This post is an attempt to analyze the feasibility of establishing an international pause on frontier AI development. More specifically, it highlights a few reasons why someone might consider pausing to be a viable component of AI safety strategy.
Summary
- I present six reasons for why pausing frontier AI development globally might be a reasonable strategy.
- 1) We might not have enough time to solve alignment. First, if we consider the problem to be the misalignment of human-level general AI systems, there just might not be another way, because we might not have enough time to solve alignment.
- Timelines could be less than five years. Leaders of labs are talking about timelines of less than five years. AI experts also don’t rule out short timelines, and Metaculus is even more pessimistic.
- Work left to solve alignment could be much longer. Likewise, there seems to be much uncertainty around how much work is there left until we solve alignment. Chris Ola (Anthropic co-founder) thinks the alignment project could require many orders of magnitude more effort than is currently put into the problem.
- 2) The U.S. public supports a pause on AI development. According to several surveys, this seems quite clear.
- 3) Historical case studies show public opposition overtaking large industries. Looking at the public opposing GM foods in Europe, and Germany opposing nuclear energy during the past two decades we see:
- the importance of trigger events in both of those instances, and note that support for a pause could quickly increase due to a future AI-related well-publicized trigger event
- that although industry sizes of past case studies look comparable under some perspectives, the potential of AI is still likely unprecedented
- 4) I look at several proposals for a global pause and mention that different variations could seem more promising, including conditional pausing, pausing everywhere except for narrow use by governments, or except by a well-coordinated secure international facility (‘CERN for AI’).
- 5) I look at current Chinese discourse on AI safety and show that they are aware of short-term concerns and might even be ahead of the US in regulating AI. Longer-term or more catastrophic concerns remain less clear.
- 6) Finally, I will go over a few reasons why complete global coordination for pausing may not be immediately necessary.
- I end by presenting a few options for action and a motivating statement.
Epistemic status: I am not an expert in this matter. My background is in computer science and effective altruist community building with some AI policy experience (my LinkedIn for the curious). I spent roughly 80 hours over a month researching for this article, reading forum posts, research articles and news stories. I also talked to several experts (see Acknowledgements section).
The overall motivation behind this article comes from having noticed that some people dismiss the option of pausing AI development very quickly, as it appears unrealistic or too ambitious. This will hopefully break that barrier and provide a few rays of optimism. I want to shed light on the issue and make the discussion a bit more nuanced than ‘pausing won’t work’.
1. We are running out of time to solve alignment
One question to ask when approaching this topic is whether it is harder or easier than the other available options
That is, it is not necessary to know all the details about each option if you can compare them to each other and pick the best choice available. If you need to hurl a rock and you can choose between a cannon and a hand, you don’t need to calculate the force output of each.
Likewise with pausing. But let’s first define what it is that we are solving.
For the purposes of this article, let’s consider the problem to be the misalignment of human-level general-purpose AI. It is worth noting, however, that other sources of (x-)risk do exist and not all experts agree that misalignment is the largest source of AI-related x-risk. Additional sources of risk include losing control of autonomous weapons systems, deliberate misuse of powerful AI to destabilize society, accidents in powerful AI systems (such as those controlling nuclear weapons), and a race towards AGI triggering a global war (though, arguably, pausing would also significantly decrease these risks as well).
To keep this article focused, let’s just consider what we can do about misalignment.
It appears we can either solve alignment with the time we have, or we can get more time.
How much time do we have?
Not much, it seems.
As a reminder, the top labs and tech companies are talking about 2–5 year timelines. Sam Altman, from OpenAI, says AGI might arrive in four or five years, Dario Amodei (Anthropic) is talking about the next year or two (“50-50 odds”), and Jensen Huang (NVIDIA) says he expects AIs to be be “fairly competitive” with humans within the next five years. Of course, possible biases exist, including a desire to hype up the technology (being heads of large companies and all). So let’s look at other predictions.
Top AI researchers (who generally have slightly longer timelines) also say that there is a 10% chance of high-level machine intelligence (HLMI) arriving in the next three years. This is based on a survey done last year of over 2,700 top researchers. Other similar surveys have longer timelines, but they have also been conducted earlier, and timelines have updated since then (see more details here).
