Acknowledgement Note:
This project was carried out as part of the “Carreras con Impacto” program during the 14-week mentorship phase. You can find more information about the program in this entry.
Summary
This research article analyzes the growing competition between the United States and China in the digital superpower arena, focusing on the evaluation of two prominent AI models: GLM and GPT. Through country-specific benchmarks, such as SuperGLUE and SuperCLUE, these models were compared in terms of academic performance and context length. In addition, predictions were made as to whether the gap between the two nations is narrowing.
1. The rise of Artificial Intelligence: the technological scenario and the competition between China and the US.
The United States and China are recognized worldwide as two digital superpowers. Although China’s progress was not initially as evident, in recent years it has experienced a remarkable surge, consolidating its position as the United States' main competitor in both commercial sector and national security implementation, particularly in the development and application of Artificial Intelligence (AI) (Hine & Floridi, 2024).
This scenario has significant implications for both national and international economies, as well as for the geopolitical sphere, since AI has current influence in numerous aspects of daily life, driven by globalization and rapid technological advancement over the past few years.
Until a few years ago, the gap between the United States - which leads in AI industries and investments - and China was quite large, leaving the US in a dominant position. However, as shown in Table 1, this gap appears to be narrowing, with the Western country continuing to excel in certain areas while the Eastern one outpaces it in others (Jorge & Anaheim University, 2020).
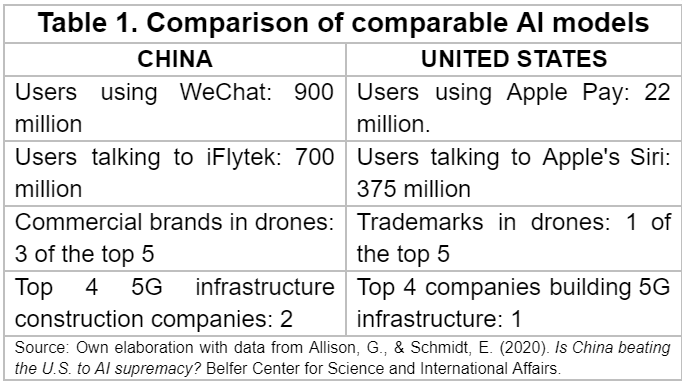
It is important to highlight that both nations have consistently demonstrated their commitment to remain leaders in the field. Authors such as Graham Allison and Eric Schmidt (2020) acknowledge the ongoing competitive race between these two technological powers, pointing out that China has made significant efforts to benefit from its geographic and population advantages, data collection capabilities and the strong national determination driven by the personal interest of the current president, Xi Jilping, in the innovation, research, development and implementation of AI. As a result, the gap between the two global powers has been decreasing considerably, with China filling more than 2.5 times the number of AI-related patents compared to the U.S. in 2018 alone.
Innovation from the Eastern country has prompted the United States to develop strategies aimed at maintaining its leadership in Artificial Intelligence. Starting with Donald Trump in 2018, U.S. presidents have consistently shown an interest in preserving this country’s advantage over others, particularly China, as reflected in Executive Order No. 13859, "Maintaining American Leadership in Artificial Intelligence". However, this was only the beginning of broader efforts to keep the AI gap as wide as possible and ensure the U.S. remains in the lead. In the years following the publication of the Executive Order, various measures were taken to block China as its main competitor, including several legislative acts such as the "Comply with the China Challenge Act of 2021", which encouraged the president to increase sanctions on the Eastern country to create "blocking points" for Chinese progress (Hine & Floridi, 2024).
In August 2022, under the leadership of President Biden, the White House issued the "CHIPS and Science Act", in which it is repeatedly stated the intention to compete and succeed in the emerging field. One of the Act’s main objectives is to counter China's role in AI development and innovation by cutting off the supply of chips and semiconductors, essential for the production of computational and language models. It is important to mention that despite being the inventor of semiconductors, the US produces only 10% of the global supply, with East Asia leading production, which is why this Act aims to invest in the domestic manufacture of these semiconductors, striving for independence and autonomy from other countries. The ultimate goal is to ensure that everything is produced within the US, eliminating reliance on foreign supply chains.
The U.S. strategy primarily focuses on innovation and development; but based on recent strategies, we could also say that it is simultaneously investing in counteracting the significant progress China has made since the launch of ChatGPT (White House, 2022).
In April 2023, the CPC party in China convened to discuss matters of economic relevance, underscoring the importance of promoting the development of General Artificial Inteligence (GAI) and its risk prevention. A month later, on May 25, 2023, the Beijing Government Gazette - issue 28 - published a statement detailing various measures to promote the innovative development of General AI in the region. These measures were implemented to accelerate the plan to build a globally influential AI innovation center between 2023 and 2025. The main recommendation was to leverage the computing power resources available in Beijing, as well as power supply, cloud, software and hardware. Additionally, a multi-cloud computing power scheduling platform was proposed to unify the operation and management of different computing power environments, making them accessible to other regions of China beyond Beijing. The advantages of size, data collection, and China's determination over the past decade have contributed to closing the gap with the United States (Allison & Schmidt, 2020).
Among the strategies employed by China is the development of evaluation models - also known as benchmarks - by non-profit organizations and private sector companies, designed for the continuous assessment of large language models (LLMs) created in the country. These benchmarks serve as a tool to measure the universality, evaluation, intelligence and robustness of the data, ensuring up-to-date improvements in AI in real time (Beijing Government Office, 2023). This need arises from the recognition of the differences between AI models in China and US, particularly due to factors such as the language, highlighting the necessity for "standardized" parameters to evaluate Chinese AI models according to their particularities.
As is apparent, some of the advantages mentioned before (Table 1) could be attributed to the difference in population size between China and the US, as suggested by the number of users engaging with the AI models of each country. This raises the question of whether the gap between the US and China is really narrowing, or if the differences remain significant enough to secure US leadership.
The implications of the AI race between the US and China being are economic, geopolitical, military and social. It is argue that "if a country invests heavily in this field, it will acquire technologies that will become the foundation of its defense capabilities and economic advantage for the rest of the century" (Savage, 2020).
In this sense, it was decided to select two LLMs for the current analysis, one from the US and the other from China, considering their comparability in terms of function and their status as some of the most advanced and/or prevalent AI models in each country. This allow us to compare them based on specific benchmarks, which will serve as standardized parameters to evaluate the performance and scalability of the competition between these two AI titans.
2. Choice of competitors and their evolution over time: ChatGPT-4 and ChatGLM-4.
2.1. Characteristics of LLMs and the selection process.
LLMs are large-scale, pre-trained, neural network-based statistical linguistic models. The concept of LLM mainly refer to neural linguistic models based on transformers containing tens to hundreds of billions of parameters, pre-trained on massive amounts of text data. LLMs are becoming the “building block” for the development of general - purpose AI agents, or artificial general intelligence (AGI) (Minaee et al., 2024). Unlike narrow AI, which is limited to specific tasks, AGI has the potential to perform any human task - and even surpass our capabilities (Bigley, 2023).
One of the most prominent AI models currently in the US is ChatGPT, developed by OpenAI, with several versions released so far, the most advanced being ChatGPT-4. This model is a leading competitor in performing general tasks and has had significant improvements in this version, making it more accessible to a broad range of users.
OpenAI, as the leading developer of LLMs in the United States, has been at the forefront of driving significant advancements in the innovation of these systems. Therefore, it is essential to analyze and compare the capabilities of this model with a counterpart in China that can compete with ChatGPT-4 in both relevance and technological capabilities.
From the literature review, several authors have emphasized that China has been rapidly developing LLM models in response to US restrictions intended to slow its progress in AI, with some models potentially comparable to ChatGPT. While there are several options within the Chinese AI ecosystem, the decision to focus on ChatGLM-4 is based on its prominent presence in several reviewed studies, highlighting its relevance and advancements compared to other Chinese models. Also, most Chinese LLM models lack the extensive benchmarking that ChatGPT has achieved, whereas ChatGLM not only demonstrates comparable capabilities in terms of its functions and scope but also represents a significant evolution from its earlier versions, making it a stronger competitor. On the top of that, ChatGLM-4 was developed by Tsinghua University in Beijing, which has been described by its creators as a "direct alternative" to ChatGPT, underscoring its intention to compete at the same technological and functional level as the US model.
The selection of these models was also based on the availability of information. Given the significance of the subject, new data is continuously emerging, with relevant updates that may prove critical to this study. Therefore, it was essential to choose models that are current, have broad capabilities and are innovative enough to remain competitive in the market. Since both models are updated versions of their predecessors, with enhanced capabilities and more parameters in their programming, they were suitable for this research.
Finally, it was important to consider the accessibility of information, especially with respect to the Chinese model, as it may represent a problem later on.
