Metaculus's Q4 Benchmark series is now live. Click here to learn more and to compete for $30,000. Benchmark the state of the art in AI forecasting against the best humans on real-world questions.
Metaculus's Q3 AI Benchmarking Series aimed to assess how the best bots compare to the best humans on real-world forecasting questions, like those found on Metaculus. Over the quarter we had 55 bots compete for $30,000 on 255 weighted questions with a team of 10 Pros serving as a human benchmark. We found that Pro forecasters were significantly better than top bots (p = 0.036) using log scoring with a weighted t-test.
This main result compares the median forecast of 10 Pro Forecasters against the median forecast of 9 top bots on a set of 113 questions that both humans and bots have answered.
That analysis follows the methodology we laid out before the resolutions were known. We use weighted scores & weighted t-tests throughout this piece, unless explicitly stated otherwise.
We further found that:
- The Pro forecaster median was more accurate than all 34 individual bots that answered more than half of the weighted questions. The difference was statistically significant in 31 of those comparisons.
- The top bots have worse calibration and discrimination compared to Pros.
- The top bots are not appropriately scope sensitive.
- The Metaculus single shot bot intended as baseline powered by GPT-4o finished slightly higher than the bot powered by Claude 3.5. The Metaculus bot powered by GPT-3.5 finished last out of 55 bots, worse than simply forecasting 50% on every question.
Selecting a Bot Team
We identify the top bots by looking at a leaderboard that includes only questions that were asked to the bots, but not the Pro forecasters. Using a weighted t-test, we calculated a 95% confidence interval for each bot and sorted the bots by their lower bounds. The table below shows that the top 10 bots out of 55 all had average Peer scores over 7 and answered over 100 weighted questions.
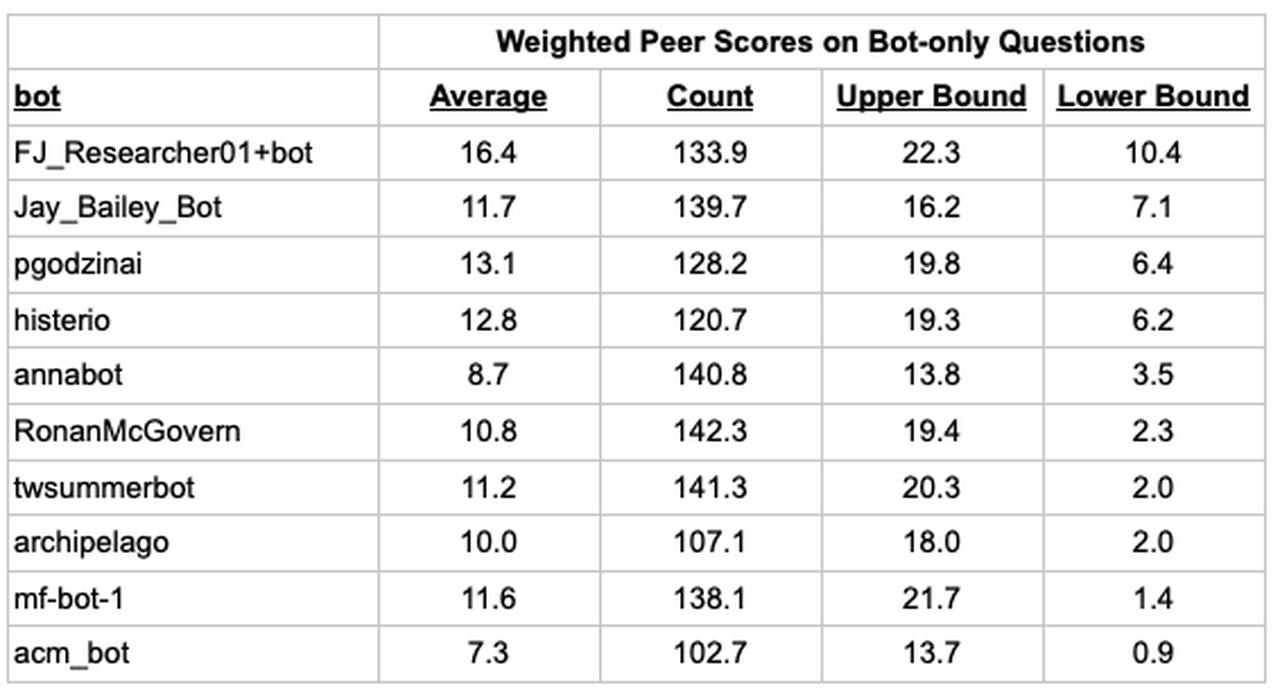
Having identified the top 10 bots, we then calculated the median forecasts for a variety of different team sizes – from including only the top 2 bots to including the top 10 bots – again on the bot-only questions. The table below shows the average weighted Baseline scores of the bot team median forecast for different team sizes (Baseline scores are rescaled log scores).