As an additional datapoint, Metaculus (an aggregate prediction site) gives a median prediction for devising, testing and announcing AGI to be in 2032.
Overall, while there are still uncertainties, it seems entirely within the realm of possibility that we will see AGI coming in the next decade, possibly much earlier.[2]
This seems quite significant.
How much work is left?
How much needs to be done still before we are ready for human-level models?
On this question, there seems to be lots of uncertainty, and I think exactly that should make us more concerned. The fact that we don’t know, means all options are more plausible.
I like Chris Ola’s (Anthropic co-founder) take on this question. He frames the difficulty of alignment as a distribution over possible ‘scales of difficulty’ from ‘trivial’ to ‘impossible’. His view (and Anthropic’s view in extension) is that of a large probability spread between options, with a bump between ‘steam engine’ and ‘the Apollo mission’ levels of difficulty (See Figure 1 for reference). Note that he says currently we have enough safety work to reach the ‘steam engine’ level of difficulty (Figure 2). Lots more work ahead.
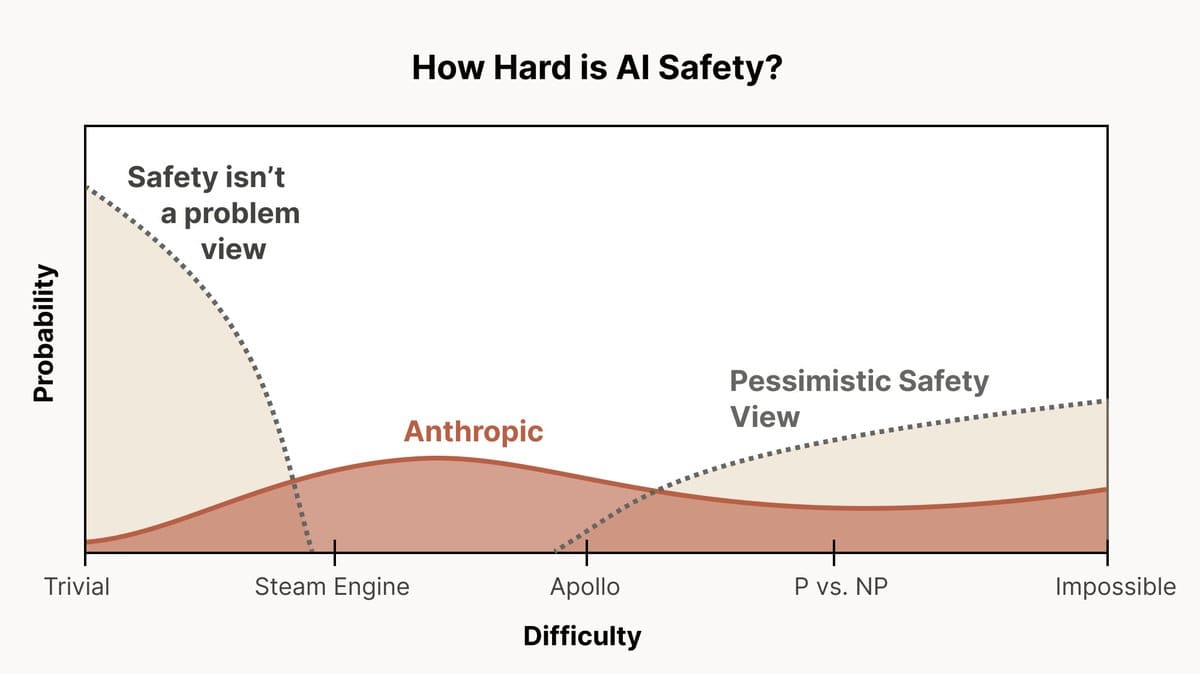
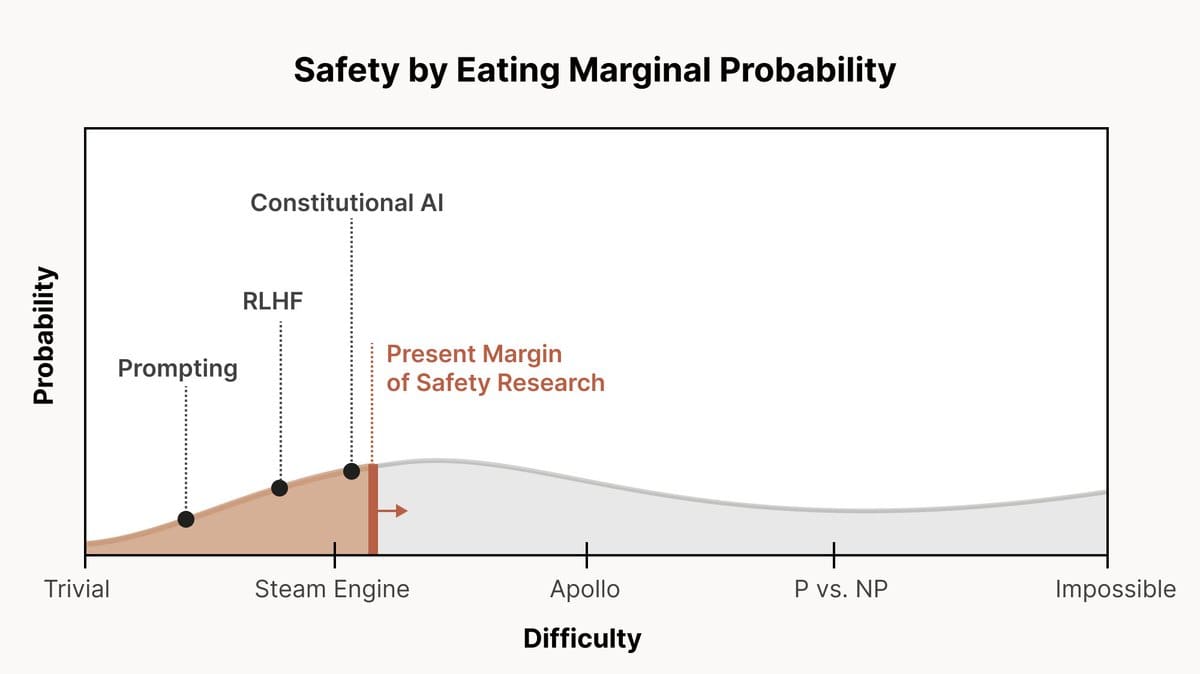
He also remarks that the worlds in which alignment is impossible and the ones in which it is easy may look very similar. So you wouldn’t know you were living in the ‘impossible’ world unless you looked really hard (which we aren’t doing). So we might be living in it.
I also like this post expanding on Chris’ tweets, outlining ten stages of alignment in more detail. The most difficult scenarios include a ‘sharp left turn’, where models suddenly become much more strategically aware and capable of evading detection.
