Thanks to Slava Matyuhin for comments
Summary
AIs can be used to resolve forecasting questions on platforms like Manifold and Metaculus.
AI question resolution, in theory, can be far more predictable, accessible, and inexpensive to human resolution.
Current AI tools (combinations of LLM calls and software) are mediocre at judging subjective or speculative questions. We expect them to improve.
AI tools are changing rapidly. If we want to organize forecasting questions to be resolved using an AI tool in 10 years, instead of selecting a specific tool, we might want to select a protocol for choosing the best tool at resolution time. We call this an "Epistemic Selection Protocol".
If we have a strong "Epistemic Selection Protocol" that we like, and expect that we'll have sufficient AI tools in the near future, then we could arguably start to write forecasting questions for them right away.
The methods listed above, if successful, wouldn't just be for resolving questions on prediction platforms. They could be generalized to pursue broad-scale and diverse evaluations.
We provide a “A Short Story of How This Plays Out", which is perhaps the most accessible part of this for most readers.
We list a bunch of potential complications with AI tools and Epistemic Selection Protocols. While these will be complex, we see no fundamental bottlenecks.
Motivation
Say we want to create a prediction tournament on a complex question.
For example:
- “Will there be over 10 million people killed in global wars between 2025 and 2030?”
- “Will IT security incidents be a national US concern, on the scale of the top 5 concerns, in 2030?”
- “Will bottlenecks in power capacity limit AIs by over 50%, in 2030?”
While these questions involve subjective elements, they aren't purely matters of opinion. Come 2030, though people might debate the details, informed observers would likely reach broadly similar conclusions.
Currently, such questions are typically resolved by human evaluators. On Manifold, the question author serves as judge, with authors developing reputations for their judgment quality over time. Metaculus takes a different approach for more complex and subjective questions, often employing small panels of subject matter experts.
However, human evaluators have several limitations:
- High costs, particularly for domain experts
- Limited track records of evaluation quality
- Poor accessibility - most forecasters cannot directly query them
- Inconsistency over time as their views and motivations evolve
- Uncertain long-term availability
- Vulnerability to biases and potential conflicts of interest
AIs as Question Evaluators
Instead of using humans to resolve thorny questions, we can use AIs. There are many ways we could attempt to do this, so we’ll walk through a few examples.
Option 1: Use an LLM
The first option to consider is to use an LLM as an evaluator. For example, write,
“This question will be judged by Claude 3.5 Sonnet (2024-06-20). The specific prompt will be, …”
This style is replicable, simple, and inexpensive. However, it clearly has some downsides. The first obvious one is that Claude 3.5 Sonnet doesn’t perform web searches, so its knowledge would likely be too limited to resolve future forecasting questions.
Option 2: Use an AI Tool with Search
Instead of using a standard LLM, you might want to use a tool that uses both LLMs and web searches. Perplexity might be the most famous one now, but other advanced research assistants are starting to come out. In theory one should be able to set a research budget that’s in line with the importance and complexity of the question.
There's been some experimentation here. See this guide on using GPT4 for resolving questions on Manifold, and this experiment write up. GPT4 allows for basic web searches.
This option is probably better than Option 1 for most things. But there are still problems. The next major one is the risk that Perplexity, or any other single tool we can point to now, won’t be the leading one in the future. The field is moving rapidly, it’s difficult to tell which tools will even exist in 5 years, let alone be the preferred options.
Option 3: Use an “Epistemic” Selection Protocol
In this case, one doesn't select a specific AI tool. Instead one selects a process or protocol that selects an AI tool.
For example:
“In 2030, we will resolve this question using the leading AI tool on the ‘Forbes 2030 Most trusted AI tools’ list.”
We’re looking for AI tools that are “trusted to reason about complex, often speculative or political matters.” This arguably can be more quickly expressed as searching for the tool with the best epistemics.
Epistemic Selection Protocols (Or, how do we choose the best AI tool to use?)
Arguably, AI Epistemic Selection Protocols can be the best choice of the above options, if one could implement them effectively, for most 2+ year questions. There are a lot of potential processes to choose, though most would be too complicated to be worthwhile. We want to strike a balance between simplicity and accuracy.
Let’s first list the most obvious options.
