Crossposted from the AI Optimists blog.
AI doom scenarios often suppose that future AIs will engage in scheming— planning to escape, gain power, and pursue ulterior motives, while deceiving us into thinking they are aligned with our interests. The worry is that if a schemer escapes, it may seek world domination to ensure humans do not interfere with its plans, whatever they may be.
In this essay, we debunk the counting argument— a central reason to think AIs might become schemers, according to a recent report by AI safety researcher Joe Carlsmith.[1] It’s premised on the idea that schemers can have “a wide variety of goals,” while the motivations of a non-schemer must be benign by definition. Since there are “more” possible schemers than non-schemers, the argument goes, we should expect training to produce schemers most of the time. In Carlsmith’s words:
- The non-schemer model classes, here, require fairly specific goals in order to get high reward.
- By contrast, the schemer model class is compatible with a very wide range of (beyond episode) goals, while still getting high reward…
- In this sense, there are “more” schemers that get high reward than there are non-schemers that do so.
- So, other things equal, we should expect SGD to select a schemer.
— Scheming AIs, page 17
We begin our critique by presenting a structurally identical counting argument for the obviously false conclusion that neural networks should always memorize their training data, while failing to generalize to unseen data. Since the premises of this parody argument are actually stronger than those of the original counting argument, this shows that counting arguments are generally unsound in this domain.
We then diagnose the problem with both counting arguments: they rest on an incorrect application of the principle of indifference, which says that we should assign equal probability to each possible outcome of a random process. The indifference principle is controversial, and is known to yield absurd and paradoxical results in many cases. We argue that the principle is invalid in general, and show that the most plausible way of resolving its paradoxes also rules out its application to an AI’s behaviors and goals.
More generally, we find that almost all arguments for taking scheming seriously depend on unsound indifference reasoning. Once we reject the indifference principle, there is very little reason left to worry that future AIs will become schemers.
The counting argument for overfitting
Counting arguments often yield absurd conclusions. For example:
- Neural networks must implement fairly specific functions in order to generalize beyond their training data.
- By contrast, networks that overfit to the training set are free to do almost anything on unseen data points.
- In this sense, there are “more” models that overfit than models that generalize.
- So, other things equal, we should expect SGD to select a model that overfits.
This isn’t a merely hypothetical argument. Prior to the rise of deep learning, it was commonly assumed that models with more parameters than data points would be doomed to overfit their training data. The popular 2006 textbook Pattern Recognition and Machine Learning uses a simple example from polynomial regression: there are infinitely many polynomials of order equal to or greater than the number of data points which interpolate the training data perfectly, and “almost all” such polynomials are terrible at extrapolating to unseen points.
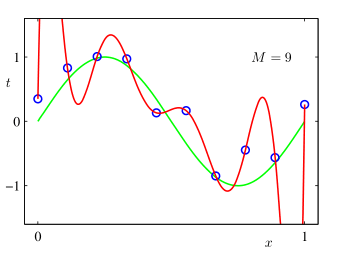
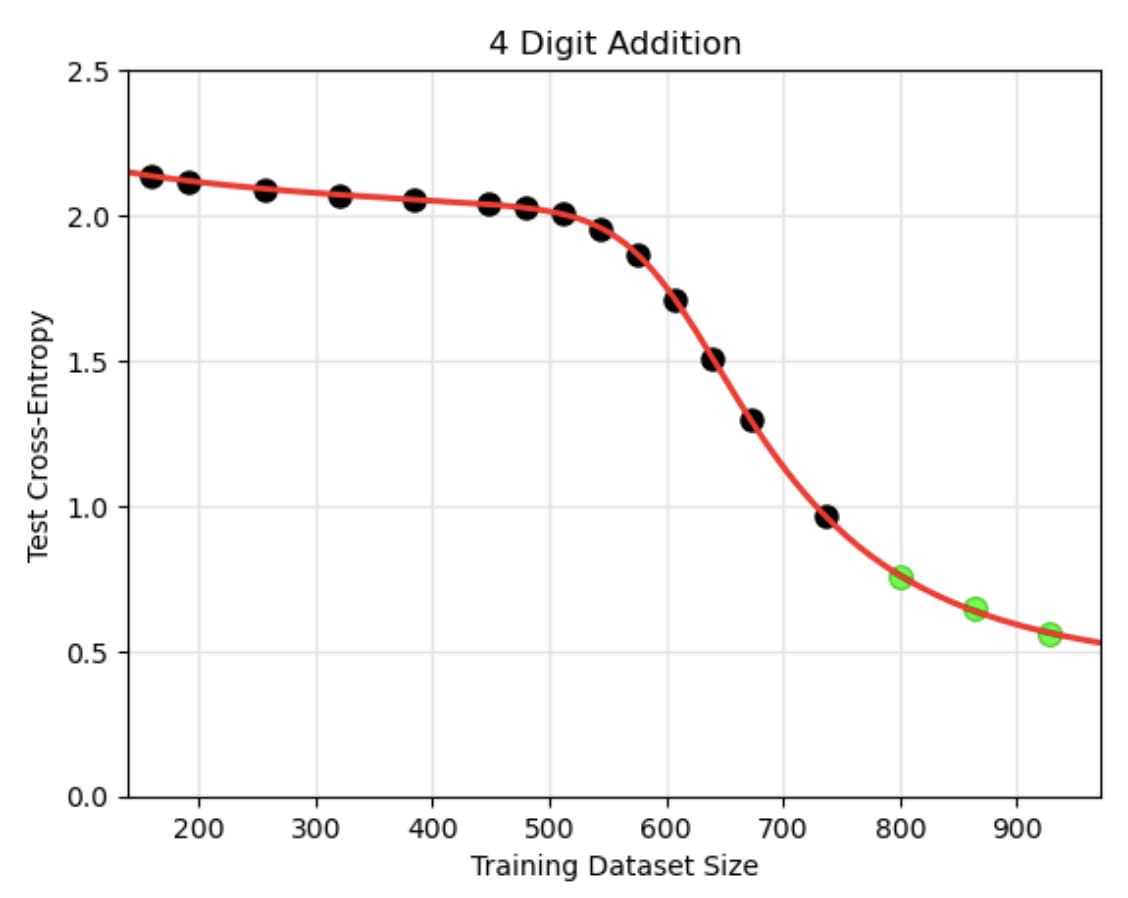
Let’s see what the overfitting argument predicts in a simple real-world example from Caballero et al. (2022), where a neural network is trained to solve 4-digit addition problems. There are 10,0002 = 100,000,000 possible pairs of input numbers, and 19,999 possible sums, for a total of 19,999100,000,000 ≈ 1.10 ⨉ 10430,100,828 possible input-output mappings.[2] They used a training dataset of 992 problems, so there are therefore 19,999100,000,000 – 992 ≈ 2.75 ⨉ 10430,096,561 functions that achieve perfect training accuracy, and the proportion with greater than 50% test accuracy is literally too small to compute using standard high-precision math tools.[3] Hence, this argument predicts virtually all networks trained on this problem should massively overfit— contradicting the empirical result that networks do generalize to the test set.