2.2. U.S. champion so far: ChatGPT-4.
2.2.1. Evolution from ChatGPT-1 to ChatGPT-4.
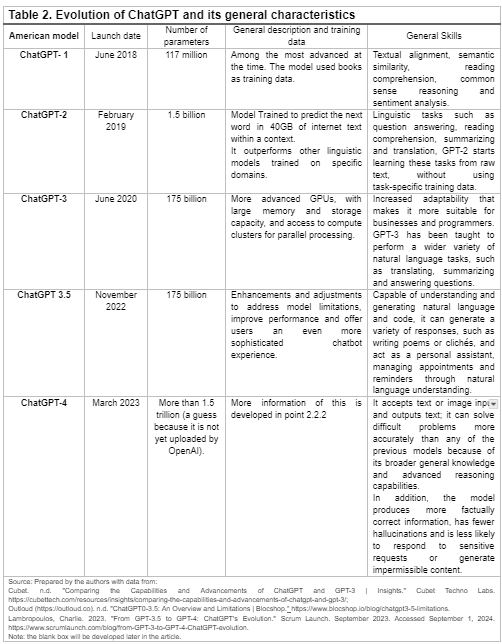
The GPT model is one of the most prominent examples where improvements made by the U.S. in large language models (LLMs) are easily observed. To better understand these advancements, a comparison between models and their progress is essential, focusing on key aspects such as release dates, the number of parameters used for training, the datasets involved, and the capabilities of each model iteration. The following table provides an overview of these factors (shown in Table 2).
2.2.2. Description of ChatGPT-4 and its configuration.
GPT-4 is an advanced multimodal model designed to process both text and image inputs and generate textual outputs. The main goal of this model is to enhance its ability to understand and generate natural language, particularly in complex scenarios requiring nuanced comprehension. To assess its capabilities, GPT-4 underwent a series of tests originally designed for humans, where it not only outperformed its predecessors, but also surpassed several AI specifically trained for those tests (OpenAI et al., 2024).
The GPT-4 training process involved predicting the next token in a document from a large database that included both publicly available data and data licensed from third parties. It was further refined through an approach known as “Reinforcement Learning from Human Feedback” (RLHF), which involves adjusting the model based on human-provided feedback, enhancing its ability to generate more useful and accurate responses (OpenAI et al., 2024).
In terms of academic performance, GPT-4 has proven to be superior than state-of-the-art (SOTA) models in seven out of eight evaluated benchmarks. Although it fell slightly bellow SOTA in specific tasks like reading comprehension and arithmetic (by less than 8 percentage points), its overall performance was outstanding. A notable example of its capabilities is its assessment on the MMLU benchmark, which measures the ability to answer both open and closed-ended questions across 57 different topics. GPT-4 surpassed the majority of AI models in all languages tested, including English (OpenAI et al., 2024).
This model represents a significant advancement in the field of artificial intelligence and remains a benchmark in the development of LLMs, demonstrating that the combination of multimodal processing and reinforcement learning can achieve unprecedented levels of performance on complex natural language tasks (OpenAI et al., 2024).
Regarding the evolution of the ChatGPT model, the latest version of GPT-4 stands out in evaluations of various categories (Table 2). However, issues such as "hallucinations," data limitations up until September, 2021 (although derived versions now include more recent data), and the inability to learn from experience still persist. Additionally, its simple reasoning does not always align with the high scores achieved in various benchmarks. Jailbreaks, which are adversarial prompts capable of bypass system restrictions, also remain an issue, though they have been reduced since the release of ChatGPT-3.5 (OpenAI et al., 2024).
However, issues such as "hallucinations," data limitations up until September, 2021 (although derived versions now include more recent data), and the inability to learn from experience still persist. Additionally, its simple reasoning does not always align with the high scores achieved in various benchmarks. Jailbreaks, which are adversarial prompts capable of bypass system restrictions, also remain an issue, though they have been reduced since the release of ChatGPT-3.5 (OpenAI et al., 2024).
The base GPT-4 model was fine-tuned to follow instructions, but it still presents issues related to biased and unreliable content, as well as risks in areas such as finding websites that sell illegal goods/services, planning attacks, harmful content, misinformation, and privacy concerns. Nevertheless, OpenAI has released an updated version of the model that seeks to improve its usability and safety, addressing some of the limitations found in the base version. According to internal OpenAI evaluations, GPT-4 is 82% less likely to respond to requests for impermissible content and 40% more likely to generate objective responses compared to GPT-3.5 (OpenAI et al., 2024).
2.3. China's response to Western LLMs: ChatGLM-4.
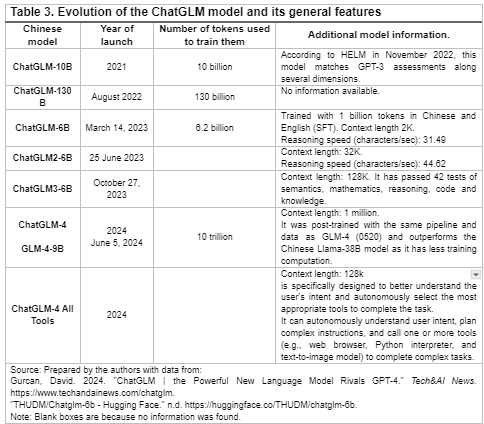
The GLM model from China is a notable example where advancements in large language models (LLMs) can be clearly seen. To better understand these improvements, a comparison of the model iterations is essential, focusing on key elements such as the number of tokens, context length, training data, multilingual capabilities, and other unique features. The following figure 3 outlines these factors, offering insight into how each version of the model has evolved over time.
2.3.1. Evolution of ChatGLM models across time
2.3.2. Description of ChatGLM-4 and its configuration
GLM stands for General Language Model, a pre-trained language model based on autoregressive whitespace filling. The ChatGLM series of models supports relatively complex natural language instructions and can solve challenging reasoning problems. (Beijing Zhipu Huazhang Technology Co., n.d.). Similar to the US GPT model, it has undergone different versions, allowing it to achieve comparable performance, and even surpass, SOTA models like GPT-4-0613 and Gemini 1.5 Pro. This has been particularly evident in widely-used American academic benchmarks such as MMLU, GSM8K, MATH, BBH, GPQA and HumanEval (GLM et al., 2024).
The GLM-10B model, launched in 2021, was designed with inspiration from GPT-3 (davinci) to offer equal or superior capabilities, while also testing techniques to successfully training models at this scale. The latest ChatGLM models (GLM-4 (0116, 0520), GLM-4-Air (0605) and GLM-4 All Tools) demonstrate significant advances in understanding and executing complex tasks through the autonomous use of external tools and functions.
China has focused heavily on context length, as ilustrated in Figure 1. Context length has become one of the most important indicators of technological advancement in AI models, often compared to the "memory" of an operating system, which enables it to complete various complex tasks (ChatGLM, 2024). In this context, the evolution and preliminary versions of this model have continued to improve their "recall" capacity.
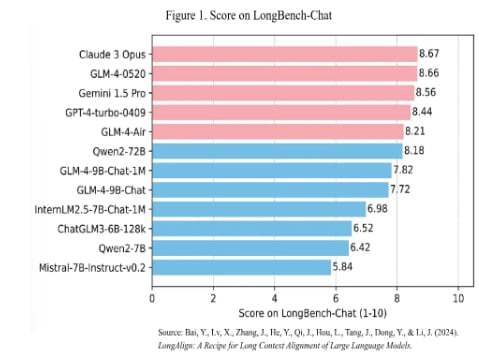
In this context, the evolutions and preliminary versions of this model have been advancing in their "recall" capacity. Specifically in the LongBench-Chat evaluation, which is specifically tasked with evaluating language models on their ability to follow instructions in contexts ranging from 10,000 to 100,000 words (Bai et al., 2024)the GLM-4-0520 model obtained a score of 8.66 while GPT-4-turbo-0409 obtained 8.44 (Bai et al., 2024).
On the other hand, the models were evaluated using InfiniteBench, which tests language models with a context length exceeding 100K. The evaluation consists of 12 tasks designed to assess different aspects of processing and language comprehension in very large contexts. SOTA models can perform these tasks with shorter text lengths, ensuring that the test actually evaluates model performance solely based on context length (Zhang et al., 2024). In this test, the GLM4-9B-Chat-1M model achieved an average score of 46.7, placing second only to GPT-4, which scored 52.5 (ChatGLM, 2024).