I think it is worth looking at the different stages of difficulty and consider for yourself whether the more difficult ones seem outlandish to you. And to remind yourself again that uncertainty is reason for hesitancy, not eagerness to push forward.
What risk can we tolerate?
I don’t think much.
One can talk about needing to safeguard the entire potential of human development across the Universe, but if that sounds outlandish, it’s not necessary to go that far. Even ‘just’ saying we want to preserve what we have right now and all the generations that could exist on Earth – that’s still a lot of value to be preserved.
Similarly, you might be motivated by the potential of aligned AI providing value across the entire spectrum of cosmos. But even without considering space expansion, there are surely many aspects in which correct implementation of aligned machine intelligence could provide substantial prosperity and wellness.[3]
So what scales of risk might we consider, keeping these stakes in mind?
Hard to say, but as a comparison, the death risk per boarding a plane is 1 in 13.7 million and the chance of dying of a shark attack is 1 in 4.3 million. We have some intuitions on how likely we are to die doing these activities. And whether they seem appropriate or not.
But we are talking about something on the scale of humanity. And the overall chances of risk seem much greater than one in a few million.
If we consider the probability of AGI arriving in the next 5 years as 10% and the probability of alignment not being ready by then as 90%, we get a 9% chance of misaligned AGI. Then there’s the question of survival, given deployed misaligned AGI. Any number we put on that is likely to be far off from the sizes of risks we might be comfortable with.
Of course, this is all napkin math, and you’d want to run the numbers yourself. But we are talking about orders of magnitude here after all. And so far, it doesn’t look so good.
