I was looking at figures like this one:
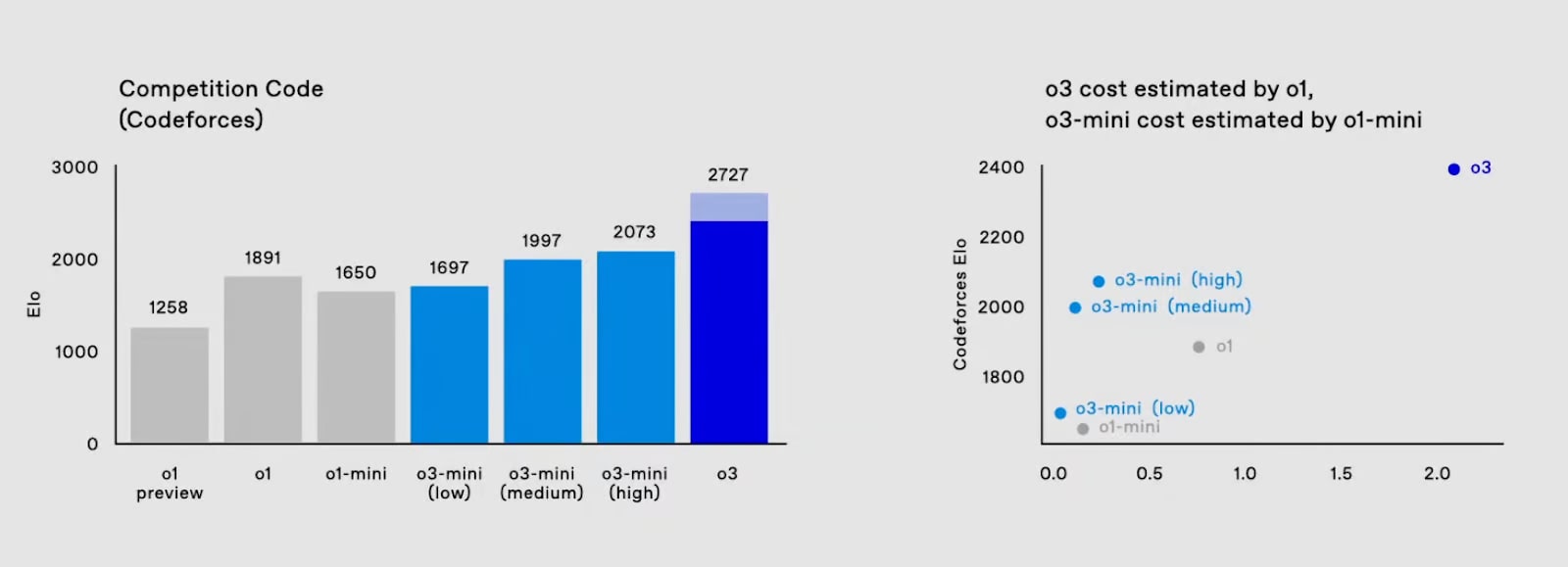
Looking at the graph to the right, it can seem like the main difference between o3-mini and full o3 is the amount of inference compute being used. That is, it seems natural to draw a curve that represents the capabilities of these models as a function