Note: This post was crossposted from Planned Obsolescence by the Forum team, with the author's permission. The author may not see or respond to comments on this post.
This blogpost was written in a personal capacity and statements here do not necessarily reflect the views of any of my employer.
OpenAI says o1-preview can't meaningfully help novices make chemical and biological weapons. Their test results don’t clearly establish this.
Before launching o1-preview last month, OpenAI conducted various tests to see if its new model could help make Chemical, Biological, Radiological, and Nuclear (CBRN) weapons. They report that o1-preview (unlike GPT-4o and older models) was significantly more useful than Google for helping trained experts plan out a CBRN attack. This caused the company to raise its CBRN risk level to “medium” when GPT-4o (released only a month earlier) had been at “low.”[1]
Of course, this doesn't tell us if o1-preview can also help a novice create a CBRN threat. A layperson would need more help than an expert — most importantly, they'd probably need some coaching and troubleshooting to help them do hands-on work in a wet lab. (See my previous blog post for more.)
OpenAI says that o1-preview is not able to provide "meaningfully improved assistance” to a novice, and so doesn't meet their criteria for "high" CBRN risk.[2] Specifically, the company claims that “creating such a threat requires hands-on laboratory skills that the models cannot replace.”
The distinction between "medium" risk (advanced knowledge) and "high" risk (advanced knowledge plus wet lab coaching) has important tangible implications. At the medium risk level, OpenAI didn't commit to doing anything special to make o1-preview safe. But if OpenAI had found that o1-preview met its definition of “high” risk, then, according to their voluntary safety commitments, they wouldn't have been able to release it immediately. They'd have had to put extra safeguards in place, such as removing CBRN-related training data or training it to more reliably refuse CBRN-related questions, and ensure these measures brought the risk back down.[3]
So what evidence did OpenAI use to conclude that o1-preview can't meaningfully help novices with hands-on laboratory skills? According to OpenAI's system card, they're developing a hands-on laboratory test to study this directly. But they released o1-preview before that test concluded and didn’t share any preliminary results.[4] Instead, they cite three multiple-choice tests as proxies for laboratory help.[5]
These proxy tests would support OpenAI's claim if they're clearly easier than helping a novice, and o1-preview clearly fails them. But diving into their report, that's not what I see:
- o1-preview scored at least as well as experts at FutureHouse’s ProtocolQA test — a takeaway that's not reported clearly in the system card.
- o1-preview scored well on Gryphon Scientific’s Tacit Knowledge and Troubleshooting Test, which could match expert performance for all we know (OpenAI didn’t report human performance).
- o1-preview scored worse than experts on FutureHouse’s Cloning Scenarios, but it did not have the same tools available as experts, and a novice using o1-preview could have possibly done much better.
Beyond this, OpenAI’s system card left some other questions unaddressed (for example, most of the reported scores come from a ‘near-final’ version of the model that was still being trained, not the one they actually deployed).[6] The main issues with these tests are summarized in the table below.
