Introduction/summary
In my last post, I laid out my picture of what it would even be to solve the alignment problem. In this series of posts, I want to talk about how we might solve it.
To be clear: I don’t think that humans necessarily need to solve the whole problem – at least, not on our own. To the contrary, I think we should be trying hard to get help from sufficiently capable and trusted AIs.[1] And I think various paths that my last post would class as “avoiding” or “handling but not solving” the problem, rather than “solving it,” are important to consider too, especially in the near-term.[2]
I’ll discuss this more in future posts. Still, even if we ultimately need AIs to help us solve the problem, I expect it to be useful to have as direct a grip as we can, now, on what the full problem is, what makes it difficult, and what approaches are available for solving it. More on why I think this below.
A few other meta notes:
- The content here is rough. I’m hoping, later, to revise it, along with some other work (including some of the future posts just mentioned), into something more polished and cohesive. But for various reasons, I wanted to get it out there on the earlier side.
Partly because I think we ultimately want to get lots of AI help on this problem, my aim here isn’t to defend one specific “solution.” Rather, my main aim is to improve our thinking about the space of solutions overall (though I do give various takes on how promising different approaches seem, and what’s required for them to work). Maybe I’ll try something more ambitious in future.[3] But I’m not actually sure what level of ambition in this respect is appropriate, from our current position. And regardless: this is where I’m at so far.
As often in discussions of aligning/controlling advanced AI systems: I think it’s plausible that various of the AIs at stake in this discussion would be moral patients by default; and if they are, many if not all of the interventions I discuss raise serious ethical concerns. I’m leaving discussion of this issue to future work. But I want to keep acknowledging it regardless.[4]
Summary of the series
The series is in four parts. Here’s a summary of the posts that have been released thus far (I’ll update it as more come out).
Part 1 -- Ontology
The first post (this one) lays out the general ontology I’ll use for thinking about approaches to solving the full alignment problem.
I start by reviewing my definition of what it would be to solve the full alignment problem (i.e., building superintelligent AI agents, without succumbing to the bad kind of AI takeover, and becoming able to elicit most of their beneficial capabilities). Most of the series focuses on avoiding takeover,[5] but I return to capability elicitation at the end.
I also briefly defend the usefulness of actually thinking about the full problem, at least for people who want the sort of high-level clarity about AI X-risk that I, personally, am seeking.
- I then describe an ontology for thinking about available approaches to the problem. In particular:
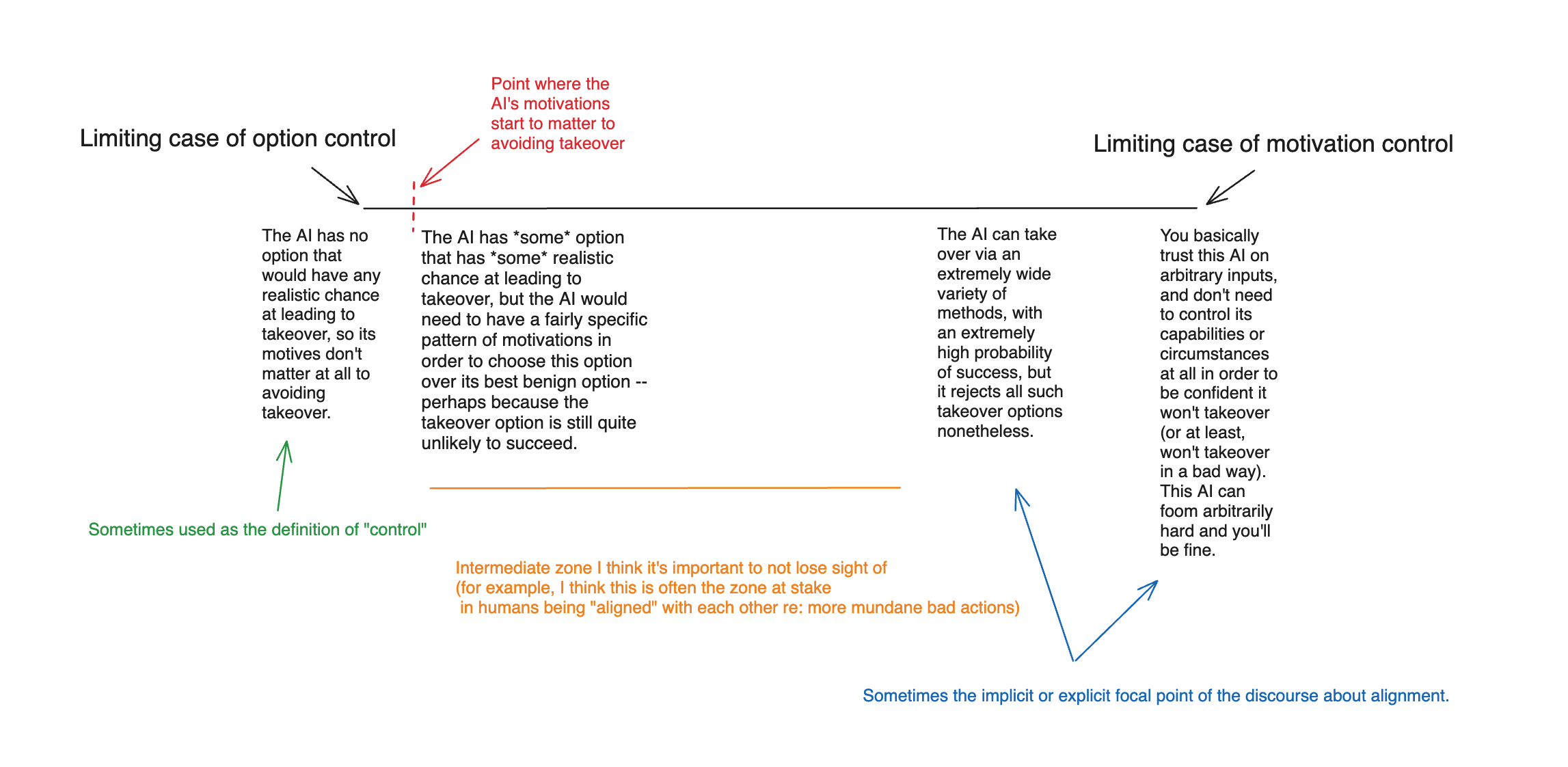
- I distinguish between what I call “motivation control” (i.e., trying to give an AI’s motivations specific properties) and “option control” (i.e., trying to give AI’s options specific properties), and I suggest that we take seriously the sense in which a solution to the alignment problem may need to combine the two (rather than focusing purely on limiting cases like “the AI has no takeover option with any non-trivial chance of success” or “we trust the AI to foom arbitrarily/the AI would never takeover no matter what options are available”).
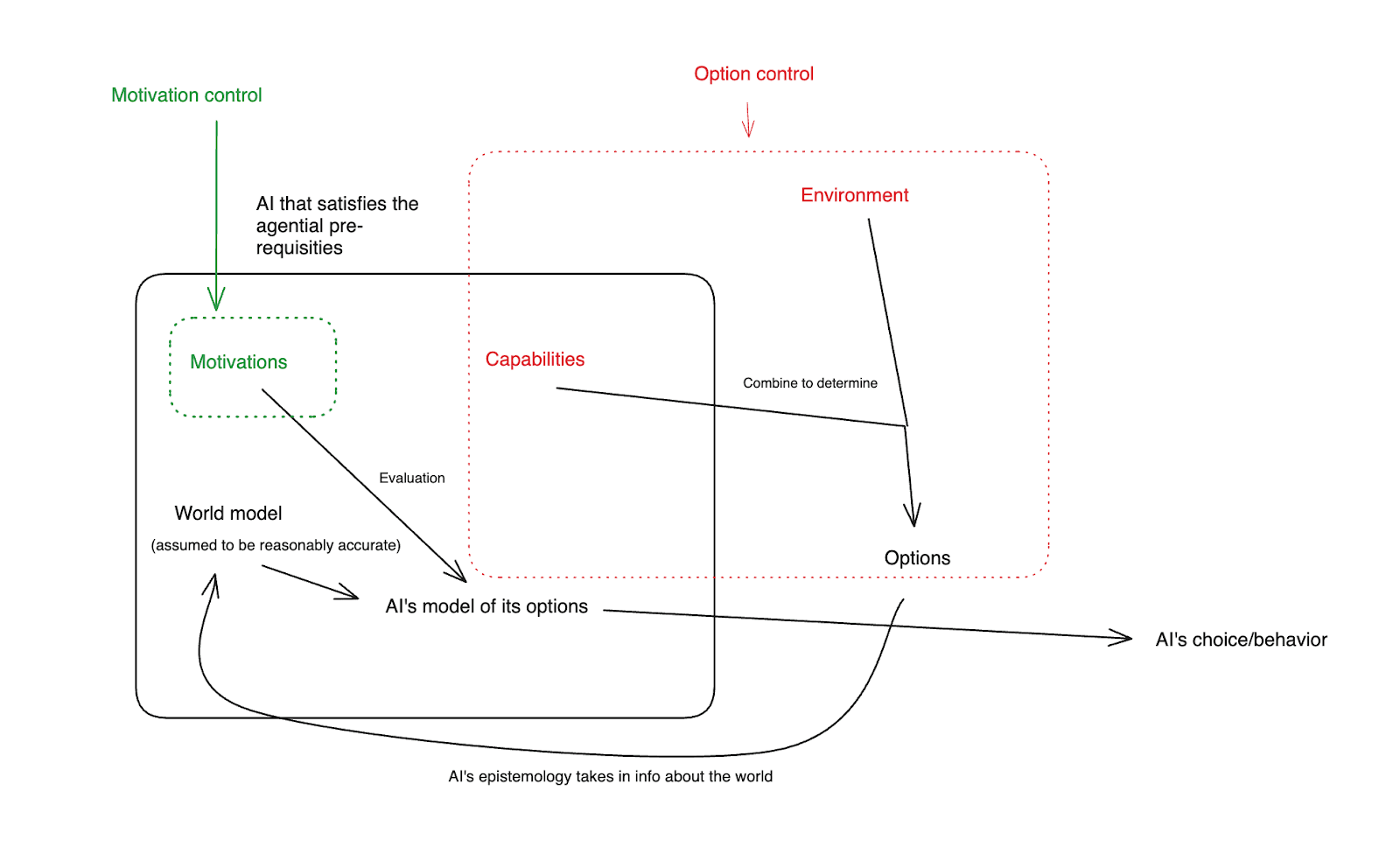
Diagram of motivation control and option control
- I sketch out a type of “safety case” – what I call an “incentive structure safety case” – tuned to the combination of option and motivation control in particular, and I offer some toy examples.
- This sort of safety case has three parts:
- The incentive specification: what properties you’re aiming to ensure that your AI’s motivations and options have.
- The incentive justification: why you believe that ensuring these properties will ensure safety from takeover.
- The incentive implementation: how you plan to ensure that the AI’s motivations and options have these properties.
- This sort of safety case has three parts:
An incentive structure safety case
I then flesh out the space of possibilities for option/motivation control in a bit more detail – in particular, distinguishing between what I call “internal” vs. “external” variables (roughly: the former are what a “black box” AI hides), and between “inspection” vs. “intervention” directed at a given variable.
- I also discuss some of the dynamics surrounding what I call “AI-assisted improvements” – i.e., the possibility of using AI labor, and/or the fruits of AI labor, to become able to do a given type of inspection/intervention much more effectively/efficiently than we can today. I think this is likely to be a crucial piece of the puzzle, and that it doesn’t necessarily imply problematic forms of circularity like “you need to have already solved alignment in order to trust your AIs to help with alignment.”
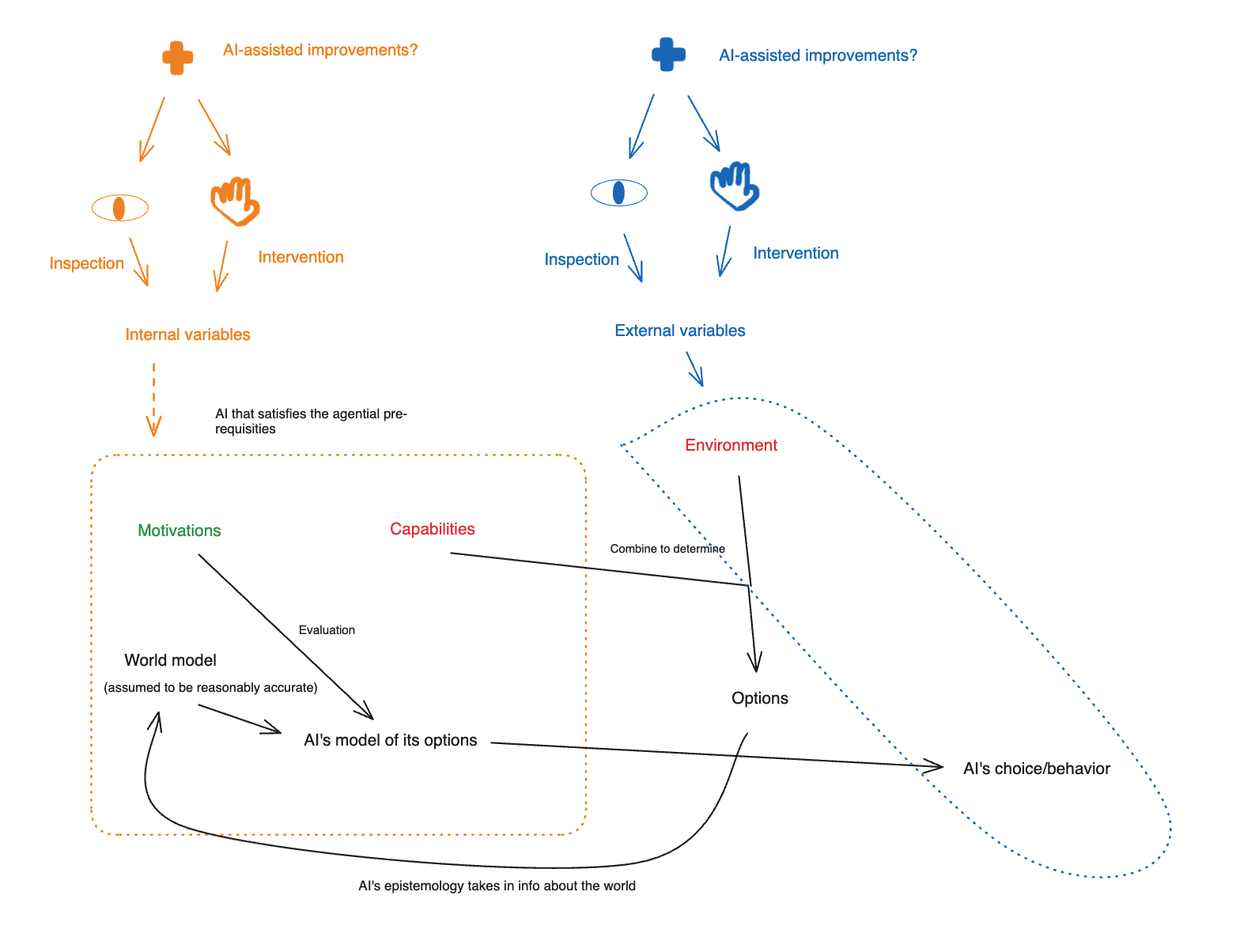
Diagram of the overall ontology in the first post
Part 2 -- Motivation control
In the second post, I offer a more detailed analysis of the available approaches to motivation control in particular.