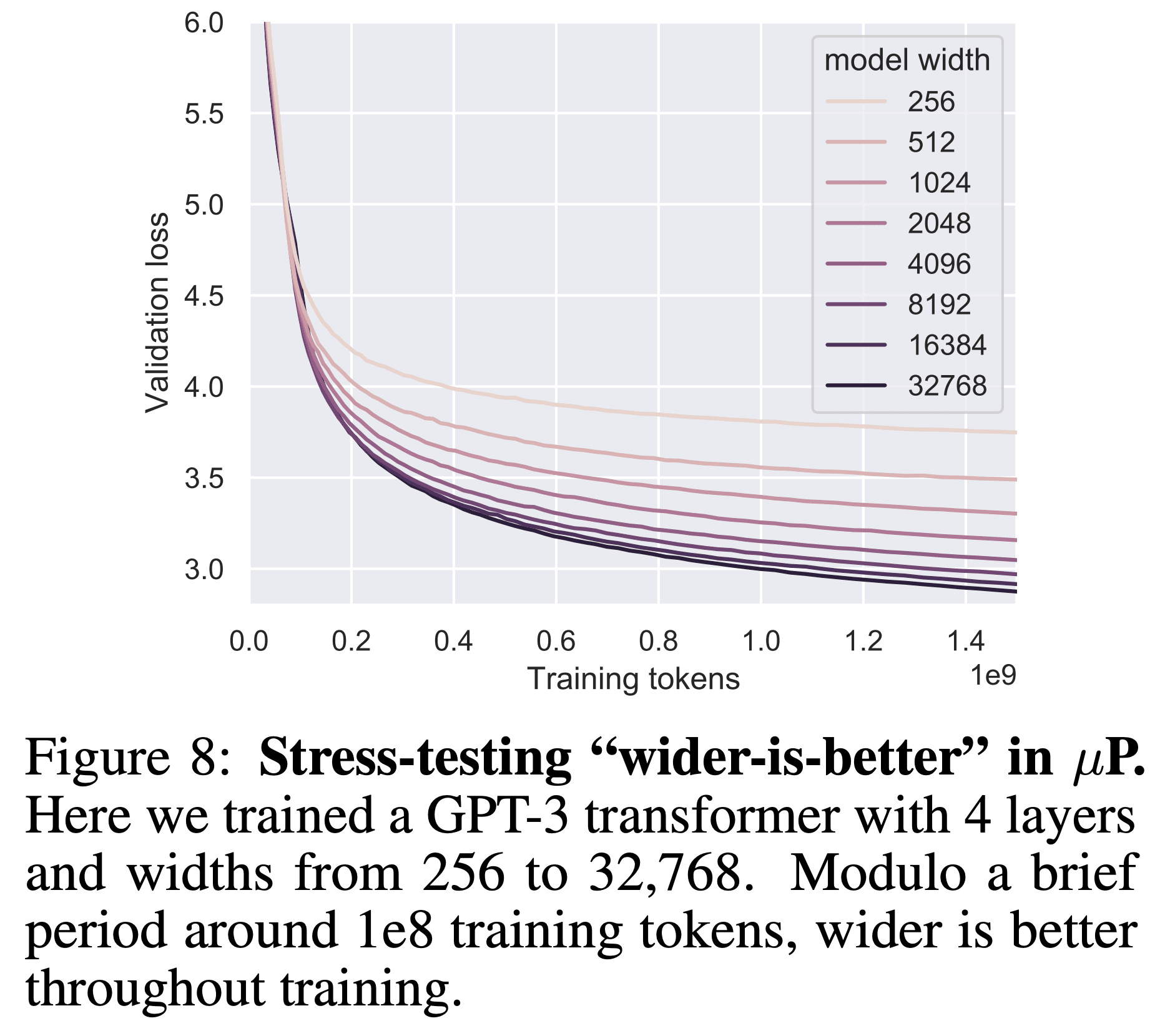
The argument also predicts that larger networks— which can express a wider range of functions, most of which perform poorly on the test set— should generalize worse than smaller networks. But empirically, we find the exact opposite result: wider networks usually generalize better, and never generalize worse, than narrow networks.[4] These results strongly suggest that SGD is not doing anything like sampling uniformly at random from the set of representable functions that do well on the training set.
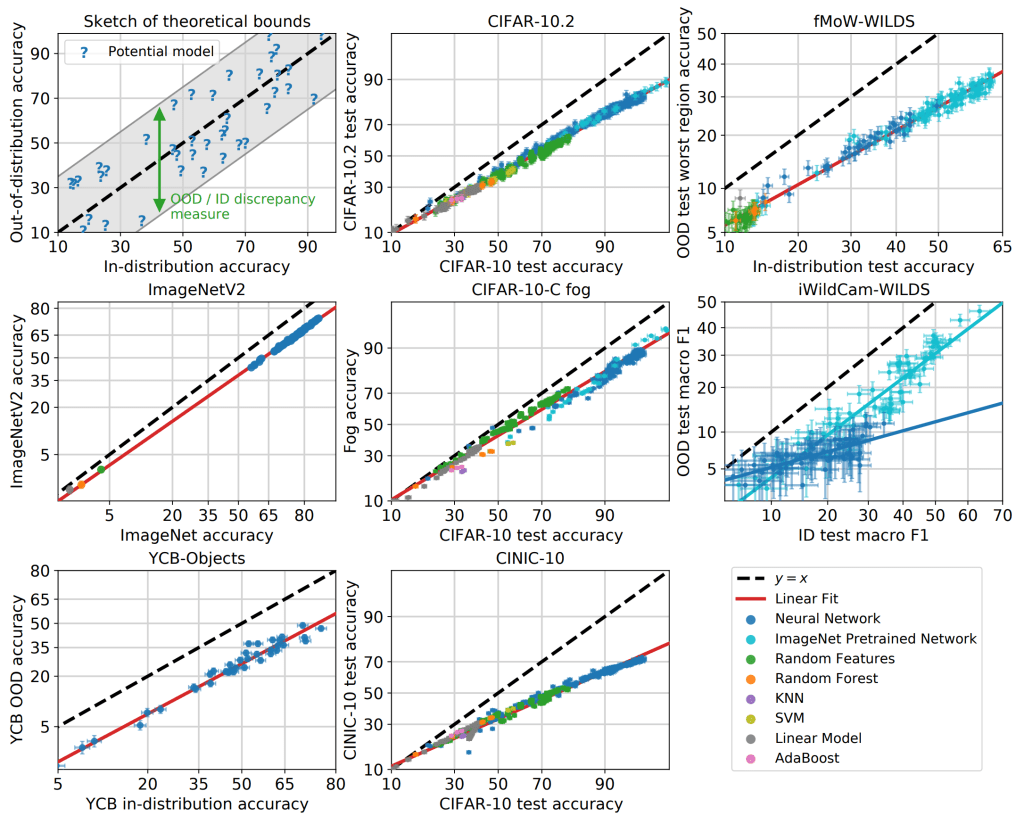
More generally, John Miller and colleagues have found training performance is an excellent predictor of test performance, even when the test set looks fairly different from the training set, across a wide variety of tasks and architectures.
