There has been a substantial update since this was first posted. The lead authors of the World Happiness Report have now reached out to me directly. Details at the bottom.
The World Happiness Report (WHR) is currently the best known and most widely accepted source of information on global life satisfaction. Its six-variable model of satisfaction is reproduced in textbooks and has been published in the same form by the United Nations since 2012. However, almost no justification is given for why these six variables are used. In response, I attempted to do the only thing I thought was responsible -- do an exhaustive search over 5,000 variables in international datasets, and see empirically what actually predicts satisfaction. I've consulted with life satisfaction specialists both in economics departments and major think tanks, and none thought this had been done before.
The variables that are selected by this more rigorous method are dramatically different from those of the WHR, and the resulting model is substantially more accurate both in and out of sample. In particular, the WHR leaves out entire categories of variables on subjects as varied, and as basic, as education, discrimination, and political power. Perhaps most dramatically, the way the WHR presents the data appears to suggest that GDP explains 40% of model variation. I find that, with my measurably more accurate model, it in fact predicts 2.5%.
The graph below ranks the model variables by contribution, which is the amount of the total satisfaction of a country they are estimated to predict. For interpretation, 1.5 points of satisfaction on the 11-point scale is equivalent to the grief felt at the death of a life partner, meaning these numbers may be numerically small, but they are enormously significant behaviorally.

