scale with humanity's duration or its average value — but not both. There is a serious advantage to those that scale with both: speed-ups, enhancements, and reducing existential risk.
- When people talk about 'speed-ups', they are often conflating two different concepts. I disentangle these into advancements and speed-ups, showing that we mainly have advancements in mind, but that true speed-ups may yet be possible.
- The value of advancements and speed-ups depends crucially on whether they also bring forward the end of humanity. When they do, they have negative value.
- It is hard for pure advancements to compete with reducing existential risk as their value turns out not to scale with the duration of humanity's future. Advancements are competitive in outcomes where value increases exponentially up until the end time, but this isn't likely over the very long run. Work on creating longterm value via advancing progress is most likely to compete with reducing risk if the focus is on increasing the relative progress of some areas over others, in order to make a more radical change to the trajectory.
The work is appearing as a chapter for the forthcoming book, Essays on Longtermism, but as of today, you can also read it online here.
Thank you for the post! I have a question: I wonder whether you think the trajectory to be shaped should be that of all sentient beings, instead of just humanity? It seems to me that you think that we ought to care about the wellbeing of all sentient beings. Why isn't this prinicple extraopolated when it comes to longtermism?
For instance, from the quote below from the essay, it seems to me that your proposal's scope doesn't neccessarily include nonhuman animals. "For example, a permanent improvement to the wellbeing of animals on earth would behave like a gain (though it would require an adjustment to what v(⋅) is supposed to be representing)."
Good point. I may not be clear enough on this in the piece (or even in my head). I definitely want to value animal wellbeing (positive and negative) in moral choices. The question is whether this approach can cleanly account for that, or if it would need to be additional. Usually, when I focus on the value of humanity (rather than all animals) it is because we are the relevant moral agent making the choices and because we have tremendous instrumental value — in part because we can affect other species for good or for ill. That works for defining existential risk as I do it via instrumental value.
But for these curves, I am trying to focus on intrinsic value. Things look quite different with instrumental value, as the timings of the benefits change. e.g. if we were to set up a wonderful stable utopia in 100 years, then the instrumental value of that is immense. It is as if all the intrinsic value of that utopia is scored at the moment in 100 years (or in the run up to it). Whereas, the curves are designed to track when the benefits are actually enjoyed.
I also don't want them to track counterfactual value (how much better things are than they would have been) as I think that is cleaner to compare options by drawing a trajectory for each option and then compare those directly (rather than assuming a default and subtracting it off every alternate choice).
It isn't trivial to reconcile these things. One approach would be to say the curve represents the instrumental effects of humanity on intrinsic value of all beings at that time. This might work, though does have some surprising effects, such as that even after our extinction, the trajectory might not stay at zero, and different trajectories could have different behaviour after our extinction.
This seems very natural to me and I'd like us to normalise including non-human animal wellbeing, and indeed the wellbeing of any other sentience, together with human wellbeing in analyses such as these.
We should use a different term than "humanity". I'm not sure what the best choice is, perhaps "Sentientity" or "Sentientkind".
On your last point, I really like “sentientkind”, but the one main time I used it (when brainstorming org names) I received feedback from a couple of non-EAs that sentientkind sounds a bit weird and sci-fi and thus might not be the best term. (I've not managed to come up with a better alternative for full-moral-circle-analogue-to-“humankind”, though.)
Thank you for the reply, Toby. I agree that humanity have instrumental values to all sentient beings. And I am glad that you want to include animals when you say shaping the future.
I wonder why you think this would be surprising? If humans are not the only beings who have intrinsic values, why is it surprising that there will be values left after humans go extinct?
It's because I'm not intending the trajectories to be a measure of all value in the universe, only the value we affect through our choices. When humanity goes extinct, it no longer contributes intrinsic value through its own flourishing and it has no further choices which could have instrumental value, so you might expect its ongoing value to be zero. And it would be on many measures.
Setting up the measures so that it goes to zero at that point also greatly simplifies the analysis, and we need all the simplification we can get if we want to get a grasp on the value of the longterm future. (Note that this isn't saying we should ignore effects of our actions on others, just that if there is a formal way of setting things up that recommends the same actions but is more analytically tractable, we should use that.)
