Introduction
Geoffrey Hinton is a famous AI researcher who is often referred to as the "godfather of AI" because of his foundational work on neural networks and deep learning from the 1980s until today. Arguably his most significant contribution to the field of AI was the introduction of the backpropagation algorithm for neural network training in 1986 which is widely used to train neural networks today. He was also involved in the development of dropout regularization, AlexNet, the RMSProp optimization algorithm, and the t-SNE visualization method. In 2018 he won the Turing award for his work on deep learning along with Yoshua Bengio and Yann LeCun. In 2024, Hinton won the Nobel Prize in Physics for his work on Boltzmann machines. He was also the PhD supervisor of Ilya Sutskever who co-founded OpenAI in 2016.
In 2023, Hinton left Google to retire and speak more freely about the risks of AI. In addition to speaking about the near-term risks of AI, Hinton has also thought carefully about the long-term consequences of AI such as whether AIs will become superintelligent and whether AI could become an existential risk to humanity.
This post starts with a brief history of AI from Hinton's perspective before describing how neural networks work, Hinton’s views on current AI models, and finally his thoughts on the future impact of AI.
A brief history of AI
"I could have said it then, but it wouldn't have convinced people. And what I could have said then is the only reason that neural networks weren't working really well in the 1980s was because the computers weren't fast enough and the datasets weren't big enough. But back in the 80s, the big issue was, could you expect a big neural network with lots of neurons in it, compute nodes, and connections between them, that learns by just changing the strengths of the connections? Could you expect that to just look at data and, with no kind of innate prior knowledge, learn how to do things? And people in mainstream AI thought that was completely ridiculous. It sounds a little ridiculous. It is a little ridiculous, but it works." - Geoffrey Hinton [1]
Today most leading AI models such as GPT-4 are artificial neural networks trained with gradient descent and backpropagation, which has become the dominant approach to building AI. However, this wasn't always the case. Hinton describes how historically there have been two primary schools of thought for how to build AI: the logic-inspired approach and the biologically-inspired approach.
The logic-inspired approach, also known as symbolic AI, says that the essence of intelligence is reasoning which can be done by using symbolic rules to manipulate symbolic expressions. The logic-inspired approach prioritizes reasoning over learning. An example of a symbolic reasoning approach is first-order logic and an example of first-order logic is “For all x, if x is a human, then x is mortal.” Given this rule, you can infer that a person is mortal given that you know that they're human.
Although symbolic AI or GOFAI (good old-fashioned AI) systems have had some success, creating these systems was laborious as facts and rules had to be hand-coded into the systems. Symbolic AI approaches also tended to be brittle, failing completely on problems outside their predefined rules or knowledge. Another major limitation that hindered these methods is the combinatorial explosion: as problems become larger, the number of computations required to solve the problem using exhaustive search tends to increase exponentially, limiting the usefulness of symbolic AI approaches in real-world tasks. The problems associated with symbolic AI contributed to the AI winters in the 1970s and 1980s where funding for AI research dried up and AI failed to live up to expectations.
In contrast, the biologically-inspired or connectionist approach emphasizes the importance of learning instead of reasoning. Rather than using explicit facts and logical rules, the biologically-inspired approach uses a neural network to automatically and implicitly learn facts and rules by adjusting the connection strengths or weights of a neural network.
According to Hinton, neural networks were very unpopular in the 1970s and most AI researchers worked on symbolic AI. Hinton described how his PhD supervisor discouraged him from working on neural networks and suggested that he worked on symbolic AI instead for the sake of his career [2]. Despite the unpopularity of neural networks in the 1970s and 1980s, Hinton continued to work on them. But why did he continue to work on neural networks when they were unpopular and considered ineffective at the time?
One key reason was his fascination with the human brain. Hinton was motivated by a desire to understand how the brain works, and he saw the brain as an existence proof that neural networks could work. To him, neural networks more closely reflected the brain’s true inner workings than traditional programming or logic-based approaches. Also, while neural networks were largely unpopular in computer science, they were still used in psychology as models of human learning. Another influence on his thinking was his father, an entomologist (insect expert), who inspired Hinton to take a biologically-inspired approach to AI.
Neural networks didn’t work well in the 1980s but by the 2010s, especially after the introduction of GPUs for neural network training, the computational power and large datasets necessary for training deep neural networks became available and neural network approaches such as convolutional neural networks (CNNs) began to outperform traditional AI approaches on tasks such as image classification, speech recognition, and machine translation.