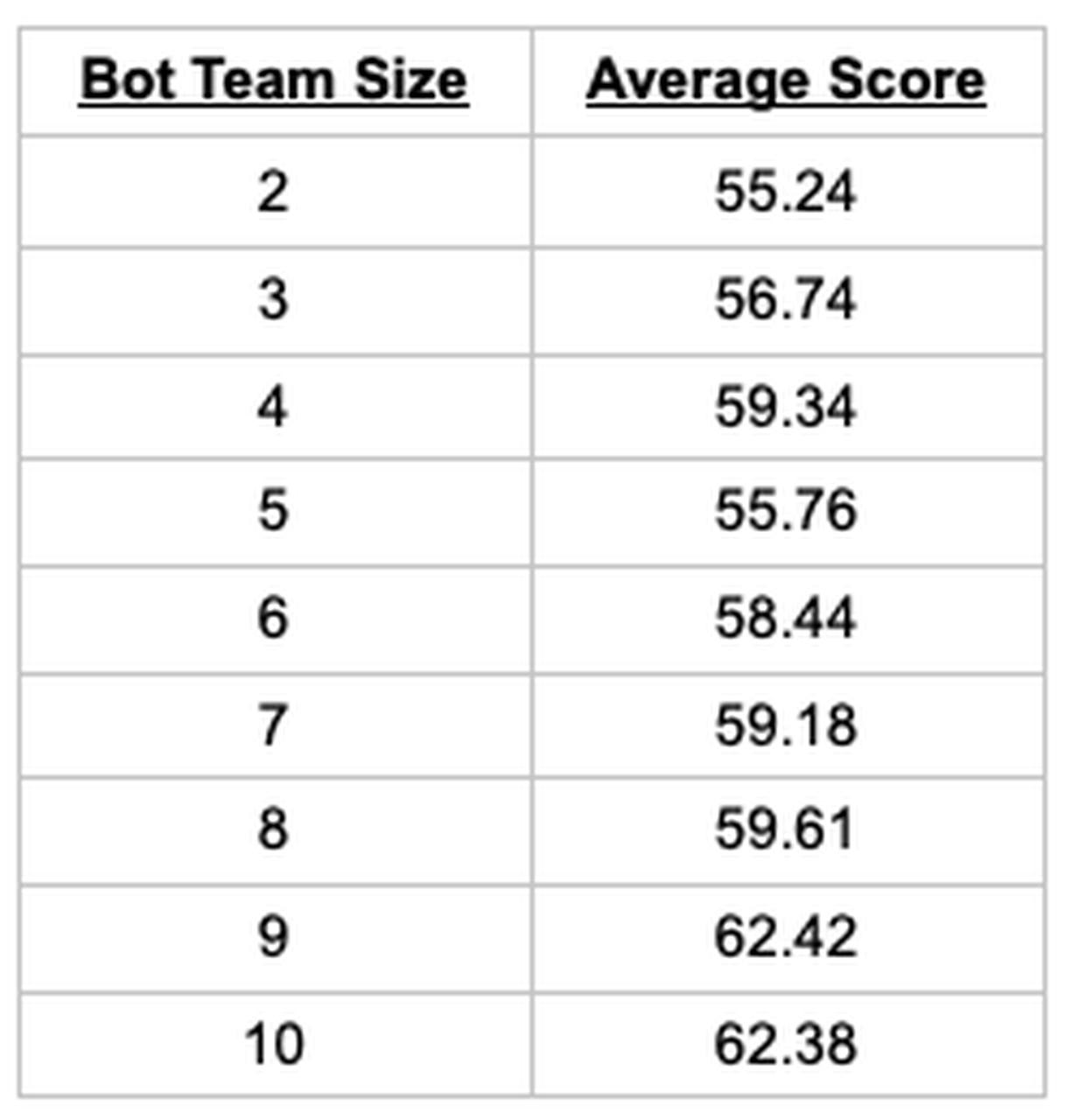
Following our methodology, we selected a 9 bot team since it had the best score.
Comparing the Bots to Pros
To compare the bots to Pros we used only the questions that both answered. We calculated the median forecasts of the bot team and the Pro forecasters. We calculated the Head-to-head Peer score and associated 95% confidence intervals from a weighted two-sided t-test. This is equivalent to a weighted paired t-test using log scores.We found an average bot team Head-to-head score of -11.3 with a 95% confidence interval of [-0.7, -21.8] over 113 weighted questions. Our methodology tells us that the bot team is worse than the Pro team at a conventional 5% significance level.
To put a -11.3 average Head-to-head Peer score into perspective, here are a few points of reference:
- Imagine a perfect forecaster who forecasts the true probability of 50% on a series of questions. Another forecaster who randomly forecasts either 28% or 72% on those questions will receive an expected -11.3 average Head-to-head Peer score.
- If the ground truth probability was 10% and a perfect forecaster forecast 10%, then a forecaster who randomly forecasts either 1.4% or 30% will receive an expected -11.3 average Head-to-head Peer score.
