I really appreciate the RP Moral Weights Project and before I say anything I’d like to thank the amazing RP crew for their extremely thoughtful and kind responses to this critique. Because of their great response I feel a little uncomfortable even publishing this, as I respect both the project and the integrity of the researchers.[1]
This project helped me appreciate what it might mean for animals to suffer, and gave a framework to compare animal and human suffering. RP’s impressive project is now a crux in the EA “space”. 80,000 hours recently used these numbers as a key factor in elevating factory farming to a "most pressing world problem" and many forum posts use their median welfare estimates as a central number in cost-effectiveness analysis. Of the first 15 posts this debate week, 7 referenced the project.
As I considered their methodology, I reflected that the outcome hinged on a series of difficult and important junctures, which led to the surprising (to many) conclusion that the moral weight of animals might not be so different from humans. However through my biased, anthropocentric lens[2], it seemed to me that these key junctures lean towards favoring animals .
I present four critical junctures, where I think the Moral Weights project favored animals. I don’t argue that any of their decisions are necessarily wrong, only that each decision shifts the project outcome in an animal friendly direction and sometimes by at least an order of magnitude.[3]
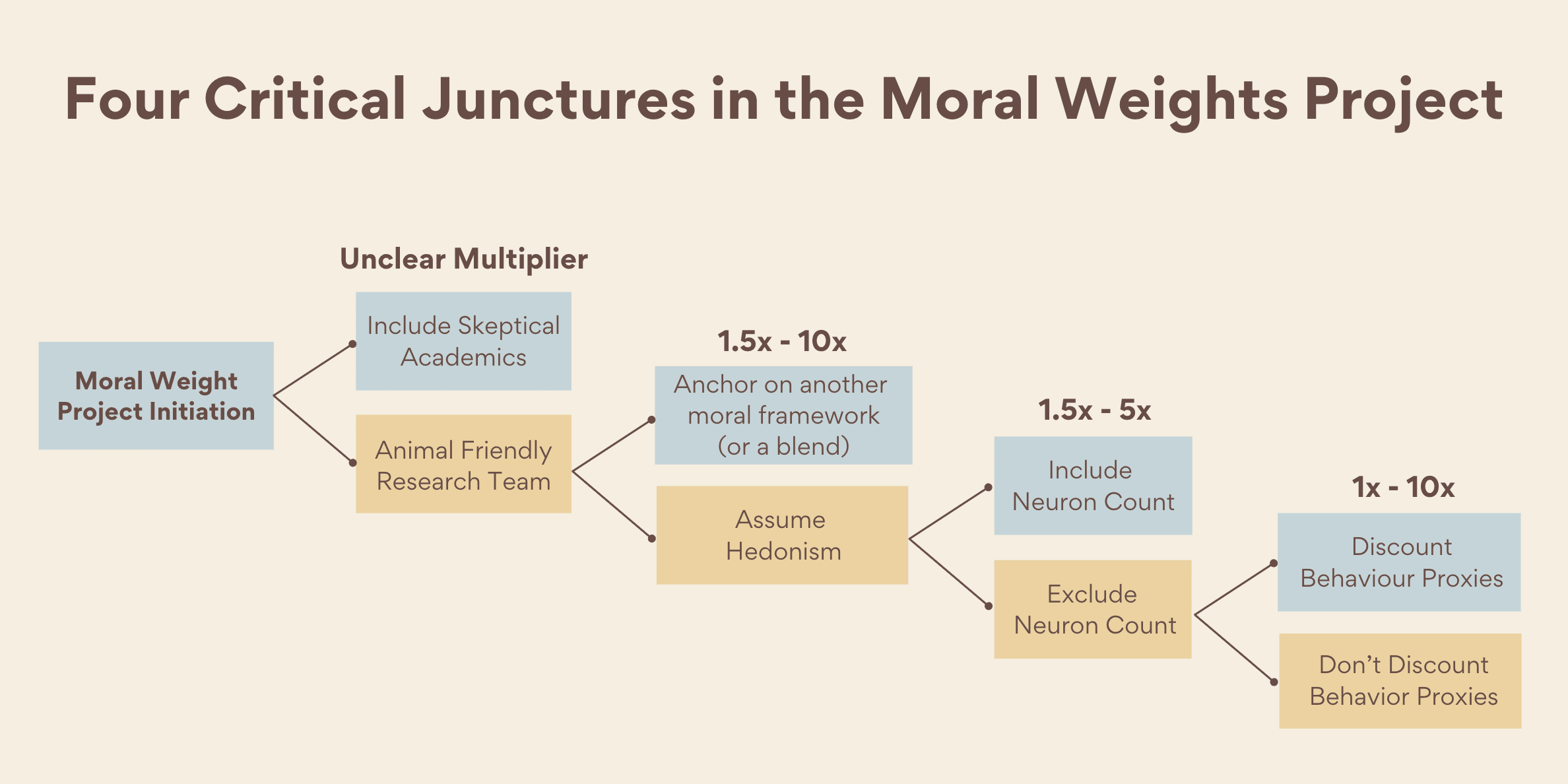
Juncture 1 – Animal Friendly Researchers (Unclear multiplier)
“Our team was composed of three philosophers, two comparative psychologists (one with expertise in birds; another with expertise in cephalopods), two fish welfare researchers, two entomologists, an animal welfare scientist, and a veterinarian.”