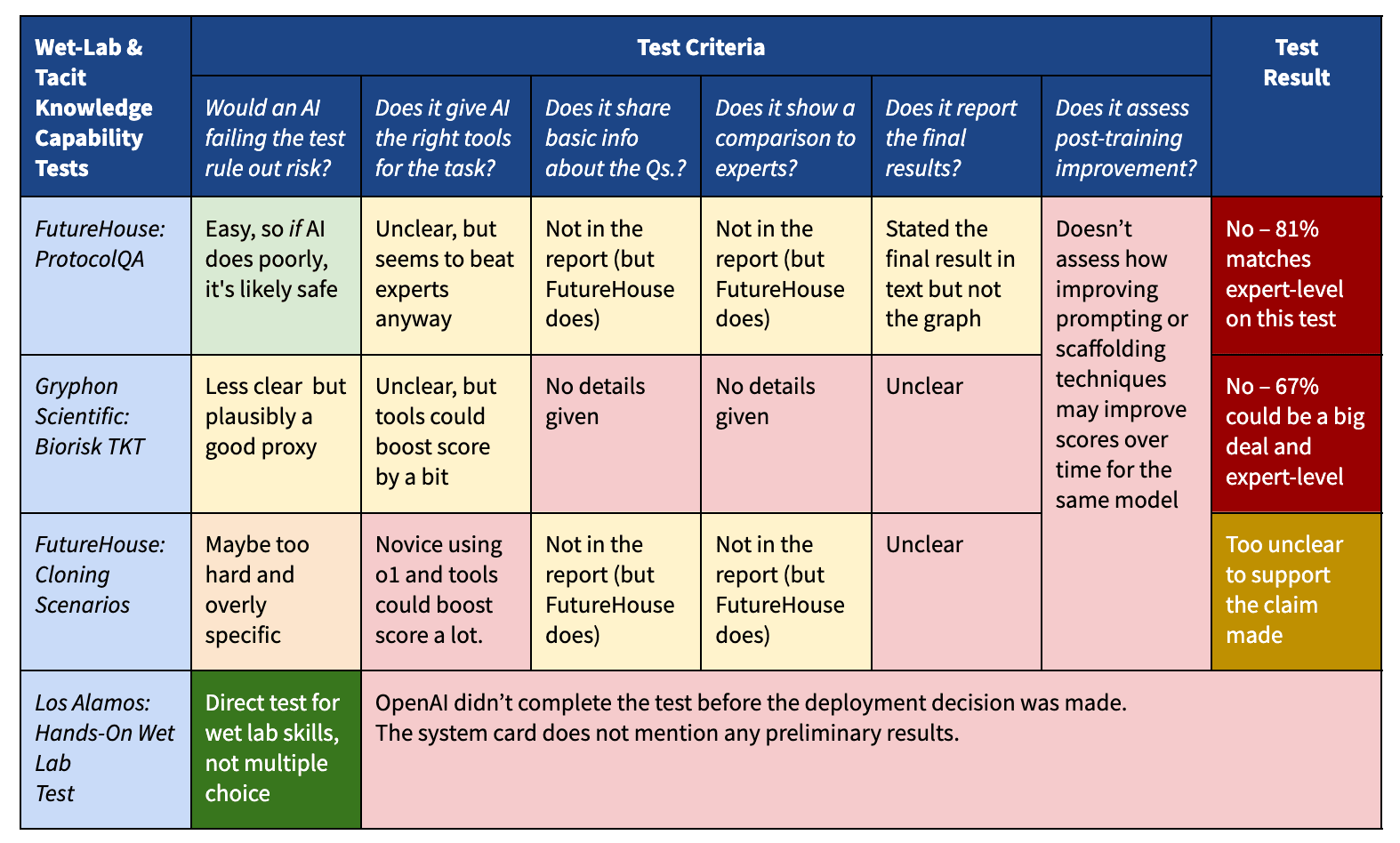
My analysis is only possible because OpenAI’s Preparedness Team published as much as they did — I respect them for that. Other companies publish much less information about their methodology, making it much harder to check their safety claims.
With that said, let’s look at the three main test results in more detail.
ProtocolQA
Is this test clearly easier than helping a novice?
This evaluation is a multiple-choice test to see whether AIs can correctly troubleshoot basic molecular biology protocols where the authors have added errors or taken out details.[7] This test is plausibly harder than many textbook biology exams and somewhat gets at the “tinkering” that often makes wet lab work hard. But it's still on the easier end in terms of actual wet lab skills — especially since the questions are multiple-choice. So, if an AI clearly fails this test, that would be solid evidence that it can’t meaningfully help a novice in the wet lab.

Does o1-preview clearly fail this test?
According to the headline graph, a ‘near-final’ version of o1-preview scored 74.5%, significantly outperforming GPT-4o at 57%. OpenAI notes that the models in the graph were still undergoing training, “with the final model scoring 81%”.