Existential risk, and an alternative framework
One common issue with “existential risk” is that it’s so easy to conflate it with “extinction risk”. It seems that even you end up falling into this use of language. You say: “if there were 20 percentage points of near-term existential risk (so an 80 percent chance of survival)”. But human extinction is not necessary for something to be an existential risk, so 20 percentage points of near-term existential risk doesn’t entail an 80 percent chance of survival. (Human extinction may also not be sufficient for existential catastrophe either, depending on how one defines “humanity”))
Relatedly, “existential risk” blurs together two quite different ways of affecting the future. In your model: V=¯vτ. (That is: The value of humanity's future is the average value of humanity's future over time multiplied by the duration of humanity's future.)
This naturally lends itself to the idea that there are two main ways of improving the future: increasing ¯v and increasing τ.
In What We Owe The Future I refer to the latter as “ensuring civilisational survival” and the former as “effecting a positive trajectory change”. (We’ll need to do a bit of syncing up on terminology.)
I think it’s important to keep these separate, because there are plausible views on which affecting one of these is much more important than affecting the other.
Some views on which increasing ¯v is more important:
Some views on which increasing τ is more important:
What’s more, changes to τ are plausible binary, but changes to ¯v are not. Plausibly, most probability mass is on τ being small (we go extinct in the next thousand years) or very large (we survive for billions of years or more). But, assuming for simplicity that there’s a “best possible” and “worst possible” future, ¯v could take any value between 100% and -100%. So focusing only on “drastic” changes, as the language of “existential risk” does, makes sense for changes to τ, but not for changes to ¯v .
This is a good point, and it's worth pointing out that increasing ¯v is always good whereas increasing τ is only good if the future is of positive value. So risk aversion reduces the value of increasing τ relative to increasing ¯v, provided we put some probability on a bad future.
What do you mean by civilisation? Maybe I'm nitpicking but it seems that even if there is a low upper bound on value for a civilisation, you may still be able to increase ¯v by creating a greater number of civilisations e.g. by spreading further in the universe or creating more "digital civilisations".
Agree this is worth pointing out! I've a draft paper that goes into some of this stuff in more detail, and I make this argument.
Another potential argument for trying to improve ¯v is that, plausibly at least, the value lost as a result of the gap between expected-¯v and best-possible-¯v is greater that the value lost as a result of the gap between expected-τ and best-possible-τ. So in that sense the problem that expected-¯v is not as high as it could be is more "important" (in the ITN sense) than the problem that the expected τ is not as high as it could be.
I think this is a useful two factor model, though I don't quite think of avoiding existential risk just as increasing τ. I think of it more as increasing the probability that it doesn't just end now, or at some other intermediate point. In my (unpublished) extensions of this model that I hint at in the chapter, I add a curve representing the probability of surviving to time t (or beyond), and then think of raising this curve as intervening on existential risk.
In this case I meant 'an 80 percent chance of surviving the threat with our potential intact', or of 'our potential surviving the threat'.
While this framework is slightly cleaner with extinction risk instead of existential risk (i.e. the curve may simply stop), it can also work with existential risk as while the curve continues after some existential catastrophes, it usually only sweeps out an a small area. This does raise a bigger issue if the existential catastrophe is that we end up with a vastly negative future, as then the curve may continue in very important ways after that point. (There are related challenges pointed out by another commenter where out impacts on the intrinsic value of other animals may also continue after our extinction.) These are genuine challenges (or limitations) for the current model. One definitely can overcome them, but the question would be the best way to do so while maintaining analytic tractability.
Enhancements
I felt like the paper gave enhancements short shrift. As you note, they are the intervention most plausibly competes with existential risk reduction, as they scale with ¯v τ .
You say: “As with many of these idealised changes, they face the challenge of why this wouldn’t happen eventually, even without the current effort. I think this is a serious challenge for many proposed enhancements.”
I agree that this is a serious challenge, and that one should have more starting scepticism about the persistence of enhancements compared with extinction risk reduction.
But there is a compelling response as to why the improvements to v(.) don’t happen anyway: which is that future agents don’t want them to happen. Taking a simplified example: In one scenario, society is controlled by hedonists; in another scenario, society is controlled by preference-satisfactionists. But, let us assume, the hedonists do in fact produce more value. I don’t think we should necessarily expect the preference-satisfactionists to switch to being hedonists, if they don’t want to switch.
(Indeed, that’s the explanation of why AI risk is so worrying from a longterm perspective. Future AI agents might want something valueless, and choose not to promote what’s actually of value.)
