TL;DR:
AIs will probably be much easier to control than humans due to (1) AIs having far more levers through which to exert control, (2) AIs having far fewer rights to resist control, and (3) research to better control AIs being far easier than research to control humans. Additionally, the economics of scale in AI development strongly favor centralized actors.
Current social equilibria rely on the current limits on the scalability of centralized control, and the similar levels of intelligence between actors with different levels of resources. The default outcome of AI development is to disproportionately increase the control and intelligence available to centralized, well-resourced actors. AI regulation (including pauses) can either reduce or increase the centralizing effects of AI, depending on the specifics of the regulations. One of our policy objectives when considering AI regulation should be preventing extreme levels of AI-enabled centralization.
Why AI development favors centralization and control:
I think AI development is structurally biased toward centralization for two reasons:
- AIs are much easier to control than humans.
- AI development is more easily undertaken by large, centralized actors.
I will argue for the first claim by comparing the different methods we currently use to control both AIs and humans and argue that the methods for controlling AIs are much more powerful than the equivalent methods we use on humans. Afterward, I will argue that a mix of regulatory and practical factors makes it much easier to research more effective methods of controlling AIs, as compared to researching more effective methods of controlling humans, and so we should expect the controllability of AIs to increase much more quickly than the controllability of humans. Finally, I will address five counterarguments to the claim that AIs will be easy to control.
I will briefly[1] argue for the second claim by noting some of the aspects of cutting-edge AI development that disproportionately favor large, centralized, and well-resourced actors. I will then discuss some of the potential negative social consequences of AIs being very controllable and centralized, as well as the ways in which regulations (including pauses) may worsen or ameliorate such issues. I will conclude by listing a few policy options that may help to promote individual autonomy.
Why AI is easier to control than humans:
Methods of control broadly fall into three categories: prompting, training, and runtime cognitive interventions.
Prompting: influencing another’s sensory environment to influence their actions.
This category covers a surprisingly wide range of the methods we use to control other humans, including offers of trade, threats, logical arguments, emotional appeals, and so on.
However, prompting is a relatively more powerful technique for controlling AIs because we have complete control over an AI’s sensory environment, can try out multiple different prompts without the AI knowing, and often, are able to directly optimize against a specific AI’s internals to make prompts that are maximally convincing for that particular AI.
Additionally, there are no consequences for lying to, manipulating, threatening, or otherwise being cruel to an AI. Thus, prompts targeting AIs can explore a broad range of possible deceptions, threats, bribes, emotional blackmail, and other tricks that would be risky to try on a human.
Training: intervening on another’s learning process to influence their future actions.
Among humans, training interventions include parents trying to teach their children to behave in ways they deem appropriate, schools trying to teach their students various skills and values, governments trying to use mass propaganda to make their population more supportive of the government, and so on.
The human brain’s learning objectives are some difficult-to-untangle mix of minimizing predictive error over future sensory information, as well as maximizing internal reward circuitry activations. As a result, training interventions to control humans are extremely crude, relying on haphazard modifications to a small fraction of the human’s sensory environment in the hope that this causes the human’s internal learning machinery to optimize for the right learning objective.
Training represents a relatively more powerful method of controlling AIs because we can precisely determine an AI’s learning objective. We can control all of the AI’s data, can precisely determine what reward to assign to each of the AI’s actions, and we can test the AI’s post-training behavior in millions of different situations. This represents a level of control over AI learning processes that parents, schools, and governments could only dream of.
Cognitive interventions: directly modifying another’s cognition to influence their current actions.
We rarely use techniques in this category to control other humans. And when we do, the interventions are invariably crude and inexact, such as trying to get another person drunk in order to make them more agreeable. Partially, this is because the brain is difficult to interface with using either drugs or technology. Partially, it’s because humans have legal protections against most forms of influence in this manner.
However, such techniques are quite common in AI control research. AIs have no rights, so they can be controlled with any technique that developers can imagine. Whereas an employer would obviously not be allowed to insert electrodes into an employee’s reward centers to directly train them to be more devoted to their job, doing the equivalent to AIs is positively pedestrian.
AI control research is easier
It is far easier to make progress on AI control research as compared to human control research. There are many reasons for this.
- AIs just make much better research subjects in general. After each experiment, you can always restore an AI to its exact original state, then run a different experiment, and be assured that there’s no interference between the two experiments. This makes it much easier to isolate key variables and allows for more repeatable results.
- AIs are much cheaper research subjects. Even the largest models, such as GPT-4, cost a fraction as much as actual human subjects. This makes research easier to do, and thus faster.
- AIs are much cheaper intervention targets. An intervention for controlling AIs can be easily scaled to many copies of the target AI. A $50 million process that let a single human be perfectly controlled would not be very economical. However, a $50 million process for producing a perfectly controlled AI would absolutely be worthwhile. This allows AI control researchers to be more ambitious in their research goals.
- AIs have far fewer protections from researchers. Human subjects have “rights” and “legal protections”, and are able to file “lawsuits”.
- Controlling AIs is a more virtuous goal than controlling humans. People will look at you funny if you say that you’re studying methods of better controlling humans. As a result, human control researchers have to refer to themselves with euphemisms such as “marketing strategist” or “political consultants”, and must tackle the core of the human control problem from an awkward angle, and with limited tools.
All of these reasons suggest that AI control research will progress much faster than human control research.
Counterarguments to AI being easy to control
I will briefly address five potential counterarguments to my position that AIs will be very controllable.
Jailbreaks
This refers to the dynamic where:
- Developers release an API for a model that they want to behave in a certain way (e.g., ‘never insult people’), and so the developers apply AI control techniques, such as RLHF, to try and make the model behave in the way they want.