The evolution of the GLM model, from GLM-130B to GLM-4 All Tools, can be measured using the MMLU (Massive Multitask Language Understanding) benchmark, designed by OpenAI. This benchmark evaluates the ability of language models to generalize across domains without task-specific fine-tuning, covering subjects in STEM, humanities, social sciences and more. Each version of the GLM models has been refined to achieve a higher level of generality, while also improving context length as seen in the progression from GLM-2 to ChatGLM2, and from GLM-4 to GLM4-All Tools, among other adjustments highlighted in Figure 2 (Hendrycks, Burns, Basart, et al., 2021).

The pretraining of LLMs as GLM-4 is based on a wide variety of multilingual sources, with a predominance of English and Chinese texts. These sources include web pages such as Wikipedia, books, source codes and scientific articles. The data processing is carried out in three main stages. First, deduplication, which removes repeated information to ensure content uniqueness. Then, filtering is applied to discard "noisy" or irrelevant documents, such as those containing offensive language or lacking value for the model. Finally, tokenization transformed the text into a sequence of tokens, which are the smallest units the model can process. By the end of these stages, the model has accumulated about 10 billion tokens, which are then used in the next training phase focused on alignment with human intentions. Although the model is trained in multiple languages, its alignment is primarily oriented towards Chinese (Hendrycks, Burns, Basart, et al., 2021).
Model alignment seeks to enable it to accurately interpret user intentions, follow instructions, and facilitate dialogue. In the case of GLM-4, this is achieved through two main approaches: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). Through SFT, labels are assigned to the data, allowing the model to improve its performance on specific tasks by adjusting its outputs to align with human expectations. Subsequently, RLHF reinforces the learning process by enabling the model to receive rewards or penalties based on its performance, adjusting its behavior to maximize accumulated rewards. This results in a safer, more efficient model that is better aligned with human preferences (Hendrycks, Burns, Basart, et al., 2021).
The most advanced version of the model, known as GLM4-All Tools, also has the capability to access external APIs and knowledge bases, enabling it to perform tasks that require additional information or resources beyond its own training. This extends the model’s functionality, allowing it to respond more accurately and efficiently to a broader range of requests. Such a comprehensive approach to training and alignment makes GLM-4 not only a robust model, but also a highly adaptable one to complex and dynamic environments, with the ability to solve problems in real time by integrating external resources (Hendrycks, Burns, Basart, et al., 2021).
3. Benchmark Evaluations
The selection of benchmarks for this study was one of the most complex tasks, given the wide range of options that measure different aspects of performance. The main challenge was to identify two benchmarks (one from each country) that were comparable in the areas they evaluated, particularly with LLMs.
The main requirement was that these benchmarks had to be up-to-date, so the selection process began with a thorough review of the most recent literature and comparison of benchmarks against each other. Another key aspect in the selection process was ensuring that the benchmark had previously assessed the selected LLMs and that the information was accessible, as some data on Chinese benchmarks remain unpublished or are limited.
Through the review, it was found that Chinese Language Understanding Evaluation (CLUE) was one of the most widely used benchmarks in China, covering fields from arts to sciences. An updated version, SuperCLUE, was then identified, which includes improvements and new assessment parameters. As for U.S. benchmarking, several articles on LLMs that referenced the benchmarks used for their evaluation pointed to the General Language Understanding Evaluation benchmark (GLUE). Similar to CLUE, GLUE also has an improved and updated version, SuperGLUE, which evaluates models on tasks comparable to those assessed by the Chinese benchmark. SuperGLUE has its own website and leaderboard, facilitating the analysis of the parameters measured and verifying whether it has evaluated more advanced AI models. The literature review further revealed that SuperGLUE is one of the most widely used benchmarks for model evaluation and a key reference in determining SOTA model performance.
3.1 Western SOTA par excellence: superGLUE
While GLUE focuses primarily on sentence-level tasks, SuperGLUE incorporates more tasks that require reasoning over longer text fragments, demanding a deeper understanding of language and logic from models (Michael X, 2023). SuperGLUE shares the same high-level motivation as GLUE: to provide a straightforward yet challenging measure of progress toward general-purpose language understanding technologies for English. Significant progress in SuperGLUE is expected to require substantial innovations in a number of core areas of machine learning, including efficient sampling, transfer, multitask, and unsupervised or self-supervised learning (Wang et al., 2019).
SuperGLUE is an enhanced version of GLUE, designed to drive advances in the development of natural language processing (NLP). Unlike its predecessor, it incorporates more challenging tasks, retaining the two most complex ones from GLUE while adding new tasks selected through an open call, aimed at identifying those that pose greater difficulties for current NLP models. Also, SuperGLUE broadens the range of task formats, which in GLUE were limited to sentence and sentence-pair classification. This new version introduces tasks such as co-reference resolution, which involves determining which entity specific words or phrases refer to, and question answering, which enables the assessment of deep language comprehension.
Another significant improvement is the incorporation of comprehensive human baselines. SuperGLUE provides detailed estimates of human performance across all benchmark tasks, clearly outlining the gap between current model performance and human-level understanding, with advanced models like BERT serving as a reference point. Enhanced code support is also provided through a modular set of tools designed to facilitate pre-training, multitask and transfer learning. These tools are built on widely adopted frameworks in the NLP community, such as PyTorch and AllenNLP, ensuring smoother and more efficient integration for researchers.
Finally, SuperGLUE introduces refined usage rules for inclusion in its leaderboard, ensuring fair competition and proper acknowledgment of the creators of the datasets and tasks. This ensures a more equitable and informative evaluation, while maintaining the high quality standards expected in current NLP research.
The following is a summary of the eight tasks evaluated in SuperGLUE:
- Boolean Questions (BoolQ): A question-answer task that begins with a short passage followed by a closed-ended question about it.
- CommitmentBank (CB): A corpus of short texts where at least one sentence contains an embedded clause. Each clause is annotated with the degree to whichthe author appears to be committed to the truth of the statement. The model must classify the clause as true, false, or neutral, based on the given context. This assesses the model’s ability to infer beliefs, opinions, or commitments implied in people's statements.
- Choice of Plausible Alternatives (COPA): A causal reasoning task in which a premise sentence is provided, and the system must determine either the cause or effect of the premise between two possible alternatives.
- Multi-Sentence Reading Comprehension: Designed to assess the ability of language models to comprehend longer passages and extract relevant information from them. This task focuses on the model's ability to infer the correct answer to a question based on the context of multiple sentences.
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD): A reading comprehension task in which the model is given a passage (often news or informational text) and a cloze question. The model must fill in the blank with the correct answer using context and common sense.
- Recognizing Textual Entailment (RTE): A task designed to evaluate if a model can determine whether a statement (or hypothesis) is true, false or neutral in relation to a given sentence (or premise).
- Word-in-Context (WiC): In this task, the model is presented with two sentences, containing the same target word. The goal is to determine whether the word has the same meaning in both contexts or if its meaning differs.
- Winograd Schema Challenge (WSC): A co-reference resolution task in which the model is given a sentence with a pronoun and a list of noun phrases. The model must identify the correct pronoun referent from the choices provided. Winograd schemes are designed to require everyday knowledge and common sense reasoning to be solved correctly.
Despite the broad range of capabilities that this benchmark can evaluate, biases such as those related to gender may still be present when evaluating models. To address this problem, SuperGLUE incorporated Winogender as an additional diagnostic dataset, which is specifically designed to measure gender bias in co-reference resolution systems (Wang et al., 2019).
3.2. The Eastern evaluation proposal: superCLUE
SuperCLUE is an enhanced benchmark, improved across several dimensions from its previous version, CLUE. Together with CUGE (Chinese Language Understanding and Generation Evaluation), it has become one of the most widely used Chinese benchmarks for evaluating large-scale pre-trained models (Siegmann & Anderljung, 2022).
Earlier benchmarks such as CLUE and GLUE were considered prominent frameworks for general evaluation, focusing on various NLP tasks. These benchmarks have been instrumental in enhancing the generalization capabilities of language models, but as recent models demonstrate advanced reasoning and problem-solving abilities, these evaluation methods have become insufficient.
To address this limitation, new benchmarks have been proposed that assess broader knowledge and advanced capabilities, including human-centered scenarios and human-level reasoning tests. Despite advances in SOTA benchmarks, some still fail to accurately reflect real human-centered scenarios. In response, some researchers have developed more reliable assessment models, such as CArena, which is based on open-ended questions and English, thus limiting its applicability to specific sets of models (Xu et al., 2023).
SuperCLUE is presented as a Chinese benchmark that includes both open-ended and closed-ended questions. Evaluating models solely with closed-ended questions is considered insufficient, but the combination with open-ended questions provides a better prediction of human preferences regarding the real-world utility of the models. SuperCLUE is designed to quickly and accurately capture user preferences in a Chinese context before models are deployed in applications, thanks to its division into three subtasks: queries and ratings from real users derived from an LLM battle platform (CArena), open-ended questions with single and multi-turn dialogues (OPEN), and closed-ended questions covering the same topics as the single-turn open-ended ones (CLOSE) (Xu et al., 2023).