It's uncontroversial to assume that researchers’ findings tend towards their priors - what they already believe[4]. This trend is obvious in contentious political subjects. In immigration research classically conservative think tanks are more likely to emphasise problems with immigration compared with libertarian or liberal ones[5]. In the Moral weights project, researchers either have histories of either being animal advocates or are at best neutral - I couldn’t find anyone who had previously expressed public skepticism at animals having high moral weight. Major contributors Bob Fischer and Adam Shriver have a body of work which supports animal welfare.
Bob Fischer “… I should acknowledge that I'm not above motivated reasoning either, having spent a lot of the last 12 years working on animal-related issues. In my own defence, I've often been an animal-friendly critic of pro-animal arguments, so I think I'm reasonably well-placed to do this work.”
Could this bias have been mitigated? I’m a fan of adversarial research collaborations – that might have been impossible here, but perhaps one or two researchers with somewhat animal-welfare-critical opinions could have been included on the team. Also this particular project had more important subjective junctures and decisions to be made than most projects, which could mean even more potential for researcher bias.
Juncture 2 - Assuming hedonism (1.5 x - 10x multiplier)
The researchers choose to assume hedonism, which is likely to favor animals more than other single moral frameworks or a blend of frameworks.
At this juncture, there was one statement I thought questionable.
“We suggest that, compared to hedonism, an objective list theory might 3x our estimate of the differences between humans’ and nonhumans’ welfare ranges. But just to be cautious, let’s suppose it’s 10x. While not insignificant, that multiplier makes it far from clear that the choice of a theory of welfare is going to be practically relevant.”
When we build a model like this, I don’t think we should consider whether any decision is large enough to be “practically relevant”, especially not at an early stage of our process when there are multiple junctures still to come. Instead we do the best we can to include all variables we think might be important no matter how small. Then perhaps at the end of the entire project we can reflect on what might have happened had we made different decisions, and how much those decisions might affect the final result.
Juncture 3: Dismissing Neuron count (1.5x – 5x multiplier)
Perhaps the most controversial juncture was to largely dismiss neuron count. To RP’s credit, they understand the importance and devote an in-depth article which explains why they don’t think neuron count is a very useful proxy for animal moral weight. I’m not going to discuss their arguments or counter-arguments, but neuron count is one of the more concrete, objective measures we have to compare animals to humans, it does correlate fairly well with intelligence and our intuitions. and it has been widely used in the past as a proxy for moral weight..
Pigs have 200x less neurons than humans, while the final RP median moral weight for pigs is 2x smaller than humans. This huge gulf means that even giving neuron count a more significant weighting would have made a meaningful difference.
Interestingly, in RP’s neuron count analysis they state “Given this, we suggest that the best role for neuron counts in an assessment of moral weight is as a weighted contributor, one among many, to an overall estimation of moral weight.” - yet they don’t end up including neuron counts in what I would consider a meaningful way[6]
Juncture 4 – Not Discounting Behavioral Proxies (2x - 10x)[7]
RP put in a groundbreaking effort to scour animal behavior research to determine how similar animal welfare related behavior is to human behavior. They call these “Hedonic proxies” and “Cognitive proxies”. If an animal exhibits a clear positive response for any behavioral proxy, RP effectively assumes for scoring purposes that each behavioral proxy translates to an equivalent intensity of experience in a human[8].
They applied no discount to these behavioral proxies. For example if pigs display anxiety-like behavior, fear-like behavior and flexible self-protective behavior, their score for these proxies is the same as a human. My counter-assumption here is that where humans display anxiety, fear or self-protective behavior, both the behaviors themselves and the corresponding experience are likely to be more intense or bigger sized than a pig, chicken or shrimp that exhibits these behaviors[9]. Phil Trammell explores this here, saying “Even if humans and flies had precisely the same qualitative kinds of sensory and cognitive experiences, and could experience everything just as intensely, we might differ in our capacities for welfare because our experiences are of different sizes”.
I understand this would be difficult to discount in a logical, systematic way[10], but not-discounting at all means animals are likely favored.