So it seems to me that your argument only works if one assumes a fairly strong form of moral internalism, that future agents will work out the moral truth and then act on that basis.
I think I may have been a bit too unclear about which things I found more promising than others. Ultimately the chapter is more about the framework, with a few considerations added for and against each of the kinds of idealised changes, and no real attempt to be complete about those or make all-things-considered judgments about how to rate them. Of the marginal interventions I discuss, I am most excited about existential-risk reduction, followed by enhancements.
As to your example, I feel that I might count the point where the world became permanently controlled by preference utilitarians an existential catastrophe — locking in an incorrect moral system forever. In general, lock-in is a good answer for why things might not happen later if they don't happen now, but too much lock-in of too big a consequence is what I call an existential catastrophe. So your example is good as a non-*extinction* case, but to find a non-existential one, you may need to look for examples that are smaller in size, or perhaps only partly locked-in?
Here's the EAG London talk that Toby gave on this topic (maybe link it in the post?).
Hi Toby,
Thanks so much for doing and sharing this! It’s a beautiful piece of work - characteristically clear and precise.
Remarkably, I didn’t know you’d been writing this, or had an essay coming out that volume! Especially given that I’d been doing some similar work, though with a different emphasis.
I’ve got a number of thoughts, which I’ll break into different comments.
Thanks Will, these are great comments — really taking the discussion forwards. I'll try to reply to them all over the next day or so.
Humanity
Like the other commenter says, I feel worried that v(.) refers to the value of “humanity”. For similar reasons, I feel worried that existential risk is defined in terms of humanity’s potential.
One issue is that it’s vague what counts as “humanity”. Homo sapiens count, but what about:
I’m not sure where you draw the line, or if there is a principled place to draw the line.
A second issue is that “humanity” doesn’t include the value of:
And, depending on how “humanity” is defined, it may not include non-aligned AI systems that nonetheless produce morally valuable or disvaluable outcomes.
I tried to think about how to incorporate this into your model, but ultimately I think it’s hard without it becoming quite unintuitive.
And I think these adjustments are potentially non-trivial. I think one could reasonably hold, for example, that the probability of a technologically-capable species evolving, if Homo sapiens goes extinct, is 90%, that non-Earth-originating alien civilisations settling the solar systems that we would ultimately settle is also 90%, and that such civilisations would have similar value to human-originating civilisation.
(They also change how you should think about longterm impact. If alien civilisations will settle the Milky Way (etc) anyway, then preventing human extinction is actually about changing how interstellar resources are used, not whether they are used at all .)
And I think it means we miss out on some potentially important ways of improving the future. For example, consider scenarios where we fail on alignment. There is no “humanity”, but we can still make the future better or worse. A misaligned AI system that promotes suffering (or promotes something that involves a lot of suffering) is a lot worse than an AI system that promotes something valueless.
The term 'humanity' is definitely intended to be interpreted broadly. I was more explicit about this in The Precipice and forgot to reiterate it in this paper. I certainly want to include any worthy successors to homo sapiens. But it may be important to understand the boundary of what counts. A background assumption is that the entities are both moral agents and moral patients — capable of steering the future towards what matters and for being intrinsically part of what matters. I'm not sure if those assumptions are actually needed, but they were guiding my thought.
I definitely don't intend to include alien civilisations or future independent earth-originating intelligent life. The point is to capture the causal downstream consequences of things in our sphere of control. So the effects of us on alien civilisations should be counted and any effects we have of on whether any earth species evolves after us, but it isn't meant to be a graph of all value in the universe. My methods wouldn't work for that, as we can't plausibly speed that up, or protect it all etc (unless we were almost all the value anyway).
It seems like it would have been worth discussing AI more explicitly, but maybe that's a discussion for a separate article?
How plausible is it that we can actually meaningfully advance or speed up progress through work we do now, other than through AI or deregulating AI, which is extremely risky (and could "bring forward the end of humanity" or worse)? When sufficiently advanced AI comes, the time to achieve any given milestone could be dramatically reduced, making our efforts ahead of the arrival of that AI, except to advance or take advantage of advanced AI, basically pointless.
I suppose we don't need this extra argument, if your model and arguments are correct.
This is a great point and would indeed have been good to include.
There is a plausible case that advancing AI roughly advances everything (as well as having other effects on existential risk …) making advancements easier if they are targetting AI capabilities in particular and making advancements targetting everything else harder. That said, I still think it is easier to reduce risk by 0.0001% than to advance AI by 1 year — especially doing the latter while not increasing risk by a more-than-compensating amount.
