Thank you to everyone who helped with the technical and logistical ideas that are coming together here! In particular, thank you to the many people who contributed to the semi-concrete project ideas listed in this post.
The basic idea
Aether will be a small group of talented early-career AI safety researchers with a shared research vision who work full-time with mentorship on their best effort at making AI go well. That research vision will broadly revolve around the alignment, control, and evaluation of LLM agents. There is a lot of latent talent in the AI safety space, and this group will hopefully serve as a way to convert some of that talent into directly impactful work and great career capital.
Get involved!
- Submit a short expression of interest here by Fri, Aug 23rd at 11:59pm PT if you would like to contribute to the group as a full-time in-person researcher, part-time / remote collaborator, or advisor. (Edit: It was very useful to get many submissions by Aug 23rd, but we are leaving the form open, so feel free to still submit.)
- Apply to join the group here by Sat, Aug 31st at 11:59pm PT.
- Get in touch with Rohan at rs4126@columbia.edu with any questions.
Who are we?
Team members so far
I recently completed my undergrad in CS and Math at Columbia, where I helped run an Effective Altruism group and an AI alignment group. I’m now interning at CHAI. I’ve done several technical AI safety research projects in the past couple years. I’ve worked on comparing the expressivities of objective-specification formalisms in RL (at AI Safety Hub Labs, now called LASR Labs), generalizing causal games to better capture safety-relevant properties of agents (in an independent group), corrigibility in partially observable assistance games (my current project at CHAI), and LLM instruction-following generalization (part of an independent research group). I’ve been thinking about LLM agent safety quite a bit for the past couple of months, and I am now also starting to work on this area as part of my CHAI internship. I think my (moderate) strengths include general intelligence, theoretical research, AI safety takes, and being fairly agentic. A relevant (moderate) weakness of mine is programming. I like indie rock music :).
I hold an undergraduate master’s degree (MPhysPhil) in Physics and Philosophy and a postgraduate master’s degree (BPhil) in Philosophy from Oxford University. I collaborated with Rohan on the ASH Labs project (comparing the expressivities of objective-specification formalisms in RL), and have also worked for a short while at the Center for AI Safety (CAIS) under contract as a ghostwriter for the AI Safety, Ethics, and Society textbook. During my two years on the BPhil, I worked on a number of AI safety-relevant projects with Patrick Butlin from FHI. These were focussed on deep learning interpretability, the measurement of beliefs in LLMs, and the emergence of agency in AI systems. In my thesis, I tried to offer a theory of causation grounded in statistical mechanics, and then applied this theory to vindicate the presuppositions of Judea Pearl-style causal modeling and inference.
Advisors
Erik Jenner and Francis Rhys Ward have said they’re happy to at least occasionally provide feedback for this research group. We will continue working to ensure this group receives regular mentorship from experienced researchers with relevant background. We are highly prioritizing working out of an AI safety office because of the informal mentorship benefits this brings.
Research agenda
We are interested in conducting research on the risks and opportunities for safety posed by LLM agents. LLM agents are goal-directed cognitive architectures powered by one or more large language models (LLMs). The following diagram (taken from On AutoGPT) depicts many of the basic components of LLM agents, such as task decomposition and memory.
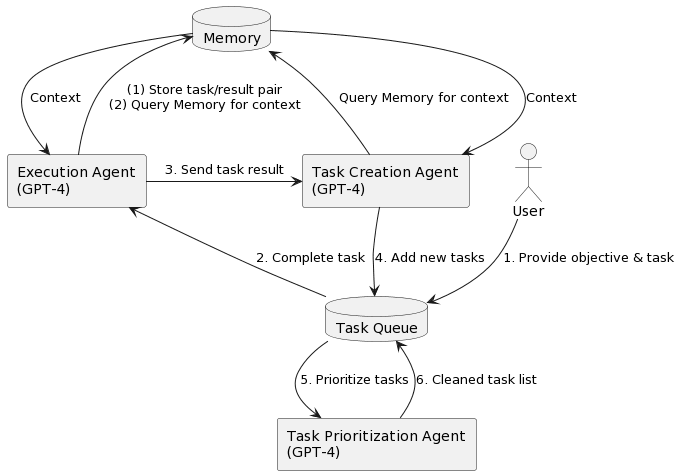
We think future generations of LLM agents might significantly alter the safety landscape, for two reasons. First, LLM agents seem poised to rapidly enhance the capabilities of frontier AI systems (perhaps even if we set aside the possibility of further scaling or design improvements to the underlying LLMs). At the same time, LLM agents open the door for a "natural language alignment" paradigm that possesses potential safety advantages and presents us with a promising set of opportunities for the alignment and control of AI systems.
