(This is the second in a series of four posts about how we might solve the alignment problem. See the first post for an introduction to this project and a summary of the posts that have been released thus far.)
Summary
In my last post, I laid out the ontology I’m going to use for thinking about approaches to solving the alignment problem (that is, the problem of building superintelligent AI agents, and becoming able to elicit their beneficial capabilities, with succumbing to the bad kind of AI takeover[1]). In particular:
- I distinguished between option control (trying to ensure that an AI’s options have specific properties) and motivation control (trying to ensure that an AI’s motivations have specific properties);
- I suggested that our approach to the alignment problem may well need to combine both;
- I offered a framework for thinking about what this looks like (i.e., “incentive structure safety cases”);
- I described the space of high-level possibilities for option/motivation control in a bit more detail – in particular, distinguishing between what I call “internal” vs. “external” variables (roughly: the former are what a “black box” AI hides), and between “inspection” vs. “intervention” directed at a given variable.
- I discussed some of the dynamics surrounding what I call “AI-assisted improvements.”
In this post, I’m going to offer a more detailed analysis of the available approaches to motivation control in particular. Here’s a summary:
- I start by describing what I see as the four key issues that could make motivation control difficult. These are:
- Generalization with no room for mistakes: you can’t safely test on the scenarios you actually care about (i.e., ones where the AI has a genuine takeover option), so your approach needs to generalize well to such scenarios on the first critical try (and the second, the third, etc).
- Opacity: if you could directly inspect an AI’s motivations (or its cognition more generally), this would help a lot. But you can’t do this with current ML models.
- Feedback quality: to the extent you are relying on behavioral feedback in shaping your AI’s motivations, flaws in a feedback signal could create undesirable results, and avoiding such flaws might require superhuman evaluation ability. (Also you need to train on a sufficient range of cases.)
- Adversarial dynamics: the AI whose motivations you’re trying to control might be actively optimizing against your efforts to understand and control its motivations; and the other AI agents you try to get to help you might actively sabotage your efforts as well.
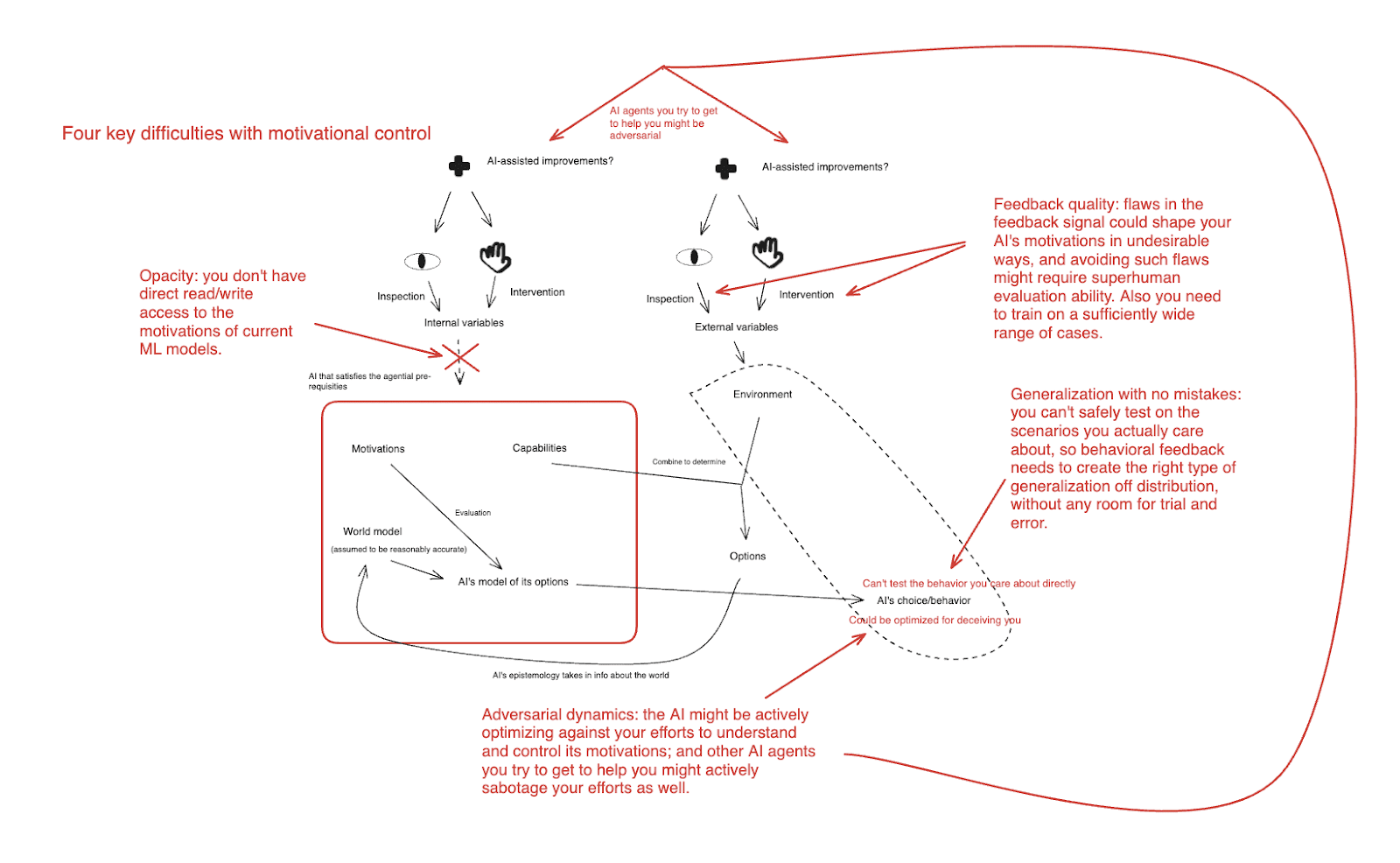
There four difficulties in a convoluted chart
- I then turn to discussing available approaches to addressing these difficulties.
