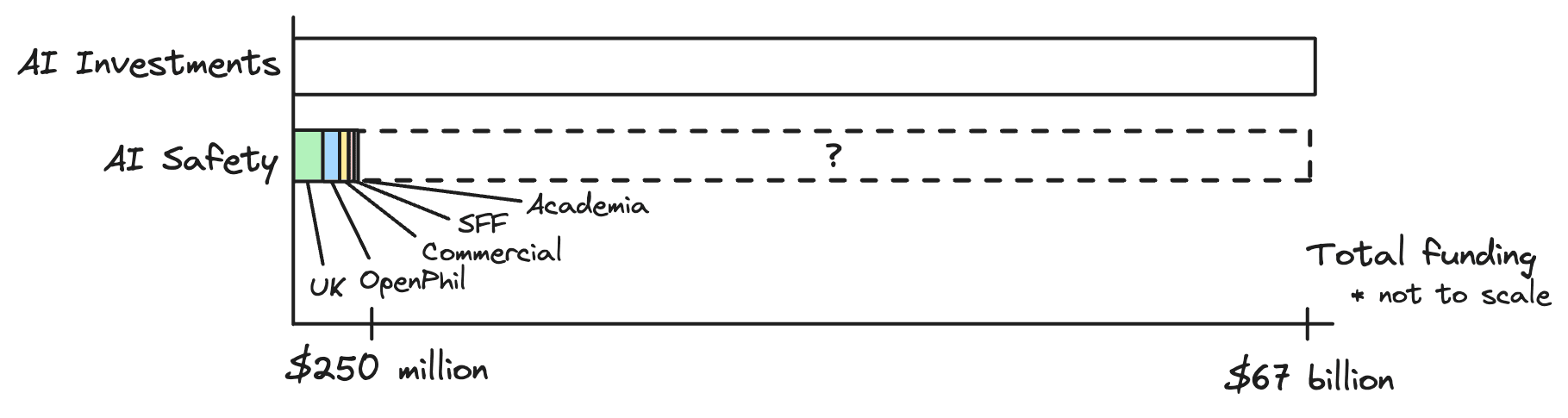
AI development attracts more than $67 billion in yearly investments, contrasting sharply with the $250 million allocated to AI safety (see appendix). This gap suggests there's a large opportunity for AI safety to tap into the commercial market. The big question then is, how do you close that gap?
In this post, we aim to outline the for-profit AI safety opportunities within four key domains:
- Guaranteeing the public benefit and reliability of AI when deployed.
- Enhancing the interpretability and monitoring of AI systems.
- Improving the alignment of user intent at the model level.
- Developing protections against future AI risk scenarios using AI.
At Apart, we're genuinely excited about what for-profit AI security might achieve. Our experience working alongside EntrepreneurFirst on AI security entrepreneurship hackathons, combined with discussions with founders, advisors, and former venture capitalists, highlights the promise of the field. With that said, let's dive into the details.
Safety in deployment
Problems related to ensuring that deployed AI is reliable, protected against misuse, and safe for users, companies, and nation states. Related fields include dangerous capability evaluation, control, and cybersecurity.
Deployment safety is crucial to ensure AI systems function safely and effectively without misuse. Security also meshes well with commercial opportunities and building capability in this domain can scale strong security teams to solve future safety challenges. If you are interested in non-commercial research, we also suggest looking into governmental research bodies, such as the ones in UK, EU, and US.
Concrete problems for AI deployment
- Enhancing AI application reliability and security: Foundation model applications, from user-facing chatbots utilizing software tools for sub-tasks to complex multi-agent systems, require robust security, such as protection against prompt injection, insecure plugins, and data poisoning. For detailed security considerations, refer to the Open Web Application Security Project's top 10 LLM application security considerations.
- Mitigating unwanted model output: With increasing regulations on algorithms, preventing illegal outputs may become paramount, potentially requiring stricter constraints than model alignment.
- Preventing malicious use:
- For AI API providers: Focus on monitoring for malicious or illegal API use, safeguarding models from competitor access, and implementing zero-trust solutions.
- For regulators: Scalable legislative auditing, like model card databases, open-source model monitoring, and technical governance solutions will be pivotal in 2024 and 2025. Compliance with new legislation, akin to GDPR, will likely necessitate extensive auditing and monitoring services.
