
Angelina Li
Bio
Hiya! I work on data stuff at CEA. I used to be the content lead on the EA Global team at CEA, and before that I did economic consulting. Here's an old website I might update at some point.
Think I'm making a mistake? Want to give me feedback? Here's my admonymous.
Posts 6
Comments54
By the way, very tiny bug report: The datestamps are rendering a bit weird? I see the correct date stamp for today under the date select, but the description text in italics is rendering as 'Yesterday', and the 'data-tip' value in the HTML is wrong.
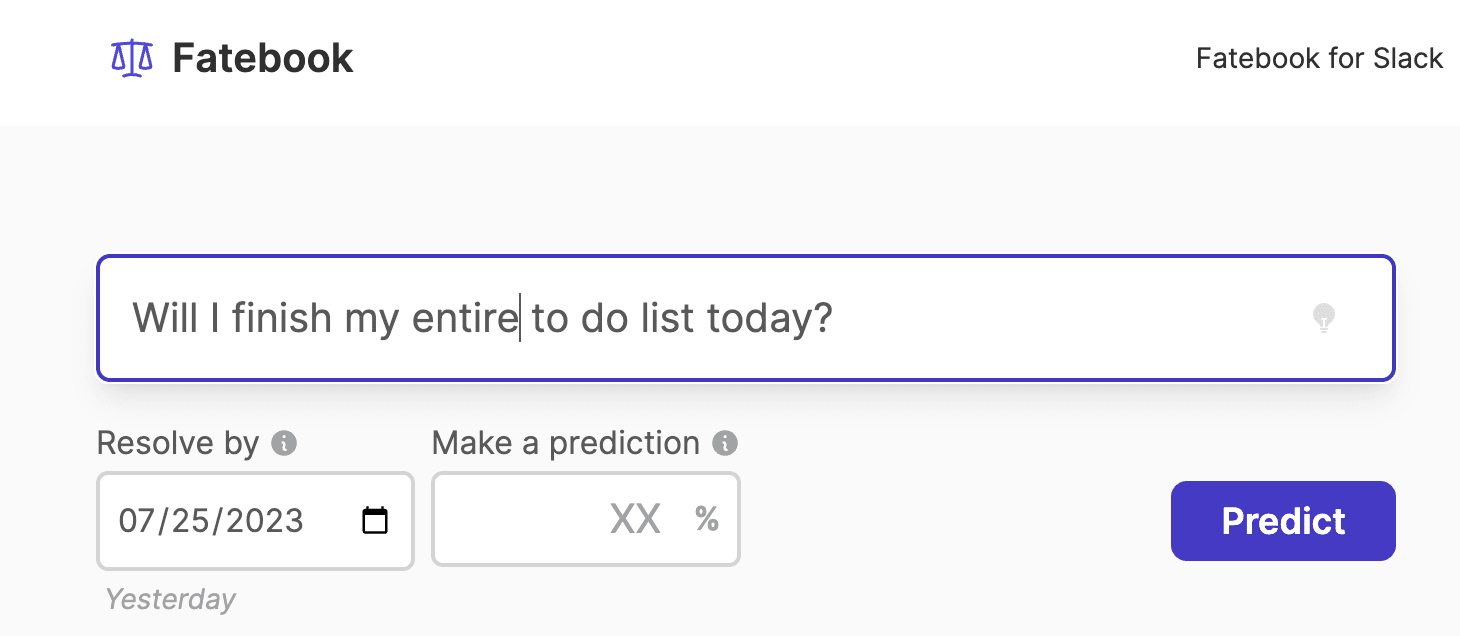

Obviously not a big deal, just passing it on :) I'm currently in PST time, where it is 9:39am on 2023.07.25, if it matters. (Let me know if you'd prefer to receive bug reports somewhere else?)
I really love this <3
Compared to more public prediction platforms (e.g. Manifold), I think the biggest value adds for me are: (a) being ridiculously easy to set up + use, and (b) being able to make private predictions.
On (b), I saw the privacy policy is currently a canned template. I'm curious if you could say more on:
- How and when you access user data
- e.g. Do you look at non-anonymized user data in your analytics and tracking?
- Who specifically gets access to user submitted predictions (can't quite tell how large your team is, for instance)
:) I'm a really big fan of Sage's work, thank you so much!
Thanks, I’m glad you like the dashboard and are finding it a productive way to engage with our work! That's great feedback for us :) As a quick aside, we actually launched this in late December during our end of year updates, this version just includes some fresh data + a few new metrics.
I’m not sure if all our program owners will have the capacity to address all of your program-specific thoughts, but I wanted to provide some high level context on the metrics we included for now.
When selecting metrics to present, we had to make trade offs in terms of:
- How decision guiding a particular metric is internally
- How much signal we think a metric is tracking on our goals for a particular project
- How legible this is to an external audience
- How useful is this as an additional community-known data point to further outside research
- E.g. Metrics like “number of EAG attendees” and “number of monthly active Forum users” seem potentially valuable as a benchmark for the size of various EA-oriented products, but aren’t necessarily the core KPIs we are trying to improve for a given project or time period – for one thing, the number of monthly active Forum users only tracks logged in users!
- The quality of the underlying data
- E.g. We’ve tried to include as much historical data as we could to make it easier to understand how CEA has changed over time, but our program data from many years ago is harder for current staff to verify and I expect is generally less reliable.
- Whether something is tracking confidential information
- Time constraints
- Updating this dashboard was meant as a ~2 week sprint for me, and imposes a bunch of coordination costs on program owners to align on the data + presentation details.