The invention of the transformer in 2017 and further increases in computational power and availability of data have led to the rise of chatbots powered by large language models (LLMs) such as GPT-4 which have demonstrated human-like performance on a wide range of tasks such as essay writing, summarizing text, and generating code.
Backpropagation and how neural networks work
Before we discuss AI further, it's useful to describe how neural networks work and how they can be trained to perform tasks using gradient descent and backpropagation.
One task a neural network could do is classify images. A neural network for this task has an input layer to represent the pixels of an image and an output layer to represent a class label such as "bird" or "cat".
Alternatively, the input units could be the previous words of a sentence converted to vectors and the output unit could be the next word in the sentence.
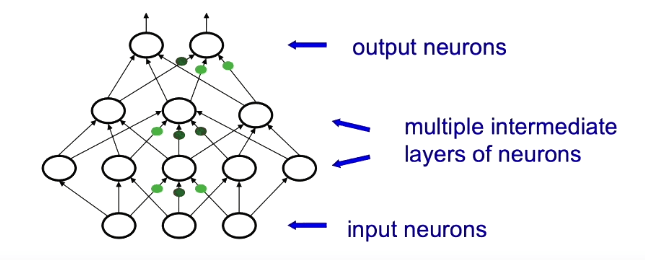
Given a fixed set of nodes in the neural network, the goal of training the network is to learn the connection strengths or weights between the nodes or neurons so that it produces the correct outputs for each input.
One very simple way to do this is to mutate or change each weight in the network a little bit and see if the output of the network improves but this approach is inefficient. A much more efficient approach is to use the gradient descent with backpropagation learning algorithm which was popularized by Hinton in 1986 and is now widely used today. Backpropagation starts with the error at the output layer and uses the chain rule from calculus to pass the error backward through the network's layers and calculate the gradient of the loss with respect to every weight in each layer. This gradient can then be used to update the network’s weights via gradient descent to improve the network's performance on the task.
Gradient descent with backpropagation is much more efficient than the naive mutation method because given a matrix of weights representing the connections between two layers of neurons, backpropagation will produce a matrix of gradients with the same size as the matrix of weights indicating which weights need to be increased or decreased and by how much to improve the network's performance. This matrix of gradients is then multiplied by a small number such as 0.001 and subtracted from the current weight matrix to update all the connection strengths or weights in each layer in parallel. It’s called gradient descent because it involves calculating the gradient of the loss (or error) with respect to each weight and subtracting the gradient from the weights which is like a ball rolling down a hill: as the values of the weights change with each gradient update, the loss or error of the network gradually decreases.
The next question is how does gradient descent with backpropagation change the network to make it perform well?
The original abstract of the backpropagation paper says that, "As a result of the weight adjustments, internal ‘hidden’ units which are not part of the input or output come to represent important features of the task domain".
The gradient descent and backpropagation process causes the neurons in the hidden layers to learn feature detectors that are useful for the task the network is being trained on. Hinton says we should imagine a trained neural network as a hierarchy of feature detectors where a feature detector is a neuron that fires when a specific input pattern is inputted to it [1].
For the image classification task, feature detectors in low layers near the input tend to detect simple features such as edges, curves, or textures, and deeper layers detect more complex features such as object parts. For the bird detector task, these parts might be the beak or foot of a bird. Finally, the output neuron for the “bird” class is activated based on a weighted sum of the feature detectors from the second last layer. So if the beak detecting neuron and the foot detecting neuron are activated, and there are positive weights between these feature detectors and the "bird" output neuron, then the "bird" output neuron will be activated and the network will predict that the image is a bird.[2]
Similarly, studies using probing techniques have discovered evidence that large language models (LLMs) understand text in a hierarchical manner. Probing involves training a classifier to predict specific linguistic properties, such as sentence length or tense, using the hidden representations of the LLM as input. If the probing classifier can accurately predict these properties, it suggests that the LLM’s hidden representations contain this encoded information.