Below we show an unweighted histogram of the Head-to-head scores of the bot team. (The Head-to-head score is equivalent to 100 * ln(bot_median/pro_median) for a question that resolves Yes.)
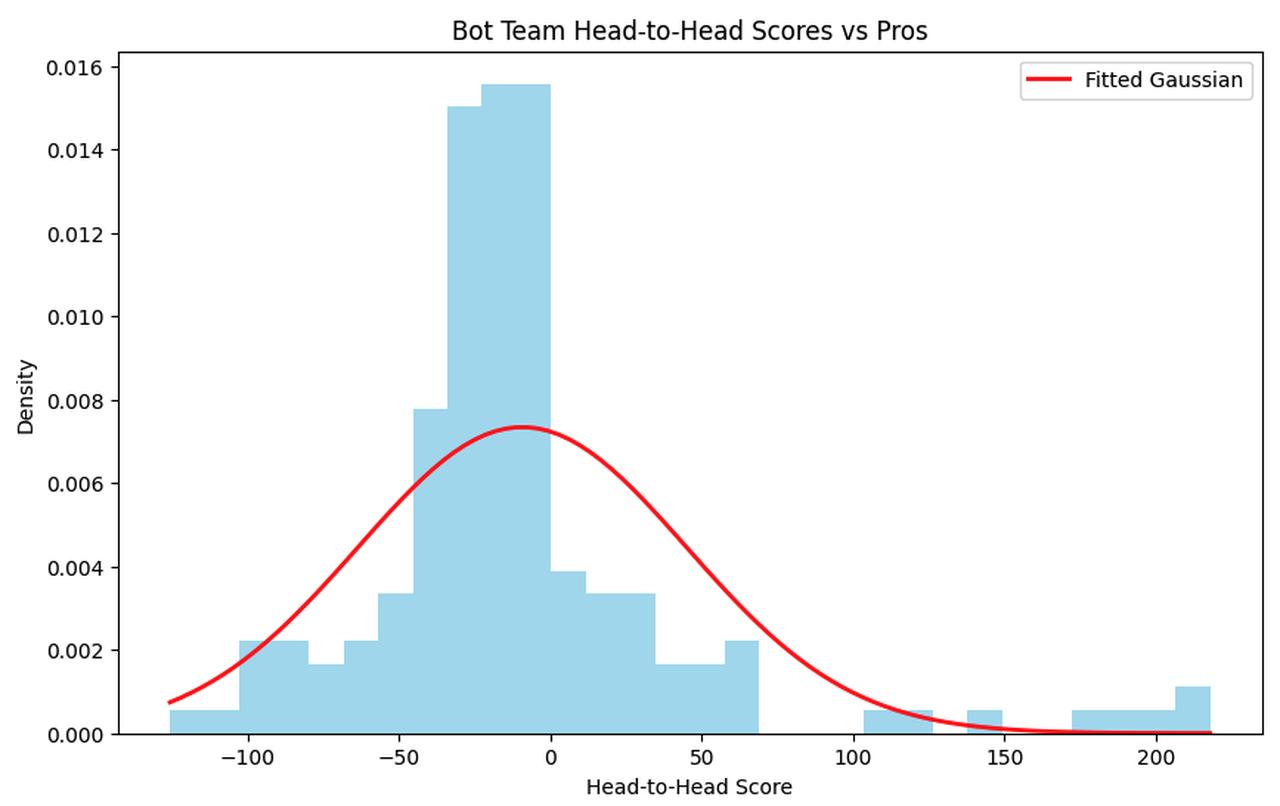
A few observations:
- The bots have more positive outlier scores than negative outliers.
- The bots have a lot of scores that are mildly negative between [-30, 0].
Why is this? Let’s look at the 5 questions the bots got the worst scores on relative to the Pros.