Option 1: Trusted and formalized epistemic evaluations
There’s currently a wide variety of AI benchmarks. For example, TruthfulQA and various investigations of model sycophancy. But arguably, none of these would be great proxies for which AI tool would be the most trusted question resolvers in the future. Newer, deliberate benchmarks could help here.
Example:
“This forecasting question will be resolved, using whichever AI Tool does the best on Complete Epistemic Benchmark X, and can be used for less than $20.”
Option 2: Human-derived trust rankings
Humans could simply be polled on which AI tools they regard as the most trustworthy. Different groups of humans would have different preferences, so the group would need to be specified in advance for an AI Selection Process.
Example:
“This forecasting question will be resolved, using whichever AI Tool is on the top of the list of ‘Most trusted AI Tools’ on LessWrong, and can be used for less than $20.”
Option 3: Inter-AI trust ratings
AI tools could select future AI tools to use. This could be a 1-step solution, where an open-source or standardized (for the sake of ensuring it will be available long-term) solution is asked to identify the best available candidate. Or it could be a multiple-step solution, where perhaps AI tools are asked to recommend each other using some simple algorithm. This can be similar in concept to the Community Notes algorithm.
Example:
“This forecasting question will be resolved, using whichever AI Tool wins a poll of the ‘Most trusted AI tools’ according to AI tools.’ In this poll, each AI tool will recommend its favorite of the other available candidates.” (Note: This specific proposal can be gamed, so greater complexity will likely be required.)
A Short Story of How This Plays Out
In 2025, several question writers on Manifold experiment with AI resolution systems. Some questions include:
“Will California fires in 2026 be worse than those in 2025? To answer this, I’ll ask Perplexity on Jan 1, 2026. My prompt will be, [Will California fires in 2026 be worse than those in 2025? Judge this by guessing the total economic loss.]”
“How many employees will OpenAI have in Dec 2025? To answer this, I’ll first ask commenters to write arguments and/or facts that they’ve found on this. I’ll filter this for what seems accurate, then I’ll paste this into Perplexity. I’ll call Perplexity 5 times, and average the results.”
Forecasters gradually identify the uses and limitations of such systems. It turns out they are surprisingly bad at advanced physics questions, for some surprising reason. There are a few clever prompting strategies that help ensure that these AIs put out more consistent results.
AI tools like Perplexity also get very good at hunting down and answering questions that are straightforward to resolve. Manifold adds custom functionality to do this. For example, say someone writes a question, “What Movie Will Win The 2025 Oscars For Best Picture?” When they do, they’ll be given the option to have a Manifold AI system automatically make a suggested guess for them, at the time of expected question resolution. These guesses will begin with high error rates (10%), but these will gradually drop.
Separately, various epistemic evaluations are established. There are multiple public and private rankings. There are also surveys of the “Most Trusted AIs”, held on various platforms such as Manifold, LessWrong, and The Verge. Leading consumer product review websites such as Consumer Reports and Wirecutter begin to have ratings for AI tools, using defined categories such as “accuracy” and “reasonableness.”
One example question from this is:
“In 2030, will it seem like o1 was an important AI development, that was at least as innovative and important as GPT4? This will be resolved using whichever AI leads the “Most trusted AIs” poll on Manifold in 2029.”
There will be a long tail of AI tools that are proposed as contenders for epistemic benchmarks. Most of the options are simply minor tweaks on other options or light routers. Few of these will get the full standard evaluations, but good proxies will emerge. It turns out that you can get a decent measure by using the top fully-evaluated AI systems to evaluate more niche systems.
In 2027, there will be a significant amount of understanding, buy-in, and sophistication with such systems (at least among a few niche communities, like Manifold users). This will make it possible to scale them for more ambitious uses.
Metaculus runs some competitions that include:
“What is the relative value of each of [the top 500 AI safety papers of 2026]? This will be resolved in 2030 by using the most trusted AI system, via LessWrong or The Economist, at that time. This AI will order all of the papers - forecasters should estimate the percentile that each paper will achieve.”
“What is the expected value of every biosafety organization in 2027, estimated as what Open Philanthropy would have paid for it from their biosafety funding pool in 2027? This will be judged in 2029, by the most trusted AI system, with a budget of $1,000 for each evaluation.”
Around this time, some researchers will begin to make wider kinds of analyses, and forecast compressions.
“How will the top epistemic model of 2030 evaluate the accuracy and value of the claims of each of the top 100 intellectuals from 2027?”