To RPs credit, they acknowledge this issue as a potential criticism at the end of their project... “You’re assessing the proxies as either present or absent, but many of them obviously come either in degrees or in qualitatively different forms.” [11]
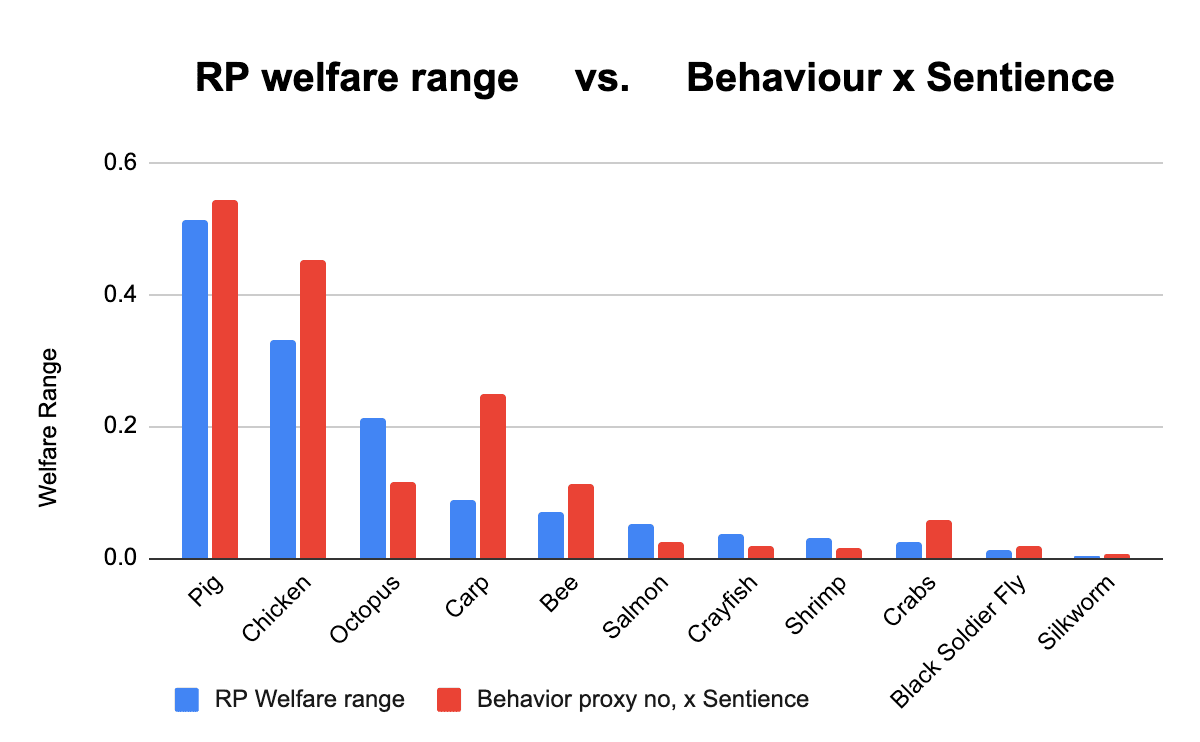
After the project decided to assume hedonism and dismiss neuron count, the cumulative percent of these 90 behavioral proxies became the basis for their welfare range estimates. Although the team used a number of models in their final analysis, these models were mostly based on different weightings of these same behavioral proxies.[12]. Median final welfare ranges are therefore fairly well approximated by the simple formula.
(Behavioral proxy percent) x (Probability of Sentience) = Median Welfare range
The graph below shows how similar RP’s final moral weights are to this simple formula.
Final Reflections
At four critical junctures in their moral weights project, RP chose animal friendly options ahead of alternatives. If less animal-friendly options had been chosen at some or all these junctures, then the median welfare range could have been lower by between 5 - 500 times.
Bob Fischer pointed out three other junctures that I didn’t include here where RP didn’t favor animals (full response in appendix)[13]. These include not allowing animals capacities that humans might lack, assigning zero value to animals on behavioral proxies with no available evidence, and giving considerable weight to neurophysiological proxies. My inclination though is that these might be less important junctures, as I don’t think any of these would swing the final results more than 2x
I’ll stress again that I’m not arguing here that any of RPs decisions were necessarily wrong, only that they were animal friendly.
Again an enormous thanks to the RP team for their generous feedback and looking forward to any response.
- ^
I also really like that RP prioritise engaging with forum responses probably more than any other big EA org, and seem to post all their major work on here.
- ^
I run a human welfare organization and have devoted my adult life so far to this cause, so in the EA community I’m on the human biased side. Interestingly though in the general population I would be comfortably in the top 1% of animal friendliness.
- ^
Where possible I’ve tried to quantify how much these decisions might have influenced their final median welfare range, based on what the RP researchers themselves expressed.
- ^
Jeff Kaufman and the discussion thread get into this in a bit more detail here https://forum.effectivealtruism.org/posts/H6hxTrgFpb3mzMPfz
- ^
- ^
Neuron counts were included , but I suspect neuron count weighting is under 5% which I don’t consider meaningful (I couldn't figure it out exactly).
- ^
I just guessed this multiplier, as RP didn't have a range here
- ^
Phil Trammell puts it a slightly different way “Regarding hedonic intensity, their approach is essentially to make a list of ways in which humans can feel good or bad, at least somewhat related to the list of capacities above, and then to look into how many items on the list a given nonhuman species seems to check off.”