of the inference cost, roughly like this for o1 and o3:
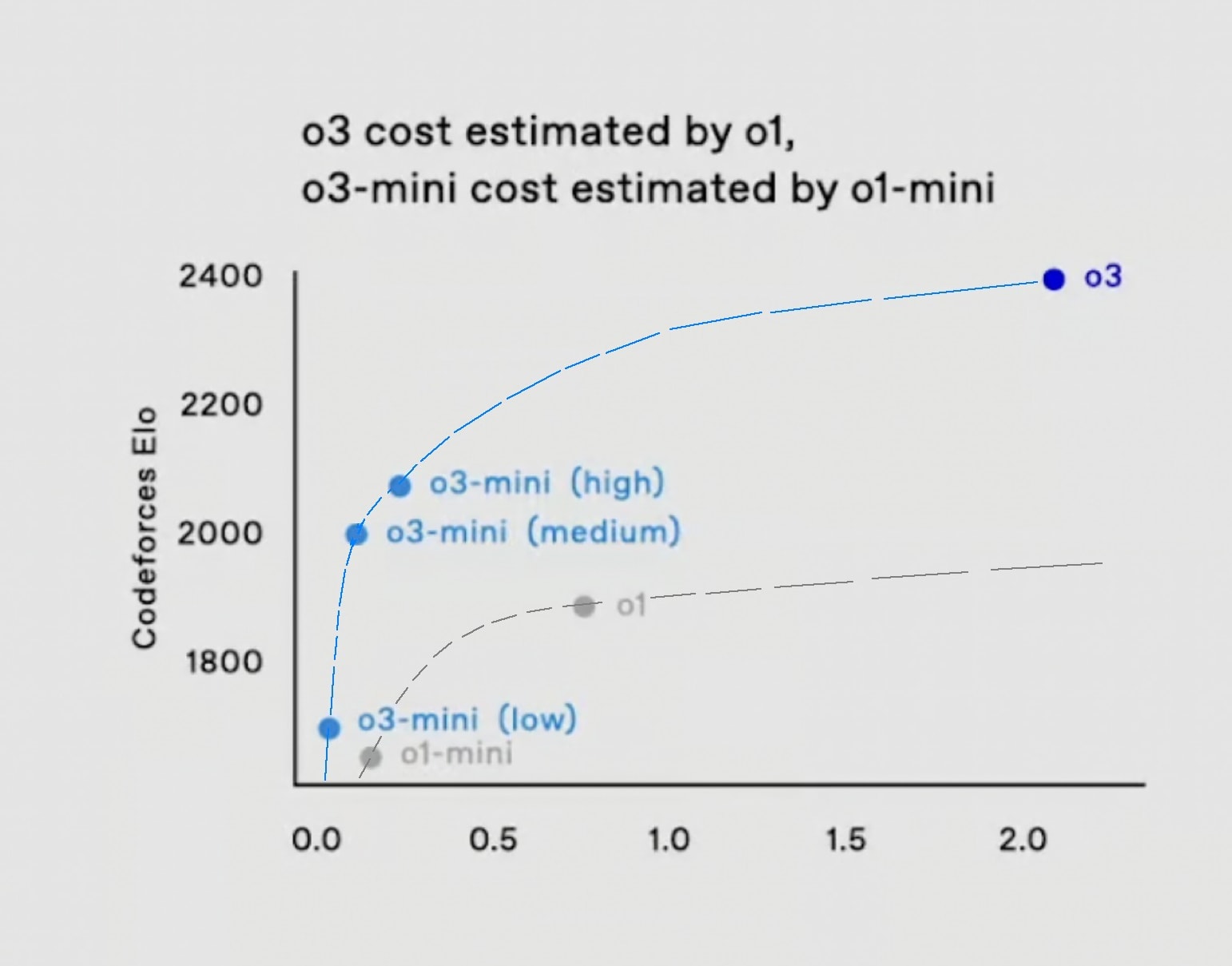
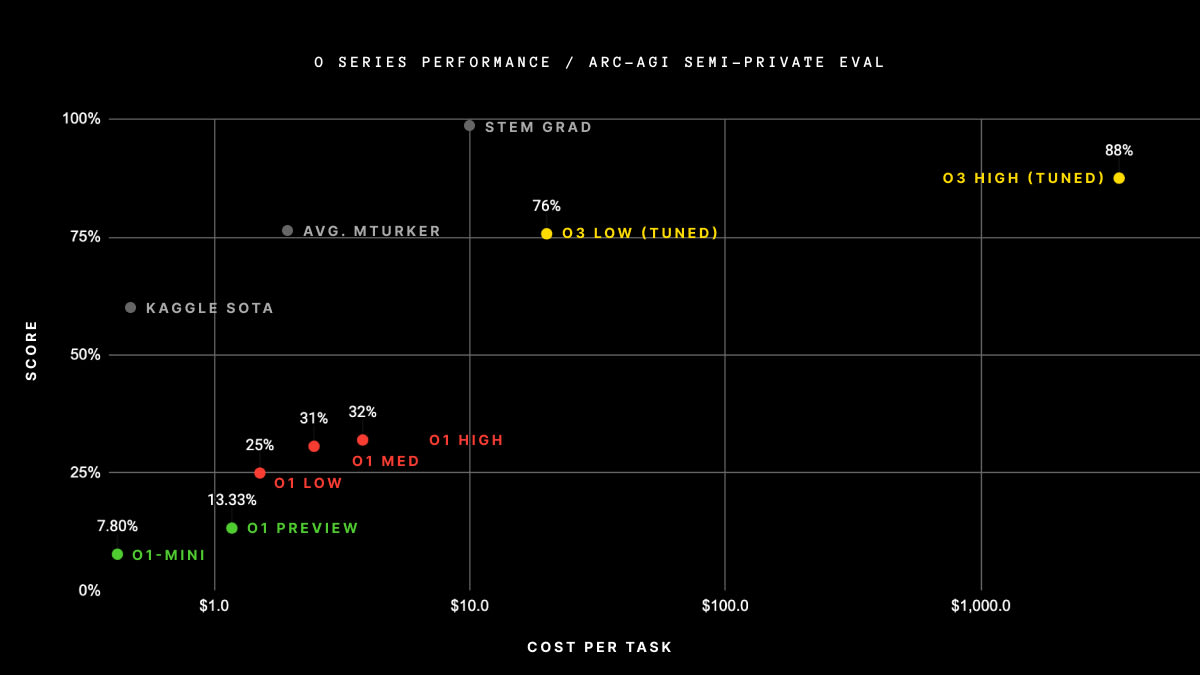
To be clear, I don't know whether this kind of picture is accurate (i.e. whether the inference cost is indeed the chief difference between oX-mini vs full oX models), but other graphs give a similar