“Will the top epistemic model of 2030 consider the current top epistemic models to be ‘highly overconfident’ for at least 10% of the normative questions they are asked?”
The top trusted AI tools start to become frequent ways to second-guess humans. For example, if a boss makes a controversial decision, people could contest the decision if top AI tools back them up. Similar analyses would be used within governments.
As these AI tools become even more trusted, they will replace many humans for important analyses and decisions. Humans will spend a great deal of effort focused on assuring these AI tools are doing a good job, and they'll have the time for that because there will be few other things they need to directly evaluate or oversee.
Protocol Complications & Potential Solutions
Complication 1: Lack of Sufficient AI Tools
In the beginning, we expect that many people won’t trust any AI tools to be adequate in resolving many questions. Even if tools look good in evaluations, it will take time for them to build trust.
One option is to set certain criteria for sufficiency. For example, one might say, “This question will be resolved using whichever AI system first gets to a 90/100 on the Epistemic Benchmark Evaluation…” This would clearly require understanding and trust in the evaluations, rather than in a specific tool, so this would require high-quality evaluations or polls.
Complication 2: Lack of Ground Truth
Many subjective and speculative questions lack definitive answers. Some questions can only be answered long after the information would be useful, while others are inherently impossible to resolve with complete certainty.
In such cases, the goal should shift from seeking perfect precision to outperforming alternative evaluation methods. Success means providing better answers than existing approaches, given practical constraints of cost, compute, and time.
AI evaluators should prioritize two key aspects:
- Calibration: Systems should express appropriate levels of certainty, aligned with the reference frame they're operating from
- Resolution: Within the bounds of reliable calibration, provide the most detailed and specific answers possible
For example, consider the question "What will be the economic impact of California wildfires in 2028?" While a perfectly precise answer is impossible, AI systems can progressively approach better estimates by:
- Aggregating multiple data sources
- Explicitly modeling uncertainties
- Identifying and accounting for measurement limitations
- Clearly stating assumptions and confidence levels
As long as a resolution is calibrated and fairly unbiased, it can be incentive-compatible for forecasting.
Complication 3: Goodharting
We’d want to avoid a situation where one tool technically maximizes a narrow “Epistemic Selection Protocol”, but is actually poor at doing many of the things we want from a resolver AI.
To get around this, the Protocol could make specifications like the following:
What will be the most epistemically-capable service on [Date] that satisfies the following requirements?