- For deployers: Ensuring data protection, access control, and reliability will make AI more useful, private, and secure for users.
- For nation-states: Assurances against nation-state misuse of models, possibly through zero-trust structures and treaty-bound compute usage monitoring.
Examples
- Apollo Research: “We intend to develop a holistic and far-ranging model evaluation suite that includes behavioral tests, fine-tuning, and interpretability approaches to detect deception and potentially other misaligned behavior.”
- Lakera.ai: “Lakera Guard empowers organizations to build GenAI applications without worrying about prompt injections, data loss, harmful content, and other LLM risks. Powered by the world's most advanced AI threat intelligence.”
- Straumli.ai: “Ship safe AI faster through managed auditing. Our comprehensive testing suite allows teams at all scales to focus on the upsides.”
Interpretability and oversight
Problems related to monitoring for incidents, retracing AI reasoning, and understanding of AI capability. Related to the research in interpretability, scalable oversight, and model evaluation.
It is without a doubt that more oversight and understanding of AI models will help us make the technology more secure (despite criticism). Given the computation needs of modern interpretability methods along with AI transparency compliance, interpretability and oversight appears to be well-aligned with commercial interests.
Problems in AI transparency and monitoring
- Tracing AI decision-making: In high-security domains like medical imaging or AI-assisted planning, understanding a model's decision-making process is essential for trust. Current methods involve retrieval and factored cognition, which can be improved and integrated further. The ability to retrace the reasoning behind problematic outputs will also be important in preventing repeated incidents.
- Better AI scrutiny: Creating better explainability tools will make AI model outputs easier to scrutinize for expert and non-expert users.
- Scalable incident monitoring: Effective monitoring of unintended model behaviors is crucial for product usability, incident reporting, auditing, reinforcement learning from human feedback, and usage statistics. Clients like OpenAI, with extensive API usage data, require innovative scalable oversight methods for effective analysis.
- Expanding model-scale interpretability: Current full-model interpretability methods demand significant computational resources. As a result, making model-scale interpretability work will likely require commercial infrastructure.
Examples
- DeepDecipher: “A web page and API that provides interpretability information from many sources on various transformer models.”
- Fiddler: “AI Observability: Build trust into AI with explainable AI.”
- Prometheus: “Power your metrics and alerting with the leading open-source monitoring solution.”
Alignment
Problems related to user intent alignment, misalignment risks of agentic systems, and user manipulation. Related fields include red teaming, causal incentives, and activation steering.
Alignment is an important part of ensuring both model reliability along with further security against deceptive and rogue AI systems. This objective aligns closely with commercial interests, specifically the need to improve model alignment, minimize unnecessary hallucinations, and strengthen overall reliability.
Approaches to commercial alignment
- Safe-by-design architectures: Innovate new architectural designs that are inherently safe, such as less agentic or more interpretable models.
- Alignment-focused training datasets: As frontier models are often trained on diverse internet data (including illicit content) and require significant investment, there are strong commercial interests to provide guarantees for aligned outcomes. This includes developing data harmfulness classification methods, RLHF, and improving human value alignment on fine-tuning datasets.
- Robust alignment methodology: Refine methods like reinforcement learning from human or AI feedback, fine-tuning, and transfer learning. Current techniques are unstable and can lead to security risks, such as jailbreaks and model deception.
- Model blue-teaming: Develop products and solutions for improving model alignment with user intent, functionality, and tool usage in major models. Blue-teaming involves mitigating the risks implied by red-teaming efforts.
- Model red-teaming: Offer scalable or consultancy-based red teaming services to help companies identify and correct errors before they reach clients.
Examples
- IBM AI Fairness 360: “This extensible open source toolkit can help you examine, report, and mitigate discrimination and bias in machine learning models throughout the AI application lifecycle.”
- Google Deepmind (a): “Solving intelligence to advance science and benefit humanity.”
AI Defense
Problems related to systemic risks of AI, improved cyber offense capabilities, and difficulty of auditing. Related fields include cybersecurity, infrastructure development, and multi-agent security.
AI defense is critical to safeguard infrastructure and governments against the risks posed by artificial general intelligence and other AI applications. Given the magnitude of this challenge, supporting solutions on a comparable scale aligns well with commercial structures.