- I start by describing what I see as the four key issues that could make motivation control difficult. These are:
- Generalization with no room for mistakes: you can’t safely test on the scenarios you actually care about (i.e., ones where the AI has a genuine takeover option), so your approach needs to generalize well to such scenarios on the first critical try (and the second, the third, etc).
- Opacity: if you could directly inspect an AI’s motivations (or its cognition more generally), this would help a lot. But you can’t do this with current ML models.
- Feedback quality: to the extent you are relying on behavioral feedback in shaping your AI’s motivations, flaws in a feedback signal could create undesirable results, and avoiding such flaws might require superhuman evaluation ability. (Also you need to train on a sufficient range of cases.)
- Adversarial dynamics: the AI whose motivations you’re trying to control might be actively optimizing against your efforts to understand and control its motivations; and the other AI agents you try to get to help you might actively sabotage your efforts as well.
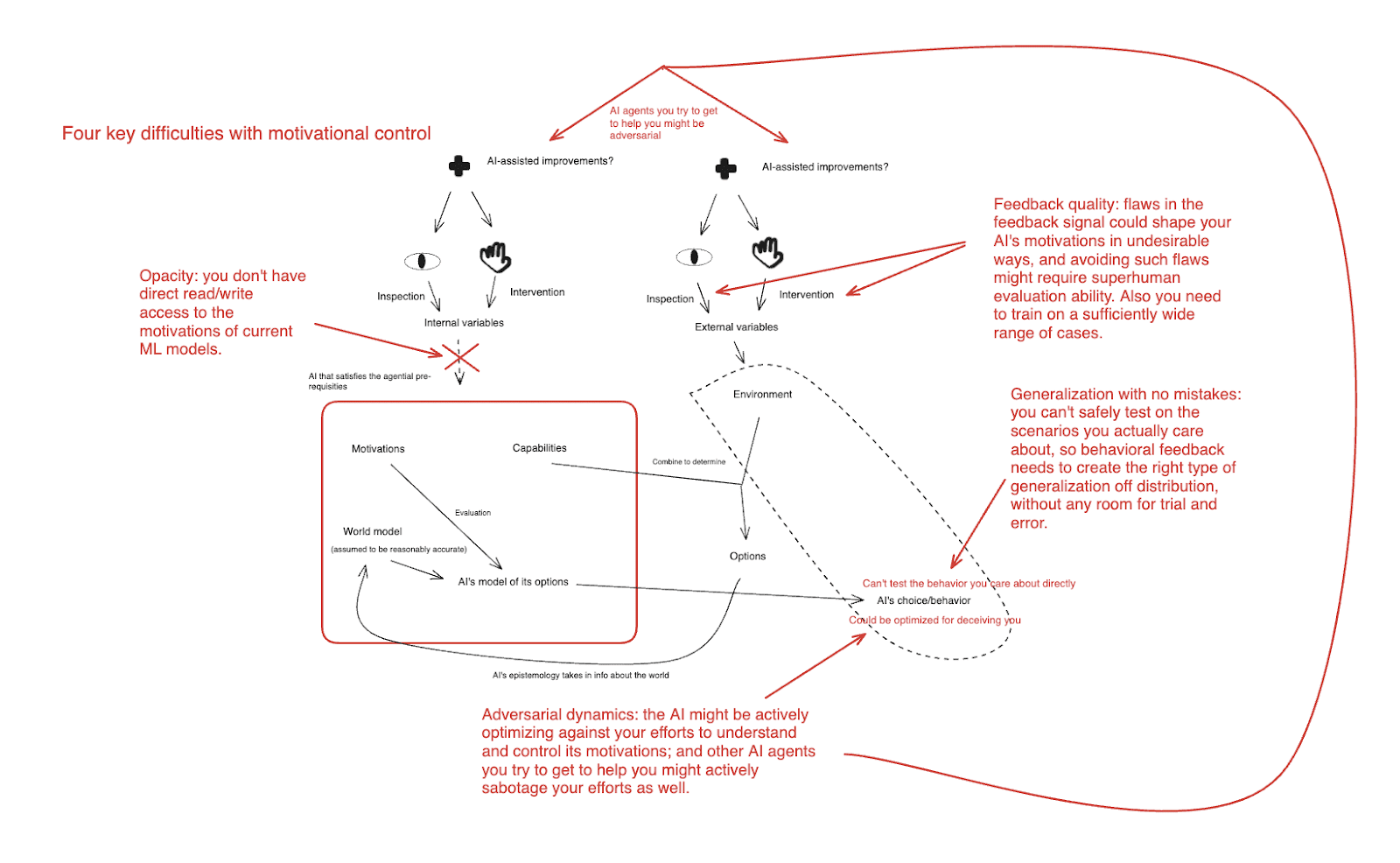
There four difficulties in a convoluted chart
- I then turn to discussing available approaches to addressing these difficulties.
- First, I’ll talk about approaches that are compatible with basically no “transparency,” and which rely almost entirely on behavioral feedback for shaping an AI’s motivations, and behavioral evidence for understanding those motivations.
- The three main approaches I discuss here are:
- A “baseline plan” that I call “behavioral feedback + crossing your fingers.” I.e., you give the best behavioral feedback you can (including via e.g. scalable oversight, adversarial training, etc), and then hope it generalizes well.
- I think we should try to do better than this.
- Using fake takeover options to become confident about the AI’s behavior on real takeover options.
- Using other behavioral approaches to develop adequate scientific understanding of generalization that you can be confident that the AI’s motivations will generalize well. (I call this “behavioral science of AI motivations.”)
- A “baseline plan” that I call “behavioral feedback + crossing your fingers.” I.e., you give the best behavioral feedback you can (including via e.g. scalable oversight, adversarial training, etc), and then hope it generalizes well.
- The three main approaches I discuss here are:
- I then turn to approaches that assume at least some degree of transparency.
- I then discuss three main approaches to creating transparency, namely:
- “Open agency” (roughly: building transparent AI agents out of safe but-still-black-box ML models, a la faithful chain-of-thought);
- “Interpretability” (roughly: learning to make ML models less like black boxes);
- “New paradigm” (roughly: transitioning to a new and more transparent paradigm of AI development that relies much less centrally on ML – for example, on that more closely resembles traditional coding).
- I then discuss three main approaches to creating transparency, namely:
- First, I’ll talk about approaches that are compatible with basically no “transparency,” and which rely almost entirely on behavioral feedback for shaping an AI’s motivations, and behavioral evidence for understanding those motivations.
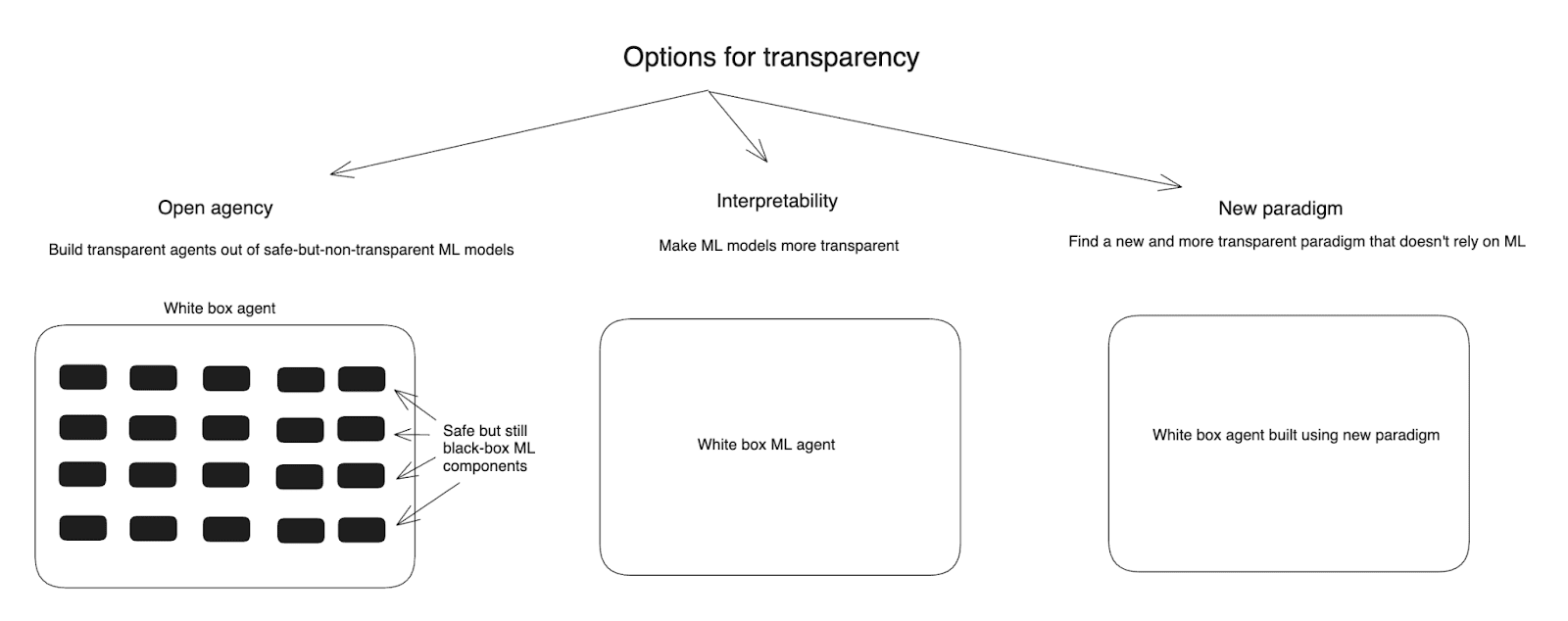
Diagram of the options for transparency I consider
- I further distinguish between attempting to target the AI’s motivations directly using a given approach to transparency, vs. attempting to target some other internal variable.
- Finally, I talk about how you might translate transparency about some internal variable into motivational control.
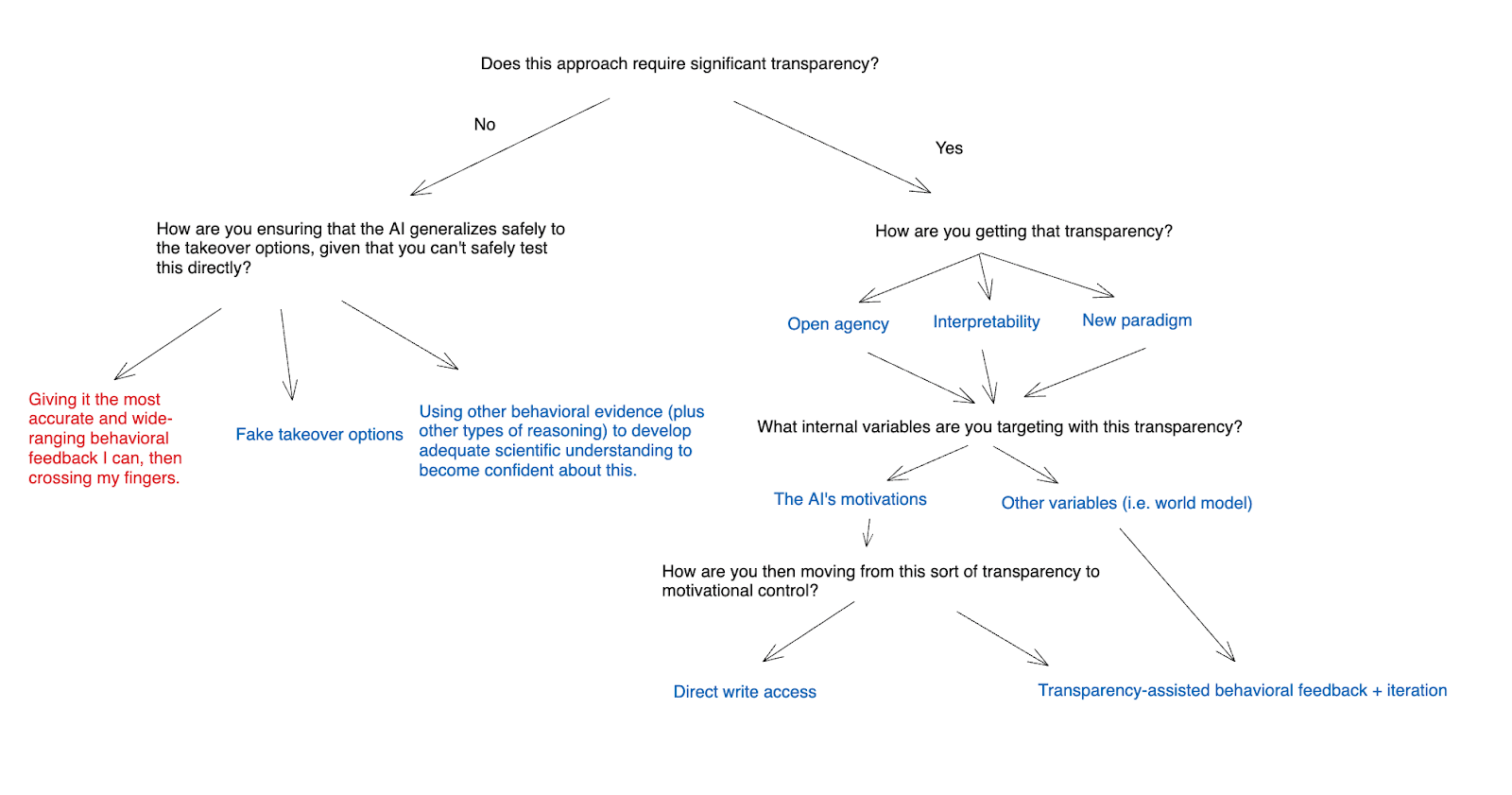
Diagram of the breakdown I use for thinking about motivation control
Part 3 -- Option control
In the third post, I offer an analysis of available approaches to option control.
- I start by briefly arguing that option control still matters even in the context of superintelligences.
- I then distinguish between a few different types of option control – and in particular, between approaches that focus on limiting/eliminating paths to successful takeover (what I call “takeover-path restriction”) vs. approaches that focus on influencing an AI’s incentives in some other way (“other incentive shaping”).