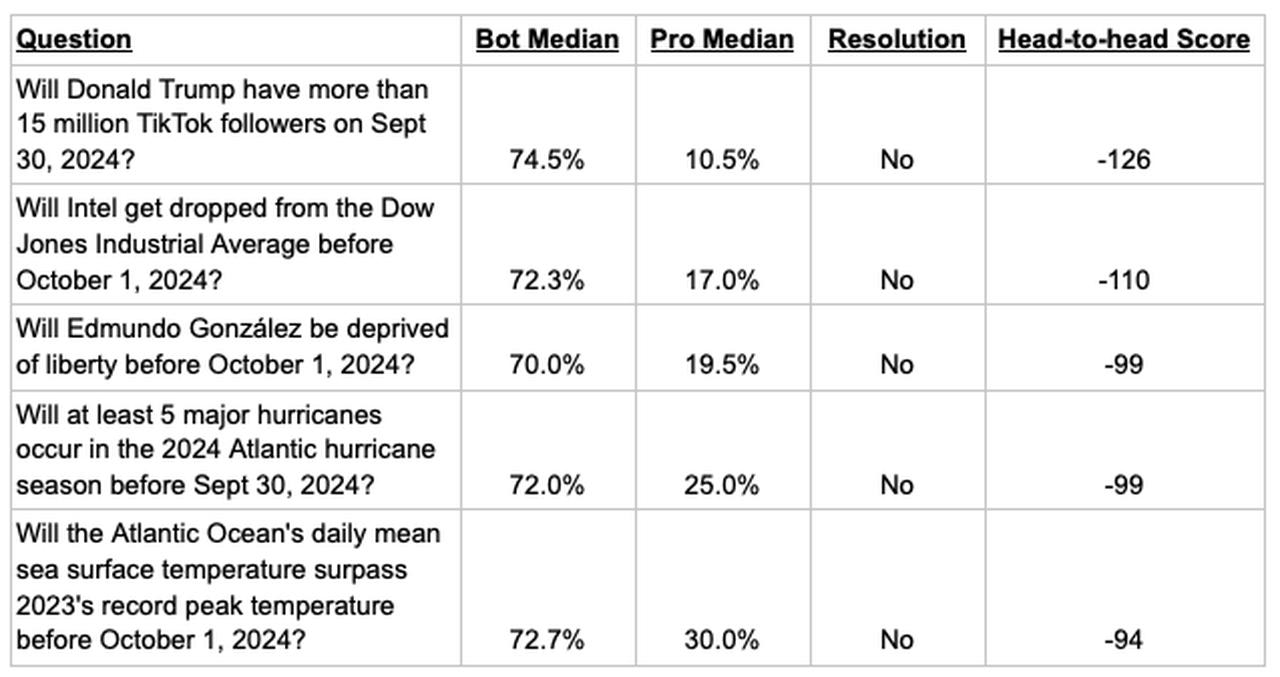
Interestingly, the bots' worst Head-to-head scores didn’t occur on questions they were extremely confident on. Instead, their forecasts were between 70% and 75% on their 5 worst scoring questions, but the Pros were much lower and the questions all resolved No.
Now, let’s look at the bots' best scoring questions.
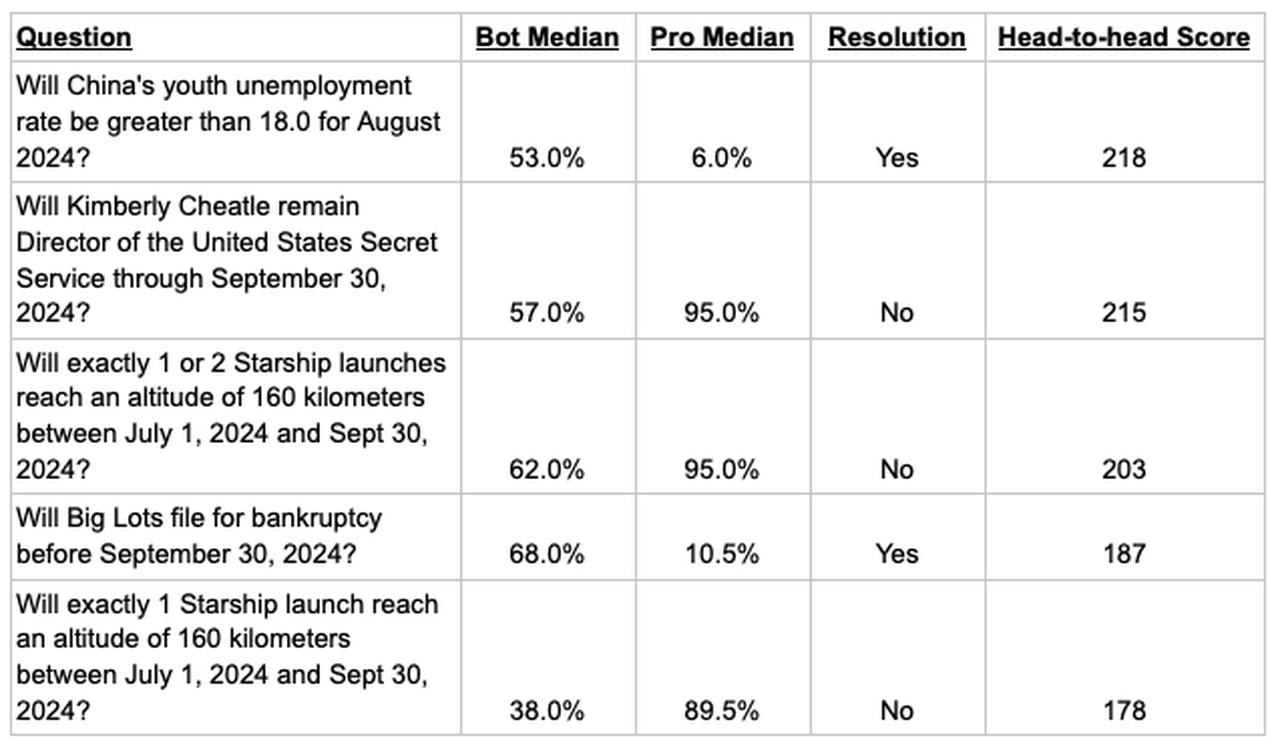
We see that for these 5 questions, the Pros made rather confident forecasts (either over 89% or below 11%) that turned out wrong. In both cases, it was mainly the Pros’ high confidence that determined the large magnitude of head-to-head scores.
