Update: this post was completed about 1 month after I started reading and considering the ideas/arguments for longtermism. After further reading and discussion with other EAs, a few of my opinions no longer correspond with this analysis. I still think many of the ideas might be useful to some, but I have realized most (but not all) of my beliefs correspond with Brian Tomasik. Even though I'm a total (not negative) utilitarian and more optimistic about the future than him, I still think reading his essays might be a better use of your time.
Summary
In the forthcoming post, I will argue why wild animal welfare (WAW) MIGHT be a more pressing cause area than x-risk prevention based on total utilitarianism, even after taking into account longtermism. I will show how you can make the same calculation yourself (checking if you agree) and then outline a rationale for how you could apply this estimation.
The scenario of humans outnumbering (wild) animals is improbable, primarily due to the vast number of wildlife and the potential for their spread to space, the perspective of total utilitarianism suggests that human suffering may be deemed negligible. Additionally, because sentient beings originating from Earth can live at least 1034 biological human life-years if we achieve interstellar travel, working on anything that doesn't cause permanent effects is also negligible. Consequently, our paramount concern should be decreasing x-risk or increasing net utilities “permanently”. If one is comparatively easier than the other, then that’s the superior option.
I will outline a formula that can be used to compare x-risk prevention to other cause areas. Subsequently, I will present a variety of arguments to consider for what these numbers might be, so you can make your own estimations. I will argue why it might be possible to create “permanent” changes in net utilities by working on WAW.
My estimation showed that WAW is more than twice as effective as x-risk prevention. Due to the high uncertainty of this number, even if you happen to concur with my estimation, I don’t see it as strong enough evidence to warrant a career change from one area to the other. However, I do think that this could mean that the areas are closer in impact than many longtermist might think, and therefore if you’re a better fit for one of them you should go for that one. Also, you should donate to whichever one is the most funding-constrained.
I will also delve into the practical applications of these calculations, should you arrive at a different conclusion than me.
(Note that I’m not in any way qualified to make such an analysis. The analysis as a whole and the different parts of the analysis could certainly be made better. Many of the ideas and made-up numbers I’m presenting are my own and therefore may differ greatly from what a more knowledgeable or professional in the field would think. To save time, I will not repeat this during every part of my analysis. I mainly wanted to present the idea of how we can compare x-risk prevention to WAW and other cause areas, in the hope that other people could use the idea (more than the actual estimations) for cause prioritization. I also want this post criticized for my personal use in cause prioritization. So please leave your questions, comments and most of all criticisms of my theory.)
(Note regarding s-risk: this analysis is based on comparing working on WAW to working on x-risk. While it does consider s-risks, it does not compare working on s-risks to other causes. However, the analysis could relatively easily be extended/changed to directly compare s-risks to x-risks. To save time and for simplifications, I didn’t do this, however, if anyone is interested, I will be happy to discuss or maybe even write a follow-up post regarding this.)
Intro
While I have for a long time been related to EA, I only recently started to consider which cause area is the most effective. As a longtermist and total utilitarian (for the most part), finding the cause that increases utilities (no matter the time or type of sentient being) the most time/cost-effectively is my goal. I got an idea based on a number of things I read, that against the belief of most EAs, WAW might be a more pressing cause area than x-risk prevention. Since this question is quite important for my impact, I thought instead of speculating, I would make my own analysis (aka speculation with numbers), see if I change my mind, and let the analysis be criticized (see appendix 1: for which questions about my theory I want answered).
I suspect my theory is likely incorrect due to the following reasons:
- I don’t have any credentials that make me qualified to make such an analysis.
- This is my first post.
- Due to personal reasons, I’m biased towards working on WAW.
- This theory is based on the principles of total utilitarianism, and may therefore not overlap with your views.
- The theory is mainly based on the assumption that working on WAW now could potentially cause permanent changes to how we treat (wild) animals in the future (read why I think this might be the case in my section “Tractability of the cause itself (WAW)”).
- This is all highly speculative.
Two framework ideas for the theory
The following arguments which will be presented are based on the theory that human welfare is negligible compared to wild animal welfare. You can read “abrahamrowe” post if you want a further explanation.[1] However, here I will just give (my own) short explanation: There are 1015 wild animals alive currently (more according to some sources but not super relevant for my theory).[2] While humans could theoretically exceed this number if we achieve interstellar travel, this is only assuming there will be no wildlife in space.
My theory is also based on the idea that any scenario where an x-risk occurs, the utilities experienced (positive and negative, and by both humans and animals) before the x-risk are negligible. Let me explain. Nick Bostrom estimates that the accessible universe can support at least 1034 biological human life-years.[3] If humans were to avoid an x-risk until then, it undoubtedly would be because humans had reached a stage where x-risks practically were impossible to occur (existential security). E.g. because we had an AI in place that could prevent any unintentional (or intentional) x-risk from occurring, or because multiple civilizations in space would live so independently that catastrophes would be unable to affect the whole human species. If we were to reach this level of security, it would likely occur within a fraction of this timespan. Therefore anything that doesn't impact utilities “permanently'' (until all sentient creatures will die off by uncontrollable courses e.g. after the 1034 years) or increase the likelihood that we will reach this level of security, is negligible in comparison (which I guess is also kind of similar to the general argument for longtermism).