impression, such as this one for the ARC-AGI benchmark, in which o1 preview, o1 (including o1-mini), and o3 each seem to follow their own respective performance curves:
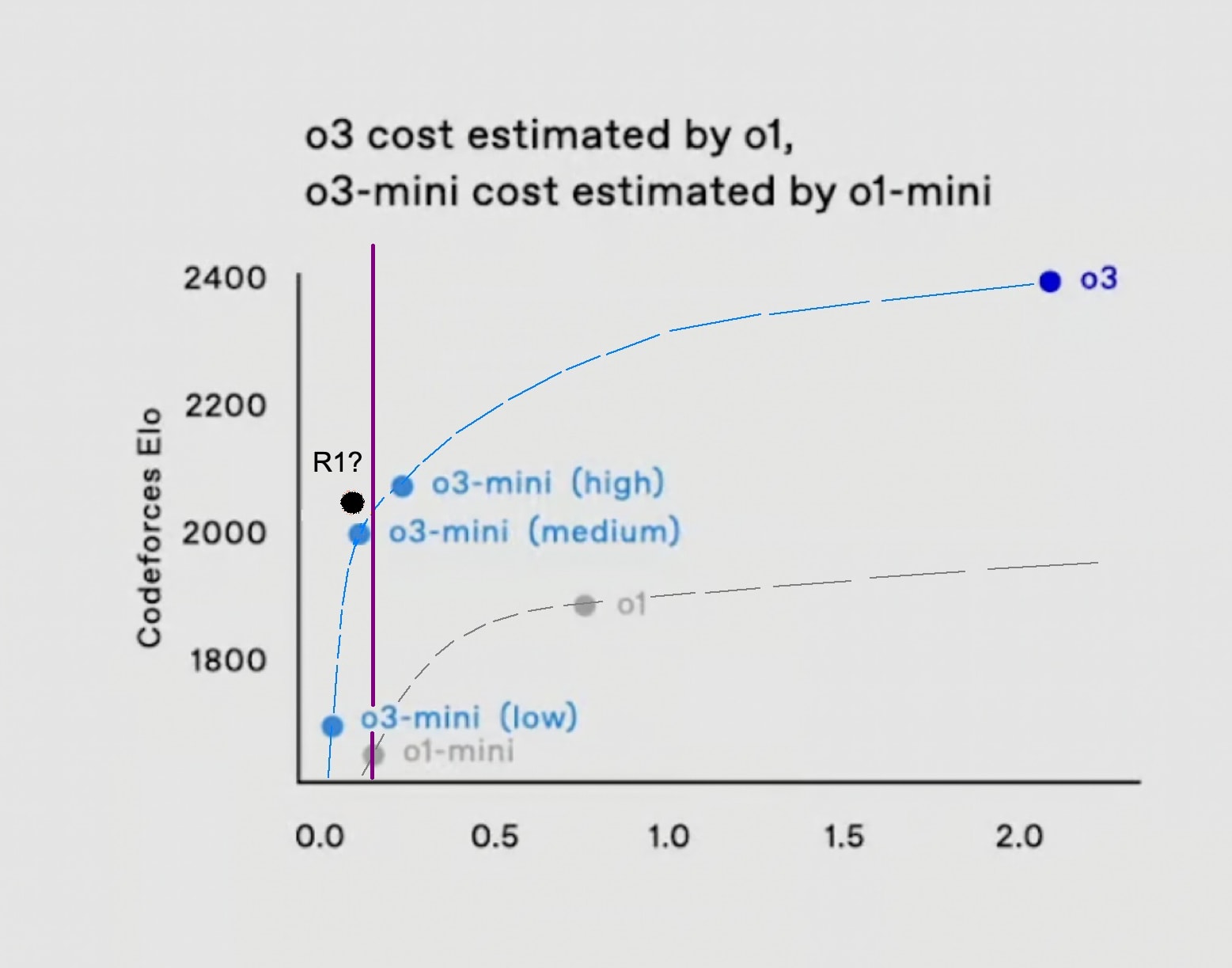
Now, what stood out to me is that the reported benchmark results for DeepSeek-R1 appear to slightly surpass those of o3-mini-medium, at least on some benchmarks. For example, R1 got 2029 on Codeforces, while o3-mini-medium got 1997. Similarly, R1 got 79.8 percent on the math benchmark AIME 2024, whereas o3-mini-medium got 78.2 percent. On the other hand, R1 did worse on the GPQA benchmark, where it got 71.5 percent against o3-mini-medium's 74.9 percent.