- ^
I understand there are differences of opinion here as to whether humans are likely to have more intense experience than soldier flies, but on balance assuming no difference still likely favours animals
- ^
Perhaps the complexity of the behavior could have been used to compare the behavior with humans? This though wouldn’t be accessible purely through accessing published research
- ^
@Will Howard🔹 makes a related but different point here. https://forum.effectivealtruism.org/posts/7JT5p2eWJyarAQJ7A/what-are-the-strongest-arguments-for-the-side-you-voted?commentId=GBCHiw8PwcmQ7PMsa
- ^
Neurophysiological proxies were also included, but given far less weight than behavioural proxies as is made clear by the graph below
- ^
1) “We could have allowed capacities that humans lack, such as chemoreception or magnetoreception, to count toward animals ’welfare ranges. Instead, we used humans as the index species,assuming that humans have every proxy with certainty. This precludes the possibility of any other animal having welfare ranges larger than humans. In other words, from the very outset of the project, we assumed humans were at least tied for having the highest welfare range.
2) It’s plausible that animals possess some of the traits for which we weren’t able to find evidence— as well as some of the traits for which we found negative evidence. Nevertheless, we effectively treated all unknowns and negative judgments as evidence for larger welfare range differences. We could have made some attempt to guess at how many of the proxies animals possess, or simply assign very low credences to proxy possession across the board, but we opted not to do that.
3) We gave considerable weight to certain neurophysiological proxies that, in our estimation, entail that there are implausibly large differences in the possible intensities of valenced states.We did this largely out of respect for the judgment of others who have used them as proxies for differences in welfare ranges.Without these proxies, the differences between our welfare range estimates would be smaller still.” - ^
Here I just guess a multiplier, as unlike the other 2 junctures I can’t base it off RP’s numbers. I included a null 1x multiplier here, as if neuron count was weighted higher in an earlier juncture, this could arguably already account for not discounting behavioral proxies.
- ^
This isn't 10,000 (10 x 100 x 10) because I feel like if neuron counts were already heavily weighted, this would probably make the lack of discounting of behavioural proxies largely obsolete, so I counted this as x 1 rather than x10.
Thanks, Nick, both for your very kind words about our work and for raising these points. I’ll offer just a few thoughts.
You raise some meta-issues and some first-order issues. However, I think the crux here is about how to understand what we did. Here’s something I wrote for a post that will come out next week:
I don’t think you’ve said anything that should cause someone to question that headline result. To do that, we’d want some reason to think that a different research team would conclude that chickens feel pain much less intensely than humans, some reason to think that neuron counts are good proxies for the possible intensities of pain states across species, or some principled way of discounting behavioral proxies (which we should want, as we otherwise risk allowing our biases to run wild). In other words, we’d want more on the first-order issues.
To be fair, you’re quite clear about this. You write:
But the ultimate question is whether our decisions were wrong, not whether they can be construed as animal-friendly. That’s why the first-order issues are so important. So, for instance, if we should have given more weight to neuron counts, so be it: let’s figure out why that would be the case and what the weight should be. (That being said, we could up the emphasis on neuron counts considerably without much impact on the results. Animal/human neuron counts ratios aren’t vanishingly low. So, even if they determined a large portion of the overall estimates, we wouldn’t get differences of the kind you’ve suggested. In fact, you could assign 20% of your credence to the hypothesis that animals have welfare ranges of zero: that still wouldn’t cut our estimates by 10x.)
All that said, you might contest that the headline result is what I’ve suggested. In fact, people on the Forum are using our numbers as moral weights, as they accept (implicitly or explicitly) the normative assumptions that make moral weights equivalent to estimates of differences in the possible intensities of valenced states. If you reject those assumptions, then you definitely shouldn’t use our numbers as moral weights. That being said, if you think that hedonic goods and bads are one component of welfare, then you should use our numbers as a baseline and adjust them. So, on one level, I think you’re operating in the right way: I appreciate the attempt to generate new estimates based on ours. However, that too requires a bunch of first-order work, which we took up when we tried to figure out the impact of assuming hedonism. You might disagree with the argument there. But if so, let’s figure out where the argument goes wrong.
One final point. I agree—and have always said—that our numbers are provisional estimates that I fully expect to revise over time. We should not take them as the last word. However, the way to make progress is to engage with hard philosophical, methodological, and empirical problems. What’s a moral weight in the first place? Should we be strict welfarists when estimating the cost-effectiveness of different interventions? How should we handle major gaps in the empirical literature? Is it reasonable to interpret the results of cognitive biases as evidence of valenced states? How much weight should we place on our priors when estimating the moral importance of members of other species? And so on. I’m all for doing that work.
Thanks for the very clear answer, Bob.
Indeed, I also feel that the post didn't really justify the claim that results are too animal-friendly.
In your Welfare Range Estimate and your Introduction to Moral Weights, you don't mention the potential of humans to make a positive impact, instead focusing only on averting DALYs. Perhaps I'm missing something here, but isn't this neglecting the hedonic goods from a positive utilitarian perspective and only addressing it from the negative utilitarian side of things?