Formula for comparing impact
So if you believe that the two previously mentioned statements are true, then we basically have two options for making the world better: decreasing the likelihood of x-risk or changing the world in such a way that net utilities will be more positive "permanently". I will now present a formula that can be used to compare these two options.
Simple formula
First of all, if you think it's 100 % guaranteed that the future will be net positive, then whether you should work on WAW or x-risks depends on two factors: how likely you think it is that an x-risk will occur at some point in the future and how tractable you think the two cause areas are. (Note: I will later in the post argue for what these numbers might be). Based on these two variables, we can use the following formula to calculate which cause is most effective:

(Note: I’m not a mathematician, so please let me know if there’s something wrong with any of my formulas. Also I’m sure there’s better variables which could have been picked.)
So x<1 means that WAW is more effective and x>1 means that x-risk prevention is more effective.
For example, let's say the likelihood of an x-risk happening at any point in the future is 50 %. Then this would mean that according to total utilitarianism, completely eliminating the chance that x-risk will ever occur, would be equivalent in value to doubling net utilities “permanently”.
So if you believe this to be the case, the determining factor for which area you should work on is tractability. Since this is quite unlikely for the EA movement to achieve, a more realistic way of saying it is: that decreasing the chance of x-risk by 1 percentage point will be equivalent to increasing net utilities by 1 %. However, if we think the likelihood of an x-risk ever happening is 75 %, then decreasing the chance of x-risk by 1 percentage point will be equivalent to increasing net utilities by 3 %.
While I have never personally seen it presented like this, I do see obvious reasons why most people would think that the former is easier than the latter (which would be aligned with current longtermist EA work). However, I will later present why I think this might not be the case.
Main formula
If you instead think the future will have net negative utilities, then working on reducing the likelihood of x-risk would be negative. So if you think this is the case, then working on the problem that would help ensure a positive future most effectively would be your best bet. I personally don't think this will be the case, however, I do think there is a risk that it will be. And if you think like me, this is still an argument for working on WAW instead of x-risks.
To make our "simple formula" more precise, we can include the possibility of a net negative future into our formula, creating our main formula:

(If you do not understand unegative I will try to explain it with an example: if we quantify the net positive utilities of the world, in case the world will be net positive, with the number 1, and then choose that unegative is equal to 2. Then this will mean that in case we end up with a world that is net negative, it will on average be twice as bad as if it were to become good, or the net utilities will be equal to -2)
The exact numbers are of course unknown, so you can enter your own estimations into the formula. E.g. this is how they will look for me:
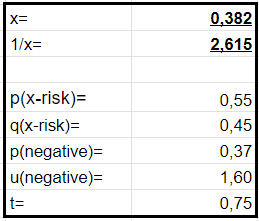
So based on my estimations, working on x-risk instead of WAW is 0,382 times more effective. Or dividing the number “1” by 0,382, we get the number of times more effective WAW is to x-risk: 2,615.
I will, for the rest of this post, argue why I chose these numbers. I’m not trying to argue that these numbers are correct, I just want to present some arguments that pull these numbers in different directions, and then I think it’s up to you to decide how the numbers should look, based on the strength of each argument.
What is the probability of an x-risk happening at any point in the future
I don’t think we have any current useful estimations for the likelihood of an x-risk happening in the long-term future (see Appendix 2: for my reasoning). I think for many of you, your own estimations might be your best bet. I will now try to give my own estimation, using mainly made-up numbers: My personal favorite estimation (mainly just because that’s the one I’m most familiar with) is the one by Toby Ord ("1 in 6" during the next century). If we assume that it will take us one millennium to reach existential security, and the risk will decrease by 20 % each century, we can calculate the probability of an x-risk ever occurring like this:
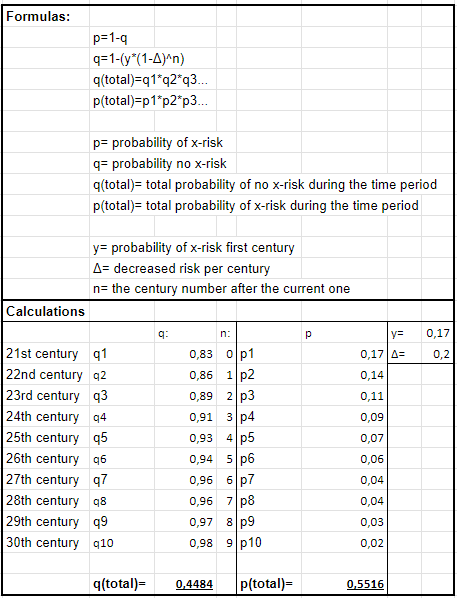
So based on my calculations, the probability of an x-risk ever occurring is ≈ 55 %. (Note: I will be happy to hear some of your guys' estimations. And if you want to play around with any of my estimations, here’s a link).
Net negative future
Many EAs think that the future will be good. However, the idea that the future might be bad is far from new. For example, Brian Tomasik wrote in 2013 about how we might be too optimistic about the future.[4] He also believes there’s a 70 % probability of space colonization causing an increase in total suffering (ignoring happiness).[5] And as mentioned before, the risk for a net negative future might be a reason against working on reducing x-risk (or more specifically human extinction), because this will simply ensure that the negative future will occur. Many of the reasons are related to s-risk. Once again, we only care about scenarios where the suffering is “permanent”, any others are negligible.