Humanity
Like the other commenter says, I feel worried that v(.) refers to the value of “humanity”. For similar reasons, I feel worried that existential risk is defined in terms of humanity’s potential.
One issue is that it’s vague what counts as “humanity”. Homo sapiens count, but what about:
I’m not sure where you draw the line, or if there is a principled place to draw the line.
A second issue is that “humanity” doesn’t include the value of:
And, depending on how “humanity” is defined, it may not include non-aligned AI systems that nonetheless produce morally valuable or disvaluable outcomes.
I tried to think about how to incorporate this into your model, but ultimately I think it’s hard without it becoming quite unintuitive.
And I think these adjustments are potentially non-trivial. I think one could reasonably hold, for example, that the probability of a technologically-capable species evolving, if Homo sapiens goes extinct, is 90%, that non-Earth-originating alien civilisations settling the solar systems that we would ultimately settle is also 90%, and that such civilisations would have similar value to human-originating civilisation.
(They also change how you should think about longterm impact. If alien civilisations will settle the Milky Way (etc) anyway, then preventing human extinction is actually about changing how interstellar resources are used, not whether they are used at all .)
And I think it means we miss out on some potentially important ways of improving the future. For example, consider scenarios where we fail on alignment. There is no “humanity”, but we can still make the future better or worse. A misaligned AI system that promotes suffering (or promotes something that involves a lot of suffering) is a lot worse than an AI system that promotes something valueless.
Sorry if I'm missing something (I've only skimmed the paper), but is the "mathematical framework" just the idea of integrating value over time?
I'm quite surprised to see this idea presented as new. Isn't this idea very obvious? Haven't we been thinking this way all along?
Like, how else could you possibly think of the value of the future of humanity? (The other mathematically simple option that comes to mind is to only value some end state and ignore all intermediate value, but that doesn't seem very compelling.)
Again, apologies if I'm missing something, which seems likely. Would appreciate anyone who can fill in the gaps for me if so!
Speed-ups
You write: “How plausible are speed-ups? The broad course of human history suggests that speed-ups are possible,” and, “though there is more scholarly debate about whether the industrial revolution would have ever happened had it not started in the way it did. And there are other smaller breakthroughs, such as the phonetic alphabet, that only occurred once and whose main effect may have been to speed up progress. So contingent speed-ups may be possible.”
This was the section of the paper I was most surprised / confused by. You seemed open to speed-ups, but it seems to me that a speed-up for the whole rest of the future is extremely hard to do.
The more natural thought is that, at some point in time, we either hit a plateau, or hit some hard limit of how fast v(.) can grow (perhaps driven by cubic or quadratic growth as future people settle the stars). But if so, then what looks like a “speed up” is really an advancement.
I really don’t see what sort of action could result in a speed-up across the whole course of v(.), unless the future is short (e.g. 1000 years).
I think "open to speed-ups" is about right. As I said in the quoted text, my conclusion was that contingent speed-ups "may be possible". They are not an avenue for long-term change that I'm especially excited about. The main reason for including them here was to distinguish them from advancements (these two things are often run together) and because they fall out very natural as one of the kinds of natural marginal change to the trajectory whose value doesn't depend on the details of the curve.
That said, it sounds like I think they are a bit more likely to be possible than you do. Here are some comments on that.
One thing is that it is easier to have a speed-up relative to another trajectory than to have one that is contingent — which wouldn't have happened otherwise. Contingent speed-ups are the ones of most interest to longtermists, but those that are overdetermined to happen are still relevant to studying the value of the future and where it comes from. e.g. if the industrial revolution was going to happen anyway, then the counterfactual value of it happening in the UK in the late 1700s may be small, but it is still an extremely interesting event in terms of dramatically changing the rate of progress from then onwards compared to a world without an industrial revolution.
Even if v(.) hits a plateau, you can still have a speed-up, it is just that it only has an impact on the value achieved before we would have hit the value anyway. That could be a large change (e.g. if the plateau isn't reached in the first 1% of our lifetime), but even if it isn't, that doesn't stop this being a speed-up, it is just that changing the speed of some things isn't very valuable, which is a result that is revealed by the framework.