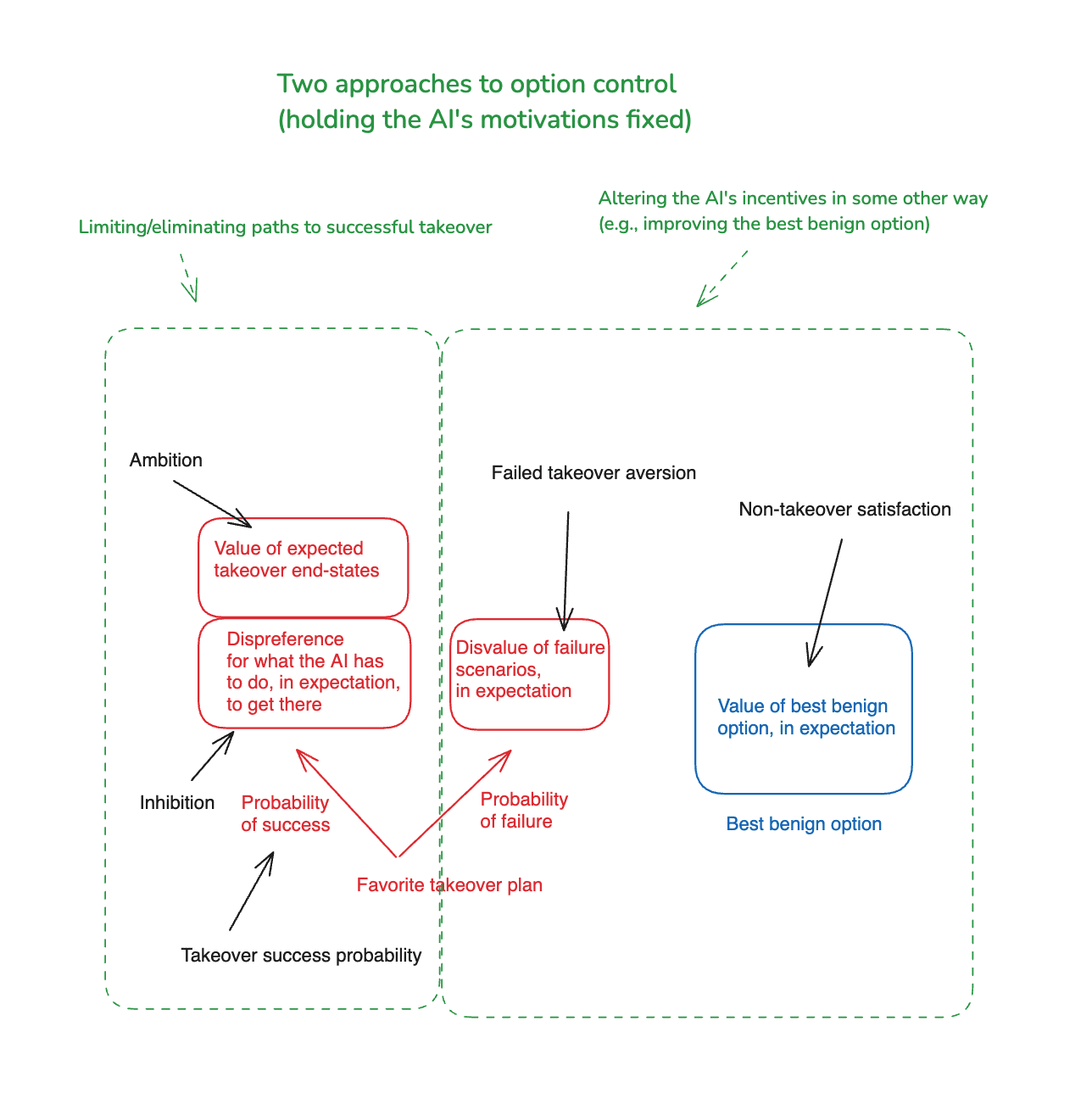
Diagram of two approaches to option control
- I then discuss takeover path restriction in some detail.
- I start by drawing a few comparisons and contrasts with motivation control – in particular, takeover path restriction does not require the same kind of generalization; and sufficiently high quality oversight can turn motivation control issues into option control issues (because it can sufficiently restrict available takeover paths).
- I then discuss what I see as the four key issues with takeover path restriction (in the context of superintelligence), namely:
- Superhuman strategies: Superintelligences can use takeover strategies that humans couldn’t generate ahead of time or detect while they’re being pursued.
- Opacity: again, it would help a lot to have direct epistemic access to internal variables like an AI’s capabilities, world model, reasoning, motivations, and so on; but in current ML models, you don’t.
- Oversight scarcity/latency: Even if we had reliable oversight, it might be too expensive to apply to enough actions, and/or too slow to respond to bad behavior.
- Adversarial dynamics: an AI might be actively optimizing against your efforts to restrict its takeover options, and the AIs you try to get to help you might sabotage your efforts as well.
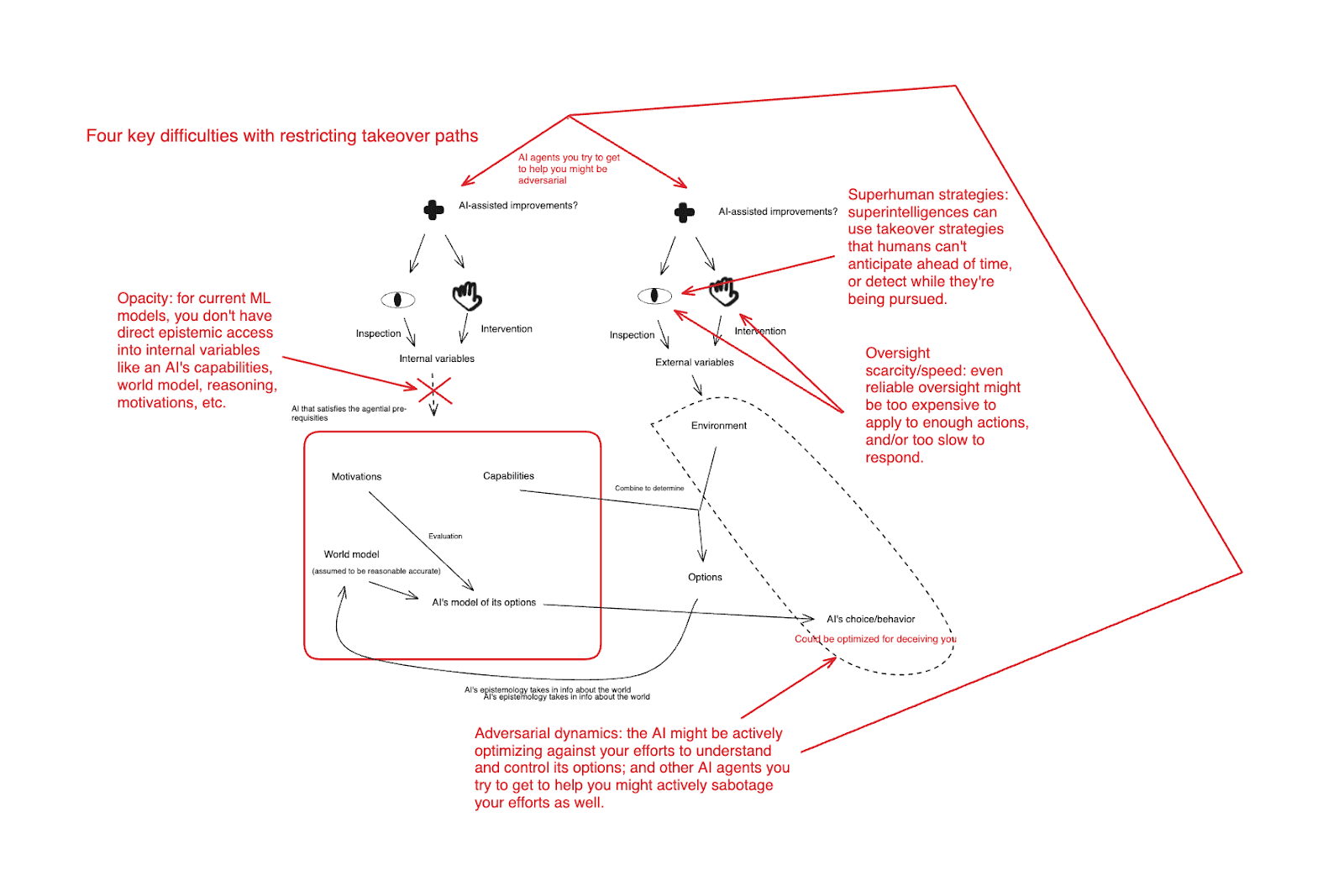
These four difficulties in a diagram
- I then turn to a discussion of how we might address these difficulties.
- I start by discussing our options for restricting the capabilities of our AIs – both in the context of “black box” approaches that can’t benefit from transparency, and more “white box” approaches that can.
- I then turn to a discussion of available approaches to hardening an AI’s environment against takeover attempts – again, in both a black box and a white box context, but starting with black box.
- Here I zoom in, in particular, on the possibility of using oversight to try to detect and block takeover pursuit while it occurs. I think there are a bunch of promising options in this vein, but they will require safe access to superhuman qualities of cognitive labor, which itself will require avoiding collusion between overseers and the AI-being-overseen.
- I also discuss other aspects of black box environmental hardening – both within the AI’s local environment (i.e., security practices within an AI lab), and within the broader world (i.e., generally improving the world’s coordination and governance, its robustness to various threat models, etc).
- I think that “stress-testing” (i.e., using a red-team to evaluate what sorts of takeover paths would be available to a given AI in a given environment) is also likely to be a very useful tool for environmental hardening – but I think it, too, will require safe access to superhuman cognitive labor.
- If we had greater transparency into the cognition of our AIs, this would help significantly with oversight, stress-testing, and other aspects of environmental hardening. I discuss a few possibilities on this front as well.
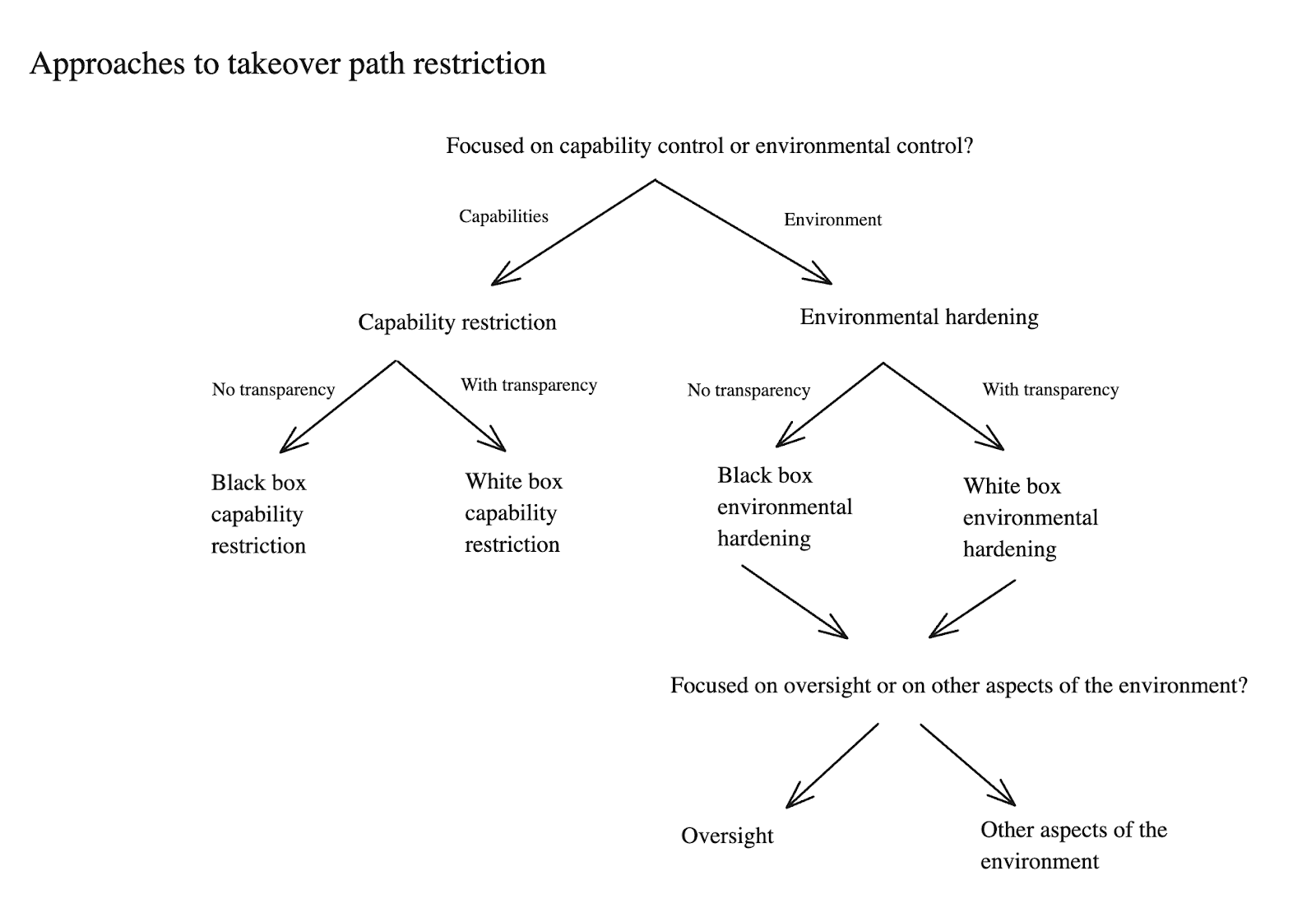
Diagram of the approaches to takeover path restriction I discuss
After this discussion of takeover path restriction, I turn to a discussion of other ways of potentially using option control to shape an AI’s incentives in desirable ways. In particular, I zoom in on the possibility of improving the AI’s best non-takeover option, so as to make cooperative strategies more attractive by the lights of its values (I call this “rewarding cooperation”).[1]
Here I describe five key challenges, and how I think we might try to address them. In particular:
Viable attempts at rewarding cooperation likely require at least some other success at motivation/option control as well – otherwise the AI will probably be able to get more of the relevant “reward” more easily via takeover. So this needs to be one component of a broader approach.
You need to figure out how to improve an AI’s best benign option in a way that it actually wants, despite “opacity” issues potentially making it harder to know what its preferences are. But there are a variety of sources of optimism here (in particular: you can reward it using convergently instrumental goods like resources/compute/help-with-what-it-asks-for; and/or you can commit to later using better transparency tools to understand its motivations better and reward them then).