I will now give my estimation (again using made-up numbers) for how likely a number of different scenarios are and how bad they would be in comparison to a net positive future:
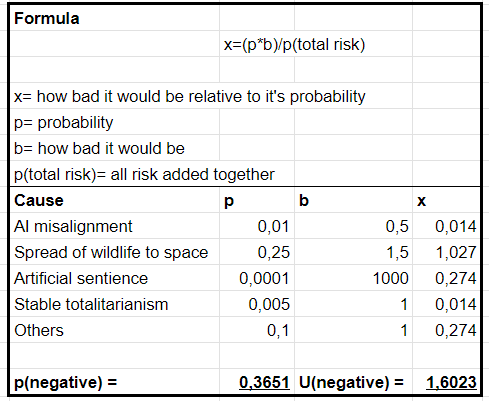
(“others” especially refer to once we are unable to imagine)
(See Appendix 3: for some thoughts on how to do the calculation)
These numbers reflect my own beliefs based on my limited knowledge, and will most likely differ greatly from yours (see Appendix 4: for why I chose these numbers).
Many longtermist may put a lot higher weight on “artificial sentience”, which could easily make the case for working directly on this cause area instead. Also, I think for a number of you, your calculations will be so that when you multiply “p(negative)” by “u(negative)” it will equal more than 1, meaning that you believe that the future will on average be net negative. Therefore the mean expected outcome of working on x-risk reduction would be negative.
Tractability
I think we can divide tractability into three parts: “tractability of the cause itself”, “tractability based on personal fit” and “tractability as the means of neglectedness”. All three, but especially the last one, are dependent on time. And personal fit obviously depends on the person. This is just to say that the tractability may vary greatly over time and from person to person. I will first give arguments to consider for each, and then give my own estimation.
Note that for calculating tractability I will specifically use AI-alignment as my example. However, since this is properly the most tractable x-risk-related cause compared to its scale, this will make a stronger case for working on x-risk than other x-risk-related causes e.g. preventing catastrophic pandemics. I will take into account that AI-related x-risk only makes up part of x-risk during my calculation of “tractability of the cause itself”.
Tractability of the cause itself
To clarify, we’re in itself, not interested in the tractability of the cause area in general. While this is important for our evaluation, what we’re truly interested in is the tractability of the cause area achieving one of the following: reducing the probability of an x-risk happening at any point in the future by 1 percentage point or increasing the net utilities of the future by 1 % “permanently”. I will talk about each separately.
Tractability of the cause itself (x-risk reduction)
There are several ways you can work on reducing x-risk, in the area of AI alignment you can do e.g. technical research on how to create safe AI systems, strategy research into the particular risks AI might pose, and policy research into ways in which companies and governments could mitigate these risks. And in different areas, there are similarly many options. Here’s a quote from 80.000 hours, on working on AI alignment: “So I think it’s moderately tractable, though I’m highly uncertain — again, assessments of the tractability of making AI safe vary enormously.”[6]
As explained earlier, the higher the likelihood of an x-risk, the more important the cause area is, according to our equation. However, this might make the cause area less tractable. Because if the likelihood is high, it might not be enough for us to prevent an x-risk once. Preventing an x-risk once might only save us temporarily. Or in other words, decreasing the probability of an x-risk ever occurring by 1 percentage point, will require more resources. Although this might not have such a big impact on the tractability, since if the cause of the x-risk in these scenarios are similar, e.g. both are related to AI, then the work used to prevent the first one might help prevent the next one.
Tractability of the cause itself (WAW)
(Note that most of my ideas in this section are inspired by the post by saulius “Wild animal welfare in the far future”. [7] However, not stating our values/beliefs to be homogeneous.)
And now, finally, for the elephant in the room - is it possible to increase net utilities permanently? Truthfully… I have no idea, but I think, based on my own educated guess, that the likelihood and scale are enough to seriously consider the idea. I will now present a possible scenario where this could happen:
Based on WAW research on earth, we realize that there's no possible way (with the use of any interventions) to create environments where wild animals will have net positive lives. Therefore we will never bring animals to space (e.g. do to an international agreement). Or similarly, we learn that certain species or even entire classes of animals are practically unable to experience net positive lives. Therefore we insure to prevent these species from colonizing other planets.
I think the probability of spreading wildlife to space is pretty high. It’s quite likely that at least some people will think spreading wildlife is the morally right thing to do. This could e.g. be done by directed panspermia (deliberate transport of microorganisms into space to be used as introduced species on other astronomical objects), terraforming or other ways. Especially because nature, by the majority of people, is seen as positive. There’s also the chance of accidental spread. For example, spacecraft sent from Earth for scientific or colonization purposes might be contaminated with microorganisms. These microorganisms might evolve into sentient beings. There is an international law to prevent this, though it is not well enforced[8].
Working on WAW could help us to achieve one or both of the following:
- Decrease the amount of animals in space
- Increase the welfare of the animals in space (e.g. by using interventions or intentionally making artificial ecosystems that ensure better welfare).