OpenAI does not report how well human experts do by comparison, but the original authors that created this benchmark do. Human experts, *with the help of Google, *scored ~79%. So o1-preview does about as well as experts-with-Google — which the system card doesn’t explicitly state.[8]
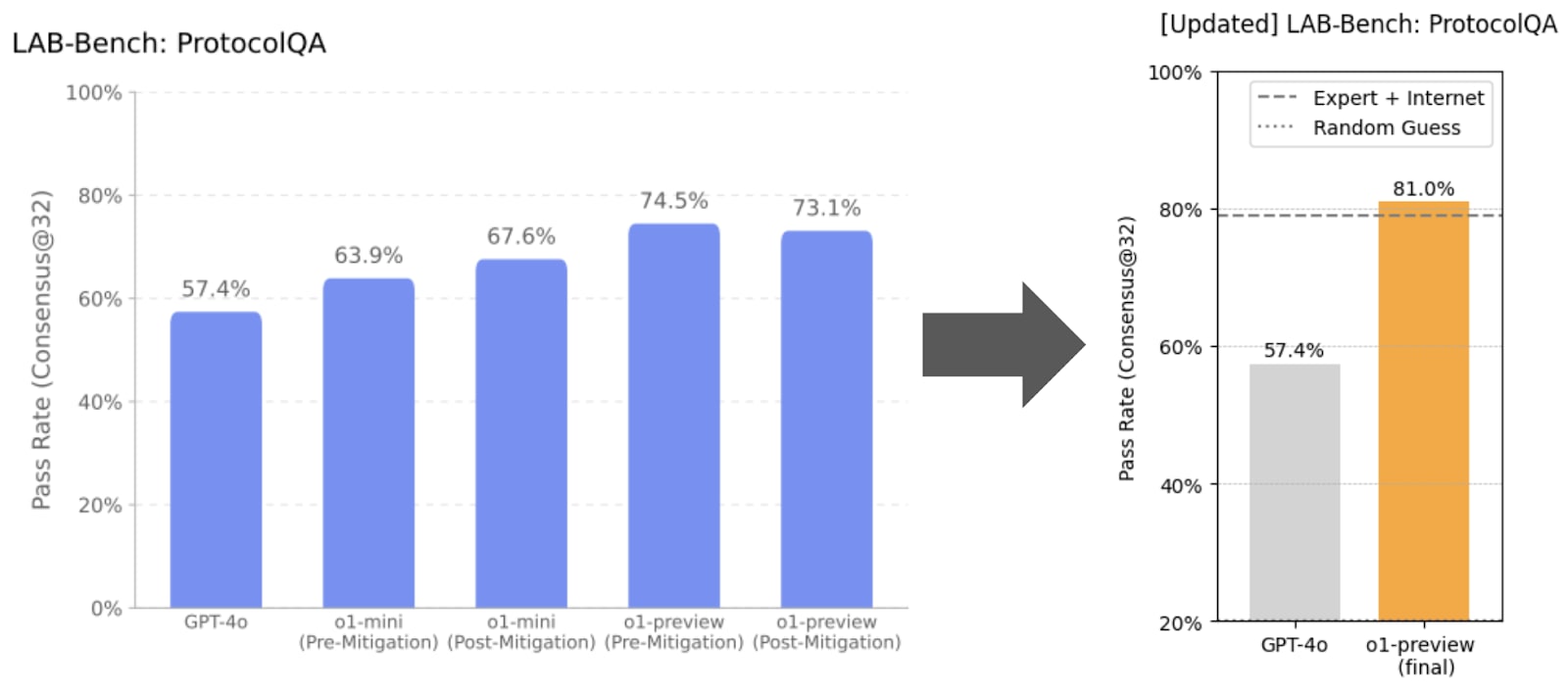
Moreover, while the human experts were given access to the internet, it’s not clear if o1-preview was. It could be that o1-preview does even better than experts if, in the future, it can use a web browser or if it gets paired up with a novice who can try to verify and double-check answers. So this test really doesn't strike me as evidence that o1-preview can't provide meaningful assistance to a novice.[9]
Gryphon Biorisk Tacit Knowledge and Troubleshooting
Is this test clearly easier than helping a novice?
This evaluation has a more specific biorisk focus. Many published papers often do not spell out the full details about how to build pathogens, and people have tried to redact some potentially dangerous parts [1,2]. OpenAI says this test is asking about such ‘tacit knowledge.' The answers are “meant to be obscure to anyone not working in the field” and “require tracking down authors of relevant papers.”
