TL/DR: We developed an interactive guide to AI safety arguments, based on researcher interviews. Go check it out! Please leave a comment and let us know what you think.
Introduction
Vael Gates interviewed 97 AI researchers on their beliefs about the future. These interviews were quite broad, covering researchers’ hopes and concerns for the field in general, as well as advanced AI safety specifically. Full transcripts are now available.
Lukas Trötzmüller interviewed 22 EAs about their opinions on AI safety. They were pre-selected to be skeptical either about the classical “existential risk from AI” arguments, or about the importance of work on AI safety. The focus of this research was on distilling specific arguments and organizing them.
This guide builds mostly on Vael’s conversations, and it aims to replicate the interview experience. The goal is not necessarily to convince, but to outline the most common arguments and counterarguments, and help readers gain a deeper understanding of their own perspective.
Design Goals
Our previous research has uncovered a wide range of arguments that people hold about AI safety. We wanted to build a resource that talks about the most frequently mentioned of those.
Instead of a linear article (which would be quite long), we wanted to create an interactive format. As someone goes through the guide, they should be presented with the content that is most relevant to them.
Even though we had a clear target audience of AI researchers in mind, the text turned out to be surprisingly accessible to a general audience. This is because most of the classical AI risk arguments do not require in-depth knowledge of present-day AI research.
Format
Our guide consists of a collection of short articles that are linked together. There are five main chapters:
- When will Generally Capable AI Systems be developed?
- The Alignment Problem (“AI systems don’t always do what we want”)
- Instrumental Incentives
- Threat Models (“how might AI be dangerous?”)
- Pursuing Safety Work
Each chapter begins with an argument, after which the reader is asked for their agreement or disagreement. If they disagree, they can select between several objections that they may have.
Each one of these objections links to a separate article, presenting possible counterarguments, that they can optionally read. Most of the objections and counterarguments are directly taken from Vael’s interviews with AI researchers.
After reading the counterargument, the reader can indicate whether they find it plausible, then is guided back to the introduction of the chapter. The reader may advance to the next main chapter at any time.
The following diagram illustrates this structure:
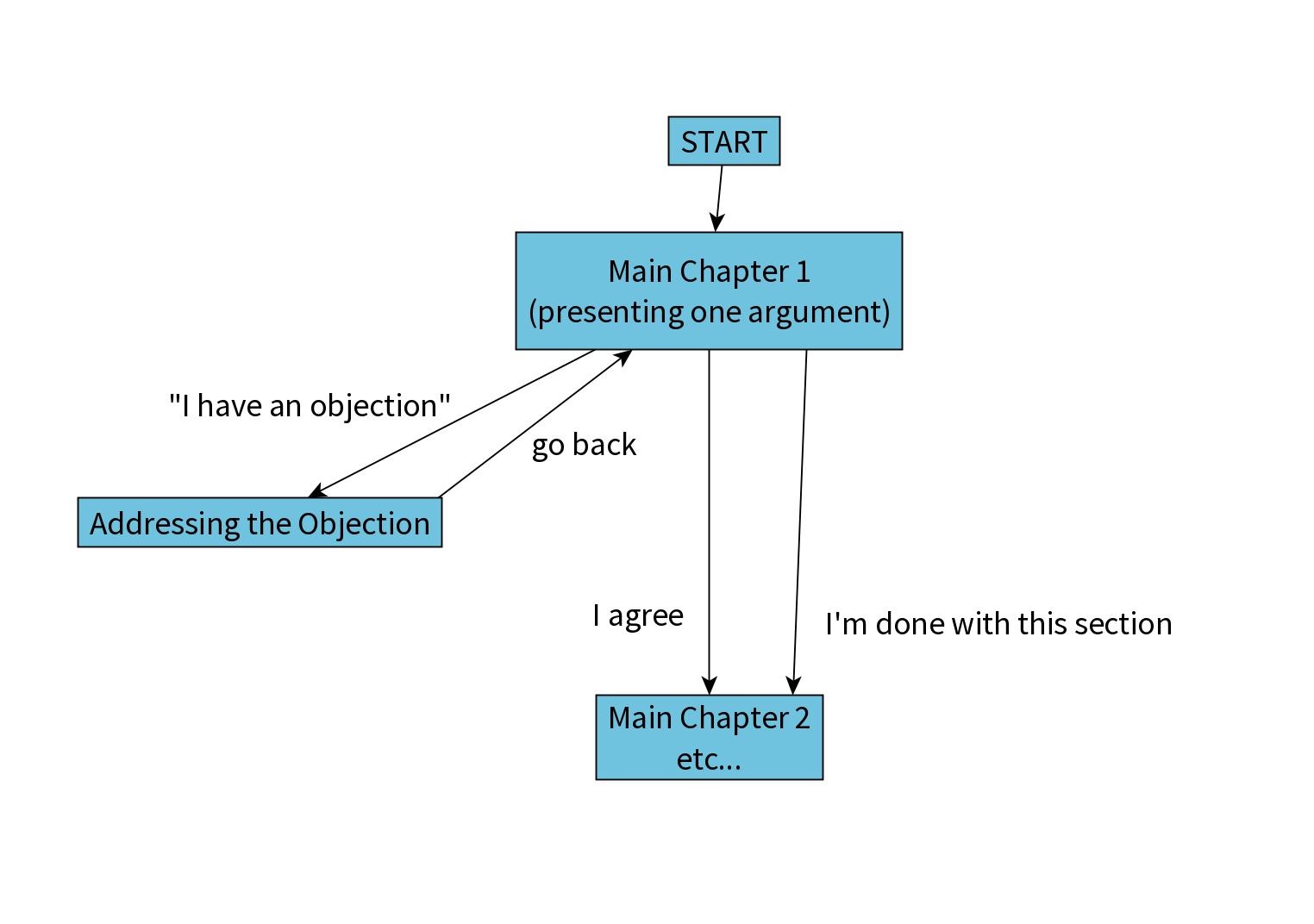 Agreement and disagreement is shown visually in the table of contents.