While most people might be against the spread of wildlife to space, the choice might not be decided by the collected human species. It could be decided by an individual in power or if certain technologies could become widespread enough, it could become possible for many individuals to do by themself.
You might think that this would only be a temporary problem since these scenarios are reversible. However, technologies able to eradicate entire biospheres likely would be limited to large organizations or nonexistent for security reasons. Meaning there has to be widespread agreement to cause this reversal. But since it’s way easier to convince someone to avoid creating unnatural life, which might be unenjoyable, than it is to convince someone to destroy life that’s already existing, it seems that preventing the spread of wildlife could cause long-term changes.
Here is a list of ways we could work on this issue (directly copied from the post by saulius[9]):
“To reduce the probability of humans spreading of wildlife in a way that causes a lot of suffering, we could:
- Directly argue about caring about WAW if humans ever spread wildlife beyond Earth
- Lobby to expand the application of an existing international law that tries to protect other planets from being contaminated with Earth life by spacecrafts to planets outside of our solar system.
- Continue building EA and WAW communities to ensure that there will be people in the future who care about WAW.
- Spread the general concern for WAW (e.g., through WAW documentaries, outreach to academia).”
You might argue that spreading WAW values is a quite indirect and potentially inefficient way of preventing a future possible problem. Which I do somewhat agree with. However, the same argument can be used against working on AI alignment, since current machine learning doesn't bring us closer to AGI, meaning that the importance of current research is questionable.[10] Even though I still think a lot of it will be useful.
In terms of the tractability of the cause area itself in general, I think it is less tractable than many other EA causes, nevertheless I think it’s more tractable than a lot of EAs seem to think. Several interventions seem doable (which in itself might have limited long-term effect, but could help the movement grow), for instance: wild animal vaccination, helping wild animals affected by weather events, helping wild animals in urban environments, animal contraception, and developing wild animal welfare assessment methods.[11] There are tools, such as the reference system and adaptive management, which make the uncertainty of these interventions not intractable.[12]
Neglectedness (as a part of tractability)
Most people reading this have properly heard numerous times that neglectedness can be used to assess how effective a cause area is. But you may not have realized that this is simply an indicator for how tractable the area is.
Both causes are obviously, at least in my opinion, extremely neglected compared to their scale. For AI alignment the numbers are according to 80.000 hours as follows: Around $50 million was spent in 2020 and around an estimated 400 people (90% CI = 200-1.000) working directly on the problem.
I have been unable to find estimations for the amount of money or FTE (“full-time equivalent“) that is allocated to WAW. I will now try to make a very rough estimation for the latter. According to ACE, they know fewer than five charities that focus on improving wild animal welfare. And they currently only recommend one of them. This organisation is Wild Animal Initiative and they have 19 employees.[13] [14] However some organizations work partly on WAW. I will try to take this into account.
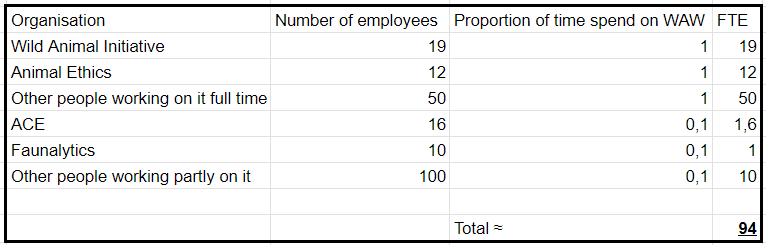
I do expect the numbers to increase proportionally more for AI-alignment because it’s about a developing technology, so the area will properly create more news. I also think WAW is less likely to be solved by non-EAs because everyone cares about creating a safe future (even though most care less than they should), but very few care about natural suffering. And I personally think it’s easier to convince someone of AI-alignment than WAW. However, I do also think that some people working on the issue of factory farming, could be convinced of switching to WAW, especially when we come closer to mass producing cultured meat. However, for simplification, I have not considered the future growth of the two movements in my calculation.
Calculating “t” (tractability)
I will calculate t by multiplying the three areas: “tractability of the cause itself * “tractability based on personal fit” * “tractability as the means of neglectedness”. So first we need to decide the numbers.
See my estimation (and explanation for chosen variables) for “tractability of the cause itself” or “x(cause)” below:

Explanation for chosen variables:
- “p(risk)”: According to Tobi Ord's estimates, the existential risk associated with unaligned AGI accounts for 60 % of the total risk next century. And since AGI “only” accounts for a part of x-risks, this reduces the scale of the cause area.
- “t(risk)”: I do think both of them are less tractable than many other cause areas. Based on having more public and professional support and less resistance, I do think x-risk prevention is a more tractable area in terms of the “cause itself”. Therefore I put this value to 2.
- “p(WAW)”: Based on my own (conservative) guess. Because based on my framework, if animals never leave to space, working on WAW will only cause temporary change, meaning that it would be negligible according to my framework. Therefore the effect is only counted if this is the case.
- “b”: Based on my own guess.
For our example, I will simply give the number 1 for personal fit, meaning that the personal fit is equal between the course areas. Remember that based on the way I made the formula, “t” is the number of times more tractable x-risk is than WAW. So if you set this value to 2, then this means your personal fit is twice as good for x-risk. And if you set the value to 0,5, then this means your personal fit is twice as good for WAW. When you set this number for yourself, remember how important personal fit is. Generally, the top 10% of the most prolific elite can be credited with around 50% of all contributions. [15] So you might have to make this number differ further from 1 than you might think.