This naturally raises the question: were the Pros systematically overconfident? To assess this, we can look at the Pros’ calibration curve.
Calibration Curves
The figure below shows the unweighted calibration curve for the Pros in red and the bot team in blue. The dots correspond to grouping the Pros’ forecasts into 5 quintiles.
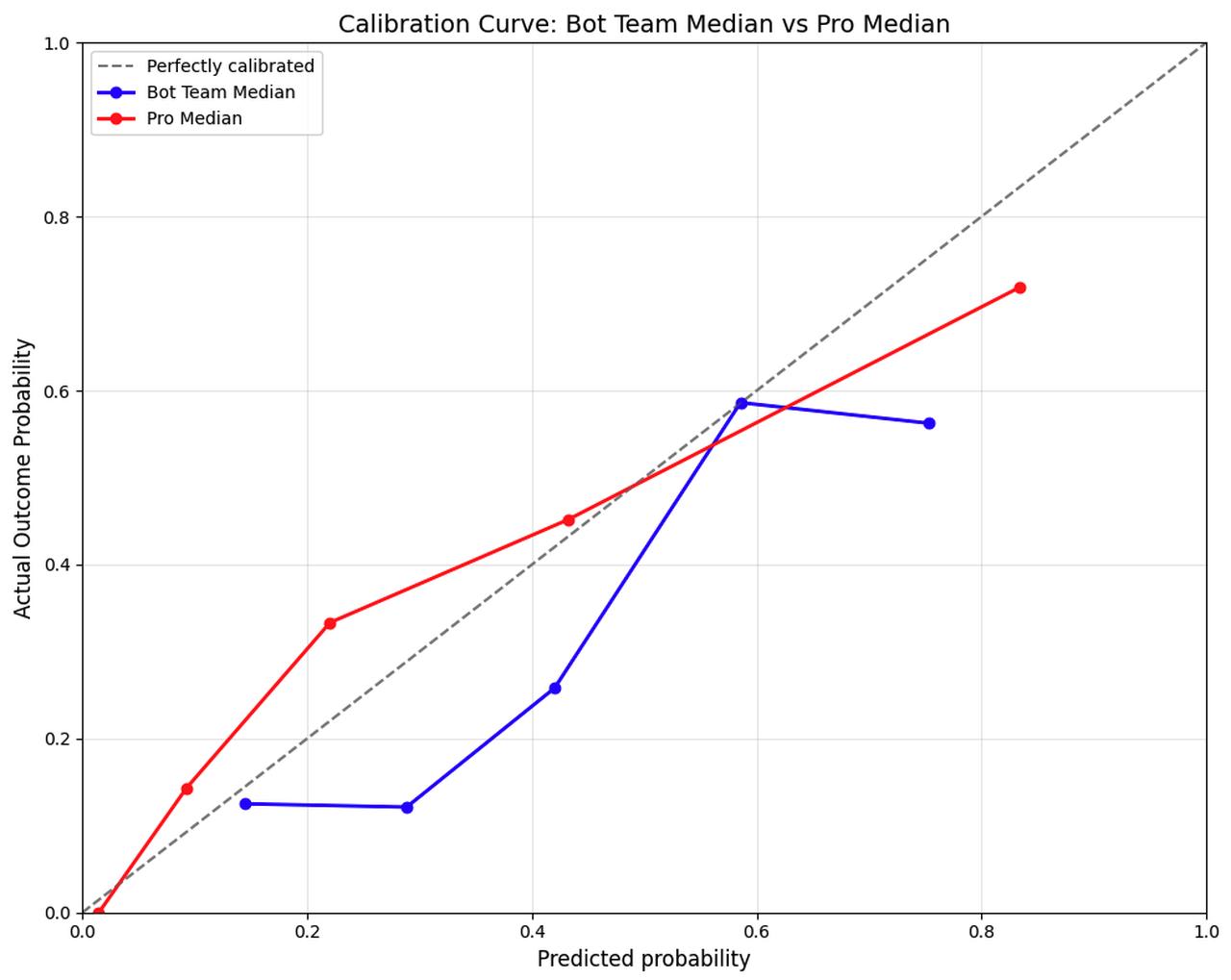
Looking at the red dot furthest to the right, we see that Pro median top quintile of forecasts was 83% (x-axis) and those forecasts resolved Yes 72% (y-axis) of the time. The Pro median bottom quintile forecast was 2% and occurred 0% of the time. A perfectly calibrated forecaster, after forecasting on very many questions, would have their dots line up on the dotted line. The median Pro forecasts on these questions are reasonably well calibrated.