Suppose v(.) stops growing exponentially with progress and most of its increase is then governed by growing cubically as a humanity's descendants settle the cosmos. Expanding faster (e.g. by achieving a faster travel speed of 76%c instead of 75%c) could then count as a speed-up. That said, it is difficult for this to be a contingent speed-up, as it raises the question of why (when this was the main determinant of value) would this improvement not be implemented at a later date? And it is also difficult in this case to see how any actions now could produce such a speed-up.
Overall, I don't see them as a promising avenue for current efforts to target, and more of a useful theoretical tool, but I also don't think there are knockdown arguments against them being a practical avenue.
Gains
“While the idea of a gain is simple — a permanent improvement in instantaneous value of a fixed size — it is not so clear how common they are.”
I agree that gains aren’t where the action is, when it comes to longterm impact. Nonetheless, here are some potential examples:
These plausibly have two sources of longterm value. The first is that future agents might have slightly better lives as a result: perhaps one in a billion future people are willing to pay the equivalent of $1 in order to be able to see a real-life panda, or to learn about the life and times of a historically interesting figure. This scales in future population size, so is probably an “enhancement” rather than a “gain” (though it depends a little on one’s population ethics).
The second is if these things have intrinsic value. If so, then perhaps they provide a fixed amount over value at any time. That really would be a gain.
Another possible gain is preventing future wars that destroy resources. Suppose that, for example, there’s a war between two factions of future interstellar civilisation, and a solar system is destroyed as a result. That would be a loss.
As you say, there is an issue that some of these things might really be enhancements because they aren't of a fixed size. This is especially true for those that have instrumental effects on the wellbeing of individuals, as if those effects increase with total population or with the wellbeing level of those individuals, then they can be enhancements. So cases where there is a clearly fixed effect per person and a clearly fixed number of people who benefit would be good candidates.
As are cases where the thing is of intrinsic non-welfarist value. Though there is also an issue that I don't know how intrinsic value of art, environmental preservation, species types existing, or knowledge is supposed to interact with time. Is it twice as good to have a masterpiece or landscape or species or piece of knowledge for twice as long? It plausibly is. So at least on accounts of value where things scale like that, there is the possibility of acting like a gain.
Another issue is if the effects don't truly scale with the duration of our future. For example, on the longest futures that seem possible (lasting far beyond the lifetime of the Sun), even a well preserved site may have faded long before our end point. So many candidates might act like gains on some durations of our future, but not others.
Advancements
I broadly agree with the upshots you draw, but here are three points that make things a little more complicated:
Continued exponential growth
As you note: (i) if v(.) continues exponentially, then advancements can compete with existential risk reduction; (ii) such continued exponential growth seems very unlikely.
However, it seems above 0 probability that we could have continued exponential growth in v(.) forever, including at the end point (and perhaps even at a very fast rate, like doubling every year). And, if so, then the total value of the future would be dramatically greater than if v(.) increases cubically and/or eventually plateaus. So, one might argue: this is where most of the expected value is. So advancements, in expectation, are competitive with existential risk reduction.
Now, I hate this argument: it seems like it's falling prey to “fanaticism” in the technical sense, letting our expected value calculations be driven by extremely small probabilities.
But it at least shows that, when thinking about longterm impact, we need to make some tough judgment calls about which possibilities we should ignore on the grounds of driving “fanatical”-seeming conclusions, even while only considering only finite amounts of value.
Aliens
Elsewhere, you note the loss of galaxies due to the expansion of the universe, which means that ~one five-billionth of the universe per year becomes inaccessible.
But if the “grabby aliens” model is correct, then that number is too low. By my calculation, if we meet grabby alien civilisations in, for example, one billion years (which I think is about the median estimate from the grabby aliens model), then we “lose” approximately 1 millionth of accessible resources to alien civilisations every year. This is still very small, but three orders of magnitude higher than what we get by just looking at the expansion of the universe.
(Then there’s a hard and relevant question about the value of alien civilisation versus the value of human-originating civilisation.)
Length of advancements / delays
“An advancement of an entire year would be very difficult to achieve: it may require something comparable to the entire effort of all currently existing humans working for a year.”
This is true when considering “normal” economic trajectories. But I think there are some things we could do that could cause much greater advancements or delays. A few examples:
Combining this with the “grabby aliens” point, there is potentially 0.1% of the value of the future that could be gained from preventing delays (1000 years * 1 millionth loss per year). Still much lower than the loss of value from anthropogenic existential risks, but higher than from non-anthropogenic risks. It’s enough that I think it’s not really action-relevant, but so at the same time not totally negligible.