According to 80000hours, “If you care about an output K times more than society at large, then (all else equal) you should expect investing in gaining that output to be K times more effective than making other investments.”[16] Meaning that if all else equal, one area being twice as neglected, would make it twice as effective to work on. For our example, we can divide the number of WAW workers by the number of AI-alignment workers:
94/400= 0,235.
So: t = 3,2*1*0,235 ≈ 0,75. Or in other words: WAW is about 1,34 times more tractable than x-risk.
Possible conclusions from the calculation (discussion)
Based on my estimations, working on WAW is more than twice as effective. However, due to the uncertainty of these numbers, I feel unable to even say with 51% certainty that WAW is more effective than x-risk prevention. Which currently is what I conclude from this data. Based on my beliefs on the future and the tractability of the causes, I can’t say with any level of certainty which cause is the most effective. Therefore if you agree with this statement, aiming for the area where you have the best personal fit is the most important.
Also due to the high uncertainty of the future, it might be so that the most effective cause area will be unaligned with our current estimations and or even by a “flow-through effect” (indirect effects of a charity's work). This is not to say we shouldn't try to make the estimations, but that in case of uncertainty, working on where you have the best personal fit, should properly be the deciding factor.
If you think there is a high risk for a net negative future or a non-negligible risk for an extremely negative future, then working on x-risk prevention might be net negative. Due to the uncertainty again, I don't think trying to increase the likelihood of human extinction would be a good idea, but trying to ensure a net positive future would be a better option than working on preventing x-risk. The uncertainty I have on whether or not the future will be net good or bad is definitely a motivation for me to prioritize WAW over x-risks. However, if you think artificial sentience is a likely s-risk, I think this could easily be the most effective cause area.
I think if other EAs do their own estimations, a lot of them will end up with x>1 (x-risk being more effective than WAW). I think most likely this will be due to them thinking WAW is less tractable than me. After all, it’s not often people talk about making “permanent” changes to utilities. I believe the spread of animals (or microorganisms that later might develop and become sentient) to space is very likely. And if it happens, it’s likely difficult to undo. I also think it’s the most likely s-risk and therefore WAW is potentially the most effective cause area so far. However, if you disagree with any of these statements, your value “t” will properly be higher (x-risk is more tractable in comparison to WAW) than mine. And so, it’s likely that another cause area is the most effective. I think, based on the cause areas I’m currently aware of, that x-risk, s-risk (especially related to artificial sentience), meta and WAW are at the top of cause areas if you're a total utilitarian and a longtermist. But I certainly could be wrong about this.
My recommendations on how to use this information
If you agree with me that we can’t say for certain which of the two cause areas are most effective:
- Work in the area where you have the best personal fit.
- If you’re doing earning to give - donate to whichever cause area is the most funding constraint currently. Historically WAW has been both funding and talent-constrained (my impression is more funding-constrained), whereas x-risks have been mainly talent-constrained, however, this seems to have changed recently.
If you think x-risk or WAW is a more effective cause area than the other:
- If you haven't started your career path or it can be changed with minimal impact, then change based on your findings.
- In general, I don’t recommend using this data to make career changes unless you're highly certain that working on one of the cause areas is more effective than the other (e.g. >80 % certainty).
- Remember that these numbers change over time, so due to this uncertainty, personal fit may still be the most important.
If you think the mean future is net negative:
- Work on WAW if you think the spread of wildlife is likely and AI sentience is unlikely.
- Work on AI sentience if you think it’s somewhat or highly likely.
- Work on s-risk prevention in general if you think multiple s-risk are of approximately equal importance when taking into account probability and significance.
—------------------------------------------------------------------
Appendices
Appendix 1: Things that I want answered about my theory
In general, I will be happy to hear any thoughts on my theory. Here is a list of ideas:
- Do you agree with my theory?
- Are any of my estimations (severely) improbable?
- Are there any technical or logical mistakes in my theory (e.g. incorrect formula or illogical arguments)?
- Are there any poorly made formulations that make my theory hard to understand?
- How does your calculation compare to mine?
- (Since I would prefer working on WAW, do you think it’s solely my personal bias that tries to rationalize an illogical, selfish decision?)
Appendix 2: Why I don’t consider any estimation for x-risk in the longterm future as strong evidens
There have been several estimations and surveys on the likelihood of x-risks in the near term future, e.g. Toby Ord’s estimation of "1 in 6" in the next century, and the Global Catastrophic Risks Survey (Sandberg and Bostrom 2008) found a median estimation of 19% probability among mainly academic experts on various global catastrophic risks, that the human species will go extinct before the end of this century.
Although this might be useful information in some instances, it’s not that helpful in our calculation. What we’re interested in is the probability of the “long longterm future”. Here are the only two estimations I could find of the next 5 centuries or longer:
- Humanity has a 95% probability of being extinct in 7,800,000 years, (J. Richard Gott, III 1993)[17]
- In 1996, John A. Leslie estimated a 30% risk over the next five centuries (equivalent to around 9% per century, on average) [18]
Some quick thoughts on the two estimations (note: I’m certainly not qualified in commenting on the estimations, and I have not used extensive time doing research):
- Both of them are more than 20 years old, so they might not reflect more recent information.