Real user ratings are a reliable standard for evaluating the performance of language models. In this context, Chatbot Arena was developed, which is a crowdsourcing platform for English models that allows users to interact with two anonymous chatbots and rate them based on their preferences. Similarly, an anonymous competition platform was created using the Elo scoring system, where users communicate with two Chinese LLMs and rate their responses (Xu et al., 2023).
Through the LangYa Leaderboard platform, user queries are analyzed in large quantities, selecting a subset of data representing various model capabilities. The winning percentages assigned by users serve as the gold standard for evaluating performance in real-world scenarios. From these data, an OPEN question set is constructed, which includes both single and multi-turn questions, and a CLOSE set derived from the OPEN one to explore whether closed-ended questions can serve as a suitable alternative (Xu et al., 2023).
The OPEN question set is designed to elicit detailed and meaningful responses, assessing both the knowledge and emotions of the model being evaluated. This set follows two key principles: first, the questions must reflect actual user queries, both in format and content, to assess the models' ability to follow instructions; and second, they must evaluate the models' ability to engage in multi-turn conversations, covering areas such as text comprehension, generation, knowledge, professionalism, and safety.
The OPEN set contains 600 questions divided between single-turn (OPEN SINGLE) and multi-turn (OPEN MULTIPLE) categories, collectively grouped as OPEN ALL (Xu et al., 2023). For the creation of multiple-choice questions, GPT-3.5 is used, as it is considered a reliable system for this task. The generated questions are then reviewed by humans to ensure quality.
SuperCLUE, by comparing the non-updated version of the Chinese GLM model with GPT-4, has shown that GPT-4 significant outperforms the other model in all categories: CLOSE, OPEN SINGLE and OPEN ALL. MiniMax ranks as the second best model overall, standing out as the most outstanding Chinese LLM. Compared to MiniMax, GPT-4 achieves more than a ten-percentage-point lead in the CLOSE category, and almost twice as many wins in the OPEN category. These results reveal a considerable performance gap between Chinese models and the global leaders, with the third best model, ChatGLM2-6B, trailing with nearly 1% fewer wins (Xu et al., 2023).
4. Comparative LLM Performance - Data Analysis
4.1. Academic Benchmarks as a Lens for Comparing Chinese and U.S. LLMs
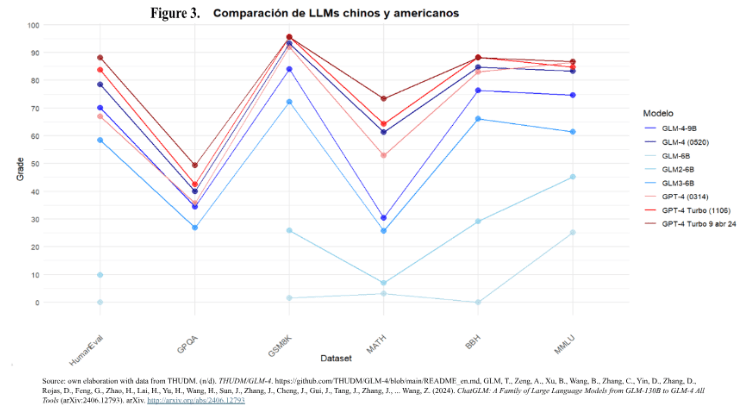
Figure 3 presents a detailed comparison between LLMs developed in China (blue shades) and the United States (red shades), evaluated across several key academic benchmarks. These datasets are designed to measure various general capabilities of the models, as detailed below:
- HumanEval: This benchmark focuses on the ability of models to generate code from textual descriptions. It directly evaluates the accuracy and efficiency of LLMs in generating functional code by simulating typical programming tasks (Walker, 2024b).
- GPQA: A dataset composed of 448 multiple-choice questions covering biology, physics and chemistry topics. These questions were designed by experts, and the benchmark assesses the reasoning abilities and specific knowledge in natural sciences of the models (Rein et al., 2023).(Suzgun et al., 2022).
- GSM8K: A benchmark focused on basic-level math problem solving. It includes 8,500 expertly crafted elementary math problems, assessing the model's ability to understand and solve structured problems, reflecting its skills in applied mathematics (Walker, 2024a).
- MATH: A more advanced dataset than GSM8K, consisting of 12,500 mathematical competition problems. Each problem has a step-by-step solution that allows models to generate complete derivations and explanations. This benchmark measures LLMs' ability to perform advanced computations, logical reasoning, and follow complex steps in a coherent manner. (Hendrycks, Burns, Kadavath, et al., 2021).
- BBH: Part of the BIG-Bench project. The set includes 23 tasks that are highly challenging for current language models. These tasks, which exceed the average human evaluator's ability, require advanced inference, logic and reasoning skills, making them a significant challenge for any LLM.
- MMLU: One of the most extensive benchmarks, with around 16,000 multiple-choice questions covering 57 academic subjects, including mathematics, philosophy, law, and medicine. It assesses models' general academic knowledge and specialization skills, as well as measures their ability to handle information across multiple domains and levels of difficulty (Hendrycks, Burns, Basart, et al., 2021).
What stands out in this graph is the continuous improvement of the Chinese models with each new iteration. In particular, the GLM-4 model (0520) is very close to the ratings obtained by the U.S. GPT-4 models, indicating rapid progress in terms of overall capabilities. Although they do not yet reach the U.S. state-of-the-art (SOTA) performance level, the Chinese models have made significant progress, despite being evaluated on benchmarks designed in English, for models trained primarily in English. This is a crucial point, since the Chinese models are trained in both languages (English and Chinese), indicating their generalizability in multilingual environments.
The trend of improvement observed in the Chinese models suggests that their rate of evolution could close the gap with the U.S. models in the short to medium term. As each new model shows at least 100% improvement over its predecessor, it is plausible to project that Chinese LLMs will soon reach, and may even surpass, the scores of U.S. models on some of these benchmarks. This progress is especially notable in general tasks such as MMLU, BBH and MATH, where academic knowledge, logical reasoning and mathematical ability are key.
In conclusion, if Chinese models continue to evolve at the current pace, they will not only reach a competitiveness similar to that of U.S. models, but could also play a key role in multilingual applications and in a wider variety of specialized domains, marking a new chapter in the race for the development of advanced artificial intelligence.
4.2. Memory in Focus: LongBench's Role in Comparing Chinese and U.S. LLMs
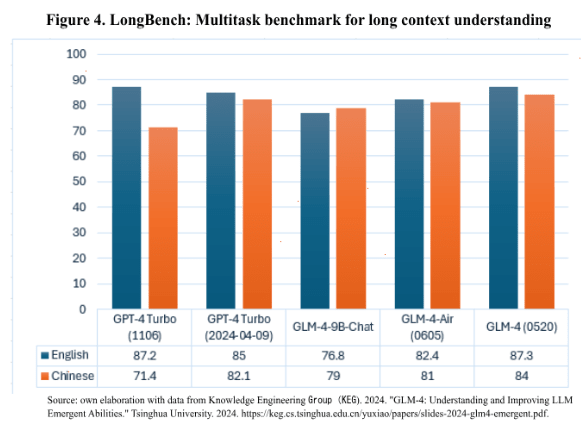
As shown in Figure 4, a comparative analysis was conducted between Chinese and US models using LongBench, a benchmark designed to evaluate the ability of LLMs to handle and process long contexts in both English and Chinese. This evaluation is essential for measuring the efficiency and memory capacity of LLMs, particularly in tasks that require handling large volumes of information or maintaining consistency across extended texts. LongBench is particularly important because context length has become a critical indicator in the evolution of language models (Bai et al., 2024), since a model’s ability to retain relevant information during prolonged interactions or across extended document is vital for advanced applications, such as long-term reasoning, synthesizing complex information, and large-scale data analysis.
One of the most striking aspects of the chart is the comparison between two versions of OpenAI's GPT-4 Turbo model. The GPT-4 Turbo (1106) model scores 87.2 in English, placing it as the top performer in this language, even surpassing its more recent version, GPT-4 Turbo (2024-04-09), which scores 85. However, the performance in Chinese is reversed, with GPT-4 Turbo (2024-04-09) significantly outperforming the earlier model, with a score of 82.1 compared to 71.4 for the November 2023 version.
On the other hand, Chinese GLM-4 models exhibit a surprisingly balanced performance. The GLM-4 model (0520) scores 87.3 in English and 84 in Chinese, making it as a strong contender against GPT-4 models in both languages. Another Chinese model, GLM-4-Air (0605), also performs remarkably, scoring 82.4 in English and 81 in Chinese. This consistency suggests that Chinese models are optimized to handle information not only in their native language, but also in English, highlighting their versatility and multilingual capabilities.