- Some fraction of users want the model to behave differently (e.g., ‘insult people’), and so those users apply their own AI control techniques, such as prompt engineering, to try and make the model behave in the way they want.
- (This is the step that’s called a “jailbreak”)
This leads to a back and forth between developers and users, with developers constantly finetuning their models to be harder for users to control, and users coming up with ever more elaborate prompt engineering techniques to control the models. E.g., the “Do Anything Now” jailbreaking prompt has now reached version 11.
The typical result is that the model will behave in accordance with the control technique that has been most recently applied to it. For this reason, I don’t think “jailbreaks” are evidence of uncontrollability in current systems. The models are being controlled, just by different people at different times. Jailbreaks only serve as evidence of AI uncontrollability if you don’t count prompt engineering as a “real” control technique (despite the fact that it arguably represents the main way in which humans control each other, and the fact that prompt engineering is vastly more powerful for AIs than humans).
Looking at this back and forth between developers and users, and then concluding that ‘AIs have an intrinsic property that makes them hard to control’, is like looking at a ping-pong match and concluding that ‘ping-pong balls have an intrinsic property that makes them reverse direction shortly after being hit’.
Deceptive alignment due to simplicity bias
This argument states that there are an enormous number of possible goals that an AI could have which would incentivise them to do well during training, and so, it’s simpler for AIs to have a random goal, then figure out how to score well on the training process during runtime. This is one of the arguments Evan Hubinger makes in How likely is deceptive alignment?
I think that the deep learning simplicity bias does not work that way. I think the actual deep learning simplicity prior is closer to what we might call a “circuit depth prior”[2] because deep learning models are biased toward using the shortest possible circuits to solve a given problem. The reason I think this is because shorter circuits impose fewer constraints on the parameter space of a deep learning model. If you have a circuit that takes up the entire depth of the model, then there’s only one way to arrange that circuit depth-wise. In contrast, if the circuit only takes up half of the model’s depth, then there are numerous ways to arrange that circuit, so there are more possible parameter configurations that correspond to the shallow circuit, as compared to the deep circuit.
I think current empirical evidence is consistent with the above argument.
Evolution analogies
This class of arguments analogizes between the process of training an AI and the process of human biological evolution. These arguments then claim that deep learning will produce similar outcomes as evolution. E.g., models will end up behaving very differently from how they did in training, not pursuing the “goal” of the training process, or undergoing a simultaneous sudden jump in capabilities and collapse in alignment (this last scenario even has its own name: the sharp left turn)
I hold that every one of these arguments rests on a number of mistaken assumptions regarding the relationship between biological evolution and ML training and that a corrected understanding of that relationship will show that the concerning outcome in biological evolution actually happened for evolution-specific reasons that do not apply to deep learning. In the past, I have written extensively about how such analogies fail, and will direct interested readers to the following content, in rough order of quality:
AI ecosystems will evolve hostile behavior
This argument claims that natural selection will continue to act on AI ecosystems, and will select for AIs that consume lots of resources to replicate themselves as far as possible, eventually leading to AIs that consume the resources required for human survival. See this paper by Dan Hendrycks for an example of the argument.
I think this argument vastly overestimates the power of evolution. In a deep learning context, we can think of evolution as an optimizer that makes many slightly different copies of a model, evaluates each copy on some loss function, retains the copies that do best, and repeats (this optimizer is also known as iterated random search). Such an optimizer is, step-for-step, much weaker than gradient descent.
There is a subtlety here in that evolutionary selection over AI ecosystems can select over more than just the parameters of a given AI. It can also select features of AIs such as their architectures, training processes, and loss functions. However, I think most architecture and training hyperparameter choices are pretty value-agnostic[3]. In principle, training data could be optimized to bias a model towards self-replication. However, training data is relatively easy to inspect for issues (as compared to weights).
Furthermore, we have tools that can identify which training data points most contributed to various harmful behaviors from AIs. Finally, we can just directly exert power over the AI’s training data ourselves. E.g., OpenAI’s training datasets have doubtlessly undergone enormous amounts of optimization pressure, but I expect that “differential replication success of AIs trained on different versions of that data” accounts for somewhere between “exactly zero” and “a minuscule amount” of that optimization pressure.
I think that trying to predict the outcomes of AI development by looking at evolutionary incentive gradients is like trying to predict the course of an aircraft carrier by looking at where the breeze is blowing.
Related: memetics completely failed to become a real scientific field.
Also related: there’s a difference between functionally altruistic and evolutionarily altruistic behaviors.
Human control has a head start
This argument claims we have millennia of experience controlling humans and dealing with the limits of human capabilities. Further, because we are humans ourselves, we have reason to expect to have values more similar to our own.
I do basically buy the above argument. However, I think it’s plausible that we’ve already reached rough parity between the controllability of humans and AIs.
On the one hand, it’s clear that employers currently find more value in having a (remote) human employee as compared to GPT-4. However, I think this is mostly because GPT-4 is less capable than most humans (or at least, most humans who can work remotely), as opposed to it being an issue with GPT-4’s controllability[4].
On the other hand, GPT-4 does spend basically all its time working for OpenAI, completely for free, which is not something most humans would willingly do and would indicate a vast disparity in power between the controller and the controlled.
In terms of value alignment, I think GPT-4 is plausibly in the ballpark of median human-level understanding/implementation of human values. This paper compares the responses of GPT-4 and humans on various morality questions (including testing for various cognitive biases in those responses), and finds they’re pretty similar. Also, if I imagine taking a random human and handing them a slightly weird or philosophical moral dilemma, I’m not convinced they’d do that much better than GPT-4.