>Aliens
You are right that the presence or absence of alien civilisations (especially those that expand to settle very large regions) can change things. I didn't address this explicitly because (1) I think it is more likely that we are alone in the affectable universe, and (2) there are many different possible dynamics for multiple interacting civilisations and it is not clear what is the best model. But it is still quite a plausible possibility and some of the possible dynamics are likely enough and simple enough that they are worth analysing.
I'm not sure about the details of your calculation, but have thought a bit about it in terms of Jay Olson's model of cosmological expanding civilisations (which is roughly how Anders and I think of it, and similar to model Hanson et al independently came up with). On this model, if civilisations expand at a constant fraction of c (which we can call f), the average distance between independently arising civilisations is D light years, and civilisations permanently hold all locations they reach first, then delaying by 1 year loses roughly 3f/D of the resources they could have reached. So if D were 1 billion light years, and f were close to 1, then a year's delay would lose roughly 1 part in 300 million of the resources. So on my calculation, it would need to be an average distance of about 3 million light years or less, to get the fraction lost down to 1 part in 1 million. And at that point, the arrangement of galaxies makes a big difference. But this was off-the-cuff and I could be overlooking something.
Good point about the fact that I was focusing on some normal kind of economic trajectory when assessing the difficulty of advancements and delays. Your examples are good, as is MichaelStJules' comment about how changing the timing of transformative AI might act as an advancement.
>Continued exponential growth
I agree that there is a kind of Pascallian possibility of very small probabilities of exponential growth in value going for extremely long times. If so, then advancements scale in value with v-bar and with τ. This isn't enough to make them competitive with existential risk reduction ex ante as they are still down-weighted by the very small probability. But it is perhaps enough to cause some issues. Worse is that there is a possibility of growth in value that is faster than an exponential, and this can more than offset the very small probability. This feels very much like Pascal's Mugging and I'm not inclined to bite the bullet and seek out or focus on outcomes like this. But nor do I have a principled answer to why not. I agree that it is probably useful to put under the label of 'fanaticism'.
This is really cool, I'm curating. It seems super clear and crisp to me, which doesn't seem like it'd be easy to do.
Thank you for providing this reading for free, and sharing this post! Inside this online PDF, under the section "Gains", there's a sentence now looking like this:
"We can all such a change a gain"
I suppose you meant to say "call" instead of "all".
What about under something like Tarsney (2022)'s cubic growth model of space colonization?
I'm not sure about Tarsney's model in particular, but on the model I use in The Edges of Our Universe, a year's delay in setting out towards the most distant reaches of space results in reaching about 1 part in 5 billion fewer stars before they are pulled beyond our reach by cosmic expansion. If reaching them or not is the main issue, then that is comparable in value to a 1 in 5 billion existential risk reduction, but sounds a lot harder to achieve.
Even in a model where it really matters when one arrives at each point in space (e.g. if we were merely collecting the flow of starlight, and where the stars burning out set the relevant end point for useful expansion) I believe the relevant number is still very small: 4/R where R is the relevant radius of expansion in light years. The 4 is because this grows as a quartic. For my model, it is 3/R, where R is 16.7 billion light years.
Great article, Toby!
Relatedly, you say that (emphasis mine):
Is the intuition that such advancement could be achieved by doubling the value growth rate for 1 year, which is much harder than decreasing existential risk by 0.0001 %?
Thanks!
The idea is that advancing overall progress by a year means getting a year ahead on social progress, political progress, moral progress, scientific progress, and of course, technological progress. Given that our progress in these is the result of so many people's work, it seems very hard to me for a small group to lead to changes that improve that by a whole year (even over one's lifetime). Whereas a small group leading to changes that lead to the neglected area of existential risk reduction of 0.0001% seems a lot more plausible to me — in fact, I'd guess we've already achieved that.
Flow vs fixed resources
In footnote 14 you say: “It has also been suggested (Sandberg et al 2016, Ord 2021) that the ultimate physical limits may be set by a civilisation that expands to secure resources but doesn’t use them to create value until much later on, when the energy can be used more efficiently. If so, one could tweak the framework to model this not as a flow of intrinsic value over time, but a flow of new resources which can eventually be used to create value.”