- Both, but especially the first one is largely based on the controversial Doomsday argument, while I do like the argument, I think it’s too speculative and holds some logical flaws e.g. observer selection effect.
- The first one is partly based on the idea that we’re unlikely to colonize the Galaxy. While I do think there is a significant chance that humans will never reach interstellar travel, I think presumably it will eventually happen. Read this post to learn why I think so. [19]
- (I, with my minimal time using to write this post, was unable to find out how Leslie came to the exact number of 30)
Appendix 3: Thoughts on how to do the calculation on “net negative future”
- Remember these numbers are made to be used for the formula. So it’s not about the probability that this future will happen in total, it’s instead about the probability, that if there will be no x-risk, there will be x probability for any of these scenarios to happen.
- Note that if you're using this calculation to compare working on an area that could be both an x-risk and a s-risk (e.g. AI misalignment), this should be reflected in your calculations. This could for example be done by instead of adding this specific number together with the others, you would instead minus it (because you’re both working on decreasing the likelihood of this specific negative future and increasing the chance that there will be a future at all). (Note that I did not do this in my calculation for the sake of simplification and because it would have minimal impact on the result).
- p(total risk) gets added together instead of multiplying the probability of it not happening (which was what we did in the calculation of x-risks) because these risks can coincide.
Appendix 4: Thoughts on why I chose these numbers for “net negative future”
- I may have put “b” to be lower than what you may expect, because of my high thoughts of how positive the future could be. I also think that if done right, there is a potential chance that we could have “the opposite of s-risks” in the future, e.g. positive spread of wildlife to space or artificial sentience (however I don’t think any EAs should attempt to create this (yet), due to the high risk of doing the opposite).
- I put the “p” for “AI misalignment” as being pretty low, because most scenarios of AI misalignment, will according to my previous statements, be negligible (talking about s-risk, not x-risk). It would in this case only be relevant if AI keeps us and/or animals alive “permanently” to have net negative lifes (which most likely would require traveling outside of the solar system). I also put “b” pretty low, because I think most likely (but not guaranteed) the impact will be minimal to animals.
- The probability of “Spread of wildlife to space” was set pretty high, because I think it’s quite likely that some people will think that using our power to spread wildlife is the morally right thing to do. Especially because nature, by the majority of people, is seen as positive. There’s also the chance of accidental spread. For example, spacecraft sent from Earth for scientific or colonization purposes might be contaminated with microorganisms.
I've only skimmed this, but just want to say I think it's awesome that you're doing your own thinking trying to compare these two approaches! In my view, you don't need to be "qualified" to try to form your own view, which depends on understanding the kinds of considerations you raise. This decision matters a lot, and I'm glad you're thinking carefully about it and sharing your thoughts.
Thank you for your encouraging words! I appreciate your support and perspective.
For the kinds of reasons you give, I think it could be good to get people to care about the suffering of wild animals (and other sentient beings) in the event that we colonise the stars.
I think that the interventions that decrease the chance of future wild animal suffering are only a subset of all WAW things you could do, though. For example, figuring out ways to make wild animals suffer less in the present would come under "WAW", but I wouldn't expect to make any difference to the more distant future. That's because if we care about wild animals, we'll figure out what to do sooner or later.
So rather than talking about "wild animal welfare interventions", I'd argue that you're really only talking about "future-focused wild animal welfare interventions". And I think making that distinction is important, because I don't think your reasoning supports present-focused WAW work.
I'd be curious what you think about that!
I do agree that current WAW interventions have a relatively low expected impact compared with other WAW work (e.g. moral circle expansion) if only direct effects are counted.
Here are some reasons why I think current interventions/research may help the longterm future.
So I think current interventions could have a significant impact on moral circle expansion. Especially because I think you have to have two beliefs to care for WAW work: believe that the welfare of wildlife is important (especially for smaller animals like insects, which likely make up the majority of suffering) and believe that interfering with nature could be positive for welfare. The latter may be difficult to achieve without proven interventions since few people think we should intervene in nature.
Whether direct moral circle expansion or indirect (via. interventions) are more impactful are unclear to me. Animal Ethics mainly work on the former and Wild Animal Initiative works mainly on the latter. I’m currently expecting to donate to both.
I think having an organization working directly on this area could be of high importance (as I know only the Center For Reducing Suffering and the Center on Long-Term Risk work partly on this area). But how do you think it’s possible to currently work on "future-focused wild animal welfare interventions"? Other than doing research, I don’t see how else you can work specifically on “WAW future scenarios”. It’s likely just my limited imagination or me misunderstanding what you mean, but I don’t know how we can work on that now.
Thanks for your reply! I can see your perspective.
On your last point, but future-focused WAW interventions, I'm thinking of things that you mention in the tractability section of your post:
That is, things aimed at improving (wild) animals' lives in the event of space colonisation.
Relatedly, I don't think you necessarily need to show that "interfering with nature could be positive for welfare", because not spreading wild animals in space wouldn't be interfering with nature. That said, it would be useful in case we do spread wild animals, then interventions to improve their welfare might look more like interfering with nature, so I agree it could be helpful.