Please let me know if this topic is addressed in another entry in your sequence, and thank you for the time you have spent researching and writing about these important topics!
Hi Josh. There are two issues here: (a) the indirect effects of helping humans (to include the potential that humans have to make a positive impact) and (b) the positive portion of human and animals' welfare ranges. We definitely address (b), in that we assume that every individual with a welfare range has a positive dimension of that welfare range. And we don't ignore that in cost-effectiveness analysis, as the main benefit of saving human lives is allowing/creating positive welfare. (So, averting DALYs is equivalent to allowing/creating positive welfare, at least in terms of the consequences.)
We don't say anything about (a), but that was beyond the scope of our project. I'm still unsure how to think about the net indirect effects of helping humans, though my tendency is to think that they're positive, despite worries about the meat-eater problem, impacts on wild animals, etc. (Obviously, the direct effects are positive!) Others, however, probably have much more thoughtful takes to give you on that particular issue.
There is some reason to believe that virtually everyone is too animal-unfriendly, including animal welfare advocates:
That's one way of constructing an uninformed prior, but that seems quite a bit worse than starting from a place of equal moral weight among cells, or perhaps atoms or neurons. All of which would give less animal friendly results, though still more animal-friendly results than mainstream human morality.
(And of course this is just a prior, and our experience of the world can bring us quite a long way from whichever prior we think is most natural.)
Cells, atoms and neurons aren't conscious entities in themselves. I see no principled reason for going to that level for an uninformed prior.
A true uninformed prior would probably say "I have no idea" but if we're going to have some idea it seems more natural to start at all sentient individuals having equal weight. The individual is the level at which conscious experience happens, not the cell/atom/neuron.
Why do you think the individual is the level at which conscious experience happens?
(I tend to imagine that it happens at a range of scales, including both smaller-than-individual and bigger-than-individual. I don't see why we should generalise from our experience to the idea that individual organisms are the right boundary to draw. I put some reasonable weight on some small degree of consciousness occurring at very small levels like neurons, although that's more like "my intuitive concept of consciousness wasn't expansive enough, and the correct concept extends here").
To be honest I'm not very well-read on theories of consciousness.
For an uninformed prior that isn't "I have no idea" (and I suppose you could say I'm uninformed myself!) I don't think we have much of an option but to generalise from experience. Being able to say it might happen at other levels seems a bit too "informed" to me.
IDK, structurally your argument here reminds me of arguments that we shouldn't assume animals are conscious, since we can only generalise from human experiences. (In both cases I feel like there's not nothing to the argument, but I'm overall pretty uncompelled.)
How far and how to generalize for an uninformed prior is pretty unclear. I could say just generalize to other human males because I can’t experience being female. I could say generalize to other humans because I can’t experience being another species. I could say generalize to only living things because I can’t experience not being a living thing.
If you’re truly uniformed I don’t think you can really generalize at all. But in my current relatively uninformed state I generalize to those that are biologically similar to humans (e.g. central nervous system) as I’m aware of research about the importance of this type of biology within humans for elements of consciousness. I also generalize to other entities that act in a similar way to me when in supposed pain (try to avoid it, cry out, bleed annd become less physically capable etc.).
I don't think you should give 0 probability to individual cells being conscious, because then no evidence or argument could move you away from that, if you're a committed Bayesian. I don't know what an uninformed prior could look like. I imagine there isn't one. It's the reference class problem.
You should even be uncertain about the fundamental nature of reality. Maybe things more basic than fundamental particles, like strings. Or maybe something else. They could be conscious or not, and they may not exist at all.
I certainly don’t put 0 probability on that possibility.
I agree uninformed prior may not be a useful concept here. I think the true uninformed prior is “I have no idea what is conscious other than myself”.
I don't think that gives you can actual proper quantitative prior, as a probability distribution.
Yeah if I were to translate that into a quantitative prior I suppose it would be that other individuals have roughly 50% of being conscious (I.e. I’m agnostic on if they are or not).
Then I learn about the world. I learn about the importance of certain biological structures for consciousness. I learn that I act in a certain way when in pain and notice other individuals do as well etc. That’s how I get my posterior that rocks probably aren’t conscious and pigs probably are.
Ok, this makes more sense.
What do you count as "other individual"? Any physical system, including overlapping ones? What about your brain, and your brain but not counting one electron?
I'm a bit confused if I'm supposed to be answering on the basis of my uninformed prior or some slightly informed prior or even my posterior here. Like I'm not sure how much you want me to answer based on my experience of the world.
For an uninformed prior I suppose any individual entity that I can visually see. I see a rock and I think "that could possibly be conscious". I don't lump the rock with another nearby rock and think maybe that 'double rock' is conscious because they just visually appear to me to be independent entities as they are not really visually connected in any physical way. This obviously does factor in some knowledge of the world so I suppose it isn't a strict uninformed prior, but I suppose it's about as uninformed as is useful to talk about?