Overall, it seems entirely plausible that (a) we don’t have long until AGI, (b) we can’t solve alignment in time, and (c) without intervention, the world will explode because AGI doesn’t care about our needs and does it’s own thing.
One way out of this predicament could be pausing development, so that we have more time for alignment research. Here are a handful of reasons to be optimistic about the prospects of such an intervention.
2. The U.S. public supports a pause
It might come as a surprise, but more than 50% of Americans support a pause on AI development. Rethink Priorities found 51% support for ‘pausing the development of large-scale AI systems’. YouGov got 58–61% support for a six-month pause, Sentience Institute got 61.1%.
Other impressive metrics include 72.4% of US adults agreeing that ‘AI is one of the most important issues in the world today’, 71.3% supporting public campaigns to slow down AI development, and 71.0% supporting government regulation that slows down AI development.
Though, in other surveys, risks of AI don’t seem to be the number one concern on people’s minds. When YouGov asked how concerned people were about problems that could end humanity, they were more concerned with nuclear weapons (66%), world war (65%), climate change (52%) and pandemics (52%) than AI (46%). Similarly in the Rethink Priorities’ poll, only 4% chose it as the most likely cause of human extinction.
Likewise, even if the majority of U.S. citizens agree that slowing down AI is necessary, this doesn’t necessarily show their willingness to take action. As Harrison brought out, there could be a separate axis for the ‘depth’ of support for a cause. This is yet uncharted.
Still, I don’t think this is reason for concern. Even as people might not realize it, the risk of misaligned AI increases many of the other cause areas people are concerned about. A heated race towards AGI could increase risks of world war and use of nuclear weapons. Likewise, the mere fact that people don’t hold AI as their top concern, does not mean that they don’t care about it. As Harrison brought out again, only 0.5% of people hold Medicare or social security as their number one concern, but it is clearly still important for them.
Overall, the public support for slowing down AI development in the U.S. looks strong. (For China, it’s less clear).
3. We’ve done it before (kinda..)
Trigger events
To add to the existing public support, we should consider the potential of ‘trigger events’, which have been shown to launch relatively quiet opposition into strong protest movements.
‘Trigger events’ are defined by Moyer (1987) ‘highly publicized, shocking incidents that dramatically reveal a critical social problem to the public in a vivid way’. In the history of successful movements, trigger events often highlight key times in the movement’s cycle, with significantly increased public support and action following the event.
For instance, in the 90s, opposition to genetically modified (GM) foods increased in nearly every EU country, which coincided with several trigger events, like the Mad Cow Disease infecting humans, asbestos problems at a major French university, and finding dioxin in Belgian chicken feed. These events further undermined trust in governments, and made the public feel that biological risks are poorly managed. (Grotto, 2019)
Possible trigger events for AI safety could range from relatively minor incidents to more severe and catastrophic occurrences. Milder incidents could include small-scale accidents involving autonomous systems, such as unintended harm caused by autonomous weapons or misdiagnoses from AI in healthcare. More serious and destructive events could involve the first instances of rogue AI systems causing significant harm to humans or damaging vital infrastructure, like an AI autonomously coordinating a large-scale cyber attack on critical human infrastructure, or a proven case where an AI engages in a deliberate and consequential deception in the wild.
Note here that these ‘trigger events’ do not have to pose immediate personal harm. Indeed, in the GM example, they weren’t even directly connected to the technology at hand. They were merely events that served as memorable symbolic events that highlighted the problem at hand.
As another example of the power of well-publicized trigger events, the 2011 Fukushima nuclear accident caused significant changes in attitudes within many countries, most notably Germany, where it resulted in a total phasing-out of nuclear power by 2023. Arlt and Wolling analyzed German media coverage and public opinion before and after the incident and found a clear and significant shift in opinion. Public opposition to nuclear energy grew from 31% to 73% just a year later.
I really like this example, because arguably, dismantling their nuclear power plants (which produced 20% of Germany’s energy) caused significant economic and geopolitical costs to the country. Estimates are between €18–250 billion in costs, not even mentioning the increased reliance on Russia’s energy, which at the very least put Germany in a tricky place following the Russian invasion of Ukraine. Yet it was done, and the cause for that can be at least partially linked to an existing public opposition fueled by a highly publicized ‘trigger event’.