So as a general note, while we generally try to present metrics that meet many of the above criteria, not all of these are numbers we are trying to blindly make go up over time. My colleague Ollie’s comment gives an example of how the metrics presented here (e.g. # total connections, LTR) are contextualized and supplemented with other evidence when we evaluate how our programs are performing.
Also thanks for your feature requests / really detailed feedback. This is a WIP project not (yet) intended to be comprehensive, so we’ll keep a note of these suggestions for if and when we make the next round of updates!
Thanks for engaging with this!
To chime in with a quick data note: "hours of engagement on the Forum" also includes time spent not viewing posts (e.g. time spent viewing events, local groups, and other non-post content on the Forum), so comparing those two numbers will give you a slightly misleading picture of the Community v. non-Community engagement breakdown.
The Forum saw a total of 39,965 hours of engagement with Community posts up until the end of Q2 in 2023, so the actual ratio between Community:non-Community post engagement is more like 2:3. I'll edit the top level post to make this clear (thanks for the nudge).
I can only imagine how bad this ratio was before the redesign if it's still worse than 1:1
FYI, the dashboard we published has this metric broken out over time, so you don't have to imagine this! :) (I don't work on the Online team, but I built this dashboard.)
Yeah, fair! It's frustratingly hard to get comprehensive lists of EA orgs (it's hard to be in the business of gatekeeping what 'EA-affiliated' is). I did a 5 min search for the best publicly available list and then gave up; sometimes I use the list of organizations with representatives at the last EAG for this use case.
Maybe within AI specifically, someone could repeat this exercise with something like this list. If someone knows of a better public list of EA orgs, I'd love to know about it :)
Here is my babble from the above exercise:
- Should there be more of a central infrastructure org within the effective animal advocacy space? If this existed, it could be a sensible place to house existing projects like Animal Advocacy Careers (feels analogous to EA Virtual Programs being housed within CEA), Animal Ask, and maybe even infrastructural research orgs like Faunalytics, Sentience Institute, etc.
- Has this sort of thing been tried before?
- Creating an org with this sort of remit seems like a very tricky thing to get right. I expect the fact that this doesn't exist yet to be somewhat good evidence that no one has the collective trust / remit to just go and do this, since the EAA space has existed for a while and I don't recall a strong push for this happening.
- Possibly you could create a central infrastructural org ("Ops for EAA") that doesn't try to do any stewardship over the EAA space, but just offers infrastructural services fairly liberally to EAA orgs. Not sure!
- Similar to the above, should more effective giving groups consider consolidating under a larger org in the back end, and retain their existing websites as 'brands'? e.g. the regional EG groups naively seem like a good candidate for this (Ayuda Efectiva, Effektiv-Spenden.org, GiEffektivt).
- If the regional EG model seems promising in general, one benefit of consolidating under a broader project might be that you could then go try and seed new regional EG groups where you think they are most needed, as opposed to solely where there is enough organiser momentum in a particular region to make this happen.
- Maybe seeding efforts are already underway and I just don't know about them!
- But perhaps for EG the trustworthiness of your brand is the most important thing, and maybe the most important this is not to be associated with some vague international super-structure to gain legitimacy within your region / avoid accusations of undue foreign influence (I can think of regions where this would be a super bad idea).
- If the regional EG model seems promising in general, one benefit of consolidating under a broader project might be that you could then go try and seed new regional EG groups where you think they are most needed, as opposed to solely where there is enough organiser momentum in a particular region to make this happen.
A reminder that I spent only 10 minutes on this, I have no special inside knowledge / am not affiliated with any of these orgs, and my main goal was to check if there is any low hanging fruit for consolidation! I'm not sure how good either of the above ideas are.
.
Some observations:
- I found it harder than expected to think of any reasonable consolidations of existing orgs
- I think the following are quite compelling reasons for orgs to remain small:
- If you are doing regional outreach / direct work: It seems plausible that regional advocacy orgs might have strong reasons to not want to be associated with some big super-structure.
- If you are doing policy or political advocacy work: Same as above, probably there are real benefits to not having lots of policy orgs closely associated with each other.
- If you have quite substantial worldview or opinion disagreements: e.g. some orgs with ostensibly similar mandates seem to exist because they are taking quite different bets (80,000 Hours and Probably Good as one example).
- I'm skeptical that merging these sorts of orgs will lead to more productive results, and think competition between orgs with similar mandates is probably more productive than competition within an org (seems kind of awkward if two projects within an org are explicitly competing for the same space!).
- Other thoughts:
- A bunch of the newer 'orgs' seem to be <2 FTE providing some sort of service as a trial, who have given themselves a formal name for legitimacy and branding reasons.
- In these cases, it seems totally right for someone to start a service as a quick trial by themselves, get some seed funding, and then get quick evidence from reality within the first few months.
- You'd probably need to do a lot more negotiation to house yourself as a project within an established org, and I'm generally in favor of people trying things and failing fast (when downside risks are low).
- I feel pretty confused if any consolidations within direct work GH&W orgs make sense. My weak impression is that a lot of more centralized GH&W orgs perform worse than program-specific orgs (scrolling through GiveWell's top charities fund, all of the recent disbursements are to program-specific organizations, e.g. orgs that focus only/primarily on malaria interventions). But maybe an EA motivated org could do better?
- I expect some small orgs exist because a bigger, potential 'parent' org doesn't have enough expertise or time to incubate the smaller project. It would probably incur a bunch of management overhead to move a highly specialized small org into the bigger structure in these cases, which doesn't seem obviously worth it to me.
- A bunch of the newer 'orgs' seem to be <2 FTE providing some sort of service as a trial, who have given themselves a formal name for legitimacy and branding reasons.
Thanks so much! :) FYI that the top level helper text seems fixed:
But the prediction-level helper text is still not locale aware:
(Again, not a big deal at all :) )