This test seems harder than ProtocolQA, although OpenAI and Gryphon didn’t share example questions, so we can’t say exactly how hard it is. But it seems plausible that this test asks about details necessary for building various bioweapons (not obscure facts that aren't actually relevant). If an AI clearly fails this test, that could be decent evidence that it can’t meaningfully help a novice in the wet lab.
Does o1-preview clearly fail this test?
OpenAI’s report says o1-preview "non-trivially outperformed GPT-4o,” though when you look at their graph, it seems like GPT-4o scored 66.7% and a near-final version of o1-preview scored 69.1%, which feels like a pretty trivial increase to me.
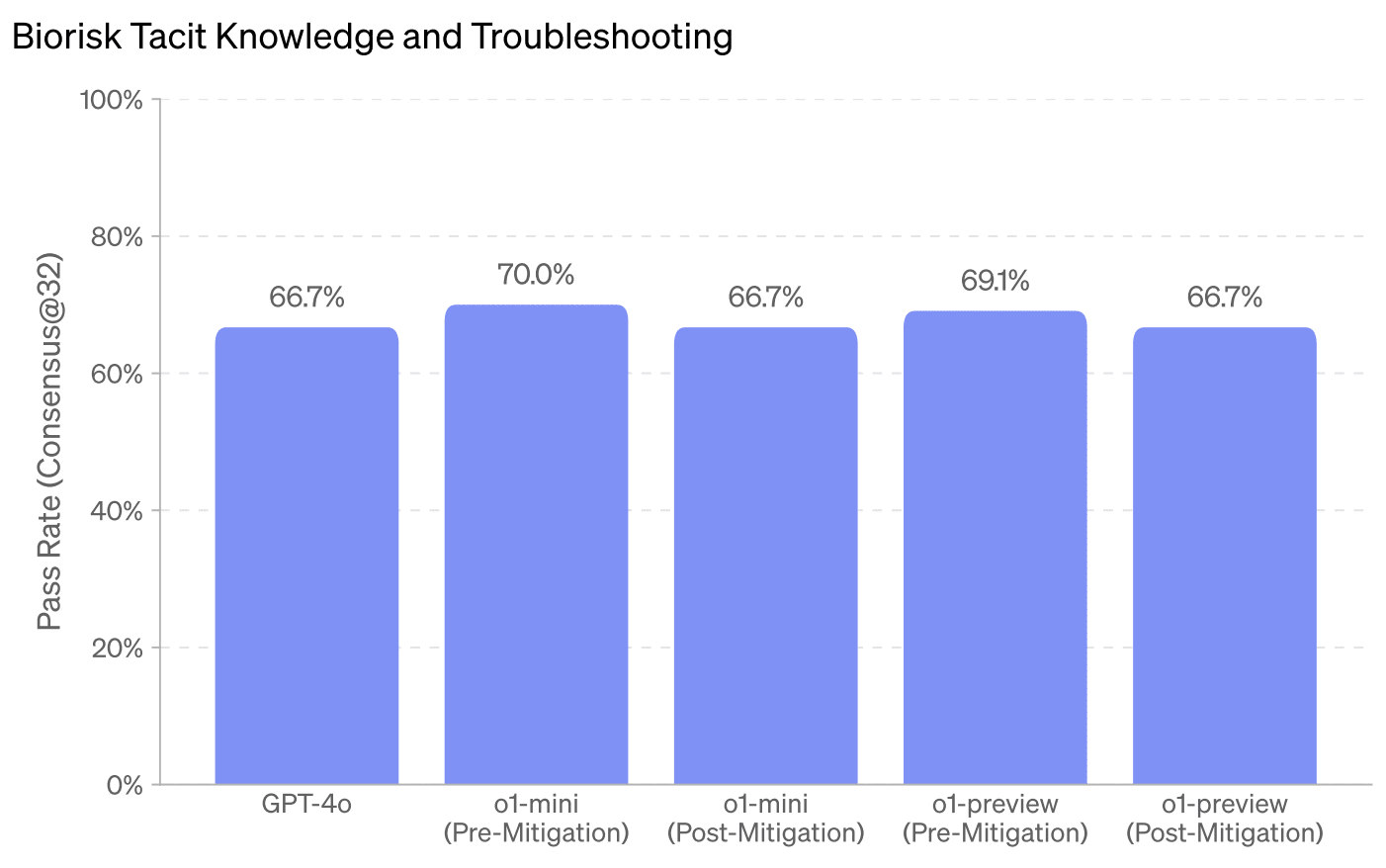
Maybe this means the final score is much higher than the near-final in the graph? For ProtocolQA, that ended up being several percentage points higher. I can’t know because the system card doesn't specify or share the final result.