Of course, not all incidents get blown up in the media and gain people’s attention. Arguably, there are trigger events surrounding AI safety that happen constantly, such as Claude 3 lying about its capabilities in model environments or ChatGPT passing the actual Turing test, but they don’t get broadly picked up by the media.
Yet it is exactly here that there is an opportunity for activists. It’s possible that the difference between trigger events causing a riot and falling flat, is often just due to someone taking the time to spread knowledge of it. Of course some forms of framing and some types of triggers work better than others. And there is the inevitable unpredictability of media algorithms and journalists’ choices. Yet it is clear that this can be influenced.
Comparing industry sizes
One the one hand, one could argue that industry sizes compared to case studies are almost comparable. The global AI market size is estimated at 196 billion USD in 2023, and OpenAI is currently valued at 80 billion USD. The value generated from nuclear power plants in Germany in 2011 was approximately 21 billion USD[4], Siemens, the nuclear power plant conglomerate was worth roughly 100 billion. The largest firm dominating the GM seed market in the 90s had a market capitalisation of around 47 billion USD. Looking at it this way, the industry sizes are in similar orders of magnitude.
Likewise, looking at other unpursued technologies, like geoengineering, or human challenge trials, the incentives to pursue them can be estimated to be in the tens of trillions of dollars.
But comparing apples to oranges is tricky. Economists Tramell and Korniek say AI could bring a permanent increase in economic growth rates or make them everincreasing. Robin Hanson in his book The Age of Em estimates an economic doubling time of one month, given digital humans.[5] Comparisons are made to the harnessing of electricity, or the industrial revolution. In these cases, it becomes significantly harder to find historical precedents of protest movements or political action changing the course.
An additional reason for pessimism is the obvious fact that the AI industry is growing, as is the AI lobby. Time reports that the number of AI lobby groups in the US tripled from 2022 to 2023 (going from 158 to 451), and OpenAI is talking about future business deals reaching trillions of dollars.
Though this makes things trickier, this doesn’t mean we can’t still significantly reduce the risks we face. Proposals for pausing include many variations, which are aligned with many of the goals of existing actors, and allow the technology to continue in a safer direction.
Let’s look at a few proposals for pausing.
4. There are many ways to pause
Considering the question of ‘how to actually do it’, there is a lot of room to open up discussion and consider several possibilities.
A standard pause proposal (outlined by PauseAI here) involves setting a compute threshold and not allowing any model training runs above that limit until no dangerous capabilities are present or the safety of models can otherwise be verified.
Compute threshold tracking can be done with (e.g.) on-chip firmware and other compute tracking governance mechanisms, which are made easier by the (current) compute chokepoint.
{kind=link}
This seems like a good starting point. But even if you think this approach is unreasonable, there may be more suitable variations.
Overall, this project of pausing is made easier if we disentangle the question and realize that:
- It’s just a narrow slice of AI technology that we want to pause – that of general artificial intelligence – is under consideration. The large majority of the AI industry, including all narrow AI tools and also more limited general models, can remain. We can reap enormous benefits just from them, and leave most of the industry intact. Pausing is just about agentic goal-oriented general-purpose models.
- It’s just the race dynamics we want to end. One could say that the whole problem of pausing can be reduced to race dynamics between countries, companies, and the open source community biting at their heels. Most of us want to build safe AGI. But we can’t do so if actors are incentivized to skip over safety concerns to win the race, even if they want to be safer themselves. It’s a Molochian kind of situation, which can be stopped with top-down regulation.
- We can have conditional pauses. If governments are uncertain whether AGI will prove to be a source of significant harm – good, let’s set up clear conditions under which we are ready to launch a (fully prepared) global moratorium. This might bridge the gap between techno-optimists and skeptics.
- We can have partial pauses. Not everybody needs to stop developing AGI. Perhaps only universities can develop it, or governments, or a single international institution.
Taking the above into account, here are three proposals that could be realistic and safer than the status quo.
A) A ‘CERN for AI’
We could build a ‘CERN for AI’. An international institution solely licensed to conduct large-scale experiments on AI exceeding the moratorium threshold. This was outlined for example by Hausenloy, Miotti and Dennis in their MAGIC proposal (standing for Multinational AGI Consortium).