My personal guess is that a competent organisation that eventually advocates for humanity to care about the welfare of all sentient beings would be good to exist. It would probably have to start by doing a lot of research into people's existing beliefs and doing testing to see what kinds of interventions get people to care. I'm sure there must be some existing research about how to get people to care about animals.
I'm not sure either way how important this would be compared with other priorities, though. I believe some existing organisations believe the best way to reduce the expected amount of future suffering is to focus on preventing the cases where the amount of future suffering is very large. I haven't thought about it, but that could be right.
Another thing on my mind is that we should beware surprising and suspicious convergence - it would be surprising and suspicious if the same intervention (present-focused WAW work) was best for improving animals' lives today and also happened to be best for improving animals' lives in the distant future.
I worry about people interested in animal welfare justifying maintaining their existing work when they switch their focus to longtermism, when actually it would be better if they worked on something different.
(I hope it’s not confusing that I'm answering both your comments at once).
While I will have to consider this for longer, my preliminary thought is that I agree with most of what you said. Which means that I might not believe in some of my previous statements.
Thanks for the link to that post. I do agree and I can definitely see how some of these biases have influenced a couple of my thoughts.
--
Okay, I see. Well actually, my initial thought was that all of those four options had a similar impact on the longterm future. Which would justify focusing on short-term interventions and advocacy (which would correspond with working on point number three and four). However after further consideration, I think the first two are of higher impact when considering the far future. Which means I (at least for right now) agree with your earlier statement:
While I still think the “flow through effect” is very real for WAW, I do think that it’s probably true working on s-risks more directly might be of higher impact.
--
I was curious if you have some thoughts on these conclusions (concluded based on a number of things you said and my personal values):
I gave this a read through, and then asked claude to summarise. I'm curious how accurate you find the following summary:
To broadly summarise my thoughts here:
● I agree with others that it's really great to be thinking through your own models of cause prio
● I am sceptical of S-Risk related arguments that point towards x-risk mitigation being negative. I believe the dominant consideration is option value. Option value could be defined as "keeping your options open in case something better comes up later". Option value is pretty robustly good if your unsure about a lot of things (like whether the long-term future is filled with good or bad). I suspect X-risk mitigation preserves option value particularly well. For that reason I prefer the phrase "preventing lock-in" vs "preventing x-risk", since we're focusing our sights on option value.
● Why should somebody suffering focused want to preserve option value? Even if you assume the long-term future is filled with suffering, you should have uncertainty factored inside and outside your model - which leads you wanting to extend the amount of time and people working on the problem, and the options they have to choose from.
Also, I agree with @Isaac Dunn that it's really great you're thinking through your own cause prioritisation.
Thanks for reading the post and for the summary. I find the summary quite accurate, but here’s a few notes:
Thanks alot for your thoughts on my theory. I never heard the term option value before, I’m gonna read more about it and see if it changes my beliefs. Here’s my thoughts on your thoughts:
- I didn't directly consider option value in my theory/calculation, but I think there is a strong overlap since my calculation only considers “permanent” changes (similar to the “lock-in” you're referring to).
- To clarify, I don’t believe that the mean future will be net negative. However the possibility of a “net-negative lock-in scenario” makes the expected value of working on preventing x-risk lower.
- I’m somewhat skeptical of the value of option value, because it assumes that humans will do the right thing. It’s important to remember that the world is not made up of EAs or philosophers and an AGI will likely not have much better values than the people who created it or controls it. And because of humans' natural limited moral circle, I think it's likely that the majority of sentient experiences (most likely from (wild) animals or artificial sentience) will be mostly ignored. Which could mean that the future overall will be net negative, even if we don’t end up in any “lock-in” scenario.
- With all that said, I still think the mean value of working on x-risk mitigation is extremely valuable. Maybe even the most or second most impactful cause area based on total utilitarianism and longtermism. But I do think that the likelihood and scale of certain “lock-in” net negative futures, could potentially make working on s-risk directly or indirectly more impactful.
Feel free to change my mind on any of this.
I'd argue there's a much lower bar for an option value preference. To have a strong preference for option value, you need only assume that you're not the most informed, most capable person to make that decision.
To intuition pump, this is a (good imo) reason why doctors recommend young people wait before getting a vasectomy. That person is able to use other forms of contraception whilst they hand that decision to someone that might be better informed (i.e. themselves in 10 years time).
Because of physical ageing, we don't often encounter option value in our personal lives. It's pretty common for choices available to us to be close to equal on option value. But this isn't the case when we are taking decisions that have implications on the long term future.
To what extent do you think approaches like AI-alignment will protect against S-risks? Or phrased another way, how often will unaligned super-intelligence result in a S-risk scenario.
______________
I want to try explore some of the assumptions that are building your world model. Why do you think that the world, in our current moment, contains more suffering than pleasure? What forces do you think resulted in this equilibrium?
I do agree that there are more capable people to make that decision than me and there will be even better in the future. But I don’t believe this to be the right assessment for the desirability of option value. I think the more correct question is "whether the future person/people in power (which may be the opinion of the average human in case of a “singleton democracy”) would be more capable than me?".