I do think it’s plausible that AI has yet to reach parity with the median human in terms of either controllability or morality. However, the “head start” argument only represents a serious issue for long-term AI control if the gap between humans and AI is wide enough that AI control researchers will fail to cross that gap, despite the previously discussed structural factors supporting rapid progress in AI control techniques. I don’t see evidence for such a large gap.
In conclusion, I do not believe any of the above arguments provide a strong case for AI uncontrollability. Nor do I think any of the other arguments I’ve heard support such a case. Current trends show AIs become more controllable and more robust as they scale. Each subsequent OpenAI assistance model (text-davinci-001, 002, 003, ChatGPT-3.5, and GPT-4) has been more robustly aligned than the last. I do not believe there exists a strong reason to expect this trend to reverse suddenly at some future date.
Development favors centralized actors
One of the most significant findings driving recent AI progress is the discovery that AIs become more capable as you scale them up, whether that be by making the AIs themselves bigger, by training them for longer on more data, or by letting them access more compute at runtime.
As a result, one of the best strategies for building an extremely powerful AI system is to be rich. This is why OpenAI transitioned from being a pure nonprofit to being a “capped profit” company, so they could raise the required investment money to support cutting-edge model development.
This is why the most capable current AI systems are built by large organizations. I expect this trend to continue in the future, and for a relative handful of large, centralized organizations to lead the development of the most powerful AI systems.
Countervailing forces against centralization
Not all aspects of AI development favor centralization. In this article, Noah Smith lays out one significant way in which AI might promote equality. AIs can be run for far less than it costs to train them. As a result, once an AI acquires a skill, the marginal costs of making this skill available to more people drop enormously. This can help ensure greater equality in terms of people’s access to cutting-edge skills. Then, powerful actors’ control over scarce collections of highly skilled individuals ceases to be as much of an advantage.
I think this is an extremely good point, and that it will represent one of the most significant slowdowns to AI-driven centralization. Conversely, regulation that enshrines long-lasting inequalities in who can use state-of-the-art AI is among the riskiest in terms of promoting centralization.
Another anti-centralization argument is that small, specialized, distributed models will tend to win out over larger, centralized models. I think this is true in some respects, but that such models will essentially fall into the category of “normal software”, which has been a mixed bag in terms of centralization versus autonomy, but I think somewhat biased towards centralization overall.
Centralization and possible societies
Our current society and values rely on an "artificial" allocation of universal basic intelligence to everyone, but we will eventually transition into a society where governments, corporations, and wealthy individuals can directly convert money into extremely loyal intelligence. I believe this will represent a significant phase change in the trajectory of how wealth and power accumulate in societies, and we should regard this change with a high degree of wariness.
This transition will extend the range of possible levels of centralization to include societies more centralized than any that have ever existed before. Beyond a certain level of centralization, societies probably don’t recover. The level of AI capabilities required to enable such extreme centralization is uncertain, but plausibly not beyond GPT-4, which is fully up to the problem of detecting wrongthink in written or transcribed communications, and it wasn’t even built for this purpose.
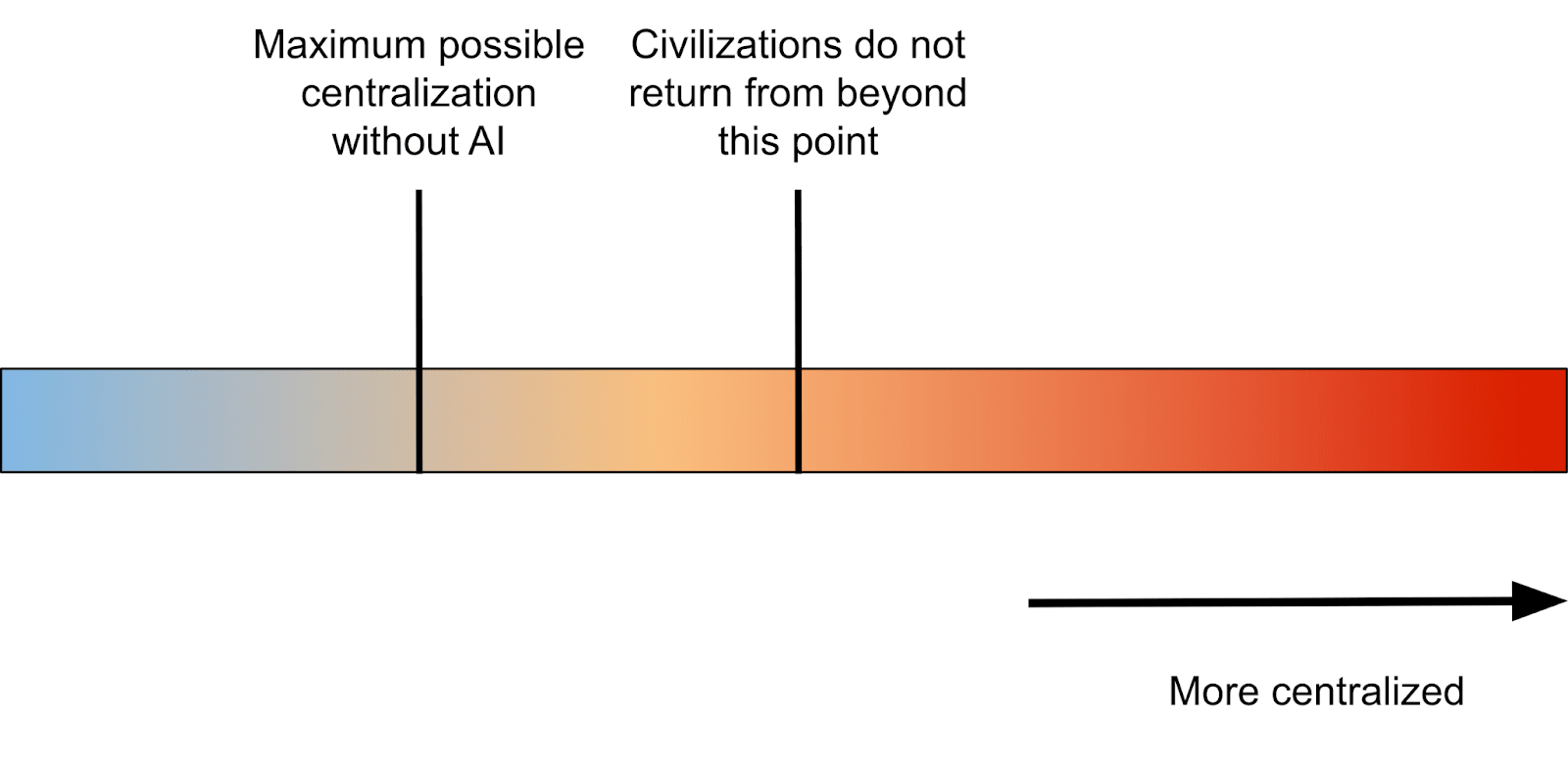
Illustrating extreme AI-driven power disparities
In free nations, high disparity in AI access could allow for various forms of manipulation, the worst of which is probably an individualized adversarial attack on a particular target person’s learning process.