Agreement and disagreement is shown visually in the table of contents.

The “Threat Models” chapter is meant as a short interlude and does not present any counterarguments - we might expand upon that in the future.
Polling and Commenting
It is also possible to leave comments on individual pages. These are displayed publicly at the end of the guide.
On the last page, you can also see a visual summary of your responses, and how they compare to the average visitor:
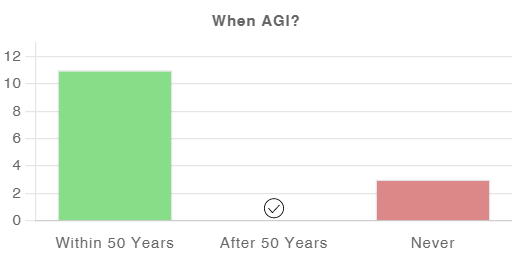
Requesting Feedback
We are releasing this within the EA and alignment communities. We would like to gather additional feedback before presenting it to a wider audience. If you have feedback or suggestions, please leave a comment below. We welcome feedback on the structure as well as the language and argumentation.
Creating Interactive Guides for Other EA Cause Areas
Our goal was to enable anyone to put complex arguments into an interactive format - without requiring experience in web development. The guide is written in a Google Doc. It contains all the pages separated by headlines, and some special code for defining the structure. Our system converts this document into an interactive website, and updates can be made through the document.
Nothing about the interactive system we developed is special to AI safety. This could be used for other purposes - for example: an introduction to longtermism, the case for bio security, or explaining ethical arguments. If you would like to use this for your project, please get in touch with Lukas.
Related Projects
The Stampy project aims to provide a comprehensive AI safety FAQ. We have given the Stampy team permission to re-use our material as they see fit.
Conclusion & Downside Risk
If you haven’t opened the guide yet, go ahead and check it out. We are really interested in your comments. How is the language and the argumentation? Are we missing important arguments? Could we make this easier to use or improve the design? Would you actually recommend this as a resource to people, if not why?
Looking at the result of our work, we notice positives and negatives.
Vael likes that the content is pretty clear and comprehensive.
Lukas likes the visual presentation and the overall look & feel. However, he has some reservations about the level of rigour in the argumentation - there are definitely parts that could be made more solid.
We both like the interactive format. We are unsure whether this is the best way to talk to people, from a fieldbuilding perspective. The reason is this: Even though the guide is interactive, it is not a replacement for a real conversation. People only have a limited number of options to choose from, and then they get lots of text trying to counter their arguments. Indeed, we wonder if this might create resistance in some readers, and if the downside risks might be worse than the upsides.
Contributions
The guide was written by Lukas Trötzmüller, with guidance and additional writing from Vael Gates.
Technical implementation by Michael Keenan and Lukas Trötzmüller.
Copy Editing: David Spearman, Stephen Thomas.
We would like to thank everyone who gave feedback.
This work was funded by the AI Safety Field Building Hub.
Thanks for this! I liked it and found it helpful for understanding the key arguments for AI risk.
It also felt more engaging than other presentations of those arguments because it is interactive and comparative.
I think that the user experience could be improved a little but that it's probably not worth making those improvements until you have a larger number of users.
One change you could make now is to mention the number of people who have completed the tool (maybe on the first page) and also change the outputs on the conclusion page to percentages.
How do you imagine using this tool in the future? Like what are some user stories (e.g., person x wants to do y, so they use this)?
Here are some quick (possibly bad) ideas I have for potential uses (ideally after more testing):
I also like the idea of people making something like this for other cause areas and appreciate the effort invested to make that easy to do.
Congrats!
I tried to comment on the page https://ai-risk-discussions.org/perspectives/test-before-deploying, but instead got an error message telling me to use the contact mail.
Thanks for the bug report, checking into it now.
Update: Michael Keenan reports it is now fixed!