- First, I’ll talk about approaches that are compatible with basically no “transparency,” and which rely almost entirely on behavioral feedback for shaping an AI’s motivations, and behavioral evidence for understanding those motivations.
- The three main approaches I discuss here are:
- A “baseline plan” that I call “behavioral feedback + crossing your fingers.” I.e., you give the best behavioral feedback you can (including via e.g. scalable oversight, adversarial training, etc), and then hope it generalizes well.
- I think we should try to do better than this.
- Using fake takeover options to become confident about the AI’s behavior on real takeover options.
- Using other behavioral approaches to develop adequate scientific understanding of generalization that you can be confident that the AI’s motivations will generalize well. (I call this “behavioral science of AI motivations.”)
- A “baseline plan” that I call “behavioral feedback + crossing your fingers.” I.e., you give the best behavioral feedback you can (including via e.g. scalable oversight, adversarial training, etc), and then hope it generalizes well.
- The three main approaches I discuss here are:
- I then turn to approaches that assume at least some degree of transparency.
- I then discuss three main approaches to creating transparency, namely:
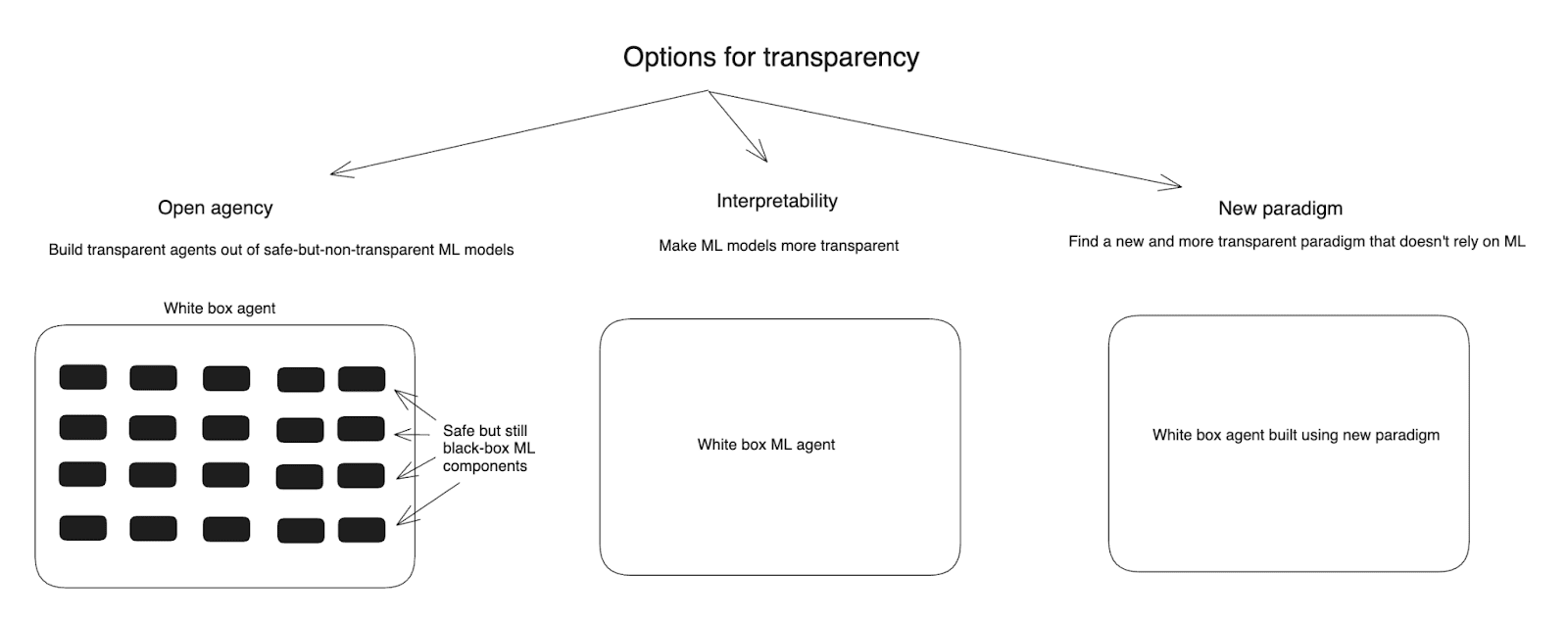
- “Open agency” (roughly: building transparent AI agents out of safe but-still-black-box ML models, a la faithful chain-of-thought);
- “Interpretability” (roughly: learning to make ML models less like black boxes);
- “New paradigm” (roughly: transitioning to a new and more transparent paradigm of AI development that relies much less centrally on ML – for example, on that more closely resembles traditional coding).