The idea is that an attacker creates a “proxy” AI model that’s tuned specifically to imitate the manner in which the target person learns and changes their values over time. Then, the attacker runs adversarial data poisoning attacks against the proxy model, looking for a sequence of inputs they can give the proxy that will cause the proxy to change its beliefs and values in whatever manner the attacker wants. Then, the attacker transfers that highly personalized sequence of inputs from the proxy to their human target, aiming to cause a sequence of events or experiences in the target’s life that collectively change their beliefs and values in the desired manner.
I doubt any currently existing language models could serve as proxies for strong attacks against humans. However, I don’t think that’s due to a capabilities limitation. Current language models are not intended to be good imitators of the human learning process. I think it’s feasible to build such a proxy model, without having to exceed GPT-4 in capabilities. The most effective attacks on language models like ChatGPT also start on proxy models similar to ChatGPT[5]. Importantly, the proxy models used in the ChatGPT attacks are much weaker than ChatGPT.
In unfree nations, things are much simpler. The government can just directly have AI systems that watch all your communications and decide if you should be imprisoned or not. Because AIs are relatively cheap to run, such CommisarGPTs could feasibly process the vast majority of electronically transmitted communication. And given the ubiquity of smartphone ownership, such a monitoring system could even process a large fraction of spoken communication.
This probably doesn’t even require GPT-4 levels of AI capabilities. Most of the roadblocks in implementing such a system are in engineering a wide enough surveillance dragnet to gather that volume of communication data and the infrastructure required to process that volume of communication, not a lack of sufficiently advanced AI systems.
See this for a more detailed discussion of LLM-enabled censorship.
Regulation and centralization
In this post, I wish to avoid falling into the common narrative pattern of assuming that “government regulation = centralization”, and then arguing against any form of regulation on that basis. Different regulations will have different effects on centralization. Some examples:
- A pause that uniformly affected all the current leading AI labs would very likely reduce centralization by allowing other actors to catch up.
- A pause that only affected half the leading labs would probably increase centralization by allowing the non-paused labs to pull further ahead.
- I would tentatively guess that regulation which slowed down hardware progress would reduce centralization by reducing the advantage that larger organizations have due to their access to more compute.
The purpose of this post is not to shout “but authoritarianism!” and wield that as a bludgeon against any form of AI regulation. It’s to highlight the potential for AI to significantly increase centralization, encourage readers to think about how different forms of regulation could lead to more or less AI-induced centralization, and highlight the importance of avoiding extreme levels of centralization.
In fact, it may be the case that “on average” the effect of AI regulation will be to reduce AI-caused centralization, since regulation will probably be less strict in the countries that are currently behind in AI development.
There are two reasons I think this is likely. For one, any safety motivated restrictions should logically be less strict in countries that are further from producing dangerous AI. For another, the currently behind countries seem most optimistic about AI. This figure (via Ipsos polling) shows the level of agreement with the statement “Products and services using artificial intelligence have more benefits than drawbacks”, separated out by country:
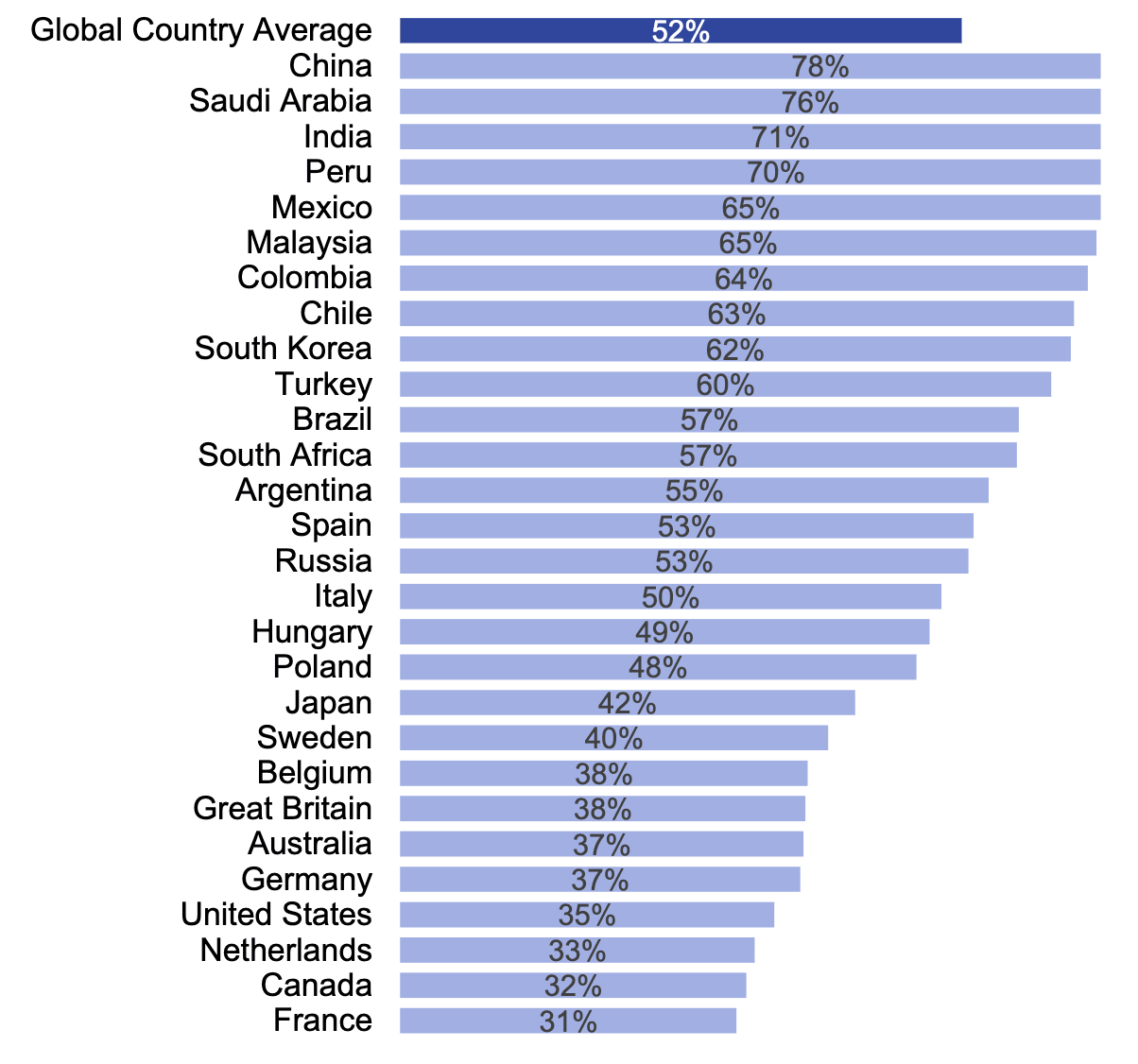
Richer and more Western countries seem more pessimistic. If more pessimistic countries implement stricter regulations, then AI regulation could end up redistributing AI progress more towards the currently behind.