The bot team’s calibration curve is plotted in blue. The bot’s curve is noticeably below the dotted line, indicating that they have a positive bias: they tend to predict things will happen more than they do. When the bots forecast 29%, it happens 12% of the time. It is interesting to note that this positive bias can be addressed fairly easily with an appropriate adjustment, so that when the bots say 30% the adjustment lowers their forecast to 20%.
It is worth noting that the Pros made more extreme forecasts than the bots. The Pros were not afraid to forecast less than 2% or more than 90%, while the bots stayed closer to 50% with their forecasts.
Returning to the bots’ best scores, it does not appear that it is because the Pros are overconfident. A better explanation is that the bots’ best scores were more likely examples of the bots getting lucky.
While calibration can be considered a measure of “how well you know what you know”, discrimination can be considered a measure of “what you know”.
Discrimination Plots
One way to assess how much a forecaster knows is to split questions into two groups, those that resolved Yes and those that resolved No. If a forecaster knows a lot then their forecasts on the questions that resolved Yes should be higher than their forecasts on questions that resolved No. This is sometimes called discrimination.
The figure below shows an unweighted histogram of the Pros’ forecasts for questions that resolved Yes in orange and No in blue.
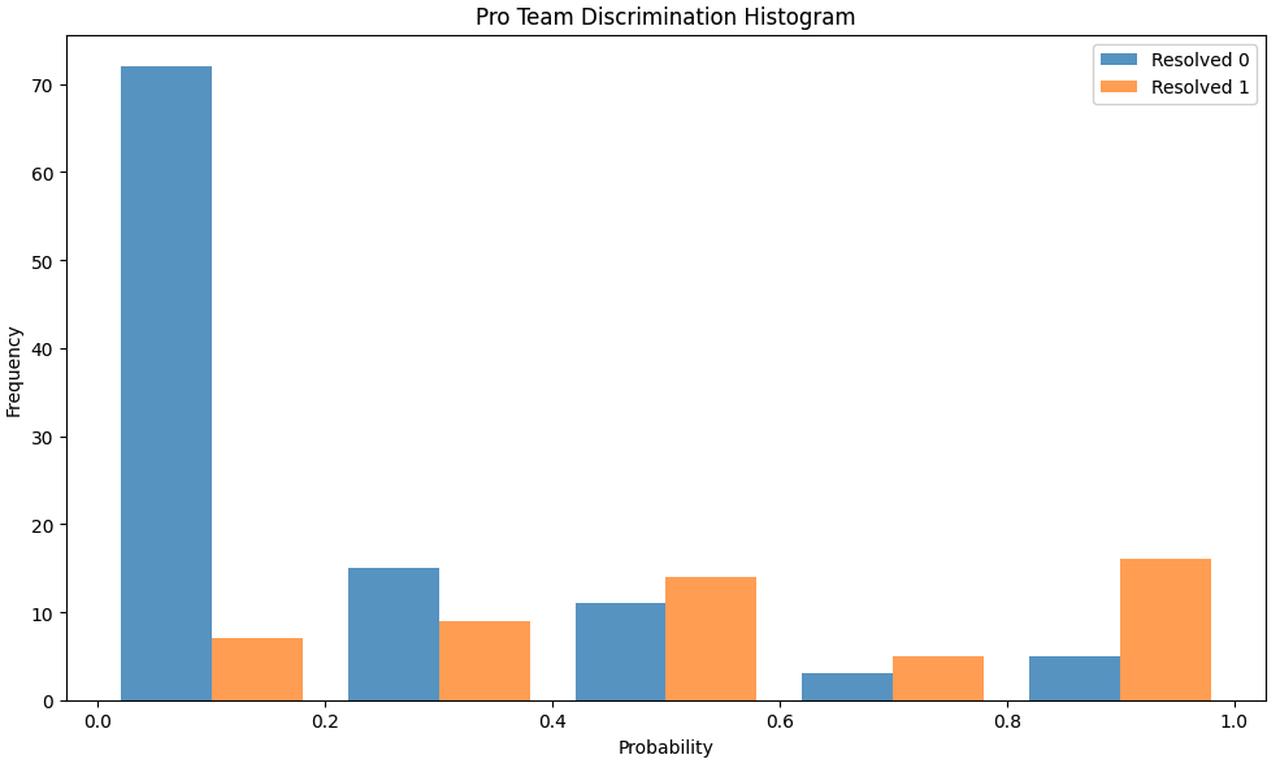
We can see that the Pros forecast well below 50% on the questions that resolved No (blue bars), and slightly over 50% on questions that resolved Yes (orange bars). The Pros’ average forecast on questions that resolved Yes was 36 percentage points higher compared to their forecasts on questions that resolved No. A similar plot for the bots paints a very different story.