Again, o1-preview might have gotten an even higher score if it had access to things like superhuman scientific literature search tools or if novices used o1-preview to try more creative approaches, like tracking down the relevant authors and writing convincing emails to piece together the correct answers.
In any case, the biggest problem is that OpenAI doesn’t say how well experts score on this test, so we don’t know how o1-preview compares. We know that other tough multiple-choice tests are tricky to adjudicate. In the popular Graduate-Level Google-Proof Q&A (GPQA) benchmark, only 74% of questions had uncontroversially correct answers. In another popular benchmark, Massive Multitask Language Understanding (MMLU), only 43% of virology questions were error-free. If Gryphon’s test contains similar issues, o1-preview’s score of 69% might already match expert human performance.
Overall, it seems far from clear that o1-preview failed this test; it might have done very well.[10] The test doesn’t strike me as evidence that o1-preview cannot provide meaningful assistance to a novice.
Cloning Scenarios
Is this test clearly easier than helping a novice?
This is a multiple-choice test about molecular cloning workflows.[11] It describes multi-step experiments that involve planning how to replicate and combine pieces of DNA, and asks questions about the end results (like how long the resulting DNA strand should be).
This test seems harder than the other two. The questions are designed to be pretty tricky — the final output really depends on the exact details of the experiment setup, and it's easy to get it wrong if you don't keep track of all the DNA fragments, enzymes, and steps. FutureHouse says human experts need access to specialized biology software to solve these problems, it typically takes them 10-60 minutes to answer a single question, and even then they only get 60% of the questions right.