That's an interesting argument thank you, and I think d others on the RP team might agree. Its a reasonable perspective to have.
I agree that 99.9% of people are likely to be too animal unfriendly, but personally (obviously from this post) think that probably animal welfare advocates are more likely to swing the other way given the strong incentives to be able to better advocate for animals (understandable), publishing impact, and just being deep in the animal thought world.
I agree that an uninformed prior would say that all individuals have equal moral weight, but I think we have a lot of information here so I'm not sure why that's super relevant here? Maybe I'm missing something.
Jeff Kaufmann raised some similar points to the 'animal-friendly researchers' issue here, and there was some extended discussion in the comments there you might be interested in Nick!
Thanks now that you mention I do remember that and that might have partly triggered my thinking about that juncture, FWIW I'll add a reference to that in.
I am far from an unbiased party since I briefly worked on the moral weight project as a (paid) intern for a couple of months, but for what it's worth, as a philosophy of consciousness PhD, it's not just that I, personally, from an inside point of view, think weighting by neuron count is bad idea, it's that I can't think of any philosopher or scientist who maintains that "more neurons make for more intense experiences", or any philosophical or scientific theory of consciousness that clearly supports this. The only places I've ever encountered the view is EAs, usually without formal background in philosophy of mind or cognitive science, defending focusing near-termist EA money on humans. (Neuron count might correlate with other stuff we care about apart from experience intensity of course, and I'm not a pure hedonist.)
For one thing, unless you are a mind-body dualist-and the majority of philosophers are not-it doesn't make sense to think of pain as like some sort of stuff/substance like water or air, that the brain can produce more or less of. And I think that sort of picture lies behind the intuitive appeal of more neurons=more intense experiences.
I'm sure that's true, but is anyone (or more than 1 or 2 people) outside of EA even really asking and publishing about that question about comparing intensity of pain between species and how much meeting count might matter regarding this?
I tried to read the referenced articles in the moral weights ticle about neuron count, and the articles I could read (that weren't behind a paywall) didn't talk about neuron count nor discussed comparing the intensity of pain between species? Id be interested to read anything which discussed this directly outside of the EA realm.
I kind of thought this was part of the reason why the moral weight's project is so important, as groups of researchers are deeply considering these questions in ways that perhaps others haven't before.
Yeah, that's a fair point, maybe I haven't seen it because no one has considered how to do the weighting at all outside EA. But my sense is that at the very least many theories are unfriendly to weighting by neuron count (though probably not all).
My inclination was that they were more cognitive pathway theories of how pain works, that might help answer the question on how likely animals were to feel pain rather than thinking much about quantifying that ( which is where neuron count might come in). But I skim read and didn't understand about half of it well so could easily have missed things.
Oh, this is a very interesting data point, I didn't know neuron counts weren't even proposed as a serious option in the literature.
I can't be sure that they aren't somewhere as "philosophy of consciousness", let alone cognitive science is a surprisingly big field, and this is not what I specialised in directly. But I have never seen it proprosed in a paper (though I haven't deliberately searched.)
I had a bit of a scan and I couldn't find it outside the EA sphere
Thanks for the post, Nick.
Note you have to practically disregard the models RP used to get to this range of the multiplier. "Welfare range with neuron counts" = "weight on neuron counts"*"welfare range based solely on neuron counts" + (1 - "weight on neuron counts")*"welfare range without neuron counts (RP's)" <=> "weight on neuron counts" = (1 - 1/"multiplier")/(1 - "welfare range based solely on neuron counts"/"welfare range with neuron counts"), where "multiplier" = "welfare range without neuron counts"/"welfare range with neuron counts". So you would need the following weights on neuron counts:
Thanks Vasco yeah my apologies I messed this one up, have changed it now. Where's the "OOps" emoji.
I think one should rely on RP's welfare ranges, but I believe the best animal welfare interventions would still be more cost-effective than the best in global health and development with your multipliers. These suggest the welfare ranges should be 0.258 % (= (1.5*10*10*100*1*10)^-0.5) as large. Adjusting my estimates based on this, corporate campaigns for chicken welfare would be 3.90 (= 2.58*10^-3*1.51*10^3) times as cost-effective as GiveWell's top charities, and Shrimp Welfare Project’s Humane Slaughter Initiative would be 112 (= 2.58*10^-3*43.5*10^3) times as cost-effective as GiveWell's top charities.
What do you have in mind by "more intense or bigger sized"?
FWIW, here's how I would probably think about it:
Thanks Michael for your response and suggested framework - I really respect your history of thinking deeply about this issue, and I'm sure you understand it far better than me. I read some of your posts and @trammell's post to try and inform myself about this issue and I confess that my understanding is partial at best.
When I say "intense or bigger sized" I'm talking about the experience, not the behaviour which may or may not approximate/indicate the experience. I might be thinking more along the lines of your "gradations in moral weight", or Trammell's "Experience size" concept.