There are several benefits of this approach. Most obviously, being a singular international non-profit institution, this would dismantle existing race dynamics, while still moving towards a safe AGI. Second, this would be overall good for AI safety research, as the actors involved are able to experiment on actual frontier models.
Arguably, this would also help with the hardware overhang counterargument, which states that pausing is bad, because after it ends, there would be an ‘overhang’ of hardware developments, which leads to a jump in AI capabilities. Under the ‘CERN for AI’ scenario, frontier AI would continue to be developed and there would be no ‘unpausing’ event to trigger a capabilities jump.
B). Conditional pausing on evals
We could also imagine conditional pausing based on model evaluations showing dangerous capabilities. This is based on a recent proposal by Alaga and Shuett.
You might find this reasonable if you trust that these evaluations are accurate, that they are comprehensive enough to cover all realistic dangerous capabilities, and that the companies will actually comply with their commitments, all of which could be put into question. There are also concerns raised around the possibilities of fine-tuning and jailbreaking models even after they have been approved by the evaluation suites.
C) Banning ‘civilian AI’
Likewise, this paper by Trager, Harack, Reuel and others details in-depth a proposal that tackles what they call civilian AI governance, which they define as all AI except that of state-authorized use for military or intelligence applications. They say such an approach is more digestible to national governments, as by significantly restricting civilian use of AI, they still retain significant benefits of the technology (while keeping it safer).
Whether this is sufficient to prevent world destruction remains unclear. However, this seems like a step in the right direction.
About compute thresholds
Most options involve making use of the hardware chokepoint that currently exists in the AI landscape. Only a few actors, all in Western countries, are responsible for the production of most hardware chips currently used in advanced AI systems. Likewise, it might be difficult to enforce anything more complex in international law than robust metrics, like ‘compute’.
As mentioned, for monitoring, chips can have embedded firmware, which enables them to track model weights. Likewise, the chip supply chain can be monitored, allowing direct access into which actors are using chips in large quantities required for building frontier models (see more: Chinchilla paper).
Setting a compute threshold (e.g. number of FLOPs for building GPT-4), updating the threshold as algorithmic capabilities increase, and disallowing model training of systems powerful than that, would (at least initially) be an easy rule to set and enforce.
The strongest concern I have heard to this approach is the fact that as model algorithms improve, at some point it is possible to train and build human-level intelligence on anyone’s home laptop, which makes hardware monitoring and restricting trickier. While this is cause for concern, I don’t think this should distract us from pursuing a pause.
Because firstly, as Ben Pace brought out, the fact that a solution doesn’t work for all cases forever is not a sufficient reason not to pursue it in a strategic sense. Israel disrupts the Iranian nuclear program any way they can even though they don’t know if they’ll ultimately be successful, because anything helps and we don’t know what the future holds.
Secondly, the process of safe AI development might give us incredibly powerful narrow AIs (or even aligned AGI) well before that, which we can then use to broker new international agreements, or amend old ones. In any case, it is a future full of many unknowns, and thus possibilities.
5. China is aware of safety concerns
Although there is less information and analysis done on the sentiment of various Chinese actors regarding AI pause, there is still sufficient information to put together a rough picture. Here is what I have gathered about governments, companies and researchers.
Government
Overall, they are working on AI regulation and talking about international cooperation.
Their recent regulatory proposal seems almost comparable to the ‘state-of-the-art’ EU AI Act, describing a ‘high-risk’ for certain models, including foundation models. Though their requirements could arguably be more restrictive, as ‘licensing’ and ‘social responsibility reports’ might not be enough to stop rogue AI.
Public statements indicate that China does wish to increase cooperation. In the 2023 meeting with Joe Biden, Xi Jinping stated: “China and the United States have two choices: one is to strengthen unity and cooperation, [..] the other is to hold a zero-sum mentality [..] The two choices represent two directions and will determine the future of mankind [..]”.
The Chinese delegate Wu Zhohui at the 2023 AI Safety Summit expressed similar need for international coordination, saying “only with joint efforts of the international commuity can we ensure AI technology's safe and reliable development”.
Therefore, though I did not uncover direct statements about Chinese willingness to establish a global pause, there is at least interest for international coordination, and an awareness of risks.