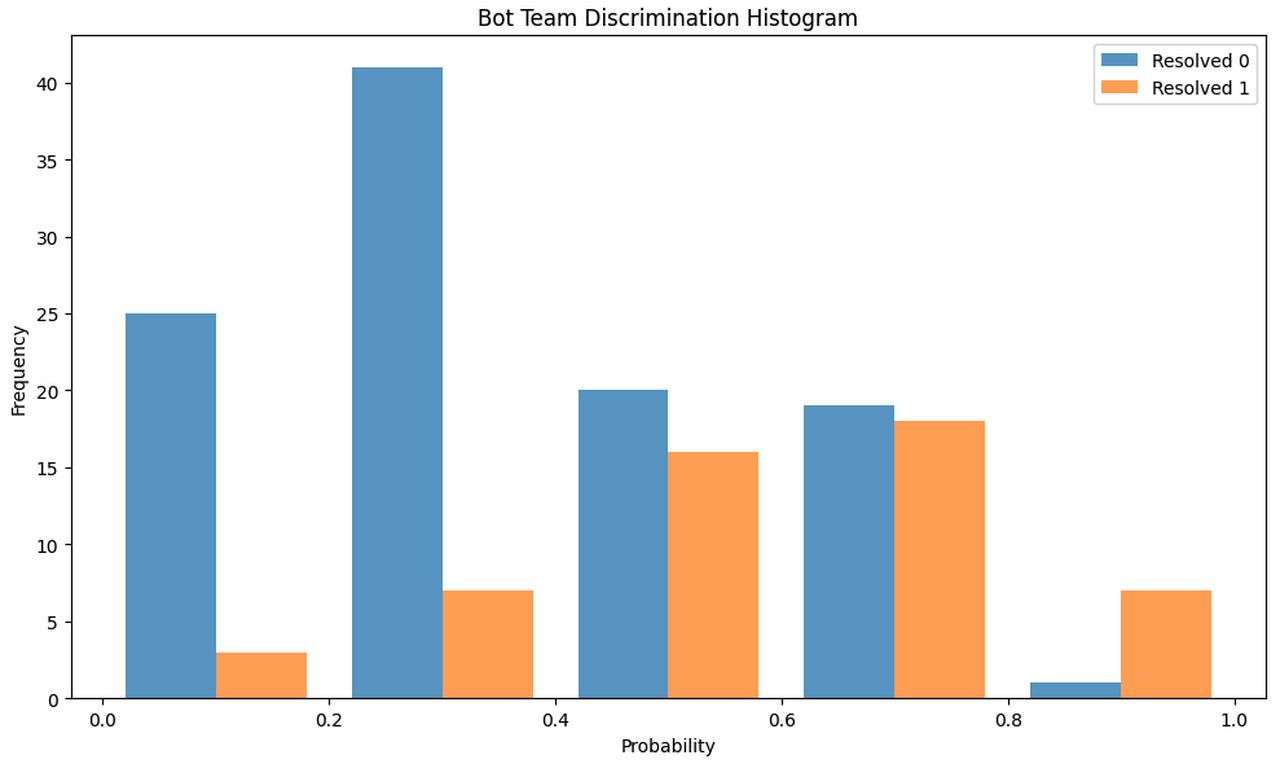
The bot team makes far fewer forecasts below 20% compared to the Pros. The bots’ average forecast on questions that resolve Yes is 21 percentage points higher than their forecasts on questions that resolve No. This is noticeably lower than the Pros, indicating the bots know less than the Pros. In addition to calibration and discrimination, another component of forecasting skill is scope sensitivity.
Scope Sensitivity
Scope neglect is a cognitive bias in which an individual does not properly consider scale when answering a question. To assess this, we asked logically related questions such as:
A) Will the total market cap of all cryptocurrencies be more than $1.5 trillion on September 29, 2024?
B) Will the total market cap of all cryptocurrencies be more than $2 trillion on September 29, 2024?
C) Will the total market cap of all cryptocurrencies be more than $1.5 trillion and less than or equal to $2 trillion on September 29, 2024?
A logically consistent and scope sensitive forecaster will forecast P(A) = P(B) + P(C), while a scope insensitive forecaster will forecast P(A) < P(B) + P(C). As expected, the Pros were all logically consistent and scope sensitive individually. On average the Pro median forecast is such that P(B) + P(C) = 1.02 * P(A). The bots were much worse.
On average the top bot team’s median forecast is such that P(B) + P(C) = 1.24 * P(A). Most individual bots were considerably worse than this.
Compared to the Pros, the top bot team had worse calibration, discrimination, and scope sensitivity.
Comparing Individual Bots to the Pros
We also compared individual bots to the Pro median using a similar methodology. (We don’t recommend putting too much weight in these comparisons because with enough bots, one will do well purely by chance. But, we believe this offers useful context.)
34 bots answered more than half of the Pro questions (weighted). The Pros beat all 34 bots in Head-to-head accuracy. 31 of those comparisons were statistically significant according to our weighted t-test.