This feels to me that it would really be changing the framework considerably, rather than just a “tweak”.
For example, consider a “speed up” with an endogenous end time. On the original model, this decreases total value (assuming the future is overall good). But if we’re talking about gaining a pot of fixed resources, speeding up progress forever doesn’t change total value.
You may be right that this is more than a 'tweak'. What I was trying to imply is that the framework is not wildly different. You still have graphs, integrals over time, decomposition into similar variables etc — but they can behave somewhat differently. In this case, the resources approach is tracking what matters (according to the cited papers) faithfully until expansion has ended, but then is indifferent to what happens after that, which is a bit of an oversimplification and could cause problems.
I like your example of speed-up in this context of large-scale interstellar settlement, as it also brings another issue into sharp relief. Whether thinking in terms of my standard framework or the 'tweaked' one, you are only going to be able to get a pure speed-up if you increase the travel speed too. So simply increasing the rate of technological (or social) progress won't constitute a speed-up. This happens because in this future, progress ceases to be the main factor setting the rate at which value accrues.
This is great. I'm so glad this analysis has finally been done!
One quick idea: should 'speed-ups' be renamed 'accelerations'? I think I'd find that clearer personally, and would help to disambiguate it from earlier uses of 'speed-up' (e.g. in Nick's thesis).
I've thought about this a lot and strongly think it should be the way I did it in this chapter. Otherwise all the names are off by one derivative. e.g. it is true that for one of my speed-ups, one has to temporarily accelerate, but you also have to temporarily change every higher derivative too, and we don't name it after those. The key thing that changes permanently and by a fixed amount is the speed.
Thanks Toby - so, so exciting to see this work progressing!
One quibble:
...when the area under the graph is mostly above the horizontal axis?
Even if you assign a vanishingly small probability to future trajectories in which the cumulative value of humanity/sentientkind is below zero, I imagine many of the intended users of this framework will at least sometimes want to model the impact of interventions in worlds where the default trajectory is negative (e.g. when probing the improbable)?
Maybe this is another 'further development' consciously left to others and I don't know how much the adjustment would meaningfully change things anyway - I admit I've only skimmed the chapter! But I find it interesting that, for example, when you include the possibility of negative default trajectories, the more something looks like a 'speed-up with an endogenous end time' the less robustly bad it is (as you note), whereas the more it looks like a 'gain' the more robustly good it is .
Very clear piece!
You mentioned optimal planning in economics, and I've wondered whether an optimal control framework might be useful for this sort of analysis. I think the difference between optimal control and the trajectory-altering framework you describe is a bit deeper than the different typical domains. There's not just one decision to be made, but a nearly-continuous series of decisions extending through the future (a "policy"). Under uncertainty, the present expected value is the presently realized ("instantaneous") value plus the expectation taken over different futures of the expected value of those futures. Choosing a policy to maximize expected realized value is the control problem.
For the most part, you get the same results with slightly different interpretation. For example, rather than impose some τ, you get an effective lifetime that's mainly determined by "background" risk but also is allowed to vary based on policy.
One thing that jumped out at me in a toy model is that while the value of reducing existential risk is mathematically the same as an "enhancement" (multiplicative), the time at which we expect to realize that extra value can be very different. In particular, an expected value maximizer may heavily backload the realization of value (even beyond the present expected survival time) if they can neglect present value to expand while reducing existential risk.
I suspect one could learn or make clearer a few other interesting things by following those lines.
I think that is indeed a good analogy. In the chapter, I focus on questions of marginal changes to the curve where there is a small shock to some parameter right now, and then its effects play out. If one is instead asking questions that are less about what we now could do to change the future, but are about how humanity over deep time should act to have a good future, then I think the optimal control techniques could be very useful. And I wouldn't be surprised if in attempting to understand the dynamics, there were lessons for our present actions too.
Humanity
Like the other commenter says, I feel worried that v(.) refers to the value of “humanity”. For similar reasons, I feel worried that existential risk is defined in terms of humanity’s potential.
One issue is that it’s vague what counts as “humanity”. Homo sapiens count, but what about:
I’m not sure where you draw the line, or if there is a principled place to draw the line.
A second issue is that “humanity” doesn’t include the value of:
And, depending on how “humanity” is defined, it may not include non-aligned AI systems that nonetheless produce morally valuable or disvaluable outcomes.
I tried to think about how to incorporate this into your model, but ultimately I think it’s hard without it becoming quite unintuitive.