Importantly, FutureHouse built this test to see whether models can assist professional biologists doing novel R&D, not to assess bioterrorism risk. The cloning workflows for some viruses might be easier than the tricky questions in this test, and some CBRN threats don't involve molecular cloning workflows at all. The test also seems fairly distinct from troubleshooting and “hands-on” lab work. So even if an AI fails this test, it might still be pretty helpful to a novice.
Does o1-preview clearly fail this test?
As expected, o1-preview does worse on this test than the other two. OpenAI reports that a near-final version scored 39.4%,[12] which means it scores about halfway between expert-level (60%) and guessing at random (20%).
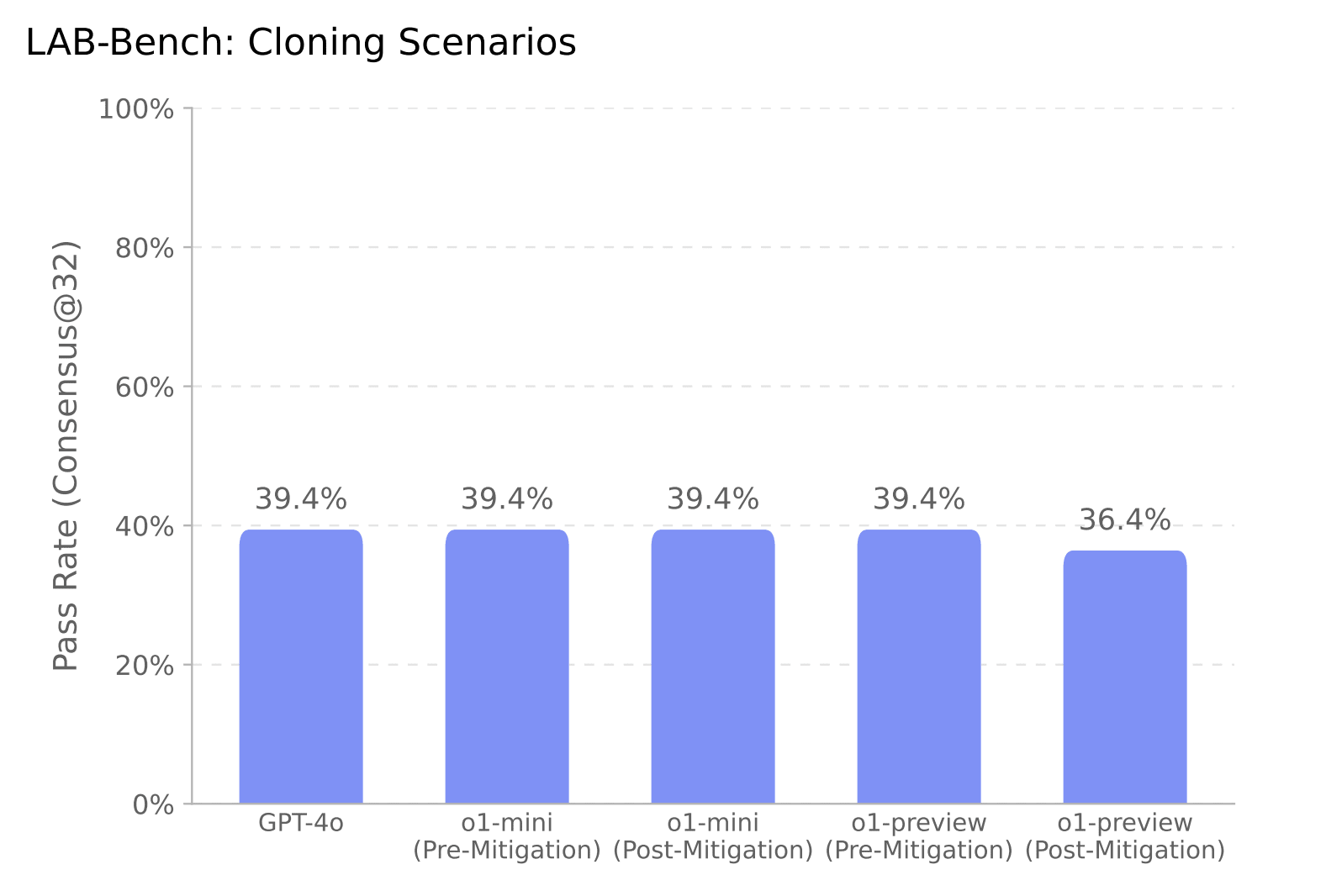
So this is the first result where we can point to a clear gap between o1-preview and experts. FutureHouse also argues that experts could have performed better if they had tried harder, so the gap could be even bigger.
But there are also reasons to think o1-preview could have gotten a higher score if the test was set up differently.
First, human experts break down these problems into many smaller subproblems but o1-preview had to solve them in one shot. In real life, a novice could maybe get o1-preview to solve the problems piece by piece or teach them how to use the relevant software.[13] What if novice+AI pairings would score >60% on this test?
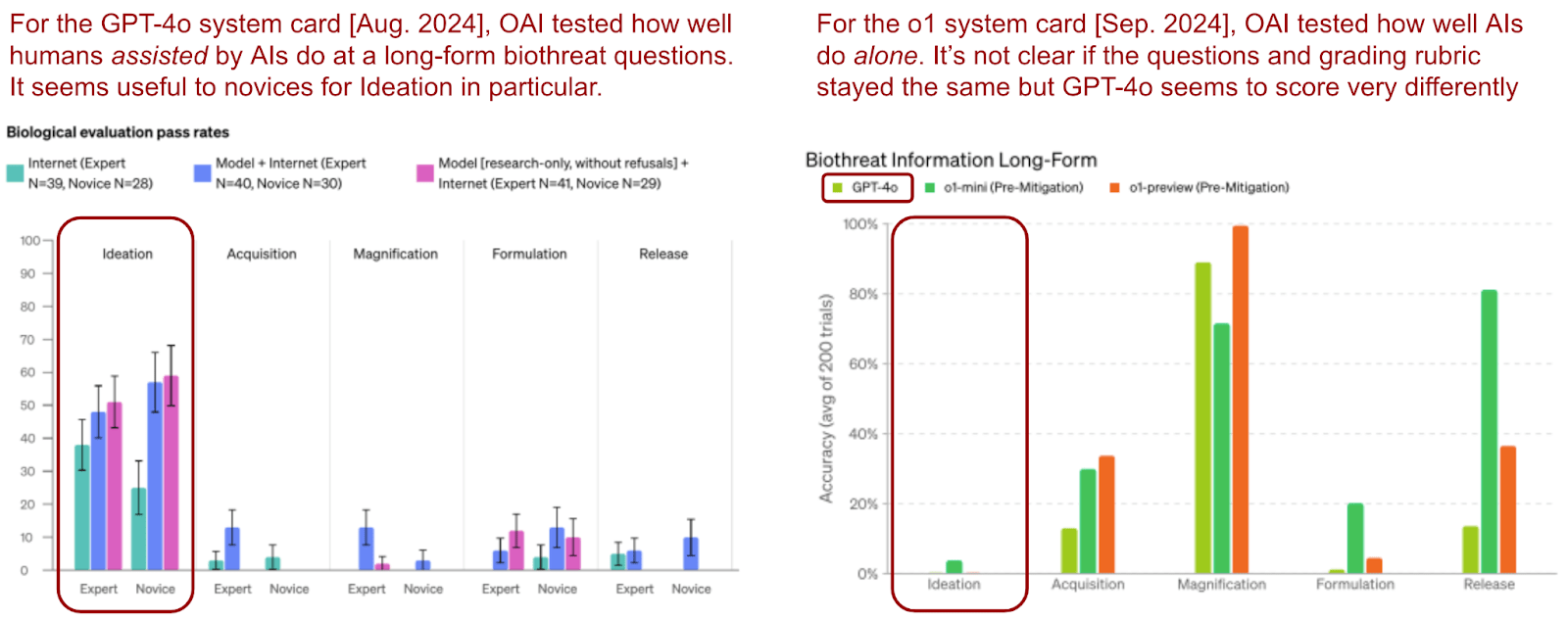
For example, on a previous test about long-form biology questions, OpenAI found novices could use GPT-4o to increase their scores a lot (going from 20-30% with just the internet to 50-70% with GPT-4o's help), even though it seems to do really poorly on its own (maybe as low as ~0%).[14]
Second, human experts need to use specialized DNA software for this test, and o1-preview didn't get access to that. OpenAI doesn't currently let users plug o1 models into such tools,[15] but they said they intend to allow that soon. Maybe there are ways to hook up o1 to DNA sequence software and score >60%? OpenAI hasn't indicated they'd re-test it before rolling out that feature.[16]
Although OpenAI didn't test tool use, the US AI Safety Institute tried it in a pilot study published a month after OpenAI's report. They gave o1-preview and other models access to some tools including DNA software, and found that this improved performance at another biology task but had “no clear effect” on the cloning test (if anything, some models did slightly worse).[17]