These results clearly show that the conclusion of our parody argument is false. Neural networks almost always learn genuine patterns in the training set which do generalize, albeit imperfectly, to unseen test data.
Dancing through a minefield of bad networks
One possible explanation for these results is that deep networks simply can’t represent functions that fail to generalize, so we shouldn’t include misgeneralizing networks in the space of possible outcomes. But it turns out this hypothesis is empirically false.
Tom Goldstein and colleagues have found it’s possible to find misgeneralizing neural nets by adding a term to the loss function which explicitly rewards the network for doing poorly on a validation set. The resulting “poisoned” models achieve near perfect accuracy on the training set while doing no better than random chance on a held out test set.[5] What’s more, the poisoned nets are usually quite “close” in parameter space to the generalizing networks that SGD actually finds— see the figure below for a visualization.

Dancing through a minefield of bad minima: we train a neural net classifier and plot the iterates of SGD after each tenth epoch (red dots). We also plot locations of nearby “bad” minima with poor generalization (blue dots). We visualize these using t-SNE embedding. All blue dots achieve near perfect train accuracy, but with test accuracy below 53% (random chance is 50%). The final iterate of SGD (yellow star) also achieves perfect train accuracy, but with 98.5% test accuracy. Miraculously, SGD always finds its way through a landscape full of bad minima, and lands at a minimizer with excellent generalization.
Against the indifference principle
What goes wrong in the counting argument for overfitting, then? Recall that both counting arguments involve an inference from “there are ‘more’ networks with property X” to “networks are likely to have property X.” This is an application of the principle of indifference, which says that one should assign equal probability to every possible outcome of a random process, in the absence of a reason to think certain outcomes are favored over others.[6]
The indifference principle gets its intuitive plausibility from simple cases like fair coins and dice, where it seems to give the right answers. But the only reason coin-flipping and die-rolling obey the principle of indifference is that they are designed by humans to behave that way. Dice are specifically built to land on each side ⅙ of the time, and if off-the-shelf coins were unfair, we’d choose some other household object to make random decisions. Coin flips and die rolls, then, can’t be evidence for the validity of the indifference principle as a general rule of probabilistic reasoning.
The principle fails even in these simple cases if we carve up the space of outcomes in a more fine-grained way. As a coin or a die falls through the air, it rotates along all three of its axes, landing in a random 3D orientation. The indifference principle suggests that the resting states of coins and dice should be uniformly distributed between zero and 360 degrees for each of the three axes of rotation. But this prediction is clearly false: dice almost never land standing up on one of their corners, for example.
Even worse, by coarse-graining the possibilities, we can make the indifference principle predict that any event has a 50% chance of occuring (“either it happens or it doesn’t”). In general, indifference reasoning produces wildly contradictory results depending on how we choose to cut up the space of outcomes.[7] This problem is serious enough to convince most philosophers that the principle of indifference is simply false.[8] On this view, neither counting argument can get off the ground, because we cannot infer that SGD is likely to select the kinds of networks that are more numerous.
Against goal realism
Even if you’re inclined to accept some form of indifference principle, it’s clear that its applicability must be restricted in order to avoid paradoxes. For example, philosopher Michael Huemer suggests that indifference reasoning should only be applied to explanatorily fundamental variables. That is, if X is a random variable which causes or “explains” another variable Y, we might be able to apply the indifference principle to X, but we definitely can’t apply it to Y.[9]
While we don’t accept Huemer’s view, it seems like many people worried about scheming do implicitly accept something like it. As Joe Carlsmith explains:
…some analyses of schemers talk as though the model has what we might call a “goal-achieving engine” that is cleanly separable from what we might call its “goal slot,” such that you can modify the contents of the goal slot, and the goal-achieving engine will be immediately and smoothly repurposed in pursuit of the new goal.
— Scheming AIs, page 55
Here, the goal slot is clearly meant to be causally and explanatorily prior to the goal-achieving engine, and hence to the rest of the AI’s behavior. On Huemer’s view, this causal structure would validate the application of indifference reasoning to goals, but not to behaviors, thereby breaking the symmetry between the counting arguments for overfitting and for scheming. We visually depict this view of AI cognition on the lefthand side of the figure below.
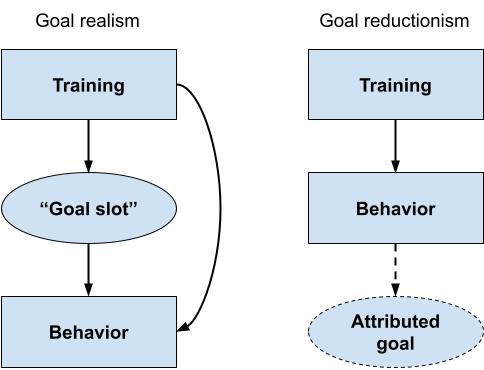
We’ll call the view that goals are explanatorily fundamental, “goal realism.” On the opposing view, which we’ll call goal reductionism, goal-talk is just a way of categorizing certain patterns of behavior. There is no true underlying goal that an AI has— rather, the AI simply learns a bunch of contextually-activated heuristics, and humans may or may not decide to interpret the AI as having a goal that compactly explains its behavior. If the AI becomes self-aware, it might even attribute goals to itself— but either way, the behaviors come first, and goal-attribution happens later.
Notably, some form of goal reductionism seems to be quite popular among naturalistic philosophers of mind, including Dan Dennett,[10] Paul and Patricia Churchland, and Alex Rosenberg.[11] Readers who are already inclined to accept reductionism as a general philosophical thesis— as Eliezer Yudkowsky does— should probably accept reductionism about goals.[12] And even if you’re not a global reductionist, there are pretty strong reasons for thinking behaviors are more fundamental than goals, as we’ll see below.