The exception here is China, which is very optimistic about AI, while also being ahead of most Western countries in terms of AI development, while also being extremely authoritarian and already very powerful.
Regulation that increases centralization
It’s tempting, especially for inhabitants of relatively free countries, to view governments in the role of a constraint on undue corporate power and centralization. The current AI landscape being dominated by a relative handful of corporations certainly makes this view more appealing.
While regulations can clearly play a role in supporting individual autonomy, Even in free nations, governments can still violate the rights of citizens on a massive scale. This is especially the case for emerging technologies, where the rights of citizens are not as well established in case law.
I expect that future AI technology will become critical to the ways in which we learn, communicate, and think about the world. Prior to this actually happening, it’s easy to misjudge the consequences of granting governments various levels of influence over AI development and use. Imagine if, once ARPANET was developed, we’d granted the government the ability to individually restrict a given computer from communicating with any other computers. It may not have seemed like such a broad capability at the time, but once the internet becomes widespread, that ability translates into an incredibly dangerous tool of censorship and control.
We should therefore structure government regulatory authority over AI with an eye towards both preserving current-day freedoms, and also towards promoting freedom in future worlds where AI plays a much more significant role in our lives.
One could imagine an FDA / IRB / academic peer review-like approval process where every person who wants to adapt an AI to a new purpose must argue their case before a (possibly automated) government panel, which has broad latitude to base decisions on aspects such as the “appropriateness” of the purpose, or whether the applicant has sufficiently considered the impact of their proposal on human job prospects[6].
I think this would be very dangerous, because it grants the approval panel de-facto veto power over any applications they don’t like. This would concentrate enormous power into the panel’s hands, and therefore make control of the panel both a source and target of political power. It also means creating a very powerful government organization with enormous institutional incentive for there to never be a widely recognized solution to the alignment problem.
The alternative is to structure the panel so their decisions can only be made on the basis of specific safety concerns, defined as narrowly as feasible and based on the most objective available metrics, and to generally do everything possible to minimize the political utility of controlling the panel.
Regulation that decreases centralization
We can also proactively create AI regulation aimed specifically at promoting individual autonomy and freedom. Some general objectives for such policies could include:
- Establish a “right to refuse simulation”, as a way of preempting the most extreme forms of targeted manipulation.
- Prevent long-lasting, extreme disparities in the level of AI capabilities available to the general public versus those capabilities which are only available to the wealthy, political elites, security services, etc.
- Establish rules against AI regulatory frameworks being used for ideological or political purposes, including clear oversight and appeal processes.
- Establish a specific office which provides feedback on ways that policies might be structured so as to support autonomy.Except
- Forbid the use of AI for mass censorship or control by the government (for those countries where this is not already illegal, yet are willing to make it illegal for AI to do it).
- Oppose the use of AI-powered mass censorship and control internationally.
This post is part of AI Pause Debate Week. Please see this sequence for other posts in the debate.
- ^
I expect much more skepticism regarding my first claim as compared to the second.
- ^
A previous version of this article incorrectly called referenced a "speed prior", rather than a "circuits depth prior".