I feel unsure whether my morals will be better or worse than that future person or people because of the following:
Well, I think working on AI-alignment could significantly decrease the likelihood of s-risks where humans are the main ones suffering. So if that’s your main concern, then working on AI-alignment is the best option (both with your and my beliefs).
While I don't think that the probability of “AGI-caused S-risk” is high. I also don’t think the AGI will prevent or care largely for invertebrates or artificial sentience. E.g. I don’t think the AGI will stop a person from doing directed panspermia or prevent the development of artificial sentience. I think the AGI will most likely have similar values to the people who created it or control it (which might again be (partly) the whole human adult population).
I’m also worried that if WAW concerns are not spread, nature conservation (or less likely but even worse, the spread of nature) will be the enforced value. Which could prevent our attempts to make nature better and ensure that the natural suffering will continue.
And since you asked for beliefs of the likelihood, here you go (partly copied from my explanation in Appendix 4):
I would argue that whether or not the current world is net positive or net negative depends on the experience of invertebrates since they make up the majority of moral patients. Most people caring about WAW believe one of the following:
I’m actually leaning more towards the latter. My guess is there’s a 60 % probability that they suffer more and a 40 % probability that they feel pleasure more.
So the cause for my belief that the current world is slightly more likely to be net negative is simply: evolution did not take ethics into account. (So the current situation is unrelated to my faith in humanity).
With all that said, I still think the future is more likely to be net positive than net negative.
My main qualitative reaction to this is that the buckets "permanently improving life quality" and "reducing extinction risk" are unusual and might not representative of what these fields generally do. Like, if you put it like the above, my intuition says that improving life quality is a lot better. But my (pretty gut level) conclusion is the opposite, i.e., that long-term AI stuff is therefore more important because it'll also have a greater impact on long term happiness than WAW, which in most cases probably won't affect the long term at all.
I do somewhat agree (my beliefs on this has also somewhat changed after discussing the theory with others). I think "conventional" WAW work has some direct (advocacy) and indirect (research) influence on peoples values, which could help avoid or make certain lock-in scenarios less severe. However, I think this impact is less than I previously thought, and I'm now of the belive that more direct work into how we can mitigate such risk is more impactful.
If I understand correctly, you put 0.01% on artificial sentience in the future. That seems overconfident to me - why are you so certain it won't happen?
Yes that’s correct and I do agree with you. To be honest the main reasons were due to limited knowledge and simplification reasons. Putting any high number for the likelihood of “artificial sentience” would make it the most important cause area (which based on my mindset, it might be).
But I’m currently trying to figure out which of the following I think is the most impactful to work on: AI-alignment, WAW or AI sentience. This post was simply only about the first two.
When all of that’s been said, I do think AI-sentience is a lot less likely than many EAs think (which still doesn't justify “0.01%”). But note that this is just initial thoughts based on limited information. Anyways, here’s my reasoning:
However I do think the probability of me changing my mind is high.
I think this formula (under "simple formula")
is wrong even given the assumption of a net-positive future. For example, suppose both problems are equally tractable and there is a 50% chance of extinction. Then x=1. But if the future is only a super tiny bit positive on net, then increasing WOW longterm has massive effects. Like if well-being vs. suffering is distributed 51%-49%, then increasing well-being by 1% doubles how good the future is.
In general, I'm pretty sure the correct formula would have goodness of the future as a scalar, and that it would be the same formula whether the future is positive or not.
I don't entirely understand the other formula, but I don't believe it fixes the problem. Could be wrong.
If I understand you correctly you believe the formula does not take into account how good the future will be. I do somewhat agree that there is a related problem in my analysis, however I don't think that the problem is related to the formula.
The problem your talking about is actually being taken into account by "t". You should note that the formula is about "net well-being", so "all well-being" minus "all suffering". So if future "net well-being" is very low, then the tractability of WAW will be high (aka "t" being low). E.g. lets say "net well-being" = 1 (made up unit), than it's gonna be alot easier to increase by 1 % than if "net well-being" = 1000.
However I do agree that estimations for expectations on how good the future is going to be, is technically needed for making this analysis correctly. Specifically for estimating "t" and "net negative future" (or u(negative)) in for the "main formula". I may fix this in the future.
If you intended it that way, then the formula is technically correct, but only because you've offloaded all the difficulty into defining this parameter. The value of t is now strongly dependent on the net proportion of well-being vs. suffering in the entire universe, which is extremely difficult to estimate and not something that people usually mean by tractability of a cause. (And in fact, it's also not what you talk about in this post in the section on tractability.)
The value we care about here is something like well-beingwell-being −sufering. If well-being and suffering are close together, this quantity becomes explosively larger, and so does the relative impact of improving WAW permanently relative to x-risk reduction. Since again, I don't think this is what anyone thinks of when they talk about tractability, I think it should be in the formula.
I do agree that t in the formula is quite complicated to understand (and does not mean the same as the typical meant by tractability), I tried to explain it, but since no one edited my work, I might be overestimating the understandability of my formulations. "t" is something like “the cost-effectiveness of reducing the likelihood of x-risk by 1 percentage point” divided by “the cost-effectiveness of increasing net happiness of x-risk by 1 percent”.
When that’s been said, I still think that the analysis lacks an estimation for how good the future will be. Which could make the numbers for "t" and "net negative future" (or u(negative)) “more objective”.