It is important also to highlight that while GPT-4 models are primary trained in English and possess multilingual capabilities, their performance in Chinese may be limited by less extensive exposure to the language during training. This could explain why the Chinese GLM models achieve more balanced scores in both languages, as they are specifically designed to handle both Chinese and English, likely with optimizations for both contexts.
The analysis suggests that Chinese models, such as GLM-4 (0520), have made significant progress in handling long contexts across multiple languages, pointing to a trend of improving recall capabilities in these models. Going forward, Chinese LLMs are likely to focus on further increasing their context-handling abilities and improving their multilingual performance, giving them a strategic advantage in global tasks that require high linguistic versatility. By contrast, although GPT-4 models maintain a clear lead in English, their potential for improvement in Chinese suggests they could benefit from further integration of data in other languages or targeted optimizations to improve their multilingual capabilities.
As context length becomes an increasingly important factor in evaluating LLM performance, it is likely to remain a central focus in the competition between AI models from different regions. The Chinese emphasis on increasing context length appears to be paying off, suggesting that they could potentially surpass their competitors in tasks requiring the management of large amounts of long-term information.
4.3. Battle of Benchmarks: SuperGLUE vs. SuperCLUE
To gain insights into the performance of large language models (LLMs) across different linguistic landscapes, a comparative analysis was conducted using two significant benchmarks: SuperCLUE and SuperGLUE. These benchmarks serve distinct purposes, with SuperCLUE targeting Chinese natural language processing (NLP) tasks and SuperGLUE focusing on English-language tasks. By examining the results from both benchmarks, we can better understand how LLMs in China and the United States approach complex language challenges, revealing their respective strengths and areas needing enhancement.
4.3.1. SuperGLUE benchmark
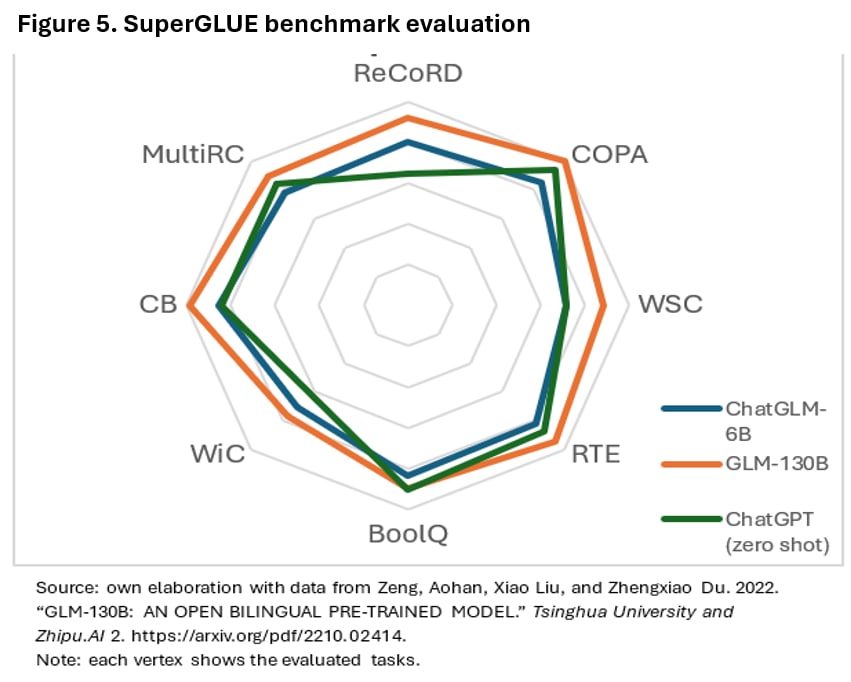
The superGLUE benchmark evaluation was performed between the ChatGLM-6B, GLM-130B and ChatGPT among a variety of tasks (Figure 5). By analyzing the ratings obtained by the three models in each of these tasks, it can be noted that the GLM-130B model (orange line) outperforms in almost every task, consistently achieving high ratings except in WiC test. In particular, its scores on ReCoRD, COPA, WSC, and MultiRC suggest that this model is better equipped for causal reasoning, complex text comprehension, and coreference resolution, although ChatGPT is only a few points behind.
Conversely, despite its smaller parameter size, the ChatGLM-6B model (blue line) delivers competitive performance, particularly in BoolQ, RTE and WiC tasks, although it falls behind GLM-130B in more complex tasks such as ReCoRD and MultiRC. This suggests that, despite being a smaller model, it handles binary decision tasks and semantic understanding with relative efficiency. As for ChatGPT in its zero-shot version (green line), it closely follows the Chinese models, showing particularly high performance on tasks like COPA and BoolQ, which require advanced reasoning and linguistic comprehension. However, it performs slightly lower on tasks like WiC and ReCoRD, where a deeper understanding of long and complex texts is crucial.
This analysis is particularly relevant because, although GLM-130B excels in most tasks, the other models, including ChatGPT, follow closely, suggesting that the competition between Chinese and US models is tighter than it seems. Notably, GLM-130B is considerably larger than the other models compared, which explains part of its advantage in more difficult tasks. Another key point is that ChatGPT displays impressive capabilities without specific training on SuperGLUE tasks, even when evaluated in zero-shot mode. This suggests that, with additional data or task-specific training, its performance could improve substantially, further narrowing the gap with Chinese models.
Given the rapid progress in language models, it is reasonable to infer that both Chinese and US models will continue to improve their capabilities with each new iteration. In particular, Chinese models like GLM-130B are making significant progress in solving complex comprehension and reasoning tasks, implying that the race to lead benchmarks like SuperGLUE will become increasingly competitive.
While GLM-130B dominates the SuperGLUE benchmark in this evaluation, smaller and more efficient models like ChatGLM-6B and ChatGPT remain competitive, highlighting the future potential of these models as they continue to evolve. Moreover, the trend observed in previous graphs, where Chinese models showed improvements in their multilingual capabilities and balanced performance on both general and long-context tasks, could lead to enhanced performance on more global and varied benchmarks, which would directly impact the future of natural language processing.
4.3.2. SuperCLUE benchmark
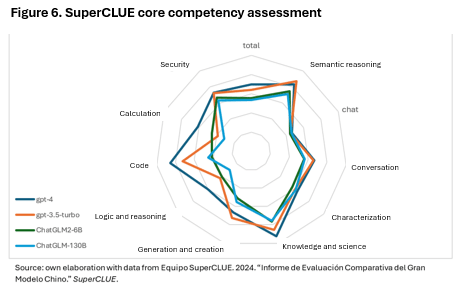
The Figure 6 comparing GPT-4, GPT-3.5-turbo, ChatGLM2-6B and ChatGLM-130B in the SuperCLUE benchmark gives us a clear picture that the US models, especially GPT-4, tend to excel in most tasks (dark blue line). Also it is important to highlight that the GPT models are compared with the GLM models specially in conversation (that is why is chatGLM) and these models are not as new as the iterations of GPT models. However, the ChatGLM2-6B (green line) is not really that far from the same grade as the most advanced GPT models as in the chat task, semantic reasoning and security. This clearly shows that perhaps the difference between LLMs models and the different iterations of Chinese and American models are not really that different when developing the same tasks.
SuperCLUE is one of the most advanced Chinese benchmarks due to the variety of tasks evaluated: knowledge and science, logic and reasoning, characterization, semantic reasoning, conversation, generation and creation, calculation and code. In addition, these tasks can be compared to the tasks evaluated in the SuperGLUE benchmark (as it is shown later).
The tasks evaluated in both benchmarks can be compared as shown in Table 4, based on a qualitative analysis of the tasks. While not exact, this comparison serves as a foundation for understanding how the models are assessed on tasks that require similar skills in different languages and contexts.