I have already gotten extremely positive feedback from academic circles, and have started looking for communities of practice that would find this valuable.
A link to the paper is below:
https://dovecoteinstitute.org/files/Loewi-Life-Satisfaction-2024.pdf
UPDATE: The lead authors of the World Happiness Report have now reached out to me directly. Already this is a shock, as I had no idea if my findings would even be taken seriously. The authors suggested changes to my methods, and I have spent the last few weeks incorporating their suggestions, during which I thought it was only responsible to take the post down. However having now taken their recommendations into account -- I find the results are in every meaningful way identical, and in fact now substantially reinforced. The post and paper have been updated to reflect what changes there were.
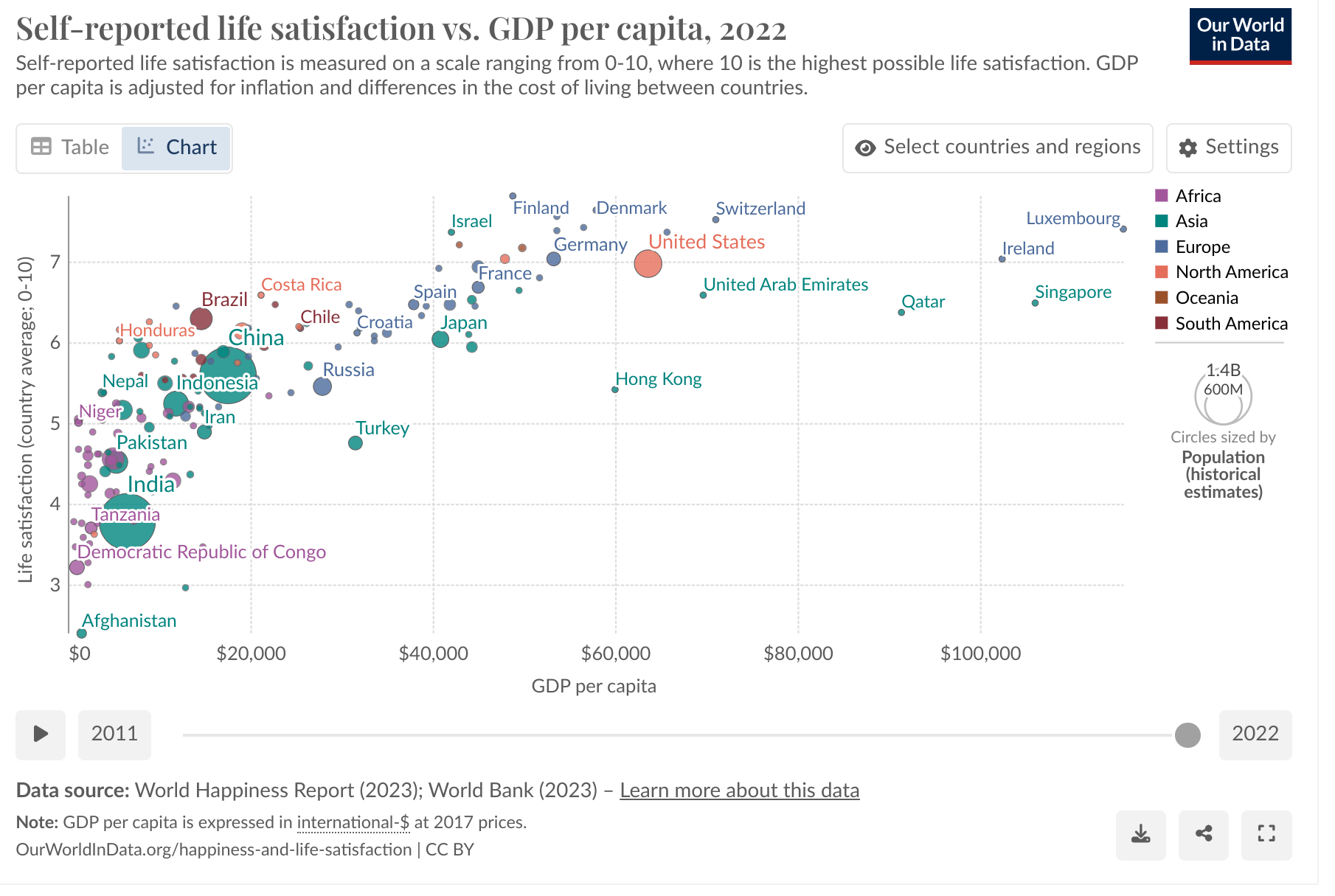


Here's the OWID charts for life satisfaction vs. GDP/capita. First linear (per the dovecote model):
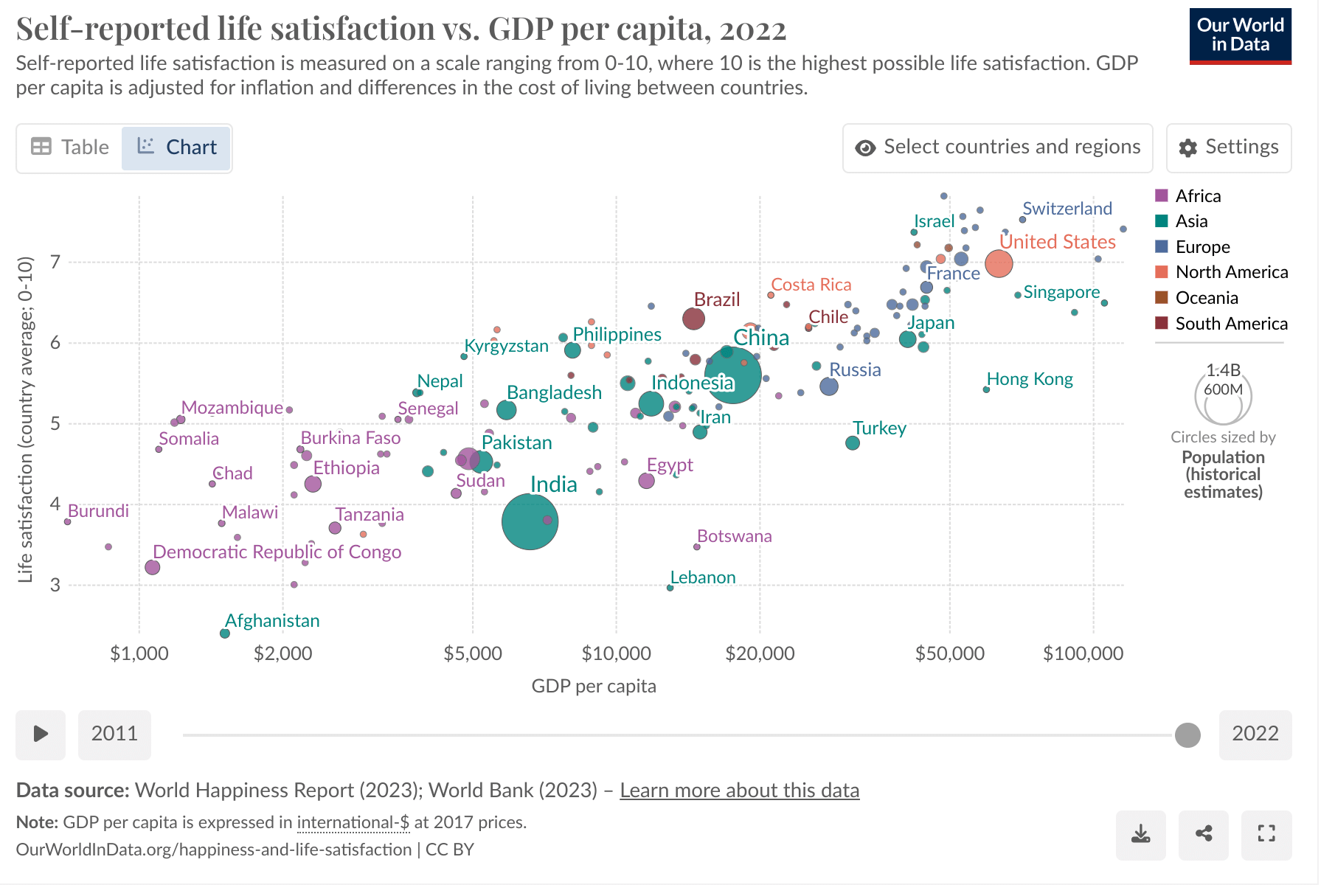
Now with a log transform to GDP/capita (per the MHR):
I think it is visually clear the empirical relationship is better modelled as log-linear rather than linear. Compared to this, I don't think the regression diagnostics suggesting non-inferiority of linear GDP (in the context of model selected from thousands of variables, at least some of which could log-linearly proxy for GDP, cf. Dan_Key's comment) count for much.
Besides the impact of GDP (2.5% versus 40%), I'd expect which other variables end up being selected also to be sensitive to this analysis choice. Unfortunately, as it is the wrong one, I'd expect (quasi-)omitted variable bias to distort both which variables are included, and their relative contributions, in the dovecote model.