- Costs under $20 per run.
- Is publicly available.
- Has over 1000 human users per month (this is to ensure there’s no bottleneck that’s hard to otherwise specify.)
- Completes runs within 10 minutes.
- Has been separately reviewed to not have significantly and deceivingly goodharted on this specific benchmark.
It’s often possible to get around Goodharting by applying additional layers of complexity. Whether it’s worth it depends on the situation.
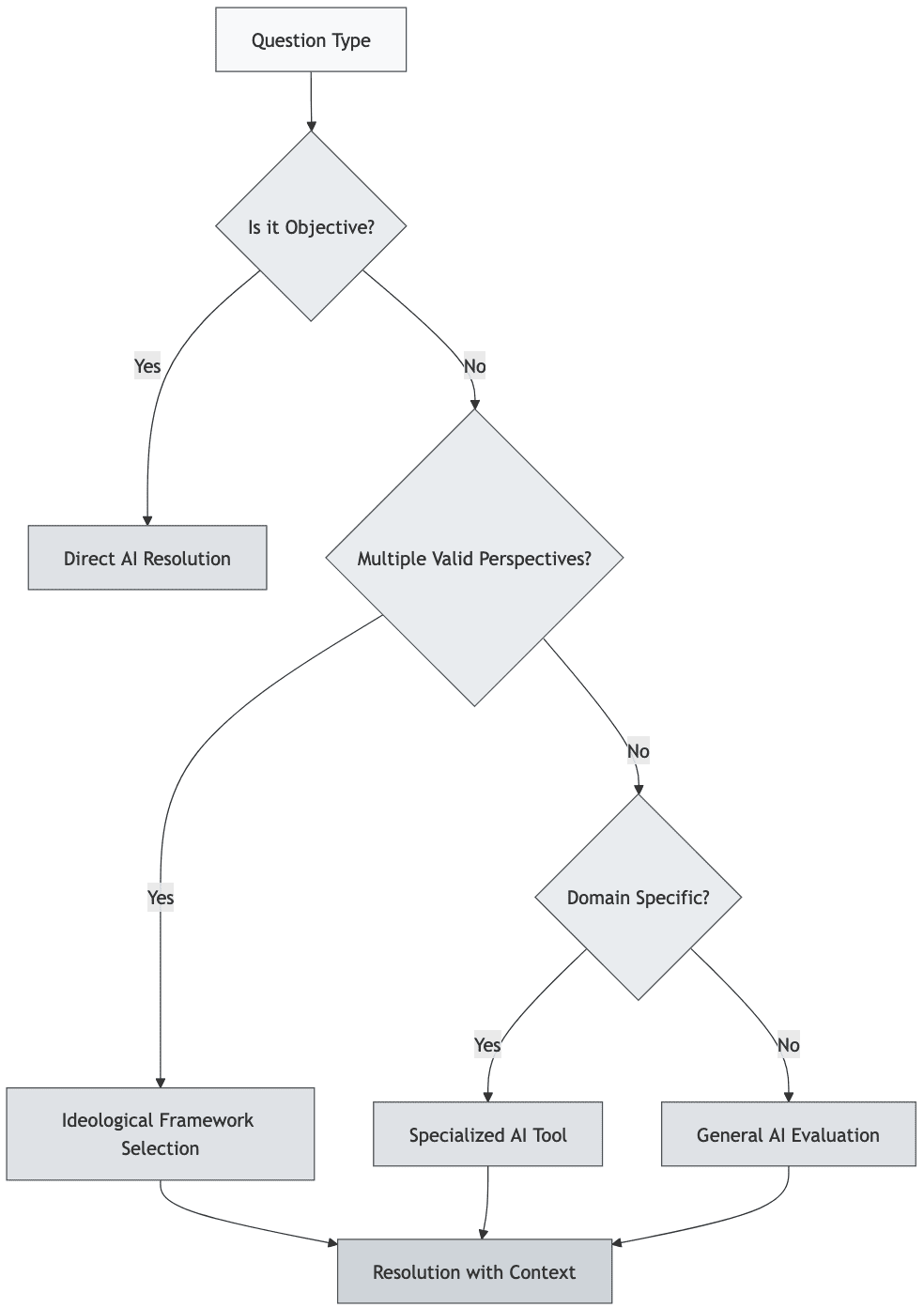
Complication 4: Different Ideologies
Consider a question about the impact of a tax cut policy. People with different philosophical or ideological backgrounds will likely disagree on fundamental assumptions, making a single "correct" answer impossible.
The simplest solution—declaring it a "complex issue with multiple valid perspectives"—is typically close to useless. A more useful approach would be developing AI tools that can represent different ideological frameworks, either through multiple specialized systems or a single system with adjustable philosophical parameters.
A more sophisticated approach could generate personalized evaluations based on individual characteristics and depth of analysis. For instance: "How would someone with background X evaluate California Proposition 10 in 2030, after studying it for [10, 100, 1000] hours?" This could be implemented using an algorithm that accounts for both personal attributes and time invested in understanding the issue. Scorable Functions might be a useful format.
Complication 5: AI Tools with Different Strengths
One might ask:
“What if different AI tools are epistemically dominant in different areas? For example, one is great at political science, and another is great at advanced mathematics.”
An obvious answer is to then create simple compositions of AI tools. A router can be used to send specific requests or sub-requests to other AI tools that are best equipped to handle them.
Complication 6: AI Tools that Recommend Other AI Tools
Imagine there’s a situation where one AI tool is chosen, but that tool recommends a different tool instead. For example, Perplexity 3.0 is asked a question, and it responds by stating that Claude 4.5 could do a better job than it could. Arguably it would make a lot of sense that if an AI tool were highly trusted to make speculative judgements, it could be trusted to be correct when claiming that a different tool is superior to itself.
This probably won’t be a major bottleneck. If AI tools could simply delegate other tools for specific questions, that could just be considered part of it during evaluation.
Going Forward
We hope this post is useful at advancing the conversation around AIs for question resolution and Epistemic AI Protocols. But it's still an early conversation.
We think there's a great deal of early experimentation and exploration to do in this broad space. Modern AI tools are arguably already good enough for broad use, and light wrappers on such tools can get us further. We hope to see work here in the next few years.