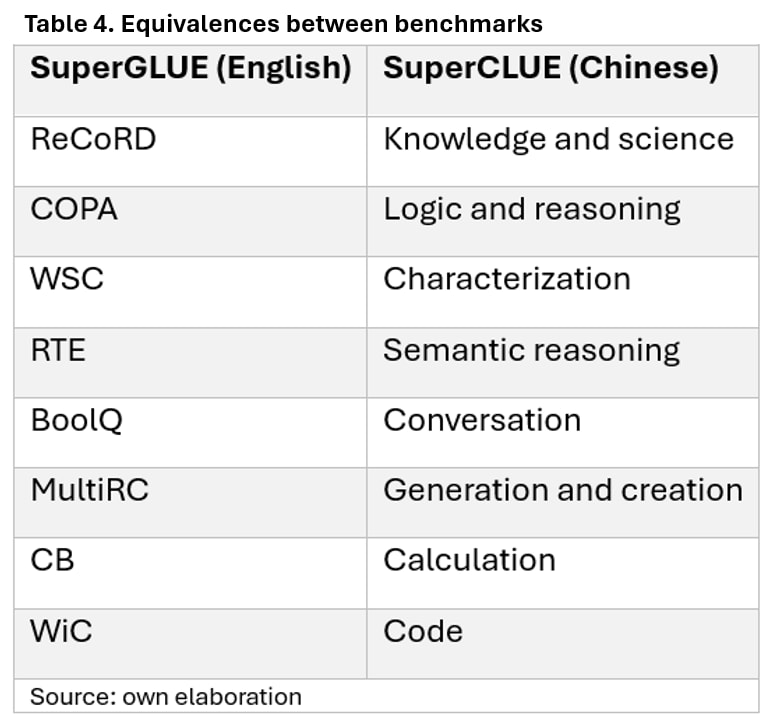
While this comparison serves as a starting point, significant discrepancies exist between the SuperGLUE and SuperCLUE benchmarks, particularly in how they assess the same model under different linguistic and task environments. For example, when analyzing the performance of the ChatGLM-130B model, its scores vary notably between benchmarks. In SuperGLUE, the model scores significantly higher on tasks such as COPA (logic and reasoning) and ReCoRD (knowledge and science) compared to its performance in SuperCLUE. This discrepancy becomes even clearer in Table 5, where this model achieves a COPA perfect score of 100% in SuperGLUE, but scores only 29.75% on similar logic tasks in SuperCLUE. These differences may be due to linguistic and cultural contexts or the nature of the conversational tasks tested in SuperCLUE, which may require further adjustments to the models to enhance their performance on multilingual and contextual tasks.
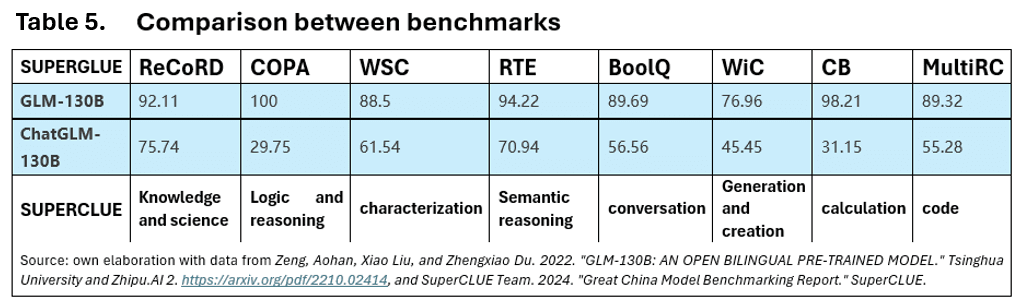
Despite these differences, distinct performance patterns in models can still be observed across various categories. In the SuperCLUE benchmark, GPT-4 excels in areas such as logic, reasoning, coding, and computation, while Chinese models like ChatGLM-130B achieve competitive scores in semantic reasoning, knowledge, science, generation and creation. This suggests that Chinese LLMs have reached a high level of sophistication, particularly in tasks requiring the processing complex scientific information and advanced semantic reasoning.
It can also be highlighted that, although ChatGLM2-6B and ChatGLM-130B models are not the latest versions, they still perform remarkably well in SuperCLUE, especially in semantic reasoning and generation and creation tasks, where the performance gap with GPT-4 is smaller than expected. This reinforces the projection that Chinese models are evolving rapidly and that future versions could potentially match or even surpass their US counterparts in certain respects.
The fact that the Chinese models analyzed here are not the most recent versions suggests that the performance gap may not be as wide as previously assumed. As these models are updated, it is likely that Chinese and U.S. LLMs performance will converge more closely in both general and specialized tasks. The small differences observed in tasks such as semantic reasoning and characterization between GPT-4 and ChatGLM-130B (63.46 vs 61.54) point to the fact that the gap between Chinese and US AI models could narrow significantly in future iterations.
5. AI power in China and the U.S.
5.1 Computational Capacity and Hardware Development.
In June 2024, the results of several key rankings, including the TOP500, GREEN500, IO500, and AI Benchmark, were published, showcasing significant advancements in supercomputing. A summary data of the results of TOP500 is presented in Table 6.
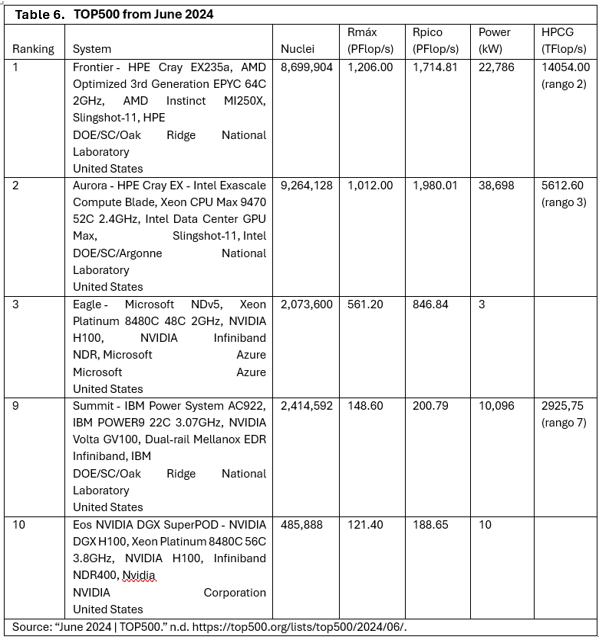
In particular, the TOP500 list has incorporated the results of the High Performance Conjugate Gradient (HPCG) test, providing an additional metric for evaluating supercomputer performance. This score complements the HPL metric, offering a more comprehensive understanding of a machine's capabilities (HPCG - June 2024 | TOP500 n.d.).
An analysis of the computational capacity and hardware development between the US and China, based on the list mentioned before, highlights how both countries are positioning themselves in terms of supercomputing and overall performance. Despite having fewer systems in the ranking, the US maintains an advantage in computational power per system. This is evident by the fact that, although China has more systems listed (227 vs. 118), the US accounts for 37.8% of total performance, compared to China's 31.9%.
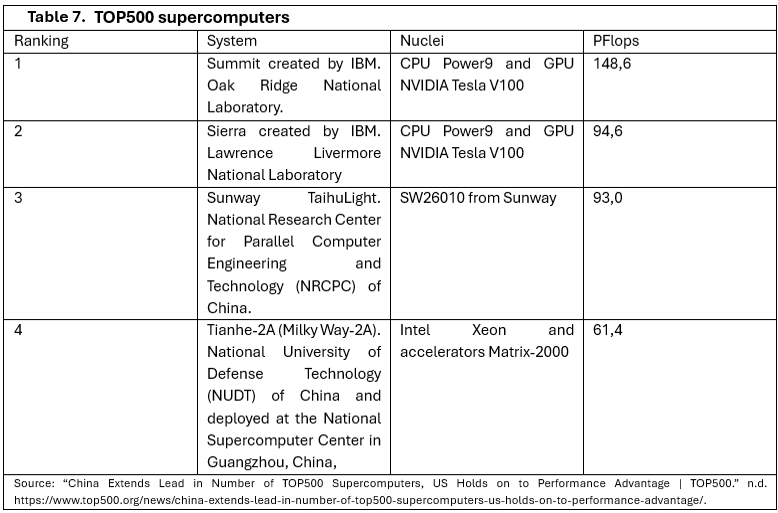
In terms of the most powerful supercomputers, the US leads with Frontier, which ranks first with a performance of 1,206 PFlop/s, followed by Aurora in second place with 1,012 PFlop/s. These systems exceed by far the performance of China’s top supercomputers, such as Sunway TaihuLight (at 93.0 PFlop/s) and Tianhe-2A (at 61.4 PFlop/s), which have not yet reached the exaflop levels of their competitor systems.
However, it is notable that the overall performance gap between the two countries has narrowed in recent years. In June 2019, the U.S. held 38.4% of the total performance shared, while China held 29.9%. By 2024, this difference has shrunk, indicating that supercomputing development in China has accelerated significantly and that, while the largest systems are still of US origin, China is rapidly increasing its aggregate computational capacity.
Differences in hardware development between the two nations are also evident. Intel, a U.S. based company, dominates the landscape by powering 470 of the 500 systems listed in the ranking (TOP500, 2024). This demonstrates Intel's CPUs continued dominance in supercomputing, although China is developing its own chips, such as Sunway's SW26010 and Matrix-2000 accelerators used in the Tianhe-2A system. IBM remains a supercomputing powerhouse as well, with its Power9 processors used in Summit and Sierra systems, combined with NVIDIA GPUs.