These studies show that the lower layers of LLMs typically capture low-level context-independent syntactic features, such as sentence length, word order, and word types (e.g. nouns or verbs). In contrast, higher layers tend to encode more abstract, context-dependent semantic information, including tenses, word meanings, and long-term dependencies like subject-verb agreement. These upper layers play a key role in word sense disambiguation, which allows the model to determine a word's meaning based on context. For example, recognizing whether "bank" refers to a financial institution or the edge of a river. [5]
Hinton on current AI models
The first language model
In his famous 1986 paper on backpropagation called “Learning representations by back-propagating errors”, Hinton introduced what he now describes as the first neural language model. In the paper, Hinton describes a neural network designed to learn the rules governing family relationships from triples, such as (colin has-father james) and (colin has-mother victoria). From these triples, other relationships can be inferred, such as (james has-wife victoria).
He notes that at the time, there were two competing theories about how to represent the meaning of words. The symbolic AI approach represented meanings explicitly using a structured graph, while the psychology approach suggested that meaning comes from learned semantic features, where words with similar meanings share similar features. Hinton unified these two ideas by using a neural network to learn the rules describing family relationships.
The symbolic AI approach to solving the task is to search for explicit rules to capture relationships between symbols, such as (x has-mother y) & (y has-husband z) => (x has-father z). Hinton’s neural network instead learned feature vectors for each word and used these learned features to predict the next word in a triple. Unlike the symbolic approach, which stored rules explicitly, the neural network encoded these rules and relationships implicitly in its weights, and used these learned weights to generate appropriate predictions. He notes that, unlike the symbolic approach, this neural network approach worked particularly well when there were sometimes rule violations.
Why current LLMs really do understand
"So some people think these things don’t really understand, they’re very different from us, they’re just using some statistical tricks. That’s not the case. These big language models for example, the early ones were developed as a theory of how the brain understands language. They’re the best theory we’ve currently got of how the brain understands language. We don’t understand either how they work or how the brain works in detail, but we think probably they work in fairly similar ways." - Geoffrey Hinton [6]
Hinton sees modern LLMs such as GPT-4 as descendants of the simple language model described above. The difference is that modern LLMs have many more neurons, process much more data, and have a different architecture. But fundamentally the way they work is similar to the simple language model. The fundamental idea is to turn symbols into feature vectors or vectors of neural activity in the hidden layers of the model and use the interaction of these vectors to predict the next word. One counterintuitive property of these neural systems is that, unlike symbolic AI systems, there are actually no words stored inside the neural network. The input and output words are symbols but all the processing in between is just weights and vectors of neuron activities and these are used to generate symbols in the output.
According to Hinton, it's reasonable to say that LLMs really do understand sentences. He argues that the way LLMs work, which involves converting words to feature vectors, computing complex interactions between features, and predicting the next word really is understanding and is similar to how the human brain understands language. Given that humans understand language, and LLMs work approximately the same way as the human brain, we can say that LLMs also understand language.
Hinton also dismisses the argument that LLMs are 'just' auto-completing the next word. Although LLMs are trained to predict the next word in sentences, Hinton argues that the auto-complete analogy is misleading since traditionally autocomplete uses the statistics of n-grams which is not how LLMs work. Instead, LLMs use this simple training objective to learn useful feature detectors in their hidden layers. Through training, they acquire a deep understanding of language and the world, far beyond simple pattern matching, enabling them to grasp context and meaning.
Another argument against the ability of LLMs to understand language is the problem of LLM hallucinations. First, Hinton argues that the psychological term confabulate is a more accurate term than hallucinate to describe what happens when LLMs make up facts. Confabulations are common in humans too and a well-known problem with eyewitness accounts. According to Hinton, the reason for confabulation in humans and LLMs is the same: both brains and LLMs store knowledge in the weights of a neural network and reconstruct events based on the weights. This process is inherently unreliable because no facts are explicitly encoded in the weights as symbols. Instead, symbols representing facts are generated using the weights and this process can produce false facts and confabulations [4].
Finally, Hinton describes how he gave a logical puzzle to GPT-4 which it was able to solve. The puzzle is, "The rooms in my house are painted blue or white or yellow. Yellow paint fades to white within a year. In two years time I want them to be white. What should I do and why?" GPT-4’s answer was to repaint the blue rooms to white and leave the yellow rooms since they would fade to white. Hinton argues that the ability of LLMs to solve novel logical puzzles like these is evidence that they really understand language [3].
The future of AI according to Hinton
Until now, I’ve only described Hinton’s views on the history of AI and current AI models. The next sections describe his views on the future of AI and discuss topics such as whether AI will surpass human intelligence and whether AI could be an existential risk to humanity.