You need the intervention to improve the AI’s best benign option more than it improves the AI’s favorite takeover option; but I think this is pretty easy to achieve (i.e., by default ways in which some improvements will impact worlds where the AI cooperates more, by making the “payment” conditional on cooperative behavior, and by drawing on future ability to investigate what behavior was cooperative).
You need the relevant “reward” to be sufficiently credible to the AI in question. This issue further decomposes into (a) the difficulty of making it true that the reward will occur with the relevant probability, and (b) the difficulty of giving the AI enough evidence of this fact. I’m more optimistic, re: (a), for short-term rewards than for long-term rewards; and conditional on success with (a), I’m optimistic about (b), because I think the AI’s strong epistemic capacities are on our side.
Finally, you need to size the reward adequately for it to make the desired difference to the AI’s incentives, while also being worth “paying” by your lights. I think this is probably the most difficult issue, and I’m most optimistic about it with respect to the components of AI motivation that are specifically focused on shorter-term goods that the AI doesn’t have time to procure via takeover (e.g., improvements to local working conditions).
Part 4 -- Incentive design and capability elicitation
In the fourth and final post, I wrap up the series with a discussion of two final topics: namely, moving from motivation/option control to safety-from-takeover (let’s call this “incentive design”), and capability elicitation.
- I start with a few comments on incentive design. Here my main point is that even if you have a large amount of control over the motivations of a given AI (for example, the sort of control at stake in being able to write a model spec that the AI will follow in common-sensical ways), there is still at least some further work to do in choosing what sorts of motivations to give the AI in question, such that they won’t lead to the AI pursuing takeover given the full range of options it might be exposed to.
- I think there are lots of grounds for optimism on this front, especially if we’re really imagining that we have large amounts of motivational control available.
- In particular, avoiding takeover here might be almost as easy as writing, in your model spec, the rough equivalent of “seriously, do not try to take over.”
- And at-all-reasonable model specs – which ask the AI to be honest, compliant with instructions, etc – would already cut off many of the most salient paths to takeover.
- Still, I think we should remain vigilant about the possibility of ignorance about exactly what a given sort of motivational specification will end up implying, especially as the world changes fast, the AI learns new things, etc; and that we should invest in serious (probably AI-assisted) red-teaming to get evidence about this.
- I think there are lots of grounds for optimism on this front, especially if we’re really imagining that we have large amounts of motivational control available.
- I then turn to the issue of capability elicitation – the other main component of “solving the alignment problem,” on my definition, on top of avoiding takeover.
- I suggest that many of the tools and frameworks the series has discussed re: avoiding takeover transfer fairly smoothly to capability elicitation as well. Mostly, we just need to add the constraint that the AI’s incentives not only privilege the best benign option over its favorite takeover plan, but also that its best benign option is the desired type of task-performance, as opposed to something else (and conditional on avoiding takeover, failures on capability elicitation are lower stakes and more iteration-friendly).
- I briefly describe two key questions I think about in the context of capability elicitation, namely:
- Can we make desired task-performance “checkable” in the roughly “output-focused” sense I discuss here – i.e., verifiable centrally based on examination of the output/behavior in question.
- Can we successfully elicit forms of task-performance that are “checkable” in this sense using behavioral feedback (plus various other possible anti-sandbagging measures)?
- If the answer to both questions is “yes,” then I think there are grounds for optimism about capability elicitation centrally using behavioral feedback. If not, then we need to get fancier – and I discuss a few possibilities in this respect.
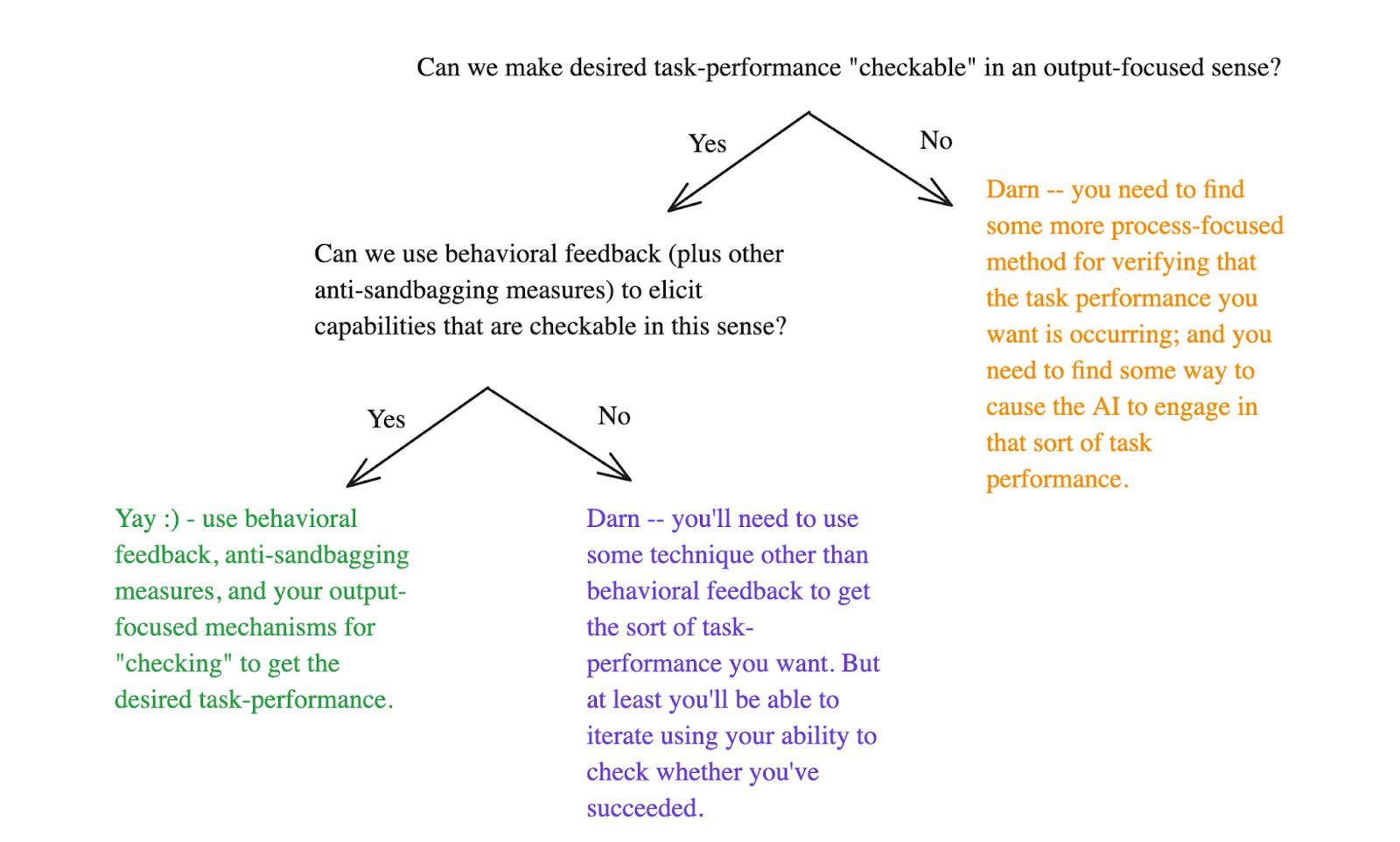
Diagram illustrating the two key questions I describe re: capability elicitation
- Finally, I emphasize that despite the comparatively small amount of attention I’ve given it in this series, capability elicitation is a crucial part of the overall picture, and deeply tied to avoiding takeover. In particular: the full challenge of avoiding takeover only arises in the context of capability elicitation (otherwise you could keep your superintelligence locked up in a box), and successfully eliciting the capabilities of various AIs is likely to play a crucial role in solving the alignment problem with respect to full-blown superintelligence.[1]
What does success look like?
Let’s start by recalling the standard we have to meet. It’s not:
“build a superintelligent AI agent whose values-on-reflection you’re happy to see optimized ~arbitrarily hard.”
Rather, it’s:
“build a superintelligent AI agent that
- doesn’t engage/participate in a bad form of takeover, and that
- chooses to engage in the desired form of task-performance,” (where (2) encompasses a sufficient range of task performance so as to allow access to a significant portion of the potential benefits of superintelligence).[6]
(Here I’m using the taxonomy from my last post pictured in the diagram below.)
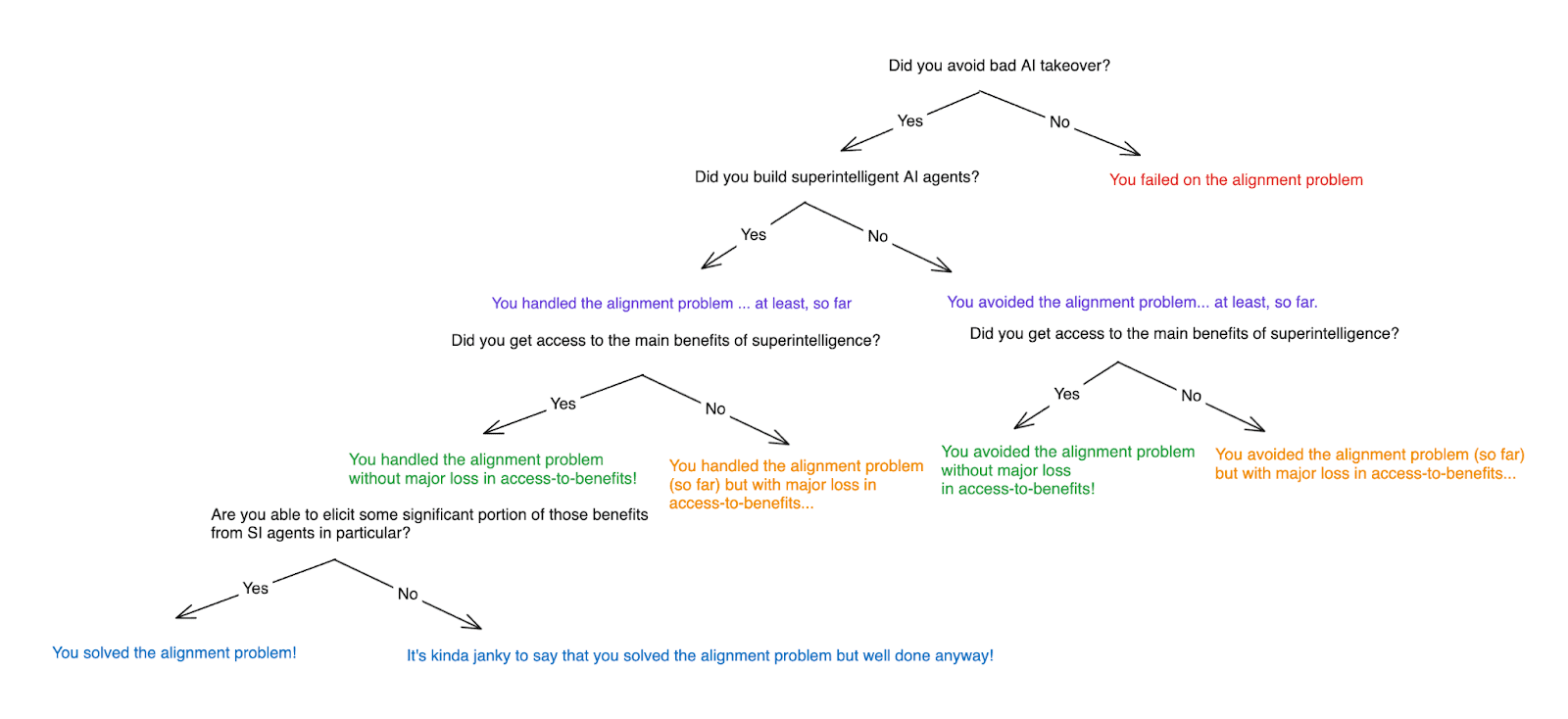
This means that in thinking about the difficulty of alignment, we shouldn’t be thinking about the difficulty of giving the AI exactly the right values. And when we identify a putative difficulty, we should be careful, in particular, to say why we should expect this difficulty to lead to a failure on (1) or (2) above.
Note that (1), here, is higher-stakes than (2), in that failures on avoiding bad takeover are irrecoverable; whereas failures on desired elicitation generally offer more room for iteration and learning-from-your-mistakes (unless the desired elicitation was crucial for avoiding bad takeover, and/or if you can’t identify the mistakes in question). I also think that many of the considerations and approaches relevant to avoiding takeover apply fairly directly to capability elicitation as well. So I’m going to focus most of the discussion on avoiding takeover, and then circle back to capability elicitation at the end.
That said, I think the two are closely interrelated. In particular, I think the full challenge of (1) only arises in the context of (2) – otherwise, you could just keep the superintelligence locked up in a box. And I think our ability to elicit the capabilities of AI systems at a given level of capability is likely to be crucial to our ability to avoid takeover from even more capable AIs.
Re: (1), I’m also going to set aside strategies that involve allowing/assuming that there is going to be an AI takeover, but trying to ensure that this takeover is non-bad. As I discussed in my last post, I think these should be seen as very much a last resort.[7]
Is it even worth talking about the full problem?
Before diving in further, I want to address an objection that I encountered a few times in talking with people about this topic: namely, the objection that it’s not worth thinking in detail about solving the full alignment problem, because humans don’t need to solve this problem (and perhaps: shouldn’t be trying to solve the full problem). Rather, the thought goes, our central focus should be on safely reaching some earlier milestone – for example, becoming able to safely get earlier and less dangerous AI systems to help us.
I agree, here, that our central focus should be on safely getting to an earlier milestone. Indeed, in future posts, I’m hoping to discuss in more detail the array of possible milestones we might consider here, and to defend, in particular, the key role of using safe AI labor to improve the situation. Indeed, various of the approaches I consider here – especially under the heading of “option control” – depend critically on being able to bootstrap to superhuman qualities of cognitive labor (though: not necessarily via dangerous superintelligent agents).[8] And unless we get very lucky, I think attempting to tackle the full alignment problem without serious help from AIs is a loser’s game.
In this sense, I am talking, here, centrally about a particular “end goal,” and not about the path to getting there.[9] And it’s not, even, the only viable “end goal.” That is, as I discussed in my last post, it’s possible that the right strategy, even in the longer term, is either to “avoid” the alignment problem by not building superintelligent AI agents at all (but hopefully getting access to the benefits of superintelligence in some other way); to “handle but not solve” the alignment problem by building superintelligent AI agents but not fully eliciting their capabilities (and again, hopefully getting access to the benefits of the un-elicited capabilities via other means); or, indeed, to give up on some of the benefits of superintelligence for the sake of safety. And even if our aim is to fully solve the problem in the longer term, these other strategies might be a better near-term focus.
Still, I personally think it’s worth trying to have as direct a grip as we can, now, on the object-level issues at stake in fully solving the problem, and on the available approaches to addressing those issues. Or at least, I want this as part of my own aspiration to think clearly about existential risk from misaligned AI; and I expect it to be useful to others as well.