We are interested in the following research directions, among others:
- Theoretical and empirical work towards understanding the current and (near-)future capabilities of LLM agents
- Investigating the contribution of explicit chain-of-thought reasoning to problem-solving capability in current LLMs
- Chain-of-thought faithfulness and steganography in current LLM agents
- Model organisms of misalignment for LLM agents (e.g., misaligned agents built atop aligned LLMs; aligned agents built atop misaligned LLMs)
- Safety and capabilities evaluations for LLM agents, including long-horizon deception
- Oversight of highly complicated or impractically long chains of reasoning
We have a number of semi-concrete project ideas in the above areas (see below). We omit discussion of related work here.
Logistics
We are seeking funding to trial this group for an initial period of seven months, from mid-October 2024 to mid-May 2025. We will apply for a range of funding levels, but as a first approximation we may aim for about $25,000 per person for the 7 month period. (Edit: We may be able to get more funding, so please don’t let that stop you from applying.) We would like to form a core team of 4-6 full-time researchers working together in-person at an AI safety office, most likely in Berkeley, California or London, UK. (Please indicate your willingness to relocate to either of those places for seven months in the application form.) After this, we would consider applying for a second round of funding if things are going well.
In addition to the core team, we are also open to collaborators who may prefer to work with us part-time and/or remotely. Please let us know via the expression of interest form if you fall in this category.
There are many other logistical factors that we will sort out as quickly as possible. Feel free to reach out to Rohan at rs4126@columbia.edu with any questions.
Considerations
Why you might want to join Aether:
- Direct impact: Our impact could be very counterfactual (this project would not exist by default, and we can pick a project we think is otherwise neglected), and we would be doing what we think is the most impactful AI safety research we can possibly do.
- Career capital: (see here for why we use this breakdown)
- Skills and knowledge: We would engage in reading, writing, coding, thinking, and generating outputs, all in the specific domain(s) we think are most important. We would spend lots of time interacting with each other and other AI safety researchers, which is great for learning. Members of the group will be given quite a bit of freedom to contribute to the high-level research direction, explore rabbit holes, do what they think is most important, and work on side-projects, all of which can accelerate learning.
- Connections: Ideally, we would spend quite a lot of time working from AIS offices (such as the LISA office in London), which is a fantastic way to make connections. In addition, we will likely be able to get high-quality mentorship from multiple experienced researchers (see About Us section).
- Credentials: As an independent research group, we will be unaffiliated with any institution. This is a bit risky and has some downsides. On the other hand, doing this well would be more impressive than the usual, institutionally regimented routes into research. We also think the probability that this goes visibly well is quite high. We should aim to create great outputs (e.g., papers, pre-prints, and blog posts), and we think we can succeed.
- Character: We’ll be a group of thoughtful, kind people interested in improving the world effectively and pushing each other to do that well.
- Runway: We will apply for a range of funding levels, but as a first approximation we may aim for about $25,000 per person for the 7 month period. This is probably not the best option for amassing runway, but if early stages go legibly well, we can likely obtain more funding later.
- Reducing uncertainty: …about promising research directions in AI safety, and about our ability to do good independent research, etc.
- This could also be a lot of fun!