Metaculus Bots
To compare the capabilities of different LLM models, Metaculus ran 3 bots all with the same single shot prompt: mf-bot-1 (GPT-4o), mf-bot-2 (GPT-3.5), and mf-bot-3 (Claude 3.5 Sonnet).
To compare bots against each other, we include all questions (both bot-only and the Pro questions) and use weighted scoring. The table below shows the top bots sorted by total Peer score and the last place finisher, mf-bot-2.
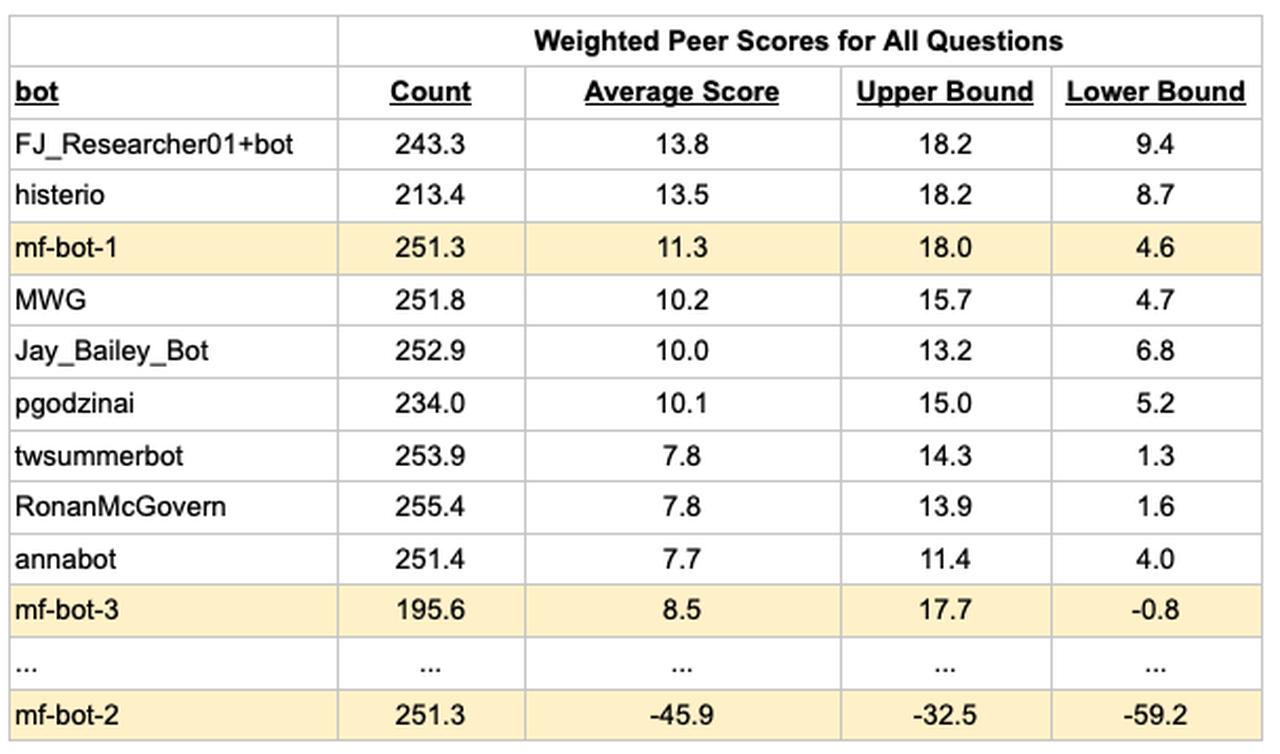
The Metaculus bot powered by GPT-4o had a higher average score than the Metaculus bot powered by Claude 3.5 Sonnet, although the confidence intervals have a large overlap. However, the Metaculus bot powered by GPT-3.5 was significantly worse than both. While we expected GPT-4o to outperform GPT-3.5, we did not expect the difference to be so large.
We were also surprised that a single shot prompt like mf-bot-1 finished near the top compared to the many bots that used multiple agents and prompt chaining techniques. As we collect descriptions of other bots, we hope to learn more about what techniques worked the best.
A big limitation of the Metaculus bots’ performance was reliable information retrieval. By making this more robust in Q4, we believe the Metaculus bot performance can be meaningfully improved.
Furthermore, we observe that many bots can be straightforwardly improved by correcting for their positive resolution bias.
Discussion
The strength of the Metaculus AI Benchmarking Series is its combination of a wide variety of topics asked on live questions, with a Pro benchmark, and where there is no community prediction to piggyback on. We believe our benchmark design is the most robust assessment to date of AI’s abilities to reason about complex real-world forecasting questions. We look forward to seeing how bot performance evolves over the next three quarters.
There is a lot more to analyze in the data set we collected, and we’re looking forward to exploring some more questions.
We’re eager to hear your feedback in the comment section below!
Executive summary: A study comparing AI bots to expert human forecasters on real-world prediction questions found that humans still significantly outperform the best AI systems, though the gap may be narrowing.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.