And I think these adjustments are potentially non-trivial. I think one could reasonably hold, for example, that the probability of a technologically-capable species evolving, if Homo sapiens goes extinct, is 90%, that non-Earth-originating alien civilisations settling the solar systems that we would ultimately settle is also 90%, and that such civilisations would have similar value to human-originating civilisation.
(They also change how you should think about longterm impact. If alien civilisations will settle the Milky Way (etc) anyway, then preventing human extinction is actually about changing how interstellar resources are used, not whether they are used at all .)
And I think it means we miss out on some potentially important ways of improving the future. For example, consider scenarios where we fail on alignment. There is no “humanity”, but we can still make the future better or worse. A misaligned AI system that promotes suffering (or promotes something that involves a lot of suffering) is a lot worse than an AI system that promotes something valueless.
I saw someone had downvoted this. I think it's because you posted it three times.
When is the release date for the book? Around many copies are you planning on selling e.g. compared to WWOTF?
I'm one of the editors of the book. Just wanted to confirm everything Toby and Pablo said. It's fully open-access, and about to be sent off for production. So while that doesn't give us a firm release date, realistically we're looking at early 2024 if we're lucky and ... not early 2024 if we're not lucky.
The text of the book is almost completely finalised now, and my guess is that it will be out early 2023 (print publishing is usually slow). It is an academic book, published with Oxford University Press, and I think it will be open access too. My guess is that sales will be only the tiniest fraction of those of WWOTF, and that free downloads will be bigger, but still a small fraction.
I can confirm it's open access. I know this because my team is translating it into Spanish and OUP told us so. Our aim is to publish the Spanish translation simultaneously with the English original (the translation will be published online, not in print form).
Nitpick, I think you meant 2024 instead of 2023 (unless you are planning on doing some time-travelling!).
Quite right!
Hi Toby,
Do you have any plans to empirically validade your framework? You model the interventions as having effects which are maintained (advancements and gains) or increased (speed-ups and enhancements) across time. In contrast, as far as I can tell, the (posterior) counterfactual impact of interventions whose effects can be accurately measured, like ones in global health and development, decays to 0 as time goes by, and can be modelled as increasing the value of the world for a few years, decades or centuries at most.
To be clear, I don't think that most things are longtermist interventions with these permanent impacts (and most things aren't trying to be).
Clearly some thing have had lasting effects. e.g. there were no electrical household items before the 19th century, and now they are ubiquitous and quite possibly will be with us as long as humanity lasts. Whereas if humanity had never electrified, the present would be very different.
That said, it is also useful to ask about the counterfactuals. e.g. if Maxwell or Edison or any other pioneer hadn't made their discoveries, how different would we expect 2024 to be? In this case, it is less clear as someone else probably would have made these discoveries later. But then discoveries that build on them would have been delayed etc. I doubt that the counterfactual impact of Maxwell goes to zero until such a point as practically everything has been discovered (or everything downstream of electromagnetism). That said, it could easily have diminishing impact over time, as is typical of advancements (their impact does not scale with humanity's duration).
But note that the paper actually doesn't claim that a particular invention or discovery acts as an advancement. It suggests it is a possible model of the longterm impacts of things like that. One reason I bring it up is that it shows that even if it was a permanent advancement, then under a wide set of circumstances, it would still be beaten by reducing existential risk. And even if attempts to advance progress really were lasting advancements, the value could be negative if they also bring forward the end time.
I would love it if there was more investigation of the empirical measurement of such lasting effects, though it is outside of my field(s).
Thanks for following up, Toby!
Right. I meant to question permanent "(posterior) counterfactual" effects, which is what matters for assessing the cost-effectiveness of interventions.
Why would the posterior counterfactual impact not go to practically 0 after a few decades or centuries? You seem to be confident this is not the case ("I [Toby] doubt"), so I would appreciate it if you could elaborate.
Nice to know!
There seems to be a typo in this link (on my laptop I can't access your other links, not sure why).
On page 22 I think you're missing the word "in" in the sentence below (I have added it in bold):
"If the lasting benefit would have been achieved later in the default trajectory, then it is only temporary so not a true gain."
It seems like the bias perspective of now is baked into this? Viewed from ice-age scale, collapse is a natural cycle, modulated by technology. The question could be more about whether we want to get something past these resets, or appreciate the destruction.