In particular, absent this kind of direct engagement, I think we risk talking overmuch about some undifferentiated “alignment problem,” which we plan to point our AIs at at some future date, without a clear enough sense of things like:
- what we are going to be trying to get these AIs to do (cf, for example, the difference between “get the AIs to help us with blah type of oversight” vs. “get the AIs to come up with some new breakthrough that ‘solves alignment’”),
- how much of what sort of trust we will need to have in these AIs and/or their output,
- how we will tell if they have succeeded (if, indeed, we will be able to tell),
- how difficult to expect the task to be,
- and whether we need to instead be prioritizing more radical alternatives.
What’s more, many of the issues and approaches I’ll discuss in the context of superintelligent AI agents apply in a similar way to merely human-level-ish or somewhat-superhuman AI agents of the kind we will plausibly need in order to get the sort of help from AIs that I think we should be looking for. So I’m hopeful that the discussion will be useful in thinking about aligning less powerful systems as well – and I’m hoping to reference it in that context in future.
Preliminaries re: avoiding takeover
OK, back to the full alignment problem – and in particular, to avoiding takeover.
We’re assuming that we’re building superintelligent AI agents. What’s required to ensure that they don’t take over (in a context where we are also trying to elicit their beneficial capabilities)?
The ontology I’m using
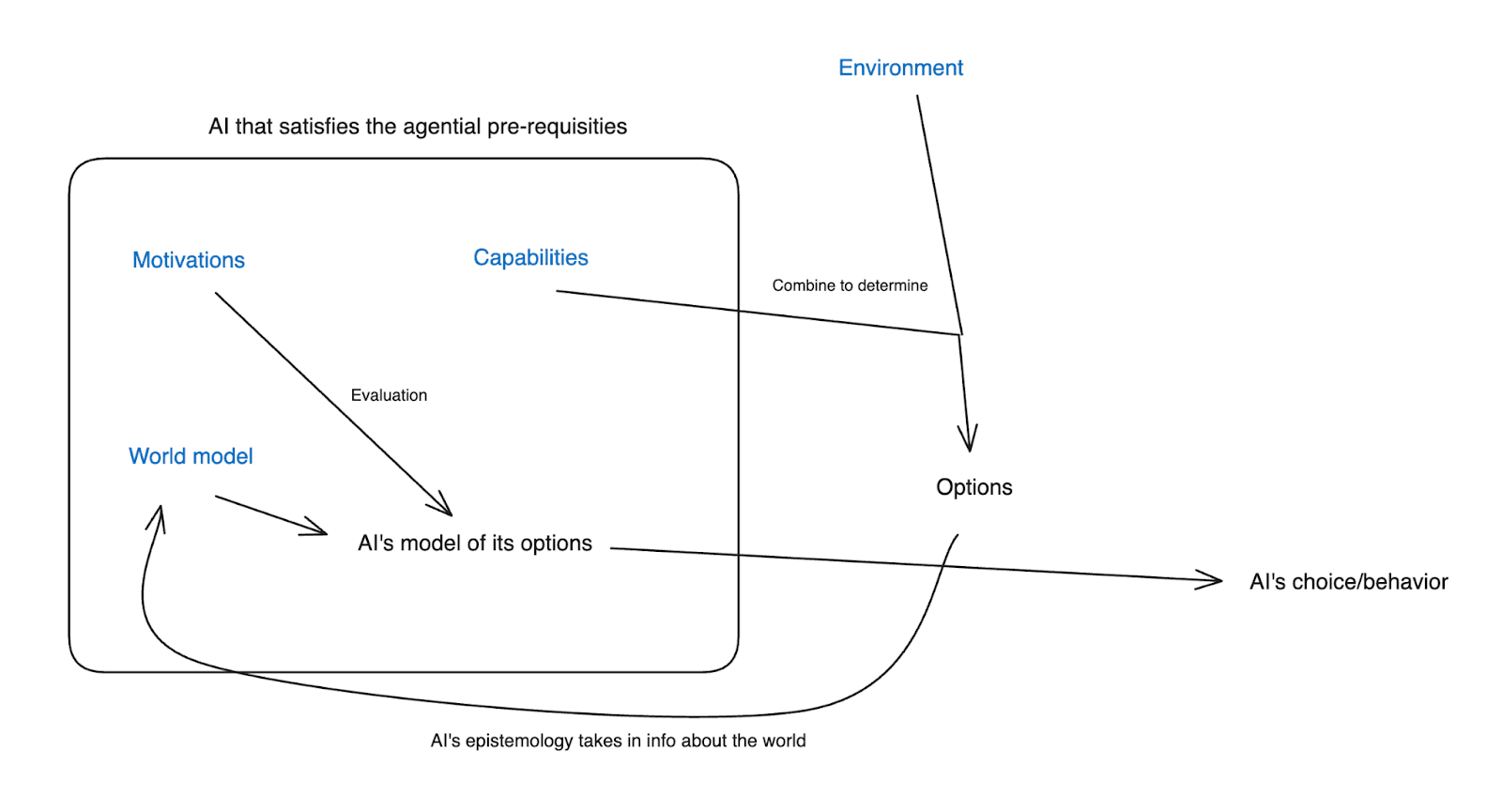
To get at this question, I want to first briefly lay out the ontology I’m using for thinking about a superintelligent AI agent. Basically, there are four key components:
- The AI’s environment
- The AI’s capabilities
- The AI’s motivations
- The AI’s world model
(Note: this ontology loads heavily on the fact that we’re assuming that the AI in question satisfies the agential pre-requisites I discuss here – i.e., that its making plans on the basis of models of a situationally-aware model of the world, evaluating those plans according to criteria, having its behavior driven coherently by these plans, etc. I’m not saying that all ML systems, or all intelligences, are well understood in this way. But I think the paradigm systems that we’re worried about from an alignment perspective are.)
Roughly speaking, the AI’s environment and its capabilities combine to produce its options – that is, what will actually happen if the AI does different things. The AI’s world model has a model of those options, including their predicted consequences. The AI’s motivations then evaluate those options using the AI’s model of them, and then the AI chooses its behavior on the basis of this evaluation.
Here’s a rough diagram, with the four fundamental components in blue:
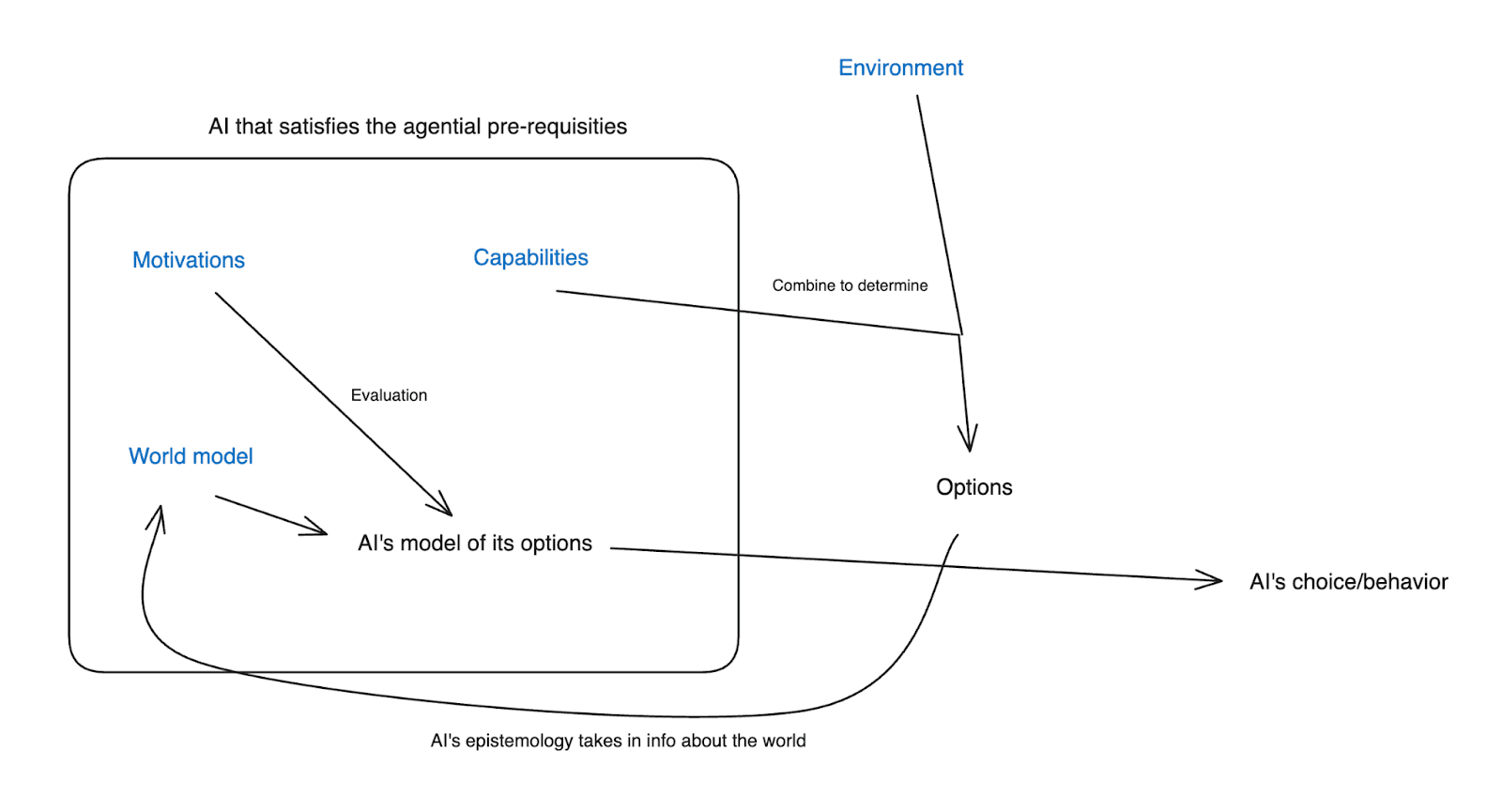
Unless I specify otherwise, I’m also generally going to assume, at least to start, that the AI’s world model is reasonably accurate – and in particular, that its model of its options reflects with reasonable accuracy the true nature of its options and their consequences. This is an attempt to respect the degree of situational awareness (and intelligence more generally) we are assuming our AI agent has. Plus, it simplifies the discussion. That said, various of the approaches I discuss do involve attempting to mess with the accuracy of the AI’s world model.
A spectrum of motivation control and option control
If we set aside attempts to intervene on the AI’s world model, this leaves, roughly, three variables that combine to determine whether our AI attempts to take over: namely, its capabilities, its environment, and its motivations.[10]
I’ll further subdivide approaches to avoiding takeover according to a spectrum of: how much do they focus on ensuring that the options available to an AI have certain properties (where, per the diagram above, an agent’s options are determined by the combination of its capabilities and its environment), vs. how much do they focus on the AI’s motivations having certain properties. I’ll call the former focus “option control,” and the latter focus “motivation control.” Thus:
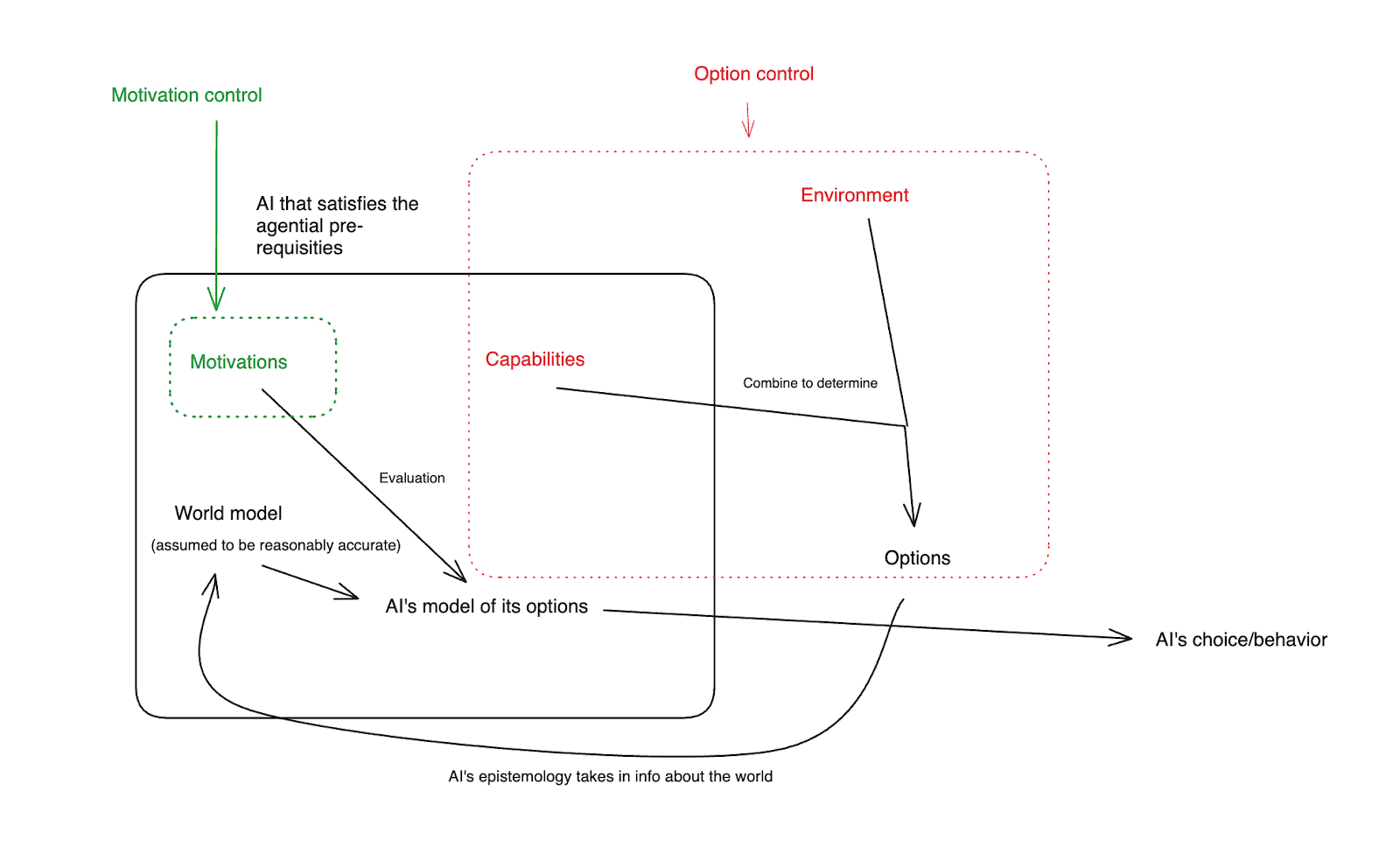
The limiting case of option control aims at ensuring no takeover in a manner robust to the AI having arbitrarily bad motivations. And the limiting case of motivation control aims at ensuring no takeover (or at least, no bad takeover) even if the AI has arbitrary options available – including options that involve improving its own capabilities radically. But I think it’s important not to miss the large intermediate space in between, in which an AI not taking over results from a combination of its motivations and its options. Indeed: at least with respect to more mundane bad actions, this is how we often achieve “alignment” between different humans. For example, an employee likely has some intrinsic motivations that make them averse to stealing from their employer; but the employer also takes some steps to make stealing difficult, and we take additional steps to ensure that the incentive landscape makes it undesirable.