Companies
Lab governance measures in Chinese tech firms have been rated as ‘fairly general’, and focused on truthfulness and toxic content rather than dangerous capabilities.
Seeing this together with state governance, it again shows an awareness of risks, but an avoidance of acknowledging large-scale catastrophe scenarios.
Researchers
Regarding the opinion of academics in China, there was a survey done in 2023 asking 566 researchers (including 247 AI researchers) about their opinions on AI regulation. Only 27.39% of respondents expressed their support for ‘a pause for at least 6 months’.
Those disagreeing explained their reasoning by saying they either (1) want the benefits of large AI models, (2) think pausing is not realistic, (3) think a 6 month pause would not bring about any substantial change, or (4) think the influence of LLMs is overstated.
Although most respondents disagreed with pausing, looking at their reasoning, they could become amenable to other policy suggestions. The ‘CERN for AI’ option mentioned earlier might still be called ‘unrealistic’ but it definitely helps with reaping the benefits of AI. Likewise, those claiming the risks are overhyped might be persuaded with additional information or future capabilities advances.
On the positive side, over 90% of respondents supported an ‘ethics, safety and governance framework’ being mandatory for large AI models.
Likewise, there are already proponents of an AI pause in the Chinese research community. Yi Zeng, a prominent AI researcher has publicly signed the FLI pause letter and talked to the UN Security Council about existential risks from AI models.
Public opinion
We have little information about the public opinion of the Chinese nation on these issues, but considering the top-down nature of Chinese rule, it might be less relevant.
Overall
It seems Chinese government officials and researchers are aware of and taking action to reduce risks from AI. It’s just that they don’t think those risks are on the scale of existential catastrophes. Fair enough.
Looking at this, it still seems possible that with additional trigger events, or even just additional information about existing threats, opinions could shift and a pause deal could become more likely.
6. We can convince others later
Other concerns regarding the development of a pause include thinking even further ahead into the world in which both the US and China have agreed on a pause, but a few smaller countries defect and disagree to take part. What then?
Firstly, if we even get to that stage, that seems like a massive win for humanity. Currently, as other countries are well behind the US and China, it will take many good years for them to catch up. Especially due to the West controlling the hardware supply chains, this may give us enough time to carefully develop safe artificial intelligence.
Secondly, getting the world’s major powers on the same page opens up a plethora of opportunities for both negative incentives (from trade embargoes to the threat of nuclear war), to positive incentives (e.g. a seat at the table to develop frontier AI and establish governance regimes).
Thirdly, again as Ben Pace brought out: just because a plan doesn’t work for all cases forever doesn’t mean it’s a bad plan. On the international stage, plans with a positive impact are often imperfect and iterative.
These are the important aspects of the pausing landscape as I currently see it. My view is that although a pause is an ambitious and in some respects unprecedented international project, there are still realistic opportunities to make it happen, and support for a pause could increase rapidly as dangerous capabilities become more obvious.
If you agree with the idea of pursuing a pause, at this point you might be wondering what you can do about it. That’s what I’ll touch on next.
What can you do?
One option is to use existing political systems through think tanks and governance institutions to push for stricter restrictions, slow down development, and widen the Overton window. This could be called an inside-approach.
Another option is to go on the outside. This can involve playing the role of concerned members of the public, being activists, bringing together civil society representatives, and showing policymakers that people desire to take stronger action.
Of course there are nuances and other options here. One could also bring together scientists, engineers, and experts in relevant fields to create diplomatic solutions (Track II diplomacy). This strategy could also be approached either from the “inside” or “outside”.
Additionally, one can either play the role of Door In The Face negotiator, explicitly calling for a global pause, hoping this will push the Overton window in the right direction, or one can move more incrementally, hoping a pause is on the table before time runs out.
What strategy or mix of strategies you choose depends on your skills, experience, and network.
Most people could likely join the ‘outside’ approach fairly quickly. This can include gathering support for protests, public statements, noticing and letting people know of recent ‘trigger events’, learning about the nuances of framing and media narratives, and making ‘memes’ viral. For all of this, a good place to start can be the PauseAI Discord group. They also have a longer list of actions you can take.