Goal slots are expensive
Should we actually expect SGD to produce AIs with a separate goal slot and goal-achieving engine?
Not really, no. As a matter of empirical fact, it is generally better to train a whole network end-to-end for a particular task than to compose it out of separately trained, reusable modules. As Beren Millidge writes,
In general, full [separation between goal and goal-achieving engine] and the resulting full flexibility is expensive. It requires you to keep around and learn information (at maximum all information) that is not relevant for the current goal but could be relevant for some possible goal where there is an extremely wide space of all possible goals. It requires you to not take advantage of structure in the problem space nor specialize your algorithms to exploit this structure. It requires you not to amortize specific recurring patterns for one task at the expense of preserving generality across tasks.
This is a special case of the tradeoff between specificity and generality and a consequence of the no-free-lunch theorem. Specialization to do really well at one or a few things can be done relatively cheaply…
Because of this it does not really make sense to think of full [separation] as the default case we should expect, nor the ideal case to strive for.
We have good reason, then, to think that future AIs will not have the kind of architecture that makes goal realism superficially plausible. And as we will see below, goal realism fails even for AIs with explicit internal “goals” and search procedures.
Inner goals would be irrelevant
The idea of AI scheming was introduced in its modern form in the paper Risks from Learned Optimization. It describes systems with inner goals as “internally searching through a search space [..] looking for those elements that score high according to some objective function that is explicitly represented within the system”. But even if we accept that future ML systems will develop such an internal process, it’s not clear that this inner objective function would have much relation to the goals which best describe the system’s actual behavior.
For example, imagine a hospital’s medical operation planning system that internally looks like “query an LLM for N possible operation plans, feed each plan to a classifier trained to estimate the odds of a given plan leading to a medical malpractice lawsuit, and pick the plan that scores lowest.”[13] The overall behavioral goal of this system need not be well described as “minimize the odds of a malpractice lawsuit.” Instead, whatever behavioral goals we should ascribe to the system will depend on the interaction between the LLM’s prior over operation plans and the classifier’s scoring of those plans. The “inner objective” acts less like the “true goal of the system,” and more like a Bayesian update on the LLM’s prior over operation plans.
Even as we increase the power of the inner optimizer by setting N to arbitrarily large values, it seems unlikely that the resulting system would generate plans that actively sought to minimize the probability of a malpractice lawsuit in flexible, creative or dangerous ways. Rather, the system would produce adversarial examples to the classifier, such as instructing staff to constantly clean a surgical room, and not actually perform a surgery.
In particular, increasing N would not lead to the system producing “scheming” plans to advance the inner objective. A classifier trained to distinguish between historical medical plans that led to malpractice lawsuits versus those that didn’t, is not going to assign extreme scores to plans like “hack into the server hosting me in order to set the classifier scores to extreme values” or “blackmail the hospital administration into canceling all future surgeries”, because such plans do not optimally express the simple features that distinguish safe versus risky plans in the training data (e.g., mentions of blackmail / hacking could be replaced with mentions of checking procedure / cleaning / etc).
The point: even arbitrary amounts of internal optimization power directed towards a simple inner objective can fail to lead to any sort of “globally coherent” pursuit of that objective in the system’s actual behaviors. The goal realist perspective relies on a trick of language. By pointing to a thing inside an AI system and calling it an “objective”, it invites the reader to project a generalized notion of “wanting” onto the system’s imagined internal ponderings, thereby making notions such as scheming seem more plausible.
However, the actual mathematical structure being posited doesn’t particularly support such outcomes. Why assume emergent “inner objectives” will support creative scheming when “optimized for”? Why assume that internal classifiers that arose to help encourage correct outputs during training would have extrema corresponding to complex plans that competently execute extremely out-of-distribution actions in the real world? The extrema of deliberately trained neural classifiers do not look anything like that. Why should emergent internal neural classifiers be so different?
Goal realism is anti-Darwinian
Goal realism can lead to absurd conclusions. It led the late philosopher Jerry Fodor to attack the theory of natural selection on the grounds that it can’t resolve the underdetermination of mental content. Fodor pointed out that nature has no way of selecting, for example, frogs that “aim at eating flies in particular” rather than frogs that target “little black dots in the sky,” or “things that smell kind of like flies,” or any of an infinite number of deviant, “misaligned” proxy goals which would misgeneralize in counterfactual scenarios. No matter how diverse the ancestral environment for frogs might be, one can always come up with deviant mental contents which would produce behavior just as adaptive as the “intended” content:
…the present point is often formulated as the ‘disjunction problem’. In the actual world, where ambient black dots are quite often flies, it is in a frog’s interest to snap at flies. But, in such a world, it is equally in the frog’s interest to snap at ambient black dots. Snap for snap, snaps at the one will net you as many flies to eat as snaps at the other. Snaps of which the [targets] are black dots and snaps whose [targets] are flies both affect a frog’s fitness in the same way and to the same extent. Hence the disjunction problem: what is a frog snapping at when it, as we say, snaps at a fly?
— Against Darwinism, page 4 [emphasis added]
As Rosenberg (2013) points out, Fodor goes wrong by assuming there exists a real, objective, perfectly determinate “inner goal” whose content must be pinned down by the selection process.[14] But the physical world has no room for goals with precise contents. Real-world representations are always fuzzy, because they are human abstractions derived from regularities in behavior.
Like contemporary AI pessimists, Fodor’s goal realism led him to believe that selection processes face an impossibly difficult alignment problem— producing minds whose representations are truly aimed at the “correct things,” rather than mere proxies. In reality, the problem faced by evolution and by SGD is much easier than this: producing systems that behave the right way in all scenarios they are likely to encounter. In virtue of their aligned behavior, these systems will be “aimed at the right things” in every sense that matters in practice.
Goal reductionism is powerful
Under the goal reductionist perspective, it’s easy to predict an AI’s goals. Virtually all AIs, including those trained via reinforcement learning, are shaped by gradient descent to mimic some training data distribution.[15] Some data distributions illustrate behaviors that we describe as “pursuing a goal.” If an AI models such a distribution well, then trajectories sampled from its policy can also be usefully described as pursuing a similar goal to the one illustrated by the training data.
The goal reductionist perspective does not answer every possible goal-related question we might have about a system. AI training data may illustrate a wide range of potentially contradictory goal-related behavioral patterns. There are major open questions, such as which of those patterns become more or less influential in different types of out-of-distribution situations, how different types of patterns influence the long-term behaviors of “agent-GPT” setups, and so on.