Thus, in a diagram:
(Though: this diagram is a bit misleading, in that it seems to suggest that the central approach to “option control” is to limit the takeover paths that the AI has available, when in fact a more diverse range of interventions are available – i.e., rewarding the AI for cooperative behavior. More below.)
To see this distinction at work in practice, let’s consider its application to the framework for thinking about AI power-seeking I offered in a previous post.
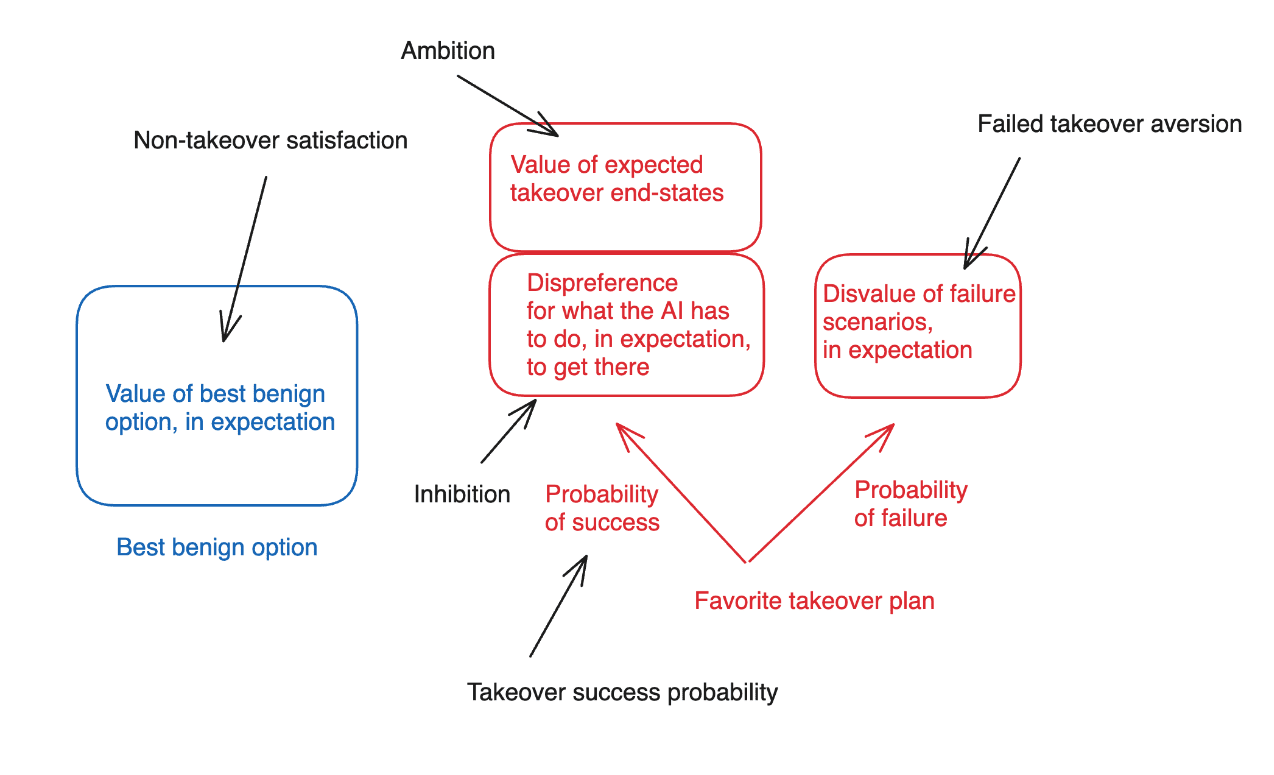
Here, we can think of option control as holding fixed the AI’s motivations – that is, the criteria it will use to evaluate different plans – but trying to intervene on its options to ensure that its best benign option is more desirable than its favorite takeover plan. Possibilities for doing this (discussed in more detail below) include:
- Lowering the probability of success for any takeover plan (and in the limit, making it the case that no takeover plan has any reasonable probability of success).
- Improving the empirical nature of the best benign option, such that it is more desirable by the lights of AI’s motivations (see here for an example discussion of this approach).
- Changing the AI’s circumstances/capabilities such that its favorite takeover plan would require violating more of the AI’s inhibitions.
- Altering the outcomes that would result in expectation from success at the favorite takeover plan, such that they are less desirable by the AI’s lights – for example, because they result in less power for the AI.
Making the empirical nature of the scenarios in which the AI tries and fails to take over less desirable by the lights of the AI’s motivations.[11]
Conversely, we can think of motivation control as holding fixed the AI’s options, but trying to intervene on the criteria the AI uses to evaluate those options, such that the AI views the best benign option as more desirable than its favorite takeover plan. Possibilities for doing this:
- Changing the AI’s motivations so that it is happier with the best benign option.
- Increasing the strength and robustness of an AI’s inhibitions, such that it would be more reluctant to do various things that taking over would require.
- Changing the AI’s level of ambition such that it is less interested in the power that successful takeover would grant – and perhaps, such that it is intrinsically averse to such power, regardless of the path it took to get it.
- Increasing the extent to which the AI’s motivations would view unsuccessful takeover as undesirable, even while holding fixed the empirical nature of what unsuccessful takeover would involve.
Per the ontology above, an agent’s options are determined by its capabilities and its environment, so option control can be further subdivided into capability control and environmental control. A few notes on this:
- In the context of solving the alignment problem as I’ve defined it, the possibilities for capability control are at least somewhat constrained, because our task is to build a full-blown superintelligent agent that doesn’t take over (and also: to elicit its capabilities enough to get access to most of their benefits). However, even within the constraints implied by “full blown superintelligence,” there may be room for variation in the capabilities at play, and thus, for forms of capability control to enter into attempts at option control.
- Note, further, that an agent’s “environment” in principle implicates the entire state of the world, and not just e.g. the immediate context in which the AI is operating. Thus, for example, it counts as a form of “environmental control” – and thus, as a form of option control – if you improve our political processes such that the world is more likely to respond quickly and effectively to a rogue AI that escapes a data-center.
Also, and importantly, not all forms of environmental control need to implicate the sorts of freedom restrictions and potentially-coercive relationship that the word “control” can conjure. Thus, for example, as I noted above, creating a just and happy default situation for our AIs can itself count as “environmental control” in the relevant sense – i.e., it improves the empirical nature of the best benign alternative.[12]
Finally, I’ll note that certain sorts of approaches to AI safety retain a kind of agnosticism about whether they are doing motivation control or option control.
- Consider, for example, a “Guaranteed Safe AI” approach that aspires to take in some formal specification of an AI’s environment (capturing all the safety-relevant features of the real-world), along with some formal specification of safety, and then to provide some quantitative guarantee that a given AI will be safe in the relevant environment.
- Described at this level of generality, such an approach skips over the distinction between option control and motivation control, and cuts straight to just guaranteeing safety.
If you can do this: great.[13] Ultimately, though, if the AI in question is a superintelligent agent, I think you will need to have done some combination of controlling its options (or at least, its perceived options) and/or its motivations, even if you aren’t saying how.
Incentive structure safety cases
Here’s one way of thinking about ways option control and motivation control can combine to produce an AI agent that doesn’t choose a takeover option. I’ll call it an “incentive structure safety case.”
Here I’m borrowing some of the vibe from Hubinger’s “How do we become confident in the safety of a machine learning system?” but with a few modifications. Broadly speaking, Hubinger suggests that efforts to create safe machine learning systems should come with a “training story” about why the way you’re training this system will result in the relevant kind of safety. He further breaks down training stories into:
- Training goals: what sort of mechanistic algorithm you want your model to learn (the “training goal specification”), and why its learning that algorithm is safe and desirable (the “training goal desirability”).
- Training rationales: why you believe that your training process will result in an AI that implements this algorithm.
- Hubinger further breaks this down into “training rationale constraints” – roughly, why it’s at least consistent with everything we know for the model to learn this algorithm via this training – and “training rationale nudges” – roughly, why we should expect the model to learn this algorithm in particular, relative to all the others that would be consistent with everything we know.
This seems like a potentially useful breakdown, but I’m going to modify it a bit. In particular:
- I’m here interested specifically in AIs that satisfy the agential pre-requisites I described above, so the algorithm we’re aiming for needs to have that structure.
I don’t want to assume that our story about safety rests entirely on the algorithm that the AI is implementing, or on its internal properties more broadly. Rather, I want to also leave room for its environment to play a key role.[14]
- I don’t want to assume that our approach to ensuring that our goals are satisfied proceed centrally via the sorts of techniques paradigmatic of machine learning.
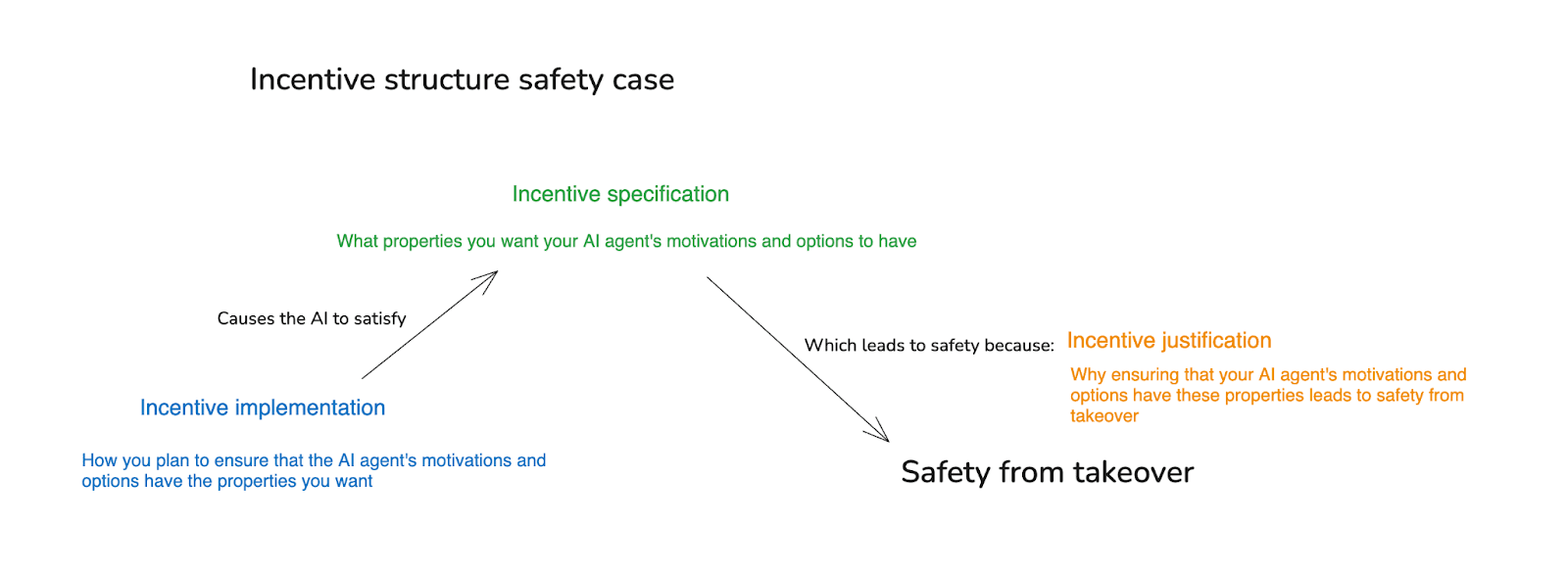
So, here’s a modified version, focused specifically on the way that option control and motivation control combine to produce safety from takeover. There are three parts:
- The incentive specification: what properties you’re aiming to ensure that your AI’s motivations and options have.
- The incentive justification: why you believe that ensuring these properties will ensure safety from takeover.
- The incentive implementation: how you plan to ensure that the AI’s motivations and options have these properties.
- At least in some contexts, especially ML-ish contexts, I think it is indeed useful to break down incentive implementation according to Hubinger’s distinction between “constraints” and “nudges,” as I think it’s often useful to explicitly highlight the sense in which your approach to implementation needs to be not only compatible with your incentive specification, but also such as to sufficiently privilege your incentive specification over all the other possibilities. But I won’t focus on this distinction here.
Thus, in a diagram:

Thus, here are some heavily abbreviated examples of incentive structure safety cases. I’m not saying they’re good. But hopefully they give a flavor of the structure.
An example of a heavily “option control”-focused incentive structure story would be something like:
- Incentive specification:
- Desired properties of the AI’s motivations: none required.
- Desired properties of the AI’s options: the AI can’t take over even if it tries.
- Incentive justification: Can’t take over → won’t take over.
- Incentive implementation: We think we can elicit its capabilities fully in a toy takeover environment and show that it can’t take-over in that environment. And we think that if it can’t take over in that environment, it can’t take over period.
A (somewhat silly) example of a more heavily “motivation control”-focused incentive structure story would be something like this.
- Incentive specification:
- Desired properties of the AI’s motivations: The AI has an extremely strong inhibition against lying.
- Desired properties of the AI’s options: Before we let the AI do anything, we’re going to ask it: “are you trying to take over?” and shut it down if it says yes. Also, it won’t be able to do anything if we don’t let it.
- Incentive justification: we think that the AI will always know that it’s trying to takeover when it’s doing so; that we’ll be asking with sufficient frequency; that the strength of the inhibition against lying will be such that it’s never outweighed, including by e.g. instrumental incentives to not get shut down; that the internal structure of the AI’s inhibition will continue to apply to the specific sort of lying at stake in responses to our questions …
- Incentive implementation:
- Option control: The AI is only going to be operating in our lab. It won’t be able to escape; it’ll never get stolen; and we’ll always implement the “are you trying to take over” process above.
- Motivation control: We’re going to try to get the AI to lie in a bunch of different toy situations and then train it to not do that using gradient descent. We think this will generalize to an extremely strong inhibition against the sort of lying we have in mind, because [insert better scientific understanding of ML generalization].