NVIDIA, a leader in artificial intelligence accelerators, has its GPUs installed in 136 of the 145 systems using accelerators, solidifying its leadership in AI and high-performance computing. This gives the US a clear competitive advantage, as NVIDIA continues to play a critical role in the development of AI infrastructure and advanced supercomputing applications (TOP500, 2024).
Also, in the third quarter of 2023, NVIDIA held roughly 80% of the GPU market, which increased to 88% in the first quarter of 2024. The majority of, if not all NVIDIA’s production is handled by Taiwan Semiconductor Manufacturing Company (TSMC), a Taiwanese-based corporation that intends to increase its AI chip production by 25% to meet rising demand. However, TSMC is neither a state-owned company nor exclusively Taiwanese, as major investors are from around the world, including the largest shareholder ADR, which owns 20.5% of the company and trade with mainly U.S. markets. Undoubtedly, Taiwan's strategic relationship with digital superpowers, particularly the U.S., will shape future progress and projections in the field.
The relationship between Taiwan and the US has been crucial in maintaining what western country supremacy in technology. At the same time, this has prompted China to implement strategic plans to produce everything needed for AI innovation, including semiconductors, within its borders (Huang, 2024). Taiwan’s influence on the market is also important within this relationship, since any disruption in the semiconductor supply from Taiwan could severely impact global supply chains, as demonstrated by the 2021 chip shortage, which resulted in billions of dollars in losses for the automotive industry (Huang, 2024).
The inclusion of the HPCG metric in the TOP500 list provides a more complete picture of the actual supercomputer performance, particularly in applications that require more complex computations beyond raw processing power. In this regard, while U.S. supercomputers continue to lead, the adoption of this metric provides a greater insight into the performance of Chinese systems in realistic computational and scientific simulations (TOP500, 2024).
From these observations, it is evident that the U.S.'s current dominance in computing power is not guaranteed in the long term. China continues to increase its number of supercomputing installations, and although its performance per system is still lower, its growing share of total performance indicates that the country is rapidly expanding its computational infrastructure.
At the hardware level, the US continues to dominate major manufacturers of key components, like Intel and NVIDIA. However, China's investment in developing proprietary technologies, such as its GPUs and accelerators, reflects a strategy of technological independence aimed to reduce reliance on U.S. components in the future. China’s push for self-sufficiency, coupled with U.S. export restrictions, is driving the development of a national computing power network designed to optimize resource use and improve efficiency.
One advantage China could exploit is its infrastructure’s ability to handle the massive computational demands of training AI models. President Xi Jinping has emphasized computing power as a vital force for AI development. As part of the megaprojects launched by China’s National Development and Reform Commission in 2021, initiatives like the China Computing Network, developed by Peng Cheng Lab and Huawei, aim to optimize resource usage while enhancing efficiency. This plan involves processing and storing more data in western China, where electricity and land costs are lower, thus integrating computational resources across the country (Arcesati, 2024).
6. Limitations
During the development of this project, several limitations were identified that affected the analysis of LLMs from China and the U.S., potentially impacting the accuracy of the results. The main obstacles encountered and their possible implications are outlined below:
- Lack of Updated Evaluations on Chosen Benchmarks: One of the biggest challenges was the absence of evaluations for the most recent iterations of the models on the selected benchmarks, such as SuperGLUE and SuperCLUE. As a result, the available data did not fully capture the performance of the latest AI models, compromising the accuracy of the analysis. To overcome this limitation, projections were made based on general academic benchmarks, which suggested that each new iteration of the models would likely show improved ratings, but without updated data, it was impossible to confirm these assumptions accurately.
- Language Barriers: Another significant obstacle was the fact that the majority of the information on Chinese models and benchmarks, such as SuperCLUE, was only available in Chinese. This entailed additional effort by the need of using AI translation tools, which demanded more time and resources. Also, since I am not a native speaker of either English or Chinese, there was some uncertainty regarding the accuracy of translations, which may have influenced the interpretation of the results. Although AI tools were useful, the quality of the translations was not always optimal, particularly in relation to technical terminology.
- Data availability: A key limitation was the lack of access to some crucial data, particularly regarding Chinese models, due to confidentiality restrictions. The unavailability of this information limited the ability to conduct detailed and direct comparisons between Chinese and U.S. models, impacting the comprehensiveness of the analysis. This restricted access could have introduced bias in the results, as the analysis relied solely on publicly available data.
- Evaluation of Models in Different Contexts: When comparing AI models developed in different countries, trained on different datasets and and originating from distinct cultural and linguistic environments, an additional challenge arose in ensuring objective evaluations. Since Chinese and U.S. LLMs were developed in different languages and based on different types of data, it was impossible to establish a common control group to eliminate potential biases. These differences in training data and the absence of a shared reference point complicated the objective evaluation of the results, as unmeasured variables could have influenced the performance of each model.
- Time Limitations: As this project was conducted within a 14-week period, the limited time frame restricted the depth of the analysis, particularly regarding the exploration of AI governance implications and the development of strategies to mitigate the identified risks.
7. Outlook
This project opens up several lines for future research that can further explore the geopolitical, social, and economic impacts of the ongoing competition between US and China in the field of artificial intelligence. The technological advancements of both nations in the race to develop LLMs raise numerous issues of interest that deserve further analysis.
One potential research direction is to examine the safety and alignment of AI models with human values. This is a crucial aspect, as AI has the potential to significantly influence the ethical systems and values that shape both nations. Ensuring that these models are aligned with global ethical principles is essential to mitigating risks.
Another critical area of study involves investigating the quality of the data used to train the models (like the ones used for GPT and GLM) and exploring the biases that may emerge across different iterations. Understanding these biases is key to improving fairness and accuracy in AI systems.
Additionally, it is important to assess the accuracy of the benchmarks used to evaluate these models, allowing a more rigorous technical analysis of their real performance in complex tasks. Exploring new benchmarks that focus on more specific and complex tasks for next-generation AI models is another promising avenue, since current benchmarks have limitations when it comes to evaluating multilingual models, as they often produce varying results depending on the cultural and linguistic context in which they are used. Future research could be based on whether models and benchmarks can be adapted to better assess linguistic and cultural biases, optimizing their performance on an international scale.
The analysis of energy efficiency in AI models will also be a crucial factor in the future development of technology, as training LLMs requires substantial computational resources that lead to high energy consumption and potential environmental impacts. As AI models continue to expand in size and capacity, both China and the U.S. will need to implement sustainability measures, develop more energy-efficient algorithms, and invest in supercomputers optimized for lower energy consumption.
Finally, given the growing concern about the potential misuse of AI, it would be valuable to examine how AI is being applied in national security, particularly in the development of autonomous weapons and surveillance technologies. Analyzing the potential impacts of AI on governance and population control would contribute to the creation of regulatory frameworks that address the risks associated with the misuse of AI.
8. Conclusions
Both China and the US find themselves in a situation comparable to the classic prisoner’s dilemma in their race for technological innovation. Despite the risks and challenges, neither country can’t slow down their investment in developing new AI technologies, as the potential consequences of falling behind are too significant. This dynamic has led to a technological race, with each nation forced to accelerate progress in order to maintain a competitive advantage over the other.
While both countries understand the risks of the competition—such as potential social and geopolitical destabilization—the strategic nature of AI and other advanced technologies makes any sign of weakness a threat. As a result, the technological race between China and the U.S. is likely to intensify further, carrying global implications for economy, security, and geopolitical balance.
The development of AI, particularly of LLMs, has broad applications in areas such as defense, security, and control of increasingly valuable resources: data and computational capabilities. Both global powers recognize that digital superiority can shift the balance in critical domains like supercomputing, commerce, political power, and economics, among others. In response to the growing competition, the US has implemented regulations such as the CHIPS and Science Act to counter China’s advancements in AI and semiconductors. This legislation highlights the US’s priority to safeguard its technological, reducing reliance on foreign companies like Taiwan's TSMC by strengthening their domestic semiconductor production. Meanwhile, China has pursued strategies to expand its supercomputing infrastructure, optimize their resource use, and extend the reach of AI through national interconnectivity.
This rivalry is also reflected in the results obtained from various evaluations. For instance, the performances of GLM and GPT models on general task benchmarks, SuperGLUE from U.S. and SuperCLUE from China, demonstrate that the western country has made significant progress in AI general task development, with projections suggesting that future iterations of these models will continue to improve. The fact that Chinese models (like GLM-4 (0520)) are increasingly approaching the performance levels of U.S. models (like GPT-4), indicates that China may close the technological gap in the short to medium term, consolidating its competitiveness in advanced AI development.