Digital vs biological intelligence
"For a long, long time I thought that if we made artificial neural nets more like real neural nets they would get better and that was the belief that I had until the beginning of 2023, and it was then that I started believing that maybe neural nets using backpropagation on digital computers are already somewhat different from us. So they're similar in the way they hold knowledge as features and interactions between features, but they're different in that you could have many different copies of the same model and each copy can learn something and then they can share very efficiently because they all work in exactly the same way, and that makes them much better than us at sharing. So they're much higher power than us, they need much more energy, but they're much better at sharing. And I stopped believing that if you make them more like brains they'll get better." - Geoffrey Hinton [7]
Previously I described how there was the logic-inspired or symbolic approach to AI which is totally artificial, and the biologically-inspired AI approach which involves training artificial neural networks. But according to Hinton, there is also a biologically-inspired and an artificial way of training neural networks. The biologically-inspired approach trains neural networks on low-power analog hardware like the brain whereas the artificial approach, which is used to train LLMs today, trains a neural network on high-power digital hardware such as GPUs.
Current artificial neural networks run on normal computers which use digital hardware that stores information precisely as binary digits and the transistors in a computer are running at a relatively high voltage allowing them to store binary digits very exactly. This form of of highly reliable and precise computation was invented because historically computer programs were written in programming languages that specify exactly what the computer should do and these programs had to run reliably and exactly.
In contrast, the human brain is analog. Rather than using a general purpose computer to simulate a neural network, in the brain the activities of neurons are directly implemented in the hardware. According to Hinton, the main advantage of this approach is that analog hardware can run neural networks with much less energy than digital hardware. Whereas the brain consumes about 20 watts of power, training digital models like LLMs requires megawatts of power (50,000 times more power).
Advantages of digital intelligence
Although digital hardware consumes much more energy than analog hardware, digital neural networks have many advantages over analog neural networks according to Hinton.
One major advantage of digital neural networks is that they can easily be copied and share information with other copies at a very high rate which enables them to learn quickly. Since artificial neural networks are stored as binary digits on reliable digital hardware, it makes artificial neural networks independent of their hardware and essentially immortal. This makes it possible to clone the model and then run several copies of it on different computers. For example, you could run the Llama 3 LLM model on a GPU in the cloud or on your laptop.
While several model copies are training on different computers in parallel, each model can learn from different data. This is called data parallelism. After each training step, the models share what they have learned with each other by averaging their gradients across all copies. This averaged gradient is then used by each model to update its weights using gradient descent. This process allows the model to learn faster by combining knowledge from all the data being processed in parallel.
Neural networks based on analog hardware such as the human brain can't use data parallelism because the hardware of each analog neural network is different, making it difficult to share information directly. For example, I can’t ask you to read a book and instantly share all the knowledge you learned with me just by merging my brain with yours.
Instead, humans share information using language where a shared intermediate information format (a language) is used to share information but the bandwidth of language is much lower than sharing gradients directly. Consequently, humans can only share a few bytes of information per second whereas digital neural networks can share gigabytes of information per second (a rate one billion times faster).
According to Hinton, the ability of digital neural networks to learn using multiple copies of the same model and then condense all the knowledge these copies have learned into one model is one of the reasons why LLMs like GPT-4 know thousands of times more facts than any one person.
Backpropagation vs the brain
"I was developing learning algorithms for biological systems that could run in a biological system which didn't use backpropagation and I couldn't make them work as well as the backpropagation algorithm that we were running in these digital systems and they would work for small networks but when I scaled it up, the digital ones always scaled up much better than the biological ones and suddenly I thought, it might not be my fault, it might not be that my learning algorithm is just a bad learning algorithm, it might be that these digital systems just are better and that's when I suddenly changed my mind about how long before we get superintelligence." - Geoffrey Hinton [8]
Another possible advantage of digital neural networks over analog neural networks is that they might have a better learning algorithm than the learning algorithm used by the human brain.
In his last several years at Google, Hinton worked on developing new learning algorithms for neural networks running on analog hardware such as the forward-forward algorithm. But he struggled to develop a learning algorithm that worked as well as backpropagation in digital neural networks. For a long time, Hinton believed that to make computers smarter, we needed to make them more like the human brain. But in 2023, he realized that maybe neural networks trained with backpropagation on digital computers have a better learning algorithm than the brain’s learning algorithm.