The key question is then: what is R1's inference cost when it gets those results? And how does that compare to o3's performance curve? I'm not sure whether there is clear data on this, but the pricing info I've seen suggests that DeepSeek-R1 API output is considerably cheaper than o1-mini API output:
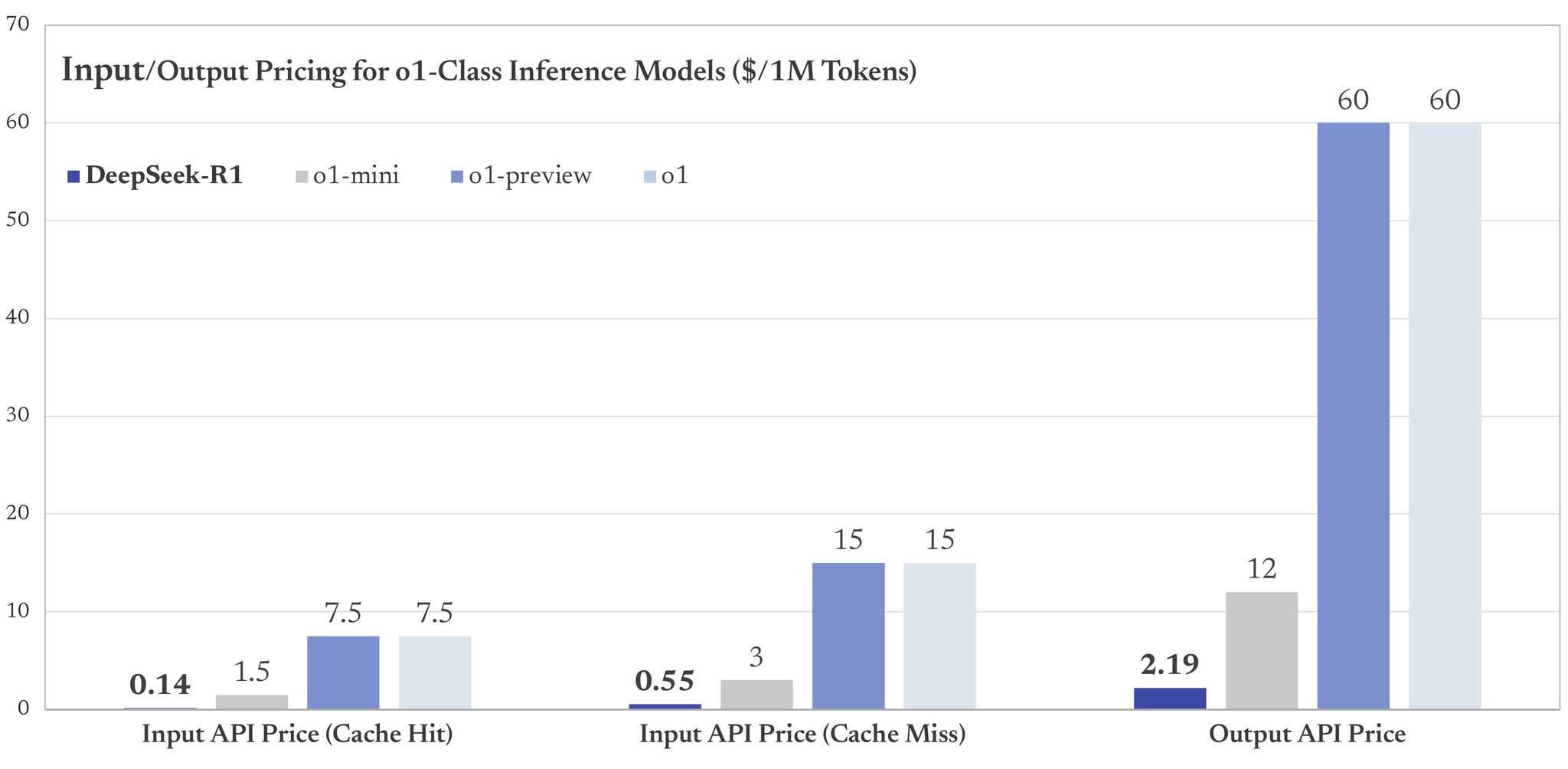
I don't know how directly this pricing info can be translated into inference costs in particular (in a way that can be compared to the o3 graph below). Yet if we assume that the lower price of R1 API output (compared to o1-mini API output) means that R1 generally has a lower inference cost than o1-mini, it would appear that R1's inference cost is somewhere to the left of the purple line below, which in turn suggests(?) that R1 might already perform better than o3 when the inference cost is held constant:
I guess there are basically two questions here:
- Is it accurate that OpenAI's oX-mini and full oX models are essentially the same models given different amounts of inference compute?
- How does the inference cost of R1 compare to that of o3?
- In other words, is R1's performance curve already above that of o3 (at least on some benchmarks)?