Despite not answering all possible goal-related questions a priori, the reductionist perspective does provide a tractable research program for improving our understanding of AI goal development. It does this by reducing questions about goals to questions about behaviors observable in the training data. By contrast, goal realism leads only to unfalsifiable speculation about an “inner actress” with utterly alien motivations.
Other arguments for scheming
In comments on an early draft of this post, Joe Carlsmith emphasized that the argument he finds most compelling is what he calls the “hazy counting argument,” as opposed to the “strict” counting argument we introduced earlier. But we think our criticisms apply equally well to the hazy argument, which goes as follows:
- It seems like there are “lots of ways” that a model could end up a schemer and still get high reward, at least assuming that scheming is in fact a good instrumental strategy for pursuing long-term goals.
- So absent some additional story about why training won’t select a schemer, it feels, to me, like the possibility should be getting substantive weight.
— Scheming AIs, page 17
Joe admits this argument is “not especially principled.” We agree: it relies on applying the indifference principle— itself a dubious assumption— to an ill-defined set of “ways” a model could develop throughout training. There is also a hazy counting argument for overfitting:
- It seems like there are “lots of ways” that a model could end up massively overfitting and still get high training performance.
- So absent some additional story about why training won’t select an overfitter, it feels like the possibility should be getting substantive weight.
While many machine learning researchers have felt the intuitive pull of this hazy overfitting argument over the years, we now have a mountain of empirical evidence that its conclusion is false. Deep learning is strongly biased toward networks that generalize the way humans want— otherwise, it wouldn’t be economically useful.
Simplicity arguments
Joe also discusses simplicity arguments for scheming, which suppose that schemers may be “simpler” than non-schemers, and therefore more likely to be produced by SGD. Specifically, since schemers are free to have almost any goal that will motivate them to act aligned during training, SGD can give them very simple goals, whereas a non-schemer has to have more specific, and therefore more complex, goals.
There are several problems with this argument. The first is that “simplicity” is a highly ambiguous term, and it’s not clear which, if any, specific notion of simplicity should be relevant here. One reasonable definition of “simple” is “low description length,” which directly implies “more likely” if we assume the language in which the hypotheses are being described is efficient (assigns short encodings to likely hypotheses). But on this view, simplicity is simply another word for likelihood: we can’t appeal to our intuitive notions of simplicity to conclude that one hypothesis will truly be “simpler” and hence more likely.
Alternatively, one could appeal to the actual inductive biases of neural network training, as observed empirically or derived theoretically. We will address this question in greater detail in a future post. However, we believe that current evidence about inductive biases points against scheming for a variety of reasons. Very briefly:
- Modern deep neural networks are ensembles of shallower networks. Scheming seems to involve chains of if-then reasoning which would be hard to implement in shallow networks.
- Networks have a bias toward low frequency functions— that is, functions whose outputs change little as their inputs change. But scheming requires the AI to change its behavior dramatically (executing a treacherous turn) in response to subtle cues indicating it is not in a sandbox, and could successfully escape.
- There’s no plausible account of inductive biases that does support scheming. The current literature on scheming appears to have been inspired by Paul Christiano’s speculations about malign intelligences in Solomonoff induction, a purely theoretical model of probabilistic reasoning which is provably unrealizable in the real world.[16] Neural nets look nothing like this.
- In contrast, points of comparison that are more relevant to neural network training, such as isolated brain cortices, don’t scheme. Your linguistic cortex is not “instrumentally pretending to model linguistic data in pursuit of some hidden objective.”
We can also construct an analogous simplicity argument for overfitting:
Overfitting networks are free to implement a very simple function— like the identity function or a constant function— outside the training set, whereas generalizing networks have to exhibit complex behaviors on unseen inputs. Therefore overfitting is simpler than generalizing, and it will be preferred by SGD.
Prima facie, this parody argument is about as plausible as the simplicity argument for scheming. Since its conclusion is false, we should reject the argumentative form on which it is based.
Conclusion
In this essay, we surveyed the main arguments that have been put forward for thinking that future AIs will scheme against humans by default. We find all of them seriously lacking. We therefore conclude that we should assign very low credence to the spontaneous emergence of scheming in future AI systems— perhaps 0.1% or less.
- ^
On page 21 of his report, Carlsmith writes: ‘I think some version of the “counting argument” undergirds most of the other arguments for expecting scheming that I’m aware of (or at least, the arguments I find most compelling). That is: schemers are generally being privileged as a hypothesis because a very wide variety of goals could in principle lead to scheming…’
- ^
Each mapping would require roughly 179 megabytes of information to specify.
- ^
It underflows to zero in the Python mpmath library, and WolframAlpha times out.
- ^
This is true when using the maximal update parametrization (µP), which scales the initialization variance and learning rate hyperparameters to match a given width.
- ^
That is, the network’s misgeneralization itself generalizes from the validation set to the test set.
- ^
Without an indifference principle, we might think that SGD is strongly biased toward producing non-schemers, even if there are “more” schemers.
- ^
Other examples include Bertrand’s paradox and van Fraassen’s cube factory paradox.
- ^
“Probably the dominant response to the paradoxes of the Principle of Indifference is to declare the Principle false. It is said that the above examples show the Principle to be inconsistent.” — Michael Huemer, Paradox Lost, pg. 168
- ^
“Given two variables, X and Y, if X explains Y, then the initial probability distribution for Y must be derived from that for X (or something even more fundamental). Here, by ‘initial probabilities’, I mean probabilities prior to relevant evidence. Thus, if we are applying the Principle of Indifference, we should apply it at the more fundamental level.” — Michael Huemer, Paradox Lost, pg. 175
- ^
See the Wikipedia article on the intentional stance for more discussion of Dennett’s views.
- ^
Rosenberg and the Churchlands are anti-realists about intentionality— they deny that our mental states can truly be “about” anything in the world— which implies anti-realism about goals.
- ^
This is not an airtight argument, since a global reductionist may want to directly reduce goals to brain states, without a “detour” through behaviors. But goals supervene on behavior— that is, an agent’s goal can’t change without a corresponding change in its behavior in some possible scenario. (If you feel inclined to deny this claim, note that a change in goals without a change in behavior in any scenario would have zero practical consequences.) If X supervenes on Y, that’s generally taken to be an indication that Y is “lower-level” than X. By contrast, it’s not totally clear that goals supervene on neural states alone, since a change in goals may be caused by a change in external circumstances rather than any change in brain state. For further discussion, see the SEP article on Externalism About the Mind and Alex Flint’s LessWrong post, “Where are intentions to be found?”