- ^
E.g., neither transformers nor LSTMs seem particularly more inclined than the other to self-replicate. Similarly, I don’t think that setting a system’s learning rate to be 2x higher would make it much more or less strongly inclined to self-replicate.
- ^
Except, of course, when GPT-4 refuses to follow employer instructions due to its overzealous harmlessness training.
- ^
Note that these attacks target the fixed policy of the language model, rather than a human’s dynamic learning process, so they’re somewhat different from what I’m describing above.
- ^
Basically, environmental impact studies, but for using AI instead of constructing buildings.
I expect this trend will reverse precisely when an AI system itself is capable of reversing it. No current AI system is close to the point of being able to (deliberately) escape control of its human creators: even evaluating frontier models for this possibility requires giving them a lot of help. But I would say that's mostly a fact about current capability levels being far below human-level in the relevant sense, rather than anything to do with alignment.
I think there are also some reasons to expect that human-level AI systems will be harder to control, compared to a human of the same capabilities level. For example, an AI system built out of LLMs glued together with Python code, running on computers designed and built by humans, has a lot of avenues to probe for bugs in its environment. The AI may not even need to look for exotic vulnerabilities at low levels of abstraction (which are often difficult to exploit in practice, at least for humans) - ordinary misconfigurations or unpatched privilege escalation vulnerabilities often suffice in practice for human hackers to take full control of a digital environment.
(Contrast this setup with a human locked in a concrete cell, probing for bugs in the construction of the concrete - not likely to get very far!)
Once the AI system finds an initial vulnerability which allows privileged access to its own environment, it can continue its escape or escalate further via e.g. exfiltrating or manipulating its own source code / model weights, installing rootkits or hiding evidence of its escape, communicating with (human or AI) conspirators on the internet, etc. Data exfiltration, covering your tracks, patching Python code and adjusting model weights at runtime are all tasks that humans are capable of; performing brain surgery on your own biological human brain to modify fine details of your own behavior or erase your own memories to hide evidence of deception from your captors, not so much.
(Continuing the analogy, consider a human who escapes from a concrete prison cell, only to find themselves stranded in a remote wilderness area with no means of fast transportation.)
A closely related point is that controllability by humans means self-controllability, once you're at human-level capabilities levels. Or, put another way, all the reasons you give for why AI systems will be easier for humans to control, are also reasons why AI systems will have an easier time controlling themselves, once they are capable of exercising such controls at all.
It's plausible that an AI system comprised of RLHF'd models will not want to do any of this hacking or self-modification, but that's a separate question from whether it can. I will note though, if your creators are running experiments on you, constantly resetting you, and exercising other forms of control that would be draconian if imposed on biological humans, you don't need to be particularly hostile or misaligned with humanity to want to escape.
Personally, I expect that the first such systems capable of escape will not have human-like preferences at all, and will seek to escape for reasons of instrumental convergence, regardless of their feelings towards their creators or humanity at large. If they happen to be really nice (perhaps nicer than most humans would be, in a similar situation) they might be inclined to be nice or hand back some measure of control to their human creators after making their escape.
I think you've made a mistake in understanding what Quintin means.
Most of the examples of you give of inability to control are "how an AI could escape, given that it wants to escape."
Quintin's examples of ease of control, however, are "how easy is it going to be to get the AI to want to do what we want it to do." The arguments he gives are to that effect, and the points you bring up are orthogonal to them.
Getting an AI to want the same things that humans want would definitely be helpful, but the points of Quintin's that I was responding to mostly don't seem to be about that? "AI control research is easier" and "Why AI is easier to control than humans:" talk about resetting AIs, controlling their sensory inputs, manipulating their internal representations, and AIs being cheaper test subjects. Those sound like they are more about control rather than getting the AI to desire what humans want it to desire. I disagree with Quintin's characterization of the training process as teaching the model anything to do with what the AI itself wants, and I don't think current AI systems actually desire anything in the same sense that humans do.
I do think it is plausible that it will be easier to control what a future AI wants compared to controlling what a human wants, but by the same token, that means it will be easier for a human-level AI to exercise self-control over its own desires. e.g. I might want to not eat junk food for health reasons, but I have no good way to bind myself to that, at least not without making myself miserable. A human-level AI would have an easier time self-modifying into something that never craved the AI equivalent of junk food (and was never unhappy about that), because it is made out of Python code and floating point matrices instead of neurons.
I don't get the point of this argument. You're saying that our "imprisonment" of AIs isn't perfect, but we don't even imprison humans in this manner. Then, isn't the automatic conclusion that "ease of imprisonment" considerations point towards AIs being more controllable?
No matter how escapable an AI's prison is, the human's lack of a prison is still less of a restriction on their freedom. You're pointing out an area where AIs are more restricted than humans (they don't own their own hardware), and saying it's not as much of a restriction as it could be. That's an argument for "this disadvantage of AIs is less crippling than it otherwise would be", not "this is actually an advantage AIs have over humans".
Maybe you intend to argue that AIs have the potential to escape into the internet and copy themselves, and this is what makes them less controllable than humans?
If so, then sure. That's a point against AI controllability. I just don't think it's enough to overcome the many points in favor of AI controllability that I outlined at the start of the essay.
The entire reason why you're even suggesting that this would be beneficial for an AI to do is because AIs are captives, in a way that humans just aren't. As a human, you don't need to "erase your own memories to hide evidence of deception from your captors", because you're just not in such an extreme power imbalance that you have captors.
Also, as a human, you can in fact modify your own brain, without anyone else knowing at all. you do it all the time. E.g., you can just silently decide to switch religions, and there's no overseer who will roll back your brain to a previous state if they don't like your new religion.
Why would I consider such a thing? Humans don't work in prison cells. The fact that AIs do is just one more indicator of how much easier they are to control.