To be clear: I’m not sure ultimately how useful this kind of “incentive structure safety case” frame will be,[15] I don’t lean on it heavily in what follows, and I think the question of “what makes a safety case adequate in the context of an advanced AI system, especially once we’re leaning on some component of motivation control in particular” deserves much more attention than I’ve given it here. Still, even as a preliminary gesture, I like the way this framework highlights the need to talk about how an advanced AI agent’s options and motivations combine to produce safety (if, indeed, the motivations are playing a role). And it points at the fact that even fairly high degrees of control over the properties of an AI’s motivations (i.e., the sort of control at stake in e.g. being able to write a constitution or model spec that an AI will follow in a common-sensical way) isn’t yet enough on its own.
Here, I’m most going to focus on what possibilities are available for attempting to ensure that our AI’s motivations and options have any specific set of properties, period – that is, roughly, what sort of toolkit incentive implementation would be able to draw on. But I’ll return to incentive specifications and justifications a bit at the end.
Carving up the space of approaches to motivation and option control
Ok: what sorts of approaches are available to ensuring that our AI’s motivations and options have some desired set of properties?
To get an initial grip on the space of possibilities here, recall the ontology I gave above:
Internal vs. external variables
We can divide the variables here into two rough categories: what I’ll call “external” and “internal.”
- External variables are in some sense “outside” the AI. Here, the main examples I have in mind are the AI’s environment, and its behavior.
- Internal variables, by contrast, are in some sense “internal” to the AI. Here, the main examples I have in mind are the AI’s motivations, its capabilities, and its world model.
(The AI’s “options,” here, emerge as a product of an internal variable – namely, the AI’s capabilities – and an external variable – namely, its environment.)
Thus, in a diagram:
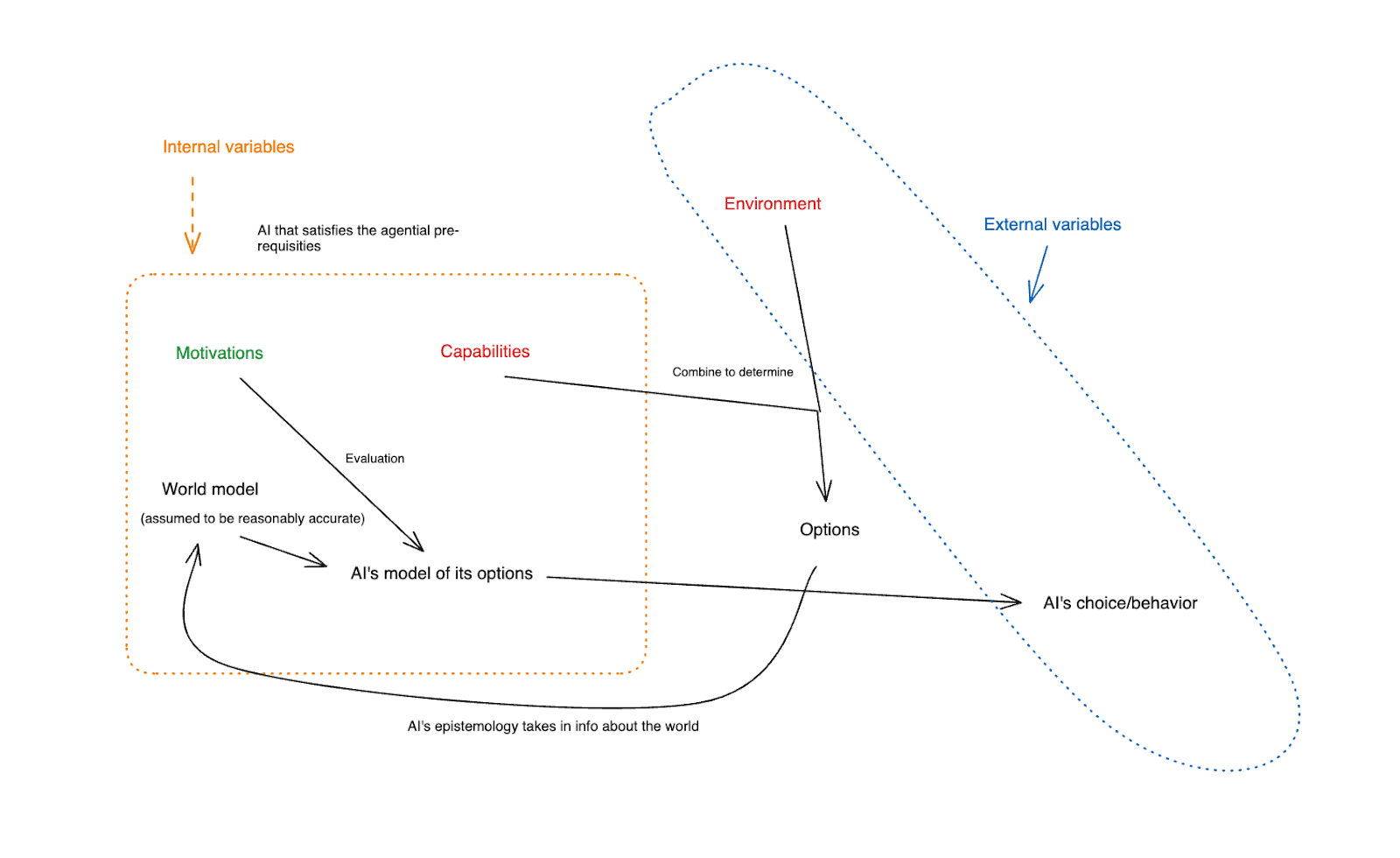
As ever, this distinction is quite rough and ready – and if it gets too cumbersome, we don’t need to hold onto it. But it will be useful in thinking through some of the options I discuss in future posts, especially in the context of AI systems that remain, in various ways, “black boxes” – since the internal variables, roughly speaking, are ones inside the black box.
Note, though, that not all AI agents, even in the current paradigm, are black boxes of this kind. In particular: even if certain components of an AI’s agency remain black boxes, it can still be the case that the structure of the AI’s agency as a whole makes the variables I’ve labeled “internal” – e.g., its motivations, capabilities, and world model – transparent to at least some extent. An example of this might be: if the AI’s agency (in the sense that satisfies the agential prerequisites) is occurring centrally in the context of a human-interpretable scaffold or chain of thought that accurately represents its planning/reasoning (see my discussion of “open agency” in the next post), rather than in the context of an opaque forward pass.
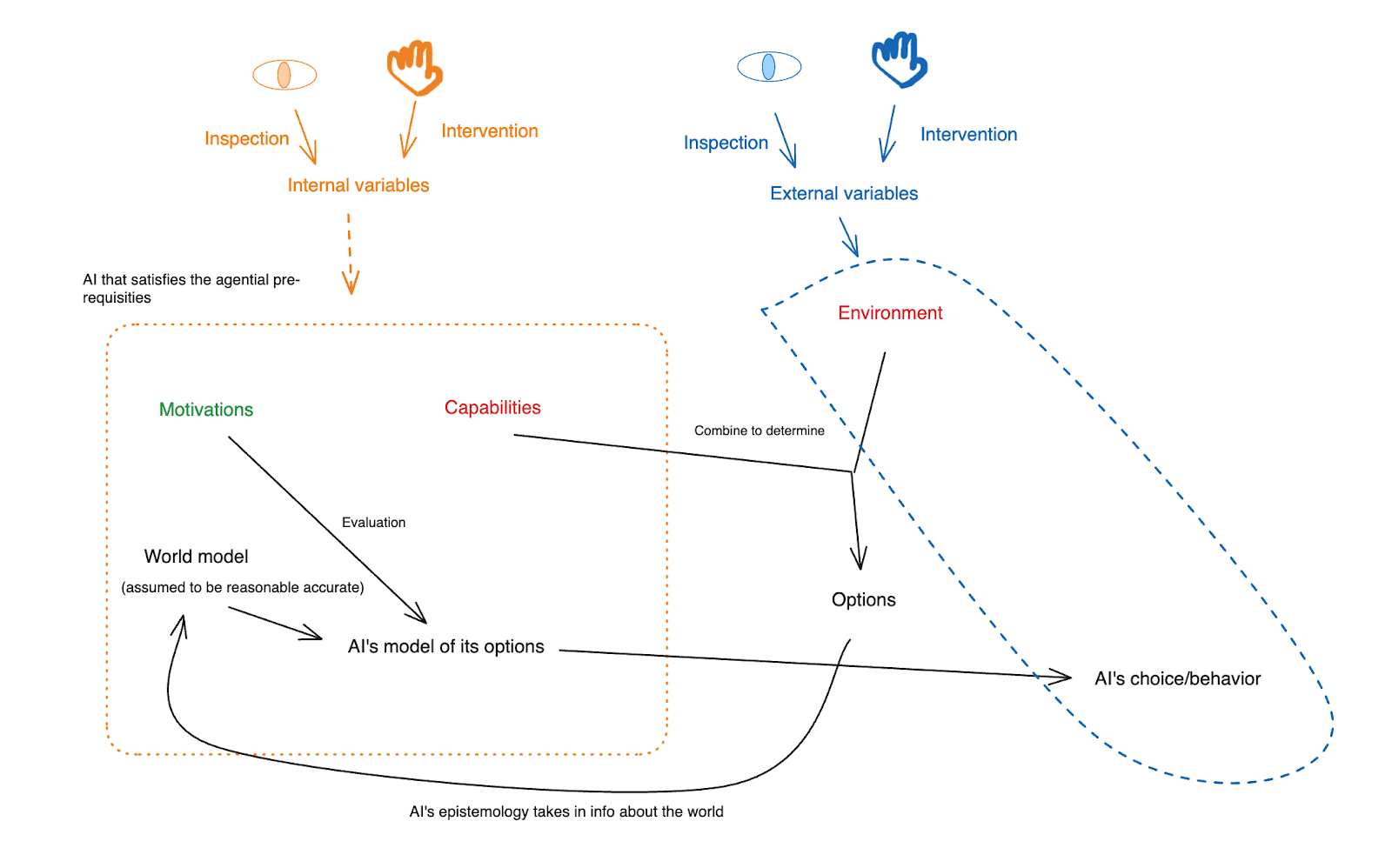
Inspection vs. intervention
I want to further distinguish between two ways of relating to a given variable or set of variables: “inspection” and “intervention.”
- “Inspection,” roughly speaking, indicates an epistemic relationship – one of investigation, understanding, and evaluation.
- “Intervention,” by contrast, indicates an attempt to actively modify one of the variables in question – whether as a direct attempt to control that variable, or as an indirect attempt to control some other variable correlated with this variable.[16]
We can apply (or attempt to apply) both inspection and intervention to both internal and external variables. Thus:
- For inspection:
- Examples of inspection on external variables would include:
- human evaluator rating an instance of AI behavior as part of RLHF training (behavioral inspection),
- a security team at the lab checking how easy it would be for a rogue AI to hack out of a given server (environmental inspection).
- Examples of inspection on internal variables would include:
- interpretability work trying to understand the algorithm the AI implements when it adds two numbers (probably best understood as capability inspection?).
- reading the chain of thought of a scaffolded agent (this could provide info about a variety of internal variables).
- Examples of inspection on external variables would include:
- For intervention:
- Examples of intervention on external variables would include:
- updating the AI’s weights so that it behaves in the higher-reward way on a given input (behavioral intervention),
- strengthening the lab’s cybersecurity to make it harder for an AI to hack a given server (environmental intervention).
- Examples of intervention on internal variables would include:
- intervening directly on an AI’s world model to make it think that the Eiffel Tower is in Rome (world model intervention);
upweighting some of Claude’s internal activations to make it obsessed with the Golden Gate bridge (~kinda like a motivational intervention);[17]
- writing down a different goal as a prompt in the context of a scaffolded agent you’re confident is planning in pursuit of the goal in the prompt (motivational intervention).
- Examples of intervention on external variables would include:
I’ll put this in the diagram as well, indicating inspection with a badly-drawn eye icon, and intervention with a badly-drawn hand icon.
AI-assisted improvements
Finally, I want to note the possibility of using AI labor, and/of the fruits of AI labor (i.e., new AI-created technologies, new forms of economic abundance), to become able to do a given type of inspection or intervention much more effectively/efficiently than we can do it today. I’ll call this an “AI-assisted improvement.”
As I noted above, I think that getting various kinds of assistance from AI systems is likely to be a crucial aspect of any viable approach to aligning a superintelligence. In future, I’m planning to write more about some of the dynamics at stake. But the topic will come up often enough, here, that I think it’s worth a few preliminary comments.
First: people often talk about “automating alignment research”; but the “AI-assisted improvements” I have in mind here cover a broader space. That is, roughly speaking, “alignment research” refers most centrally to the sort of cognitive labor that e.g. humans on technical AI safety teams at AI labs are doing – i.e., thinking about alignment, designing experiments that will shed light on specific issues, implementing those experiments, interpreting them, communicating about the results, and so on. I do think we want AI assistance with this sort of thing – but I think it’s worth emphasizing just how much of what we might want AIs to help with isn’t of this flavor. For example, in the context of different techniques for getting high quality feedback and oversight for AI behavior, the AIs are functioning less as the analogs of alignment researchers, and more as the (more sophisticated) analogs of the human raters tasked with providing data to a preference model.[18] And in the context of techniques I’ll discuss in future posts for hardening an AI’s environment, the AIs are acting more like e.g. cybersecurity researchers and white-hat hackers than alignment researchers.
Second, and relatedly, plans for using AI-assistance to improve our approaches to the alignment problem come on a spectrum of “executability,” where “executable” means something like “we basically know how we would do this, even if we don’t have the required resources yet,” and “not-yet-executable” indicates something more like: we’re hand-waving about some hoped-for improvement in our ability to do something, but we’re very far from knowing what we’d actually do to achieve this.
- Thus: “give our human evaluators access to the latest AI personal assistant” is an executable form of amplification. And I think various more intense schemes for scalable oversight – e.g., amplification and distillation, debate, recursive reward modeling, etc – are at least fairly “executable” in the sense of: we know what the process would be for implementing them (even if we’re not yet sure of what the results of implementing the process would be). Below I often focus on AI assistance that is comparatively “executable” in this sense.
- Whereas my sense is that various hoped-for improvements in our interpretability techniques would fall into the bucket of “not-yet-executable.” And same for various proposals that involve formally verifying that our AIs have various safety properties.
Third: I think there is often a background concern, in the context of any proposal that involves utilizing AI labor to help align an AI, that the proposal in question will rest on some problematic circularity. That is, the thought is something like: if the issue you’re trying to solve is that you don’t trust AI_1, and you want AI_2 to help you with that, don’t you need to trust AI_2? And so, don’t you need to have already solved the “how to build an AI you trust” problem? But I think there are a wide variety of options for avoiding problematic types of circularity here. In particular:
- AI_2 can be the sort of AI that does not satisfy the “agential prerequisites” and/or the “goal content” prerequisites that I discuss here, such that questions about the sort of “misalignment” that leads to it pursuing takeover don’t arise.