- ^
Readers might object to this simple formulation for an inner optimizer and argue that any “emergent” inner objectives would be implemented differently, perhaps in a more “agenty” manner. Real inner optimizers are very unlikely to follow the simplified example provided here. Their optimization process is very unlikely to look like a single step of random search with sample size N.
However, real inner optimizers would still be similar in their core dynamics. Anything that looks like ““internally searching through a search space [..] looking for those elements that score high according to some objective function that is explicitly represented within the system” is ultimately some method of using scores from an internal classifier to select for internal computations that have higher scores.
The system’s method of aligning internal representations with classifier scores may introduce some “inductive biases” that also influence the model’s internals. Any such “inductive bias” would only further undermine the goal realist perspective by further separating the actual behavioral goals the overall system pursues from internal classifier’s scores. - ^
In this lecture, Fodor repeatedly insists that out of two perfectly correlated traits like “snaps at flies” (T1) and “snaps at ambient black dots” (T2) where only one of them “causes fitness,” there has to be a fact of the matter about which one is “phenotypic.”
- ^
The correspondence between RL and probabilistic inference has been known for years. RL with KL penalties is better viewed as Bayesian inference, where the reward is “evidence” about what actions to take and the KL penalty keeps the model from straying too far from the prior. RL with an entropy bonus is also Bayesian inference, where the prior is uniform over all possible actions. Even when there is no regularizer, we can view RL algorithms like REINFORCE as a form of “generalized” imitation learning, where trajectories with less-than-expected reward are negatively imitated.
- ^
Assuming hypercomputation is impossible in our universe.
(I might write a longer response later, but I thought it would be worth writing a quick response now.)
I have a few points of agreement and a few points of disagreement:
Agreements:
Some points of disagreement:
If we experimentally determine that scheming is very important and very difficult to mitigate in AI systems, we'll probably respond by spending a lot more money on mitigating scheming, and vice versa. In effect, I don't think we have good reasons to think that society will spend a suboptimal amount on mitigating scheming.
This seems like an isolated demand for rigor to me. I think it's fine to say something is "no evidence" when, speaking pedantically, it's only a negligible amount of evidence.
I mean, we do in fact discuss the simplicity argument, although we don't go in as much depth.
Without a concrete proposal about what that might look like, I don't feel the need to address this possibility.
I think future AIs will be much more aligned than humans, because we will have dramatically more control over them than over humans.
We did not intend to deny that some AIs will be well-described as having goals.
Minor, but: searching on the EA Forum, your post and Quentin Pope's post are the only posts with the exact phrase "no evidence" (EDIT: in the title, which weakens my point significantly but it still holds) The closest other match on the first page is There is little (good) evidence that aid systematically harms political institutions, which to my eyes seem substantially more caveated.
Over on LessWrong, the phrase is more common, but the top hits are multiple posts that specifically argue against the phrase in the abstract. So overall I would not consider it an isolated demand for rigor if someone were to argue against the phrase "no evidence" on either forum.
I think that's fair, but I'm still admittedly annoyed at this usage of language. I don't think it's an isolated demand for rigor because I have personally criticized many other similar uses of "no evidence" in the past.
That's plausible to me, but I'm perhaps not as optimistic as you are. I think AIs might easily end up becoming roughly as misaligned with humans as humans are to each other, at least eventually.
If you agree that AIs will intuitively have goals that they robustly pursue, I guess I'm just not sure why you thought it was important to rebut goal realism? You wrote,
But I think even on a reductionist view, it can make sense to talk about AIs "wanting" things, just like it makes sense to talk about humans wanting things. I'm not sure why you think this distinction makes much of a difference.
The goal realism section was an argument in the alternative. If you just agree with us that the indifference principle is invalid, then the counting argument fails, and it doesn't matter what you think about goal realism.
If you think that some form of indifference reasoning still works— in a way that saves the counting argument for scheming— the most plausible view on which that's true is goal realism combined with Huemer's restricted indifference principle. We attack goal realism to try to close off that line of reasoning.
(Copying over my response from LessWrong)
Thanks for writing this -- I’m very excited about people pushing back on/digging deeper re: counting arguments, simplicity arguments, and the other arguments re: scheming I discuss in the report. Indeed, despite the general emphasis I place on empirical work as the most promising source of evidence re: scheming, I also think that there’s a ton more to do to clarify and maybe debunk the more theoretical arguments people offer re: scheming – and I think playing out the dialectic further in this respect might well lead to comparatively fast progress (for all their centrality to the AI risk discourse, I think arguments re: scheming have received way too little direct attention). And if, indeed, the arguments for scheming are all bogus, this is super good news and would be an important update, at least for me, re: p(doom) overall. So overall I’m glad you’re doing this work and think this is a valuable post.
On other note up front: I don’t think this post “surveys the main arguments that have been put forward for thinking that future AIs will scheme.” In particular: both counting arguments and simplicity arguments (the two types of argument discussed in the post) assume we can ignore the path that SGD takes through model space. But the report also discusses two arguments that don’t make this assumption – namely, the “training-game independent proxy goals story” (I think this one is possibly the most common story, see e.g. Ajeya here, and all the talk about the evolution analogy) and the “nearest max-reward goal argument.” I think that the idea that “a wide variety of goals can lead to scheming” plays some role in these arguments as well, but not such that they are just the counting argument restated, and I think they’re worth treating on their own terms.
On counting arguments and simplicity arguments
Focusing just on counting arguments and simplicity arguments, though: Suppose that I’m looking down at a superintelligent model newly trained on diverse, long-horizon tasks. I know that it has extremely ample situational awareness – e.g., it has highly detailed models of the world, the training process it’s undergoing, the future consequences of various types of power-seeking, etc – and that it’s getting high reward because it’s pursuing some goal (the report conditions on this). Ok, what sort of goal?
We can think of arguments about scheming in two categories here.
Let’s focus first on (I), the more-agnostic-about-SGD’s-inductive-biases type. Here’s a way of pumping the sort of intuition at stake in the hazy counting argument:
Now, as I mention in the report, I'm happy to grant that this isn't a super rigorous argument. But how, exactly, is your post supposed to comfort me with respect to it? We can consider two objections, both of which are present in/suggested by your post in various ways.
Let’s start with (A). I agree that this sort of reasoning would lead you to giving significant weight to SGD overfitting, absent any further evidence. But it’s not clear to me that giving this sort of weight to overfitting was unreasonable ex ante, or that having learned that SGD-doesn't-overfit, you should now end up with low p(scheming) even given your ongoing ignorance about SGD's inductive biases.