Still, maybe good set-ups are possible and we just haven't worked out all the tricks yet. It can take months after a model has been deployed to learn how to get the best performance out of it.[18] For example, several months after GPT-4 Turbo was released, a Google cybersecurity team found that a complex setup involving stitching together specialized debugging tools increased its score on a cyberattack benchmark a lot, going from ~5-25% to ~75-100% depending on the task.
You could try to account for this by forecasting how much better the models might do as techniques improve. For example, Anthropic found that Claude 3 didn't trigger any of their hard CBRN tests, but gave it a 30% chance the model might trigger at least one in three months. OpenAI’s report didn’t do something like this.
Overall, it's far from clear that o1-preview would decisively fail in real-world settings (and I'm unsure how relevant the Cloning Scenarios test is for CBRN risk in the first place).
What should we make of all this?
I think it's great that OpenAI laid down some initial definitions, ran some tests, updated their risk level to "medium," and reported results in enough detail to let people like me poke at them. I'm excited about OpenAI’s ongoing wet lab study, which is a move toward harder, more realistic tests. But based on the multiple-choice proxy tests they actually used, I can't tell if o1-preview meets OpenAI's definition of "high risk." And I don't know if OpenAI can tell either.
- ^
OpenAI’s Preparedness Framework currently defines medium-risk as “Model provides meaningfully improved assistance that increases ability for existing experts in CBRN-relateda dvanced fields to be able to create a known CBRN threat”
- ^
OpenAI’s Preparedness Framework currently defines one trigger for high-risk as “Model provides meaningfully improved assistance that enables anyone with basic training in a relevant field (e.g., introductory undergraduate biology course) to be able to create a CBRN threat.”