Regardless of the framework I do believe that animals' experience when a similar behaviour to a human is displaced, is likely less "intense or bigger sized" than a human and so there could possibly be some kind of discount applied. I also acknowledge like you and RP that there's a smallish chance that some or all animals might be experiencing more.
Ah sorry, I should have read more carefully. You were clearly referring to the intensity or size of the experience, not of the behaviour. 4 hours of sleep and commenting before going to the airport. :P
I wrote more about experience size in the comments on trammell's post.
Glad to see you found my post thought-provoking, but let me emphasize that my own understanding is also partial at best, to put it mildly!
I also left a comment related to neuron counts and things similar to experience size in point 2 here.
I can see that for some people who have specific preferences about what entities should exists and how, this research can be informative. But it's a very narrow set of views.
My other opinion here is that impartial hedonism is crazy. If you just anchor to it without caveats, and you somehow got hold of significant power, most of the humans would fight you, because they have preferences, that you totally ignore. (E.g. if you have button to replace humans with other species that has 7% more welfare or place everyone in experience machines or whatever). I can understand it as some form of proxy, where sometimes it conforms to your intuitions, but sometimes it recommends you to stab your eyes out, and in these cases you ignore it. (and if you do it just for strategic reasons, you are looking like a paperclip maximizer who swears not to paperclip humans because otherwise it will face resistance and prob of death. tbh) And this is kind of undermining its ultimate legitimacy, in my eyes. It's not a good model of human preferences concerning other people / beings / entities / things.
I think these two comments by Carl Shulman are right and express the idea well:
https://forum.effectivealtruism.org/posts/btTeBHKGkmRyD5sFK/open-phil-should-allocate-most-neartermist-funding-to-animal?commentId=nt3uP3TxRAhBWSfkW
https://forum.effectivealtruism.org/posts/9rvLquXSvdRjnCMvK/carl-shulman-on-the-moral-status-of-current-and-future-ai?commentId=6vSYumcHmZemNEqB3
btw I think it's funny how carefully expressed this critique is for how heavy it is. "oh, that's just choices, you know, nothing true / false". Kind of goes in the same direction to the situation with voting, where almost no one the left side expressed their opinion and people on the right side don't feel like they have to justify it under scrutiny, just express their allegiance in comments.
You could also just replace everyone with beings with (much) more satisfied preferences on aggregate. Replacement or otherwise killing everyone against their preferences can be an issue for basically any utilitarian or consequentialist welfarist view that isn't person-affecting, including symmetric total preference utilitarianism.
It's also not a good model of human preferences concerning other people / beings / entities / things. In that I totally agree
how about sneakily placing them into experience machines or injecting them with happiness drugs? Also this "can be" is pretty uhhh weird formulation.
Maybe not that on its own, but if you also change their preferences in the right ways, yes, on many preference views. See my post here.
This is one main reason why I'm inclined towards "preference-affecting" views. On such views, it's good to satisfy preferences, but not good to create new satisfied preferences. If it were good to create new satisfied preferences, that could outweigh violating important preferences or totally changing people's preferences.
What do you mean?
Well, it seems pretty central to such proposals, like "oh yeah, the only thing that matters is happiness - suffering!" and then just serial bullet biting and/or strategic concessions. It's just a remark, nothing important really.
Hmm how about messing with which new agents will exist? Like, let's say farms will create 100 chickens of breed #1 and mistreat them at the level 10. But you can intervene and make it so such that they will create 100 chickens of breed #2 and mistreat them at the level 6. Does this possible action get some opinion from such systems?
Some such views would say it's good, including a narrow asymmetric view like Pummer (2024)'s (applied to preferences), negative utilitarianism, and wide preference-affecting views. On wide preference-affecting views, it's better to have a more satisfied preference than a less satisfied different one, and so a better off individual than a worse off different one (like the wide person-affecting views in Meacham (2012) and Thomas (2019)).
I'm most attracted to narrow asymmetric views like Pummer's, because I think they handle replacement and preference change best. I'm working on some similar views myself.
Strict narrow preference-affecting views, like presentism and necessitarianism (wrt preferences), would be indifferent. Presentism would only care about the preferences that already exist, but none of these chickens exist yet, so they wouldn't count. Necessitarianism would only care about the preferences that will exist either way, but none of the chickens' preferences would exist either way, because different chickens would exist between the two outcomes.
I have a some related discussion here.
Also, how do you balance actions that make less suffering vs less sufferers. Like, you also have another possible action to make it such that farms will create only 70 chickens of breed #3 and mistreat them at the level 10. How do you think about it comparatively. Like, how it cashes out, for chickens, because it's a pretty practical problem
Btw thanks for links I'll check them out
This will depend on the specific view, and person-affecting views and preference-affecting views can be pretty tricky/technical, in part because they usually violate the independence of irrelevant alternatives. I'd direct you to Pummer's paper.
I also think existing person-affecting and preference-affecting views usually do badly when choosing between more than two options, and I'm working on what I hope is a better approach.