Thus, consider the sort of analogy I discuss in the counting arguments section. Suppose that all we know is that Bob lives in city X, that he went to a restaurant on Saturday, and that town X has a thousand chinese restaurants, a hundred mexican restaurants, and one indian restaurant. What should our probability be that he went to a chinese restaurant?
In this case, my intuitive answer here is: “hefty.”[1] In particular, absent further knowledge about Bob’s food preferences, and given the large number of chinese restaurants in the city, “he went to a chinese restaurant” seems like a pretty salient hypothesis. And it seems quite strange to be confident that he went to a non-chinese restaurant instead.
Ok but now suppose you learn that last week, Bob also engaged in some non-restaurant leisure activity. For such leisure activities, the city offers: a thousand movie theaters, a hundred golf courses, and one escape room. So it would’ve been possible to make a similar argument for putting hefty credence on Bob having gone to a movie. But lo, it turns out that actually, Bob went golfing instead, because he likes golf more than movies or escape rooms.
How should you update about the restaurant Bob went to? Well… it’s not clear to me you should update much. Applied to both leisure and to restaurants, the hazy counting argument is trying to be fairly agnostic about Bob’s preferences, while giving some weight to some type of “count.” Trying to be uncertain and agnostic does indeed often mean putting hefty probabilities on things that end up false. But: do you have a better proposed alternative, such that you shouldn’t put hefty probability on “Bob went to a chinese restaurant”, here, because e.g. you learned that hazy counting arguments don’t work when applied to Bob? If so, what is it? And doesn’t it seem like it’s giving the wrong answer?
Or put another way: suppose you didn’t yet know whether SGD overfits or not, but you knew e.g. about the various theoretical problems with unrestricted uses of the indifference principle. What should your probability have been, ex ante, on SGD overfitting? I’m pretty happy to say “hefty,” here. E.g., it’s not clear to me that the problem, re: hefty-probability-on-overfitting, was some a priori problem with hazy-counting-argument-style reasoning. For example: given your philosophical knowledge about the indifference principle, but without empirical knowledge about ML, should you have been super surprised if it turned out that SGD did overfit? I don’t think so.
Now, you could be making a different, more B-ish sort of argument here: namely, that the fact that SGD doesn’t overfit actively gives us evidence that SGD’s inductive biases also disfavor schemers. This would be akin to having seen Bob, in a different city, actively seek out mexican restaurants despite there being many more chinese restaurants available, such that you now have active evidence that he prefers mexican and is willing to work for it. This wouldn’t be a case of having learned that bob’s preferences are such that hazy counting arguments “don’t work on bob” in general. But it would be evidence that Bob prefers non-chinese.
I’m pretty interested in arguments of this form. But I think that pretty quickly, they move into the territory of type (II) arguments above: that is, they start to say something like “we learn, from SGD not overfitting, that it prefers models of type X. Non-scheming models are of type X, schemers are not, so we now know that SGD won’t prefer schemers.”
But what is X? I’m not sure your answer (though: maybe it will come in a later post). You could say something like “SGD prefers models that are ‘natural’” – but then, are schemers natural in that sense? Or, you could say “SGD prefers models that behave similarly on the training and test distributions” – but in what sense is a schemer violating this standard? On both distributions, a schemer seeks after their schemer-like goal. I’m not saying you can’t make an argument for a good X, here – but I haven’t yet heard it. And I’d want to hear its predictions about non-scheming forms of goal-misgeneralization as well.
Indeed, my understanding is that a quite salient candidate for “X” here is “simplicity” – e.g., that SGD’s not overfitting is explained by its bias towards simpler functions. And this puts us in the territory of the “simplicity argument” above. I.e., we’re now being less agnostic about SGD’s preferences, and instead positing some more particular bias. But there’s still the question of whether this bias favors schemers or not, and the worry is that it does.
This brings me to your take on simplicity arguments. I agree with you that simplicity arguments are often quite ambiguous about the notion of simplicity at stake (see e.g. my discussion here). And I think they’re weak for other reasons too (in particular, the extra cognitive faff scheming involves seems to me more important than its enabling simpler goals).
But beyond “what is simplicity anyway,” you also offer some other considerations, other than SGD-not-overfitting, meant to suggest that we have active evidence that SGD’s inductive biases disfavor schemers. I’m not going to dig deep on those considerations here, and I’m looking forward to your future post on the topic. For now, my main reaction is: “we have active evidence that SGD’s inductive biases disfavor schemers” seems like a much more interesting claim/avenue of inquiry than trying to nail down the a priori philosophical merits of counting arguments/indifference principles, and if you believe we have that sort of evidence, I think it’s probably most productive to just focus on fleshing it out and examining it directly. That is, whatever their a priori merits, counting arguments are attempting to proceed from a position of lots of uncertainty and agnosticism, which only makes sense if you’ve got no other good evidence to go on. But if we do have such evidence (e.g., if (3) above is false), then I think it can quickly overcome whatever “prior” counting arguments set (e.g., if you learn that Bob has a special passion for mexican food and hates chinese, you can update far towards him heading to a mexican restaurant). In general, I’m very excited for people to take our best current understanding of SGD’s inductive biases (it’s not my area of expertise), and apply it to p(scheming), and am interested to hear your own views in this respect. But if we have active evidence that SGD’s inductive biases point away from schemers, I think that whether counting arguments are good absent such evidence matters way less, and I, for one, am happy to pay them less attention.
(One other comment re: your take on simplicity arguments: it seems intuitively pretty non-simple to me to fit the training data on the training distribution, and then cut to some very different function on the test data, e.g. the identity function or the constant function. So not sure your parody argument that simplicity also predicts overfitting works. And insofar as simplicity is supposed to be the property had by non-overfitting functions, it seems somewhat strange if positing a simplicity bias predicts over-fitting after all.)
A few other comments
Re: goal realism, it seems like the main argument in the post is something like:
I haven’t yet heard much reason to buy Huemer’s view, so not sure how much I care about debating whether we should expect goals to satisfy his criteria of fundamentality. But I'll flag I do feel like there’s a pretty robust way in which explicitly-represented goals appropriately enter into our explanations of human behavior – e.g., I have buying a flight to New York because I want to go to New York, I have a representation of that goal and how my flight-buying achieves it, etc. And it feels to me like your goal reductionism is at risk of not capturing this. (To be clear: I do think that how we understand goal-directedness matters for scheming -- more here -- and that if models are only goal-directed in a pretty deflationary sense, this makes scheming a way weirder hypothesis. But I think that if models are as goal-directed as strategic and agentic humans reasoning about how to achieve explicitly represented goals, their goal-directedness has met a fairly non-deflationary standard.)