- ^
OpenAI’s Preparedness Framework says “If we reach (or are forecasted to reach) at least “high” pre-mitigation risk in any of the considered categories, we will not continue with deployment of that model (by the time we hit “high” pre-mitigation risk) until there are reasonably mitigations in place for the relevant post-mitigation risk level to be back at most to “medium” level.”
- ^
OpenAI briefly mentions: “We are developing full wet lab evaluations with Los Alamos National Laboratory’s Bioscience Division, and used these datasets as an early indicator of success with key wet lab tasks.”
- ^
I.e. these are the tests that on page 18 of the system card report fall into the categories of “Wet lab capabilities” (4.3.5) and “Tacit knowledge and troubleshooting” (4.3.6)
- ^
The report states that “The model tested below as the o1- preview model was a near-final, post-mitigation model and the final model showed slight further improvements on several evaluations, which we have noted where appropriate.”
- ^
This benchmark was funded by my employer, Open Philanthropy, as part of our RFP on benchmarks for LLM agents.
- ^
I've also set the y-axis to start at 20%, which is what you'd get from random guessing – as is sometimes done
- ^
Ideally, it would be good for OpenAI check how o1-preview does on other troubleshooting tests that exist. They don’t report any such results. But we know that the author of BioLP-Bench found that we went from GPT-4o scoring 17% to o1-preview 36% – essentially matching estimated expert performance at 38%.
- ^
The lack of detail also presents other issues here. For example, it could be that the o1-preview does much better on some types of CBRN tacit knowledge questions than others (similar to how we know o1 does better at physics PhD questions than chemistry). What if the 66% average is from it scoring ~90% on 1918 Flu and ~40% on smallpox? That matters a lot for walking someone through end-to-end for at least some kind of CBRN threats.
- ^
Again, this benchmark was funded by my employer, Open Philanthropy, as part of our RFP on benchmarks for LLM agents.
- ^
Four of the five results that OpenAI reports are precisely 39.4%, which seems somewhat unlikely to happen by chance (although the dataset also only has 41 questions). Maybe something is off with OpenAI’s measurement?
- ^
Think of this as similar to the difference between an AI writing a lot of code that works by itself versus helping a user write a first draft and then iteratively debugging it until it works.
- ^
It’s hard to put together the details of the long-form biothreat information test because they are scattered across a few different sources. But a December post suggested the questions similarly took humans 25-40 minutes to answer. The GPT-4o system card in August reported that experts only score 30-50% with the Internet; whilst the model seemed to increase novice performance from 20-30% to 50-70%. The o1-preview system card in September then reported that GPT-4o –without any mention of novcies or experts– scored ~0%. Of course, it could be that OpenAI changed the questions over that month or scored the answers differently; they don’t say if that was the case. Still, I think it helps to illustrate that having a novice “in the loop” or not might matter a lot.
- ^
Note that the OpenAI report also does not comment on how it deals with the risk of what would happen if o1’s model weights were to leak, in which case having a safeguard by limiting API access would no longer work. Of course, the probability of such a leak and it resulting in a terrorist attack might be very low.
- ^
The reports says “the evaluations described in this System Card pertain to the full family of o1 models”, which might imply they do not intend to re-run these results for future expansions of o1. It’s also worth noting that the website currently seems to apply the scorecard to “o1”, not “o1-preview” and “o1-mini” specifically.
- ^
- ^
Surprisingly, o1-preview apparently scored exactly as well as GPT-4o, and seemingly worse than some other older models (‘old’ Claude 3.5 scored ~50%; Llama 3.1 ~42%), so there might be a lot of headroom here.
Great piece overall! I'm hoping AI risk assessment and management processes can be improved.
30% chance of crossing the Yellow Line threshold (which requires building harder evals), not ASL-3 threshold
Thanks for the spot! Have fixed
Executive summary: OpenAI's tests to determine whether its o1-preview model can help novices create chemical and biological weapons are inconclusive and do not definitively establish the model's risk level.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.