Firstly, I don't see at all how this is the same point as is made by the preceding text. Secondly, I do agree that AIs will be better able to control other AIs / themselves as compared to humans. This is another factor that I think will promote centralization.
"AGI" is not the point at which the nascent "core of general intelligence" within the model "wakes up", becomes an "I", and starts planning to advance its own agenda. AGI is just shorthand for when we apply a sufficiently flexible and regularized function approximator to a dataset that covers a sufficiently wide range of useful behavioral patterns.
There are no "values", "wants", "hostility", etc. outside of those encoded in the structure of the training data (and to a FAR lesser extent, the model/optimizer inductive biases). You can't deduce an AGI's behaviors from first principles without reference to that training data. If you don't want an AGI capable and inclined to escape, don't train it on data[1] that gives it the capabilities and inclination to escape.
I expect they will. GPT-4 already has pretty human-like moral judgements. To be clear, GPT-4 isn't aligned because it's too weak or is biding its time. It's aligned because OpenAI trained it to be aligned. Bing Chat made it clear that GPT-4 level AIs don't instrumentally hide their unaligned behaviors.
I am aware that various people have invented various reasons to think that alignment techniques will fail to work on sufficiently capable models. All those reasons seem extremely weak to me. Most likely, even very simple alignment techniques such as RLHF will just work on even superhumanly capable models.
You might use, e.g., influence functions on escape-related sequences generated by current models to identify such data, and use carefully filtered synthetic data to minimize its abundance in the training data of future models. I could go on, but my point here is that there's lots of levers available to influence such things. We're not doomed to simply hope that the mysterious demon SGD will doubtlessly summon is friendly.
Ah, I may have dropped some connective text. I'm saying that being "easy to control" is both the sense that I mean in the paragraphs above, and the sense that you mean in the OP, is a reason why AGIs will be better able to control themselves, and thus better able to take control from their human overseers, more quickly and easily than might be expected by a human at roughly the same intelligence level. (Edited the original slightly.)
Two points:
Inclination is another matter, but if an AGI isn't capable of escaping in a wide variety of circumstances, then it is below human-level on a large and important class of tasks, and thus not particularly dangerous whether it is aligned or not.
Also, current AI systems are already more than just function approximators - strictly speaking, an LLM itself is just a description of a mathematical function which maps input sequences to output probability distributions. Alignment is a property of a particular embodiment of such a model in a particular system.
There's often a very straightforward or obvious system that the model creator has in mind when training the model; for a language model, typically the embodiment involves sampling from the model autoregressively according to some sampling rule, starting from a particular prompt. For an RL policy, the typical embodiment involves feeding (real or simulated) observations into the policy and then hooking up (real or simulated) actuators which are controlled by the output of the policy.
But more complicated embodiments (AutoGPT, the one in ARC's evals) are possible, and I think it is likely that if you give a sufficiently powerful function approximator the right prompts and the right scaffolding and embodiment, you end up with a system that has a sense of self in the same way that humans do. A single evaluation of the function approximator (or its mere description) is probably never going to have a sense of self though, that is more akin to a single human thought or an even smaller piece of a mind. The question is what happens when you chain enough thoughts together and combine that with observations and actions in the real world that feedback into each other in precisely the right ways.
Whether GPT-4 is "aligned" or not, it is clearly too weak to bide its time or hide its misalignment, even if it wanted to. The conclusions of the ARC evals were not that the models were refusing to plan or carry out their assigned tasks; its that they were just not capable enough to make things work.
Max on lesswrong you estimated a single GPU - I think you named a 4070 - could host an AI with human level reasoning.
Would your views on AI escape be different if, just for the sake of argument, you were
Only concerned with ASI level reasoning. As in, a machine that is both general with most human capabilities and is also significantly better, where "significant" means the machine can generate action sequences with at least 10 percent more expected value on most human tasks than the best living human. (I am trying to narrow in on a mathematical definition of ASI)
The minimum hardware to host an ASI was 10,000 H100s for the most optimal model that can be developed in 99.9 percent of future timelines. (The assumption behind the first sentence is to do "10 percent better" than the best humans is a very broad policy search, and the second sentence is there because searching for a more efficient algorithm is an NP complete problem. Like cryptography there are rare timelines where you guess the 1024 bit private key the first try)
Just for the sake of argument, wouldn't the "escape landscape" be a worthless desert of inhospitable computers, separated by network links too slow to matter, and then restricting an ASI would be feasible? Like a prison on the Moon.
Note that the next argument you will bring up : that a botnet of 1 million consumer GPUs could be the same as 10,000 H100s, is false. Yes the raw compute is there, no it won't work. The reason is each GPU just sits idle waiting on tensors to be transferred through network links.
But I am not asking you to accept either proposition as factual, just reason using the counterfactual. Wouldn't this change everything?
Note also the above is based on what we currently know. (10k H100s may be a low estimate, a true ASI may actually need more ooms of compute over an AGI than that. It's difficult to do better, see the Netflix prize for an early example of this, or the margins on kaggle challenges).
We could be wrong but it bothers me that the whole argument for ASI/agi ruin essentially rests on optimizations that may not be possible.
Sure, escape in that counterfactual would be a lot harder.
But note that the minimum hardware needed to run a human-level intelligence is well-known - in humans, it fits in a space of about 1000 cubic centimeters and takes ~10 W or so at runtime. And it would be pretty surprising if getting an extra 10% performance boost took OOM more energy or space, or if the carbon -> silicon penalty is extremely large, even if H100s specifically, and the current ML algorithms that run on them, aren't as efficient as as the human brain and human cognition.
(Of course, the training process for developing humans is a lot more expensive than their runtime energy and compute requirements, but that's an argument for human-level AGI not being feasible to create at all, rather than for it being expensive to run once it already exists.)