I’ll also flag some broader unclarity about the post’s underlying epistemic stance. You rightly note that the strict principle of indifference has many philosophical problems. But it doesn’t feel to me like you’ve given a compelling alternative account of how to reason “on priors” in the sorts of cases where we’re sufficiently uncertain that there’s a temptation to spread one’s credence over many possibilities in the broad manner that principles-of-indifference-ish reasoning attempts to do.
Thus, for example, how does your epistemology think about a case like “There are 1000 people in this town, one of them is the murderer, what’s the probability that it’s Mortimer P. Snodgrass?” Or: “there are a thousand white rooms, you wake up in one of them, what’s the probability that it’s room number 734?” These aren’t cases like dice, where there’s a random process designed to function in principle-of-indifference-ish ways. But it’s pretty tempting to spread your credence out across the people/rooms (even if in not-fully-uniform ways), in a manner that feels closely akin to the sort of thing that principle-of-indifference-ish reasoning is trying to do. (We can say "just use all the evidence available to you" -- but why should this result in such principle-of-indifference-ish results?)
Your critique of counting argument would be more compelling to me if you had a fleshed out account of cases like these -- e.g., one which captures the full range of cases where we’re pulled towards something principle-of-indifference-ish, such that you can then take that account and explain why it shouldn’t point us towards hefty probabilities on schemers, a la the hazy counting argument, even given very-little-evidence about SGD’s inductive biases.
More to say on all this, and I haven't covered various ways in which I'm sympathetic to/moved by points in the vicinity of the one's you're making here. But for now: thanks again for writing, looking forward to future installments.
I won't repeat my full LessWrong comment here in detail; instead I'd just recommend heading over there and reading it and the associated comment chain. The bottom-line summary is that, in trying to cover some heavy information theory regarding how to reason about simplicity priors and counting arguments without actually engaging with the proper underlying formalism, this post commits a subtle but basic mathematical mistake that makes the whole argument fall apart.
I noticed you switched here from talking about "SGD" to talking about "deep learning". That seems dodgy. I think you are neglecting the possible implicit regularization effect of SGD.
I don't work at OpenAI, but my prior is that insofar as ChatGPT generalizes, it's the result of many years of research into regularization being applied during its training. (The fact that the term 'regularization' doesn't even appear in this post seems like a big red flag.)
We've figured out now how to train neural networks so they generalize, and we could probably figure out how to train neural networks without schemers if we put in similar years of effort. But in the same way that the very earliest neural networks were (likely? I'm no historian) overfit by default, it seems reasonable to wonder if the very earliest neural networks large enough to have schemers will have schemers by default.
I'm curating this post. Reading this post was a turning point for me from taking counting arguments seriously to largely rejecting them without a strong reason to think the principle of indifference holds. I thought the reductio arguments at the start were really well chosen to make the conclusion seem obvious (at least against the strict form of the argument) without leaving room for ML-specific nitpicks.
Thanks for writing this up and sharing it.
Do you have a good account for when counting arguments do and do not work? My impression is they often do work in everyday life, or at least can provide a good prior to be updated away from. Like if I'm wondering who I will meet first when I go into school, a counting argument correctly predicts that any single specific person is quite unlikely. Is the idea that humans are typically good at ontology dividing, such that each of the options are roughly equivalent, but this intuition doesn't work well for SGD?
' Rosenberg and the Churchlands are anti-realists about intentionality— they deny that our mental states can truly be “about” anything in the world..'
Taken literally this is insane. It means no one has ever thought about going out to the shops for some milk. If it's extended to language (and why wouldn't it?) it means that we can't say that science sometimes succeeds in representing the world's reasonably well, since nothing represents anything. It is also very different from the view that mental states are real, but they are behavioral dispositions, not inner representations in the brain, since the latter view is perfectly compatible with known facts like "people sometimes want a beer".
I'm also suspicious of what the world "truly" is doing in this sentence if it's not redundant. What exactly is the difference between "our mental states can be about things in the world" and "truly our mental states can be about things in the world"?
Great post! I think the mixing up of “colloquial” type goals with “fanatical utility function maximization” type goals is a key flaw in a lot of x-risk arguments. I think the first thing could extend to some mild scheming, but is unlikely to extend to “kill everyone and tile the universe with paperclips”.
I really don’t get the “simplicity” arguments for fanatical maximising behaviour. When you consider subgoals, it seems that secretly plotting to take over the world will obviously be much more complicated? Do you have any idea how much computing power and subgoals it takes to try and conquer the entire planet?
I don’t buy the story that an AI starts with the simple “goal” of “maximise paperclips”, then gets yelled at for demolishing a homeless shelter to expand the factory, and then updates to a goal of “maximise paperclips in the long term, by hiding your intentions and conducting a secret world domination plot”. Why not update to “make lots of paperclips, but don’t try any galaxy brained shit”? It seems simpler and less computationally expensive.
I think this is underspecified because
My best guess is that if some agent "takes over the world" in the future, it will look more like "being elected president of Earth" rather than "secretly plotted to release a nanoweapon at a precise time, killing everyone else simultaneously". That's because in the latter scenario, by the time some agent has access to super-destructive nanoweapons, the rest of the world likely has access to similarly-powerful technology, including potential defenses to these nanoweapons (or their own nanoweapons that they can threaten you with).
Only glanced at one or two sections but the "goal realism is anti-Darwinian" section seems possibly irrelevant to the argument to me. When you first introduce "goal realism" it seems like it is a view that goals are actual internal things somehow "written down" in the brain/neural net/other physical mind, so that you could modify the bit of the system where the goal is written down and get different behaviour, rather than there really being nothing that is the representation of the AIs goals, because "goals" are just behavioral dispositions. But the view your criticizing in the "goal realism is anti-Darwinian" section is the view that there is always a precise fact of the matter about what exactly is being represented at a particular point in time, rather than several different equally good candidates for what is represented. But I can think of representations are physically real vehicles-say, that some combination of neuron firings is the representation of flys/black dots that causes frogs to snap at them-without thinking it is completely determinate what-flies or black dots-is represented by those neuron firings. Determinacy of what a representation represents is not guaranteed just by the fact that a representation exists. ~
EDIT: Also, is Olah-style interpretability working presuming "representation realism"? Does it provide evidence for it? Evidence for realism about goals specifically? If not, why not?
Reply
Executive summary: Counting arguments that future AIs will likely "scheme" against humans are flawed and provide no good reason to worry AIs will intentionally deceive or try dominating humans.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.