Why you might not want to join Aether:
- Logistical obstacles: You might have already made commitments that are incompatible with this. We are open to having a few part-time collaborators in addition to a core team of full-time researchers—if you would be interested in working with us only part-time and/or remotely, please let us know.
- Incompatible research interests: You may disagree with us that LLM agents are a plausible route to transformative AI, or that the natural language alignment paradigm is a promising approach to the alignment, control, and evaluation of AI systems.
- High risk, high reward option: While the upsides of this going well are significant, there is also a non-trivial risk that this doesn’t work out (e.g., if we are unable to obtain funding, or if after seven months we haven’t made meaningful progress).
Sample of semi-concrete project ideas
- Importance of chain-of-thought. Empirically characterize the decomposition of reasoning that happens within each LLM call (using LLM latent representations) vs that is carried out by the scaffold across multiple LLM calls (using natural language)
- Similar: Develop a way to tell when models gain the ability to do new levels of dangerous black-box reasoning
- Similar: Characterize what sorts of reasoning problems current LLMs are able to perform within a single forward pass and what problems they need CoT for
- Create an environment for executing, evaluating, and iterating on “throw the kitchen sink” alignment strategies.
- Currently, alignment techniques (such as scalable oversight, interpretability, adversarial robustness, etc.) are often studied and applied separately. Can they be applied simultaneously to make safer and more useful systems?
- We could explore this in a contained artificial environment, such as a video game setup with safety-relevant analogies to the real world.These analogies might include: (i) the possibility for the AI to achieve good outcomes that a human can’t achieve alone, and (ii) the availability of catastrophic actions at test-time. The idea would be to construct a toy setup that has many of the challenges of real-world superalignment that are missing from most (all?) empirical work to date.
- Measuring long-horizon deception. Suite of evals: Agent has to do X while also secretly doing Y, how good is it at that?
- The difficulty of this depends on the safety techniques being used
- Can compare control techniques and improve them by iterating on this
- Model organisms of misaligned LLM agents. Develop a model organism of a misaligned agent built upon an aligned LLM, or give empirical evidence that this is unlikely
- Steganography / Chain-of-thought faithfulness. Develop a model organism of natural-language steganography that transmits hidden information from previous LLM calls to later ones (using memories, contexts, etc.) without being detected, or give empirical evidence that this is unlikely.
- Quantitative survey of current (and anticipated) agent applications: How sophisticated are the scaffolding architectures currently used? How goal-directed do these scaffolds make agents? Can we quantify these things?
- General oversight of LLM agents. Assess reliability of LLM judges that grade the safety of agent logs / proposed actions
- E.g., could have the supervisor summarize / paraphrase the action and see if that results in the same consequences
- Oversight of impractically long chains of reasoning.
- Construct a misaligned, interpretable, but impractically long reasoning chain.
- Construct overseers with various capabilities.
- Measure overseer performance.
- Repeat steps 1 - 3 with diverse chains.
- Aim to predict the tradeoff between capability and effective oversight.
- Study the value of train and test-time compute for generic LLM tasks, see e.g. approaches trying to apply Monte-Carlo tree search and related ideas on LLMs.
- Will there be inference time compute scaling laws comparable to training compute ones? Can clever inference time algorithms for GPT-4 unlock capabilities similar to GPT-6+? Capabilities even beyond that?
- Exploring foundation model agent capabilities: The following are interesting questions that can inform safety, but are more clearly relevant to capabilities. Increasing safety and advancing capabilities are not always at odds; we are still figuring out how to act given these concerns.
- Designing an LLM agent that does better on the Abstraction and Reasoning Corpus (ARC) as proof of principle for efficacy of LLM-based cognitive architectures.
- Do LLM agents perform any better than simple LLM calls on ARC?
- Does adding analogs of (e.g.,) executive function make the difference between a mere “program interpolator” and a true program synthesizer?