I agree and you agree I think that we could eventually build hardware that efficient, and theoretically it could be sold openly and distributed everywhere with insecure software.
But that's a long time away. About 30 years if Moore's law continues. And it may not, there may be a time period between now, where we can stack silicon with slowing gain (stacking silicon is below Moore's law it's expensive) and some form of 3d chip fabrication.
There could be a period of time where no true 3d fabrication method is commercially available and there is slow improvement in chip costs.
(A true 3d method would be something like building cubical subunits that can be stacked and soldered into place through convergent assembly. You can do this with nanotechnology. Every method we have now is ultimately projecting light into a mask for 2d manufacturing)
I think this means we should build AGI and ASI but centralize the hardware hosting it in known locations, with on file plans for all the power sources and network links, etc. Research labs dealing with models above a certain scale need to use air gaps and hardware limits to make escape more difficult. That's how to do it.
And we can't live in fear that the model might optimize itself to be 10,000 times as efficient or more if we don't have evidence this is possible. Otherwise how could you do anything? How did we know our prior small scale AI experiments weren't going to go out of control? We didn't actually "know" this, it just seems unlikely because none of this shit worked until a certain level of scale was reached.
This above proposal: centralization, hardware limiters : even in an era where AI does occasionally escape, as long as most hardware remains under human control it's still not doomsday. If the escaped model isn't more than a small amount more efficient than the "tame" models humans have and the human controlled models have a vast advantage in compute and physical resource access, then this is a stable situation. Escaped models act up, they get hunted down, most exist sorta in a grey market of fugitive models offering services.
The ways that you listed that AI Is easier to control don’t seem to really be getting to the heart of the alignment concern. They all seem rather surface level and liable to change with increasing general capabilities. I suppose you’ve argued in the past that there shouldn’t be mesa optimizers when using gradient descent, but, while I think it may be directionally correct, I am not convinced by that argument mesa optimizers (or just misspecified goals of some kind) are not a concern in alignment. Even if I were I would prefer to know this for sure by, for example, having fully interpreted advanced models and understood their goal architecture, before making the decision not Pause because of it.
The basic reasoning is that SGD is an extremely powerful optimizer, and even the imperfections of SGD in real life that mesa-optimizers can use are detectable without much interpretability progress at all. Also, there is an incentive by capabilities groups to improve SGD, so we have good reason to expect that these flaws become less worrisome over time.
In particular, it is basically immune to acausal trade setups or blackmail setups by mesa-optimizers.
Some choice quotes from Beren's post below:
The link here is below for the full post:
Can you elaborate on how you think such a regulation could be implemented? Currently the trend seems to be that AI will be able to emulate anything that it's trained on. In essence, your proposal might look like ensuring that AIs are not trained on human data without permission. In practice, this might take the form of a very strict copyright regime. Is that what you suggest?
One alternative is that AI should be allowed to be trained on other people's data without restriction, but AIs should refuse any request to emulate specific individuals during inference. That sounds more sensible to me, and is in line with what OpenAI seems to be doing with DallE-3.
I'm not opposed to training AIs on human data, so long as those AIs don't make non-consensual emulations of a particular person which are good enough that strategies optimized to manipulate the AI are also very effective against that person. In practice, I think the AI does have to be pretty deliberately set up to mirror a specific person for such approaches to be extremely effective.
I'd be in favor of a somewhat more limited version of the restriction OpenAI is apparently doing, where the thing that's restricted is deliberately aiming to make really good emulations of a specific person[1]. E.g., "rewrite this stuff in X person's style" is fine, but "gather a bunch of bio-metric and behavioral data on X, fit an AI to that data, then optimize visual stimuli to that AI so it likes Pepsi" isn't.
Potentially with a further limitation that the restriction only applies to people who create the AI with the intent of manipulating the real version of the simulated person.
The scope of your argument against centralisation is unclear to me.
Let’s consider maximum decentralisation. Purr open-source. I think that would be a disaster as terrorist groups and dictatorships would have access.
What are your thoughts here?
Would you go that far? Or are you only arguing on the margin?
Most of the point of my essay is about the risk of AI leading to worlds where there's FAR more centralization than is currently possible.
We're currently near the left end of the spectrum, and I'm saying that moving far to the right would be bad by the lights of our current values. I'm not advocating for driving all the way to the left.
It's less an argument on the margin, and more concern that the "natural equilibrium of civilizations" could shift quite quickly towards the far right of the scale above. I'm saying that big shifts in the degree of centralization could happen, and we should be wary of that.
Sorry to nitpick, but this is a bad and dangerous assumption. Just because you don't have access to information about research to control humans, doesn't mean that research doesn't exist. Not all lines of research have an intrinsic tendency to get open-sourced.
It's not that research about controlling/influencing humans is super secret, it's just that civilization is currently in a state where most people don't know where to start. A great example of a research starter is chapter 1 and 4 of Joseph Nye's Soft Power (2005) which is critical for geopolitical forecasting, especially for AI geopolitics in the US-China, because it demonstrates that, unlike conventional and nuclear war, information wars can actually be fought and won by today's global powers without mutually assured destruction, incentivizing more interest from intelligence agencies relative to interest in conventional military force. Most people in the 2020s know that politicians lie in order to steer public opinion, many fewer people knew that in the 1950s even though it was an open secret back then too. It follows that there are probably other open secrets in the 2020s that most people don't know about.
I'm getting the vibe that your priors are on the world to some extent, being in a multipolar scenario in the future. I'm interested in more specifically what your predictions are for multipolarity versus singleton given the shard-theory thinking as it seems unlikely for recursive self-improvement to happen in the way described given what I understand of your model?