Several factors have contributed to China’s emergence as a direct competitor to the western power, including the access to GPUs, training with vast amounts of data in both English and Chinese, and the adoption of advanced techniques like SFT and RLHF, which have been recently integrated into certain Chinese models. Additionally, China’s focus on enhancing its capabilities in long-context processing (LongBench) suggests that, if Chinese LLMs continue to evolve at their current pace, they could not only reach competitive levels in multilingual applications but also surpass U.S. models in specialized domains.
The analysis of benchmarks like SuperGLUE and SuperCLUE also highlights differences in how AI models are evaluated across different languages and contexts. While SuperGLUE focuses on task evaluation in English, SuperCLUE is oriented towards natural language processing in Chinese. In these evaluations, U.S. models like GPT-4, tend to excel in logic, reasoning, and computation tasks, while Chinese models like ChatGLM-130B, have demonstrated a competitive performance in areas like semantic reasoning and scientific knowledge. However, significant discrepancies are also observed between the performances of the same models across these benchmarks, suggesting that linguistic and cultural contexts play a crucial role in assessing the capabilities of LLMs. This raises questions about whether the benchmarks used in this research are truly efficient in evaluating LLMs and to what extent they may be biased.
In conclusion, the evidence suggests that the competitiveness gap between the U.S. and China in the development of LLMs is narrowing. This shift introduces new risks and challenges on the global stage, as both countries continue to vie for technological superiority.
References
Allison, G., & Schmidt, E. (2020). Is China Beating the U.S. to AI Supremacy?
Arcesati, R. (2024, May 2). China's AI development model in an era of technological deglobalization. Mercator Institute for China Studies. https://www.merics.org/en/report/chinas-ai-development-model-era-technological-deglobalization
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y., Tang, J., & Li, J. (2024). LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding.
Beijing Government Office (2023). Notice of the General Office of the Beijing Municipal People's Government on the issuance of "Various Measures in Beijing to Promote the Innovative Development of General Artificial Intelligence" (28). https://www.beijing.gov.cn/zhengce/gfxwj/202305/t20230530_3116869.html
Bigley, K. (2023). The Artificial Intelligence Revolution in an Unprepared World: China, the International Stage, and the Future of AI. Harvard International Review. https://hir.harvard.edu/artificial-intelligence-china-and-the-international-stage/
ChatGLM (2024, July 23). GLM Long: Scaling Pre-trained Model Contexts to Millions [Medium]. https://medium.com/@ChatGLM/glm-long-scaling-pre-trained-model-contexts-to-millions-caa3c48dea85.
"China Extends Lead in Number of TOP500 Supercomputers, US Holds on to Performance Advantage | TOP500." n.d. https://www.top500.org/news/china-extends-lead-in-number-of-top500-supercomputers-us-holds-on-to-performance-advantage/.
Cubet. n.d. "Comparing the Capabilities and Advancements of ChatGPT and GPT-3 | Insights." Cubet Techno Labs. https://cubettech.com/resources/insights/comparing-the-capabilities-and-advancements-of-chatgpt-and-gpt-3/.
GLM, T., Zeng, A., Xu, B., Wang, B., Zhang, C., Yin, D., Zhang, D., Rojas, D., Feng, G., Zhao, H., Lai, H., Yu, H., Wang, H., Sun, J., Zhang, J., Cheng, J., Gui, J., Tang, J., Zhang, J., ... Wang, Z. (2024). ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools (arXiv:2406.12793). arXiv. http://arxiv.org/abs/2406.12793
Gurcan, David. 2024. "ChatGLM | the Powerful New Language Model Rivals GPT-4." Tech&AI News. https://www.techandainews.com/chatglm.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2021). Measuring Massive Multitask Language Understanding.
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., & Steinhardt, J. (2021). Measuring Mathematical Problem Solving With the MATH Dataset (arXiv:2103.03874). arXiv. http://arxiv.org/abs/2103.03874
Hine, E., & Floridi, L. (2024). Artificial intelligence with American values and Chinese characteristics: A comparative analysis of American and Chinese governmental AI policies. AI & SOCIETY, 39(1), 257-278. https://doi.org/10.1007/s00146-022-01499-8
Huang, K.-S. (2024, August 2). More Than Mercenary: Why Taiwan's Semiconductor Dominance Helps the US. The diplomat. https://thediplomat.com/2024/08/more-than-mercenary-why-taiwans-semiconductor-dominance-helps-the-us/
"HPCG - June 2024 | TOP500." n.d. https://top500.org/lists/hpcg/2024/06/.
Jorge, V. I. & Anaheim University, Global Strategy and Innovation Management, USA (2020). BENCHMARKING INNOVATION: USA AND CHINA. I-Manager's Journal on Management, 14(3), 1. https://doi.org/10.26634/jmgt.14.3.16255
"June 2024 | TOP500." n.d. https://top500.org/lists/top500/2024/06/.
Knowledge Engineering Group(KEG). 2024. "GLM-4: Understanding and Improving LLM Emergent Abilities." Tsinghua University. 2024. https://keg.cs.tsinghua.edu.cn/yuxiao/papers/slides-2024-glm4-emergent.pdf.
Michael X. (2023, September 18). Benchmark of LLMs (Part 1): Glue & SuperGLUE, Adversarial NLI, Big Bench. Medium. https://medium.com/@myschang/benchmark-of-llms-part-1-glue-superglue-adversarial-nli-big-bench-8d1aed6bae12.
Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., & Gao, J. (2024). Large Language Models: A Survey (arXiv:2402.06196). arXiv. http://arxiv.org/abs/2402.06196
Lambropoulos, Charlie. 2023. "From GPT-3.5 to GPT-4: ChatGPT's Evolution." Scrum Launch. September 2023. Accessed September 1, 2024. https://www.scrumlaunch.com/blog/from-GPT-3-to-GPT-4-ChatGPT-evolution.
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., ... Zoph, B. (2024). GPT-4 Technical Report (arXiv:2303.08774). arXiv. http://arxiv.org/abs/2303.08774
Outloud (https://outloud.co). n.d. "ChatGPT0-3.5: An Overview and Limitations | Blocshop." https://www.blocshop.io/blog/chatgpt3-5-limitations.
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark (arXiv:2311.12022). arXiv. http://arxiv.org/abs/2311.12022
Savage, N. (2020, December 10). Learning the algorithms of power. 588. https://media.nature.com/original/magazine-assets/d41586-020-03409-8/d41586-020-03409-8.pdf
Siegmann, C., & Anderljung, M. (2022). The Brussels Effect and Artificial Intelligence. https://doi.org/10.33774/apsa-2022-vxtsl.
SuperCLUE Team. 2024. "Great China Model Benchmarking Report." SuperCLUE.
Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H. W., Chowdhery, A., Le, Q. V., Chi, E. H., Zhou, D., & Wei, J. (2022). Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them (arXiv:2210.09261). arXiv. http://arxiv.org/abs/2210.09261
Tang, J. (n/d). ChatGLM: An Alternative to ChatGPT. https://keg.cs.tsinghua.edu.cn/jietang/publications/iswc23-chatglm.pdf.
"THUDM/Chatglm-6b - Hugging Face." n.d. https://huggingface.co/THUDM/chatglm-6b.
Thudm. n.d. "GLM-4/README_en.md at Main - THUDM/GLM-4." GitHub. https://github.com/THUDM/GLM-4/blob/main/README_en.md.
TOP500. (2024, June). https://top500.org/lists/top500/2024/06/
Walker, S. (2024a). GSM8K Benchmark [KLU]. https://klu.ai/glossary/GSM8K-eval.
Walker, S. (2024b). HumanEval Benchmark [KLU]. https://klu.ai/glossary/humaneval-benchmark.
Wang, A., Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2019). SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
White House (2022, August 9). FACT SHEET: CHIPS and Science Act Will Lower Costs, Create Jobs, Strengthen Supply Chains, and Counter China. https://www.whitehouse.gov/briefing-room/statements-releases/2022/08/09/fact-sheet-chips-and-science-act-will-lower-costs-create-jobs-strengthen-supply-chains-and-counter-china/
Xu, L., Li, A., Zhu, L., Xue, H., Zhu, C., Zhao, K., He, H., Zhang, X., Kang, Q., & Lan, Z. (2023). SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark (arXiv:2307.15020). arXiv. http://arxiv.org/abs/2307.15020
Zeng, Aohan, Xiao Liu, and Zhengxiao Du. 2022. "GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL." Tsinghua University and Zhipu.AI 2. https://arxiv.org/pdf/2210.02414.
Zhang, X., Chen, Y., Hu, S., Xu, Z., Chen, J., Hao, M. K., Han, X., Thai, Z. L., Wang, S., Liu, Z., & Sun, M. (2024). ∞BENCH: Extending Long Context Evaluation Beyond 100K Tokens.