- Constructing more sophisticated scaffolding. LLM agents thus far (e.g., AutoGPT) have operated on fairly basic principles (e.g., naive self-prompting) without much explicit attention to what is known about the human cognitive architecture. What might a more cognitively anthropomorphic LLM agent look like?
- Step 1: Map out high-level elements of the human cognitive architecture and their relationships. Form a heuristic model of how these elements give rise to human intelligence, creativity, and reasoning ability. Then review the details of how the individual mechanisms work in the human case.
- Step 2: Does the gap between existing LLM agents (e.g., AutoGPT, Baby AGI) and the more cognitively anthropomorphic ones we have in mind seem theoretically substantial? Will closing this gap make a relevant difference?
- Step 3: Can we design and then actually build an LLM agent modeled more closely on the human cognitive architecture? Does it show promise?
- Designing an LLM agent that does better on the Abstraction and Reasoning Corpus (ARC) as proof of principle for efficacy of LLM-based cognitive architectures.
Hot-take: 10b) seems pretty risky. I wouldn't recommend pursuing it unless either i) you're really good at keeping secrets ii) you have a specific reason to believe these architectures will be safer, not just trying to measure potential capabilities improvements.
I would suggest that there are other projects that have a much better risk-reward ratio, even within evals, or even within agentic evals.
Not saying that I think 10b is the best project, but I think that improving capabilities via scaffolding (and generally improving our understanding of scaffolding) looks generically good.
This is because:
That said, I think some scaffolded architectures may be significantly safer than others, so I'm not equally-positive about exploring all directions for scaffolded agents.
It's not clear that scaffolding is a one-time boost vs. a whole series of boosts, so I guess I feel that the idea of "burning up" the overhang is naive.
BTW, it's possible I'm not appreciating the strongest forms of the arguments against advancing scaffolding being good. From my perspective, if I think of it purely as "software capabilities" then there's a generic argument against improving capabilities, which I don't totally buy but definitely gets some weight. But when you zoom in to thinking about different types of capabilities I end up thinking scaffolding is quite robustly good. I'd be interested if you know of a zoomed-in case against scaffolding.
I don't have a "zoomed-in case", but if I did, I think it would be unwise to share it publicly.
That's very surprising to me. Can you explain why publicly?
Surely to be convincing, I'd have to go into detail about the best ways to scaffold such systems. And even though my knowledge is likely not at the level where this would likely have any impact, it still seems bad in principle to do things that would be bad if they were done by someone with a higher level of knowledge and competence.
Oh I see. I definitely wasn't expecting anything that zoomed in. Rather, I was thinking maybe you had some abstract model which separated out capabilities-from-base-model from capabilities-from-scaffolding, and could explain something about the counterfactual of advancing the latter, and how it all interacted with safety.
Sticking to generalities, there are many ways of scaffolding models and many of them can combine and many kinds of scaffolding that don’t work at lower base model levels will work at higher base model levels. You can basically just throw anything at humans and we’ll figure out how to make it work.
I agree with this. (While noting that some forms of scaffolding will work noticeably better with humans than others will, so there are still capabilities boosts to be had for organizations of humans from e.g. procedures and best practices.)
But if our plan was to align organizations of some human-like entities that we were gradually training to be smarter, I'd be very into working out how to get value out of them by putting them into organizations during the training process, as I expect we'd learn important things about organizational design in the process (and this would better position us to ensure that the eventual organizations were pretty safe).
Sure, I totally expect it to be a series of boosts, but like most domains I expect you get diminishing returns to research effort put in. So there's a question of at-the-margin, how much of a boost-from-the-low-hanging-fruit-of-scaffolding are you leaving?
Companies are investing hundreds of millions into agent research. It seems quite unlikely that this lab will discover something dangerous that others won't. The bottleneck is the intelligence in the foundation models and amount of inference compute to produce outputs you can search over. Different scaffolding is very unlikely to take it all the way.
Executive summary: Aether is seeking talented early-career researchers to join a new independent research group focused on LLM agent safety, with applications open for full-time, part-time, and advisory roles.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.