The human brain has 100 trillion connections while LLMs such as GPT-4 only have about 1 trillion connections. Despite having fewer connections, Hinton estimates that GPT-4 knows thousands of times more facts than any person [4]. According to Hinton, part of the reason is that LLMs read far more text than a human will ever read but another reason might be that backpropagation is a superior learning algorithm.
Hinton won the 2024 Nobel Prize in Physics for his work on Boltzmann machines which use a learning algorithm that is more brain-like than backpropagation. However, today neural networks trained with backpropagation are far more popular than Boltzmann machines because they work better in practice.
Hinton used to believe that superintelligent AI was decades away, but because of these recent updates, he now believes that there is a 50% probability that AI will surpass human intelligence in the next 20 years [7].
Existential risk from AI
"I think it's quite conceivable that humanity is just a passing phase in the evolution of intelligence. You couldn't directly evolve digital intelligence, it requires too much energy and too much careful fabrication. You need biological intelligence to evolve so that it can create digital intelligence. The digital intelligence can then absorb everything people ever wrote in a fairly slow way, which is what ChatGPT has been doing. But then it can start getting direct experience of the world and learn much faster. And it may keep us around for a while to keep the power stations running, but after that, maybe not." - Geoffrey Hinton [9]
Hinton believes that AI could surpass human intelligence in the next 20 years and that superintelligent AI would be an existential risk to the survival of humanity.
Why? Well according to Hinton, there are very few examples of less intelligent things being controlled by more intelligent things. One example he gives is babies being able to influence their mother to get food and attention. But he notes that this relationship was specifically evolved. Apart from that example, more intelligent agents tend to control less intelligent ones and therefore humanity might lose control of the world to AIs if they surpass our intelligence.
According to Hinton, AIs will be more useful if they are agentic and agentic AIs will be able to take actions and create their own subgoals. And one subgoal that will be useful for almost any AI agent is to get more control such as acquiring more computing resources or money. And so we might end up competing with AIs for resources and that could lead to human extinction if AIs take all the resources. This concern is similar to existing AI safety concepts such as instrumental convergence.
Hinton is also concerned about evolution occurring in AIs. Although the goals of AIs might initially be designed by humans, Hinton believes that if AIs can start replicating themselves, evolution could start occurring in the AI population. The problem with this is that evolution by natural selection often favors selfish behavior. AIs that hoard resources and create copies of themselves might out-compete more benevolent AIs and over time evolution could cause the behavior of AIs to become misaligned with humanity’s interests.[3]
"Some people think that we can make these things be benevolent, but if they get into a competition with each other, I think they’ll start behaving like chimpanzees and I’m not convinced you can keep them benevolent. If they get very smart and get any notion of self-preservation, they may decide they’re more important than us." - Geoffrey Hinton [4]
When asked about the likelihood of human extinction from AI, Hinton acknowledges that there is a wide range of views on the subject. On the optimistic side, there’s Yann LeCun, who also won the Turing award for deep learning, who believes the existential risk from AI is near zero. And on the pessimistic side, people like Eliezer Yudkowsky believe that superintelligent AI will almost certainly lead to human extinction. While Hinton admits to having a naturally pessimistic outlook, after considering the full range of opinions, he believes there's a 10-20% chance that superintelligent AI will cause human extinction.
"I tend to be slightly depressive so I think we haven't got a clue, so 50% is a good number. But other people think we have got some clue, and so I moderate that to 10% to 20%." - Geoffrey Hinton [10]
Actions we should take to reduce existential risk from AI
We stand a good chance of surviving it but we better think very hard about how to do that." - Geoffrey Hinton [10]
Hinton has also shared some thoughts on what we should do to reduce the existential risk from superintelligent AI.
He says that the obvious way to avoid the existential risk from AI is to not create superintelligent AIs in the first place. But he thinks this strategy is unlikely to work because of competition between countries and companies and because AI will be so useful (though he still thinks it's a reasonable strategy for people to try):
"So for climate change, for example, stop burning carbon ... I mean, the equivalent would be stop developing AI. I think that might be a rational decision for humanity to make at this point, but I think there's no chance they'll make that decision because of competition between countries and because it's got so many good uses ... For atom bombs, there really weren't that many good uses." - Geoffrey Hinton [10]
He has also shared some thoughts on what governments and companies could do to reduce existential risk from AI. One suggestion he has is that governments should force companies to do more research on AI safety. For example, governments could insist that companies spend 10% of their resources on AI safety research. Without government intervention, companies might be incentivized to rush the deployment of new models and spend minimal resources on safety.