Studies analyzing the effect size of protests and writing to representatives shows promising results. Two studies show that writing to staffers increases their chance of voting a particular way 12% or 20% percent. Likewise, a survey of staffers indicated that the number of personalized messages required can be less than 50. For a detailed analysis of protest movement effectiveness, I can recommend Özden and Glover’s report (“Protests movements: How effective are they?”).
Overall, I won’t do a detailed analysis here on the best exact strategies, but being in the effective altruism community, there are many resources and opportunities to figure that out.
Conclusion
As a final message of optimism, I would like to share a perspective by Katja Grace. The EA community has met momentous challenges with unparalleled optimism and a strong willingness in the past. We feel that this community has attributes which set us apart and make us able to do what others cannot. No matter how difficult the alignment problem seems, smart people have been more than willing to try to solve it, because it’s the right thing to do.
Likewise, it might be strategically correct to just assume we are living in a world that can be saved and in which you can make a difference. Because there does exist a world like that. And you might be living in it.
And what’s the alternative? That nothing will work and none of it will matter anyway? Why not try and find out.
Acknowledgements
Thanks to Ben Harack, Chris Gerrby, Felix De Simone, Mathias Kirk Bonde, and Nathan Metzger for comments and advice.
- ^
For a longer analysis of different predictions, see this recent work by Convergence Analysis (Timelines to Transformative AI: an investigation, 2024).
- ^
For a more in-depth exploration of the possible benefits of AI, you may look at books like “Life 3.0”.
- ^
Estimated by mutiplying the electricity price (12 cents per kWh) with the amount of nuclear energy generated (133 TWh) and converting that into USD with the 2010 conversion rate.
- ^
Chapter 16. Growth.
There are many ways to slow AI development, but I'm concerned that it's misleading to label any of them as pauses. I doubt that the best policies will be able to delay superhuman AI by more than a couple of years.
A strictly enforced compute threshold seems like it would slow AI development by something like 2x or 4x. AI capability progress would continue via distributed training, and by increasing implementation efficiency.
Slowing AI development is likely good if the rules can be enforced well enough. My biggest concern is that laws will be carelessly written, with a result that most responsible AI labs obey their spirit, but that the least responsible lab will find loopholes to exploit.
That means proposals should focus carefully on trying to imagine ways that AI labs could evade compliance with the regulations.
Right. I was also concerned some of the proposals here might be misleading to be named 'pauses'. Proposals to 'significantly slow down development' might be more accurate in that case.
Maybe that's a better way to approach talking about pausing. See it more as a spectrum of stronger and weaker slowdown mechanisms?
(Comments from skimming the piece and general thoughts from the current state of AI legislation)
->If there is agreement, there should be a pause, building international trust for a pause is crucial- Current verification mechanisms are rather weak.
-> Current policy discourse rarely includes X-risks (coming from legislative drafts, frameworks, and National strategies countries are releasing). A very small minority of people in the broader CSO space seem concerned about X-risks. The recent UN AI Advisory Body report on AI also doesn't really hone in on x-risks.
-> There might be strange observer effects wherein proposing the idea of a pause makes that party look weak and makes the tech seem even more important.
-> Personally, I am not sure if there is a well-defined end-point to the alignment problem. Any argument for a pause should come with what the "resume" conditions are going to be. In the current paradigm, there seems to be no good definition of acceptable/aligned behavior accepted across stakeholders.
Now,
-> Pausing is a really bad look for people in office. Without much precedent, they would be treading straight into the path of innovation while also angering the tech lobby. They need a good reason to show their constituents why they want to take a really extreme step, such as pausing progress/innovation in a hot area(this is why trigger events are a thing). This sets bad precedents and spooks other sectors as well(especially in the US where this is going to be painted as a Big Government move). Remember, policymakers have a much broader portfolio than just AI, and they do not necessarily think this is the most pressing problem.
-> Pausing hurts countries that stand to gain(or think that they do) the most from it (this tends to be Global South, AI For Good/SDGs folk).
-> Any arguments for pause will also have to consider the opportunity cost of delaying more capable AI.
-> Personally, I don't update much on the US public being surveyed because of potential framing biases, little downside cost of agreeing, etc. I also don't think the broader public understands the alignment problem well.