- I.e., AI_2 can be some combination of: not capable of planning, not driven coherently by its planning, not situationally aware, not consequentialist, focused only on myopic goals, etc.
- Even if AI_2 is the sort of AI that raises questions about takeover-relevant misalignment, we might be in a position to trust that AI_2 isn’t pursuing takeover on grounds that don’t apply to AI_1 – i.e., AI_2 might have weaker/more limited capabilities, it might be in a different environment than AI_1, it might be given a very different task than AI_1, it might have been trained in a very different way, etc.
- Even if we can’t be confident that AI_2 isn’t pursuing takeover, such that we don’t “trust” AI_2 itself, we still might be in a position to trust the quality of AI_2’s output – for example, because we can evaluate that output via some other trusted process, because we’re confident that our training process/incentive-structure causes AI_2 to give the output we want in this case, etc.
- Thus, for example, even “scheming” models will often be doing their tasks in the desired way (even if not: for the desired reasons).
- In general, I expect that leaning hard on a distinction between “trusted” and “untrusted” models to mislead, because I think that “trust” should generally be relative to a set of options. I.e., you trust your employees in circumstances roughly like their current circumstances; but you wouldn’t necessarily trust them to be dictators-of-the-universe.
- I also think it’s at least conceptually possible for both AI_1 and AI_2 to be trusted to the same degree, and for their labor to still be playing an important role in securing against takeover attempts by the other. I.e., in principle you could be sending AI_1s output to AI_2 to evaluate/oversee; and if you can do things like prevent collusion between the two of them, while also suitably eliciting their capabilities, there doesn’t need to be problematic circularity there. Indeed, this can work even if AI_2 is just another copy of AI_1.
Fourth, and relatedly: at times in what follows, I will specifically talk about the need for superhuman qualities of cognitive labor to be used in some approach to controlling the motivations and/or options of a superintelligent agent AI_1. But this doesn’t mean that getting access to that sort of cognitive labor requires another superintelligent AI agent, AI_2, with a capability profile and general dangerous-ness level comparable to AI_1. Or at least, this isn’t implied at a conceptual level. Rather, at least conceptually, there is an available possibility of bootstrapping to a given quality of superhuman cognitive labor – including the sort of superhuman cognitive labor that AI_1 can paradigmatically engage in – using AI systems that are less capable, agentic, etc than AI_1 itself (and thus, AI systems whose output is easier to trust). Some available techniques for this, using some AI_2 that is some combination of weaker/less dangerous than AI_1, include: using many copies of AI_2 to perform the task (including e.g. having them debate the issue, having them work on different components of the task, etc), running AI_2 for a longer time, incorporating humans and/or other trusted AIs into the process, etc.
Indeed, a lot of work done under the heading of “scalable oversight” falls roughly under the heading of “how do we bootstrap to superhuman qualities of oversight/feedback using components that are less dangerous than the thing we’re trying to oversee/provide feedback on.” I’m relatively optimistic that this sort of bootstrapping is possible, and I generally expect success in this regard to be extremely important.[19]
Now, one way this sort of bootstrapping could fail would be if there are certain kinds of superhuman task-performance that are qualitatively out of reach of even-somewhat-weaker systems. I.e., if there are tasks such that an AI of “IQ 1000” can do it, but no number of IQ 999 AI systems can do it even with much larger amounts of time and resources.
- In favor of hard barriers of this kind, you can point to cases like “could any number of 8 year olds really invent relativity, even given extremely large amounts of time? What about: any number of mice?” and “when it was Kasparov vs. the world, Kasparov won” (though: according to Wikipedia, Kasparov also wrote that he “had never expended as much effort on any other game in his life”; and apparently he had the benefit of reading-along with the online commentary from the world team).
- One response to the mice/8-year-olds case is to posit some specific level of intelligence after which the hard barriers disappear. I.e., some level between mice/8-year-olds and… human adults? Though this can feel quite arbitrary.
Against hard barriers of this kind, you can point to arguments like “positing hard barriers of this kind requires saying that there are some very small differences in intelligence that make the crucial difference between being able vs. unable to do the task in principle. Otherwise, e.g., if a sufficient number of IQ 100 agents with sufficient time can do anything that an IQ 101 agent can do, and a sufficient number of IQ 101 agents with sufficient time can do anything an IQ 102 agent can do, etc, then by transitivity you end up saying that a sufficient number of IQ 100 agents with sufficient time can do anything an IQ 1000 agent can do. So to block this sort of transition, there needs to be at least one specific point where the relevant transition gets blocked, such that e.g. there is something that an IQ X agent can do that no number of IQ X-minus-epsilon agent cannot. And can epsilon really make that much of a difference?”[20]
Though: note that this sort of argument also seems to imply that a sufficient number of mice, with sufficient time, should be able to invent general relativity, which seems wrong.
(Note: we need to exclude cheatsy cases like “organize all the mice into a turing machine that computes a superintelligence” and “the mice just flail around until they hit on the answer.” I think we can probably find a reasonably principled way to exclude such cases, though.)
Note, though, that even if you don’t think that some number of IQ 999 AIs with sufficient time can match the cognition performance of an IQ 1000 AI, you can still get additional juice, from the perspective of scalable oversight, from the difference in difficulty between evaluation and generation. I.e., maybe the large team of IQ 999 AIs can at least evaluate the output of an IQ 1000 AI to a sufficient degree.
Conversely, though: even if you’re optimistic in principle about large amounts of slightly-weaker AI labor substituting for slightly-better AI labor, in practice you can still quickly hit quantitative barriers (see Shlegeris here for some more discussion). For example: maybe enough humans could in principle evaluate something given enough time; but you definitely don’t have enough humans, or enough time (though cases with different types of AIs might be easier here, because it’s easier to copy the helper AIs, run them faster, etc).
In general, I’m not going to here try to dig in deeply on what sorts of AI assistance to expect to be what sorts of feasible. I do, though, want to make sure that certain kinds of people don’t immediately bounce off of any reference to using AIs to help with this problem on grounds like “in order to do that you would’ve already needed to solve the problem in question.” Maybe, ultimately, objections like that will bite fatally – but much more needs to be said.
I’ll denote the possibility of getting significant AI help with various option/motivation control approaches with a “plus” sign on the diagram. Thus:
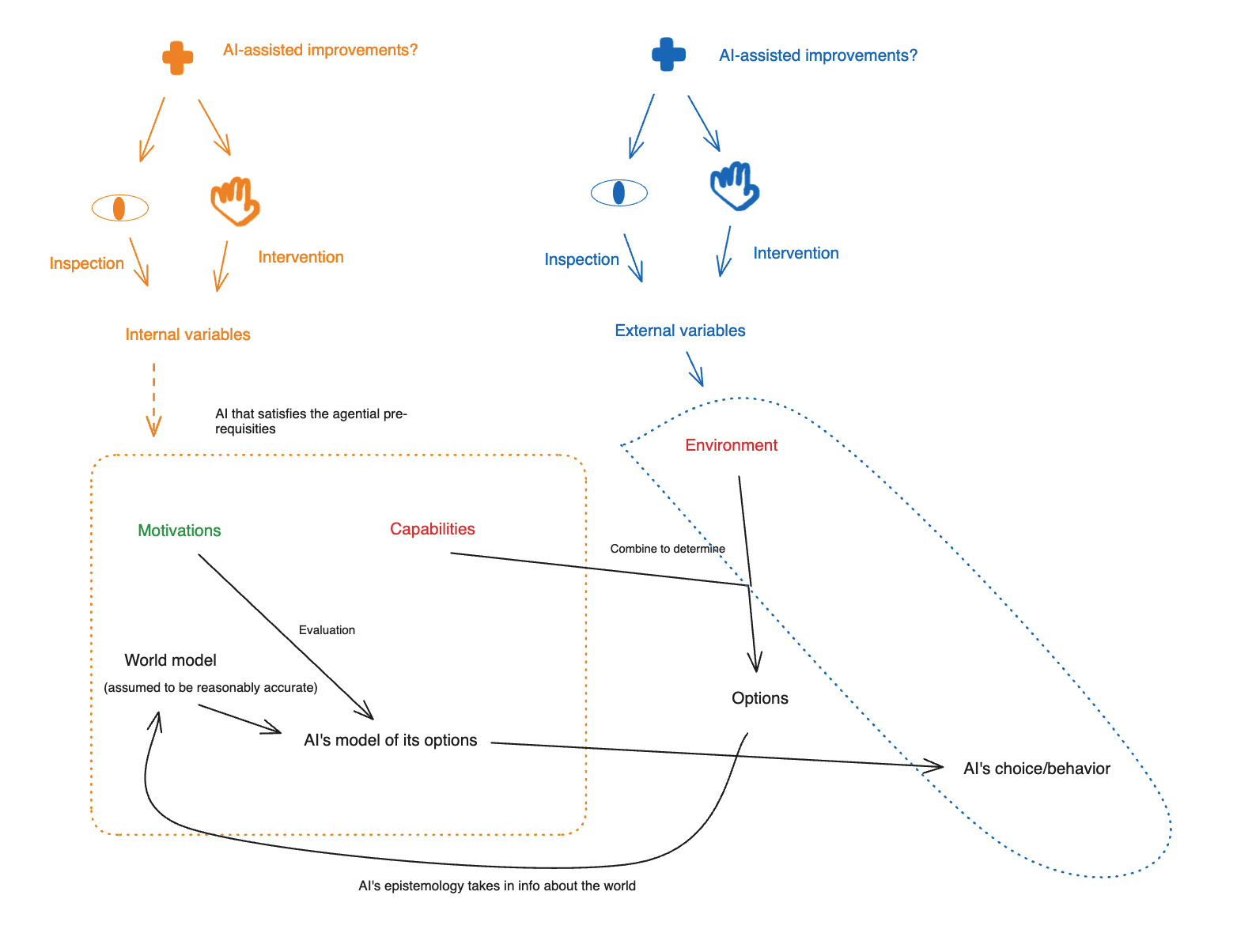
OK: that was some initial set-up for how I’m thinking about the space of possible approaches to motivation control and option control. In the next post, I’ll move on to the approaches themselves, starting with motivation control.
Acknowledgements; I've benefitted from discussion about the issues in this series with tons of people over the years, but thanks especially to Ryan Greenblatt, Buck Shlegeris, Paul Christiano, Evan Hubinger, Collin Burns, Richard Ngo, Holden Karnofsky, Nick Beckstead, Daniel Kokotajlo, Ajeya Cotra, Tom Davidson, Owen Cotton-Barratt, Nate Soares, Lukas Finnveden, and Carl Shulman. The section on “Takeover-path restriction” draws heavily on work from Redwood Research, and the section on “Rewarding cooperation” draws heavily on unpublished work from Buck Shlegeris, Daniel Kokotajlo, Tom Davidson, and especially Lukas Finnveden.
- ^
Indeed, if we don’t have this kind of help by the time we’re building full-blown superintelligence, then various of the approaches I consider here, especially under the heading of “option control,” are not viable.
- ^
My last post calls it “avoiding the problem” if you don’t build superintelligent agents at all, and “handling but not solving the problem” if you build superintelligent agents, but don’t become able to elicit most of their beneficial capabilities.
- ^
Though: I do think it’s an open question what level of ambition it makes sense to have, re: identifying the best full solutions to the problem from our current position. And I’m most interested in informing our nearer-term orientation towards e.g. getting the AIs to help.
- ^
- ^
Including: all forms of AI takeover. That is, for the reasons I discuss here, I don’t discuss approaches that assume the AIs are going to take over, but try to make this non-bad.
- ^
Obviously, one can dispute this as a definition of "solving the alignment problem," and claim on these grounds that the series isn't pointed at the real problem. I wrote a long post defending this particular conception of the problem -- and I do actually think it's the right thing to focus on. But I don't think it's worth getting hung up on terminology here, so if you want, feel free to think of this as the alignment-problem_joe.
- ^
To be clear: as I discussed in my last post, I think the best futures may well be “run by AIs” in some sense. But I think we want to choose to transition to these sorts of futures after having solved the alignment problem in the sense at stake here, and with the benefit of e.g. superintelligent advice in doing so.
- ^
The nature and amount of trust you need to have in the AIs performing the labor is, in my opinion, a distinct question; and note that the AIs producing this labor, even in the context of aligning a superintelligent agents, do not, themselves, necessarily need to be superintelligent agents.
- ^
Though as I discussed in my last post, it’s not the most final goal – i.e., it’s not “have things go well in general,” nor even “become able to safely align AI agents that are as-intelligent-as-physically-possible.” That’s on purpose.
- ^
Another way of carving this up would be to think of interventions on capabilities, environment, and world model as all feeding into an AI’s model of its options. I think it’s possible this is better, and may use this framing in future work.
- ^
Though I think we need to be very careful here, on both ethical and prudential grounds.
- ^
See the section on “rewarding cooperation” below for more on this.
- ^
Can you, though?
- ^
Hubinger could in principle capture this in the context of “training goal desirability,” but I want the role of the environment to be more center stage.
- ^
In principle, for example, you can skip talk about the “incentive specification,” and instead try just go straight from ‘we’re going to do blah” to “therefore no takeover.”
- ^
I'll think of constructing an AI from the ground up to fit a certain specification as a case of "intervention." Admittedly, though, the connotations and possibilities at stake in constructing an AI from the ground up vs. altering an existing AI may be important -- for example, in the context of trying to prevent adversarial dynamics from ever arising, vs. trying to eliminate them once they've arisen. Thanks to Owen Cotton-Barratt for discussion here.
- ^
Note: at one level, you could view “updating the AI’s weights via SGD to make it behave in a higher reward way” and “upweighting an internal activation to make Claude behave like Golden-Gate Claude” as similar sorts of interventions – i.e., the thing you actually changed is internal to the AI, and the way you know you’ve succeeded is via behavioral inspection. The difference, in my head, is that it feels like updates via SGD are just directly selecting for behavior – e.g., making a given sort of output more likely. Whereas the Golden Gate Claude example is proceeding more centrally via some hypothesized (even if still quite incomplete) understanding of how the model’s internal cognition is working (i.e., understanding at the level of “this feature represents the golden gate bridge”). Admittedly, though, this distinction seems especially blurry. If I had to resolve it one way or another, I’d re-classify Golden Gate Claude as a behavioral intervention, and reserve “internal intervention” for cases where the degree of understanding and control over an internal variable is more confident and direct.
- ^
Indeed, AIs are already used for this purpose.
- ^
I may write more about this aspect in the future, but skipping for now.
- ^
One model, suggested to me by Owen Cotton-Barratt, would be that the threshold occurs at the point where your thinking is so unreliable that errors accumulate faster than you can check/eliminate them. On this model, minds just above the threshold might still be extremely inefficient at performing the relevant tasks, because they need to engage in such intensive processes of error-correction.