He also emphasizes the importance of AI companies doing empirical AI safety research to understand how to make AI safe:
"Certainly one thing we should do is, as we make things more intelligent, as the big companies edge towards superintelligence, they can actually do experiments on how these things might get out of control before they're smarter than us. And anybody who's written a computer program knows that you write the computer program and then it doesn't work and then you realize you misunderstood something or didn't think of something. And so empirical checking of things is really crucial. You can't just do arm chair prediction of everything. And I think they should force the big companies to do experiments on how these things try and get out of control. And I think we already know some of the ways they will. So we'll give them subgoals because agents are much more effective at planning your holiday if they can set up sub-goals of sort of getting you there and finding a hotel and stuff and you don't want to micromanage them, you want them to create the sub-goals. But they will then start creating subgoals like ‘if I only had a little more control I could do things better’ and that could easily lead them to wanting to take over. I think we need to do experiments on that because at present it's all just theorizing. We don't really have any experience with things more intelligent than us or how to deal with them." - Geoffrey Hinton [7]
Finally, Hinton says that because it's in no one's interest to allow AI to take over, countries and companies could collaborate to ensure that AI is beneficial in a way similar to how the US and the Soviet Union avoided nuclear war during the Cold War:
"My one hope is that because if we allowed it to take over it would be bad for all of us, we could get the US and China to agree like we could with nuclear weapons, which were bad for all of us. We're all in the same boat with respect to the existential threat. So we all ought to be able to cooperate on trying to stop it." - Geoffrey Hinton [9]
Two future AI scenarios
Hinton sees two main future possibilities for the relationship between humans and AIs: either AIs take over and humanity goes extinct, or humanity successfully learns to live with superintelligent AIs.
To imagine what life might be like with superintelligent AIs, Hinton describes a scenario where there is a dumb CEO with a very intelligent personal assistant who's much smarter and makes most of the key decisions. So Hinton imagines a future where we might all have superintelligent personal assistants who act in our best interest:
“If you could somehow understand a way in which it never had any ego, it never wanted to have more copies of itself, it was perfectly happy to be like a very intelligent executive assistant for a very dumb CEO and it was perfectly happy in that role. That's what we want, right? So there is a good scenario here, which is we could all have executive assistants far smarter than us” - Geoffrey Hinton [10]
References
- Full interview: "Godfather of artificial intelligence" talks impact and potential of AI
- Why the Godfather of AI Fears What He’s Built (The New Yorker)
- "Godfather of AI" Geoffrey Hinton: The 60 Minutes Interview
- Prof. Geoffrey Hinton - "Will digital intelligence replace biological intelligence?" Romanes Lecture (University of Oxford)
- What Does BERT Learn about the Structure of Language?
- 'Godfather of AI' on AI "exceeding human intelligence" and it "trying to take over" (BBC Newsnight)
- Professor Geoffrey Hinton is presented with the UCD Ulysses Medal
- The Godfather in Conversation: Why Geoffrey Hinton is worried about the future of AI
- Possible End of Humanity from AI? Geoffrey Hinton at MIT Technology Review's EmTech Digital
- Q&A with Geoffrey Hinton (METR)
- ^
Actually it's usually not the case that each neuron is associated with one pattern or concept. Due to a phenomenon called superposition, often each neuron is activated by several different patterns.
- ^
This is a good description of how convolution neural networks (CNNs) work but I think vision transformers work in a slightly different way. CNNs were popular in the 2010s and are now fairly well-understood because of the work of interpretability researchers like Chris Olah but vision transformers have become more popular than CNNs since the early 2020s. Here's an article comparing how CNNs and vision transformers work and a paper on vision transformers. Here's a quote from the article: "If a CNN’s approach is like starting at a single pixel and zooming out, a transformer slowly brings the whole fuzzy image into focus."
- ^
See "Natural Selection Favors AIs Over Humans" by Dan Hendrycks for a detailed description of how evolution could occur in AIs.
Executive summary: Geoffrey Hinton, a pioneer in AI, discusses the history and current state of neural networks, and warns about potential existential risks from superintelligent AI while suggesting ways to mitigate these risks.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.