Concrete societal-scale needs for AI defense
- AI-driven cyber defense: With the advent of general intelligence, cyber offenses are expected to accelerate. Creating scalable defenses for the broader attack surface of AI systems, along with enhancing traditional cyber defenses, is vital for protecting infrastructure and ensuring national security.
- Scalable AI and infrastructure vulnerability detection: Using AI to scan for vulnerabilities across services and apps can lead to robust, proactive cybersecurity measures for a safer internet.
- Auditing firmware & hardware: Compliance with computing and training governance is likely to become mandatory. Developing methods for adherence to these constraints is a critical task.
- Systemic security: Similar to isolated communication networks in critical infrastructures like national energy control, robust measures against AI network-based cyber offenses are essential. This presents a significant opportunity for companies specializing in industrial engineering and systems security.
- Combatting misinformation: Democratic processes are at-risk to deepfakes, misinformation, and malicious intervention, and AI will exacerbate these issues.
Examples
- Darktrace: “Prevent targeted attacks with the only AI in cybersecurity that adapts to your unique business”
- CrowdStrike: “The world's leading AI-native cybersecurity platform.”
- Siemens: “Cybersecurity is a highly sensitive area that demands a trustworthy partner. A technology partner who understands how products, systems, and solutions integrate with the processes and people behind them and how people interact with them.”
Wrapping up
We are optimistic about the potential of AI safety in commercial domains and hope that this can serve as an inspiration for future projects. We do not expect this overview to be exhaustive, and warmly invite you to share your thoughts in the comments. Please reach out via email if you're interested in developing AI safety solutions or considering investments in these types of projects.
Apart is an AI safety research organization that incubates research teams through AI safety research hackathons and fellowships. You can stay up-to-date with our work via our updates.
Appendix: Risks of commercial AI safety
Here are a few risks to be aware of when launching commercial AI safety initiatives:
- Maintaining control: Taking on investment late is a good idea to keep owner dilution to a minimum and retain control of the company, especially to avoid commercial incentives taking over. You also need to ensure that your bylaws and investor agreements are heavily skewed in your favor (I recommend the short book called Fundraising). Always remember that investors invest for profit.
- Incentive alignment: It's important that your financial incentives are aligned with the AI safety purposes, otherwise the core research and development will likely skew in a less impactful direction.
- Scaling too fast: The culture of high growth can easily divert your original purpose. Be careful of scaling before 1) you have reached product-market fit (e.g. $1M ARR) and 2) you have solved the incentive alignment. You need to build your system for growth before growing. I recommend reading Disciplined Entrepreneurship or The Great CEO Within for more context on these questions.
Appendix: Further examples
- Anthropic (bias): “Whose opinions are the responses of Large Language Models (LLMs) most similar with when considering the perspectives of participants across the world?”
- Imbue (a, safe-by-design): “We want machines that learn the way humans do”
- Grafana: “Compose and scale observability with one or all pieces of the stack”
- Ought: “Ought is a product-driven research lab that develops mechanisms for delegating high-quality reasoning to advanced machine learning systems.”
- Rebuff.ai: “A self-hardening prompt injection detector”
- METR: “METR works on assessing whether cutting-edge AI systems could pose catastrophic risks to civilization.”
Appendix: Funding calculations
| Category | Sub-category | Amount | Source |
|---|---|---|---|
| Capabilities | Funding | $66.8 billion | Top Global AI Markets (trade.gov) |
| AI safety | OpenPhil | 50M | An Overview of the AI Safety Funding Situation — LessWrong |
| AI safety | Government | 127M | Introducing the AI Safety Institute - GOV.UK (www.gov.uk) |
| AI safety | Commercial | 32M | An Overview of the AI Safety Funding Situation — LessWrong |
| AI safety | SFF | 30M | An Overview of the AI Safety Funding Situation — LessWrong |
| AI safety | Academia + NSF | 11M | An Overview of the AI Safety Funding Situation — LessWrong |
| AI safety | Potential | 60.2B | Capabilities minus all AI safety |
Doesn't the $67 billion number cited for capabilities include a substantial amount of work being put into reliability, security, censorship, monitoring, data protection, interpretability, oversight, clean dataset development, alignment method refinement, and security? At least anecdotally the AI work I see at my non-alignment-related job mainly falls under these sorts of things.
You are completely right. My main point is that the field of AI safety is under-utilizing commercial markets while commercial AI indeed prioritizes reliability and security to a healthy level.