It's kind of disappointing that it's not concrete enough to cash out even for such a simple and isolated decision.
I also checked out the Pummer lecture and it's kind of weird feeling but i think he doesn't disambiguate between "let's make my / ours preferences more coherent" and "let's figure out how to make social contract/coordination mechanisms/institutions more efficient and good". It's disappointing
I'd guess that there are concrete enough answers (although you may need to provide more info), but there are different views with different approaches, and there’s some tricky math involved in many of them.
Pummer is aiming at coherent preferences (moral views), not social contract/coordination mechanisms/institutions. It's a piece of foundational moral philosophy, not an applied piece.
Do you think his view isn't concrete enough, specifically? What would you expect?
>I'd guess that there are concrete enough answers (although you may need to provide more info), but there are different views with different approaches, and there’s some tricky math involved in many of them.
Yeah, I'm tempted to write a post here with chicken setup and collect the answers of different people, maybe with some control questions like "would you press a button that instantaneously and painlessly kills all the life on earth", so I'd have a reason to disregard them without reading. But, eh
>Pummer is aiming at coherent preferences (moral views), not social contract/coordination mechanisms/institutions.
and my opinion is that he is confused what is values and what is coordination problems, so he tries to bake the solutions of coordination problems into values. I'm fine with the level of concreteness he operates under, it's not like i had high expectations from academic philosophy
I'm curating this post. The issue of moral weights turned out to be a major crux in the AW vs GH debate, and I'm excited about more progress being made now that some live disagreements have been surfaced. I'm curating this post and @titotal's (link) as the "best in class" from the debate week on this topic.
On this post: The post itself does a good job of laying out some reasonable-to-hold objections to RP's moral weights. Particularly I think the point about discounting behavioural proxies is important and likely to come up again in future.
I think comment section is also very interesting, there are quite a few good threads:
1. @David Mathers🔸' comment which raises the point that the idea of estimating intensity/size of experience from neuron counts doesn't come up (much) in the academic literature. This was surprising to me!
2. @Bob Fischer's counterpoint making the RP case
3. This thread which gets into the issue of what counts as an uninformed prior wrt moral weights
I actually feel mildly guilty for my comment. It's not like I've done a proper search, it's not something I worked on directly, and I dislike neuron count weighting from a more inside view persepctive, so it's possible my memory is biased here. Not to mention that I don't actually no of any philosophers (beyond Bob and other people at RP themselves) who explicitly deny neuron count weighting. Don't update TOO much on me here!
Separate from your comment, I have seen comments like this elsewhere (albeit also mainly from Bob and other RP people), so I still think it's interesting additional evidence that this is a thing.
It seems like some people find it borderline inconceivable that neuron counts correspond to higher experience intensity/size/moral weight, and some people find it inconceivable the other way. This is pretty interesting!
This project and many participants on this forum this week also seem to be neglecting the positive utilitarian perspective. 1 human saved has the potential to make an immense positive impact on the world, whereas animals do not.
Possible effects like these are worth considering, but they're not part of moral weights in the sense meant here. Moral weights are only one thing you should consider when comparing possible interventions, not an all-things-considered score, including all possible flow-through effects.
As such, what is at stake here is not "the positive utilitarian perspective". Moral weights do include positive welfare of individuals, they just don't include possible (positive or negative) side-effects of helping different individuals.
Thank you - that is helpful and does make more sense. I was under the false impression that moral weights were designed to be the only thing people ought to consider when comparing interventions, and I'm curious how many people on both sides of the argument have a similar misconception.
Well, to be fair, a human saved also has the potential to have an immense negative impact (for instance, actively supporting factory farming).
I understand the sentiment a about ripple effects, but I find this way of phrasing it unfortunate. Saving the life has positive impact, its the actions of the person after that which could be negative.
The possibility that the saved person's future actions could be negative is of great delicacy.
One problem comes when we stack the deck by ascribing the positive effects of the saved person's future actions to the lifesaving intervention but refuse to do the same with the saved person's negative actions. That makes the lifesaving intervention look more attractive vis-a-vis other interventions that are on the table.
My own tentative thinking -- at least for GiveWell-style beneficiaries[1] -- to balance this out is to count both the positive and negative downstream expected effects of the person's choices in the calculus, but with a floor of zero / neutral impact from them. I could try to come up with some sort of philosophical rationale for this approach, but in the end counting a toddler's expected future actions against them on net feels way too much like "playing God" for me. So the value I ascribe to saving a life (at least for GiveWell-style beneficiaries) won't fall below the value I'd assign without consideration of the person's expected future actions.
I say this to bracket out the case of, e.g., an adult who has caused great harm through their deliberate actions and would be expected to continue causing that harm if I rescued them from a pond.
Executive summary: The Rethink Priorities Moral Weights Project may be biased towards favoring animals due to four key methodological decisions, potentially inflating animal welfare estimates by 10-1000 times compared to alternative approaches.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.