- I then discuss three main approaches to creating transparency, namely:
- First, I’ll talk about approaches that are compatible with basically no “transparency,” and which rely almost entirely on behavioral feedback for shaping an AI’s motivations, and behavioral evidence for understanding those motivations.
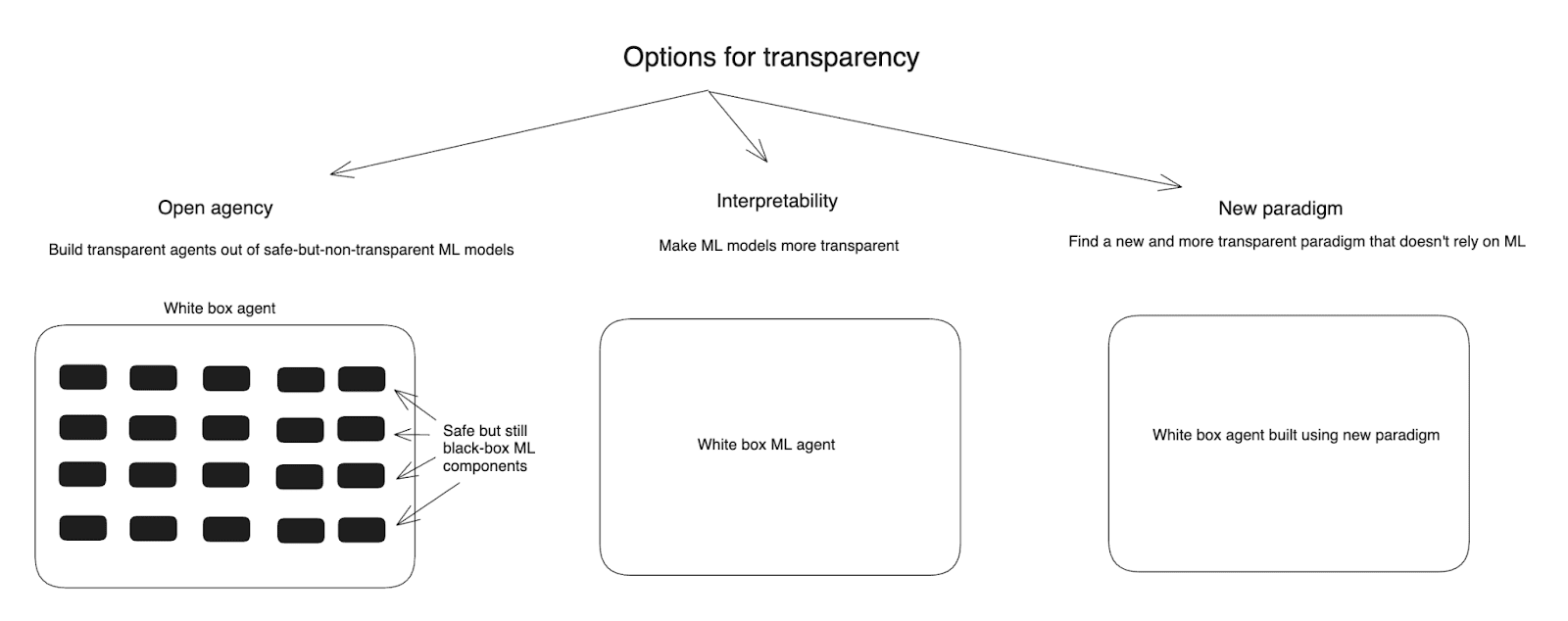
Diagram of the options for transparency I consider
- I further distinguish between attempting to target the AI’s motivations directly using a given approach to transparency, vs. attempting to target some other internal variable.
- Finally, I talk about how you might translate transparency about some internal variable into motivational control.
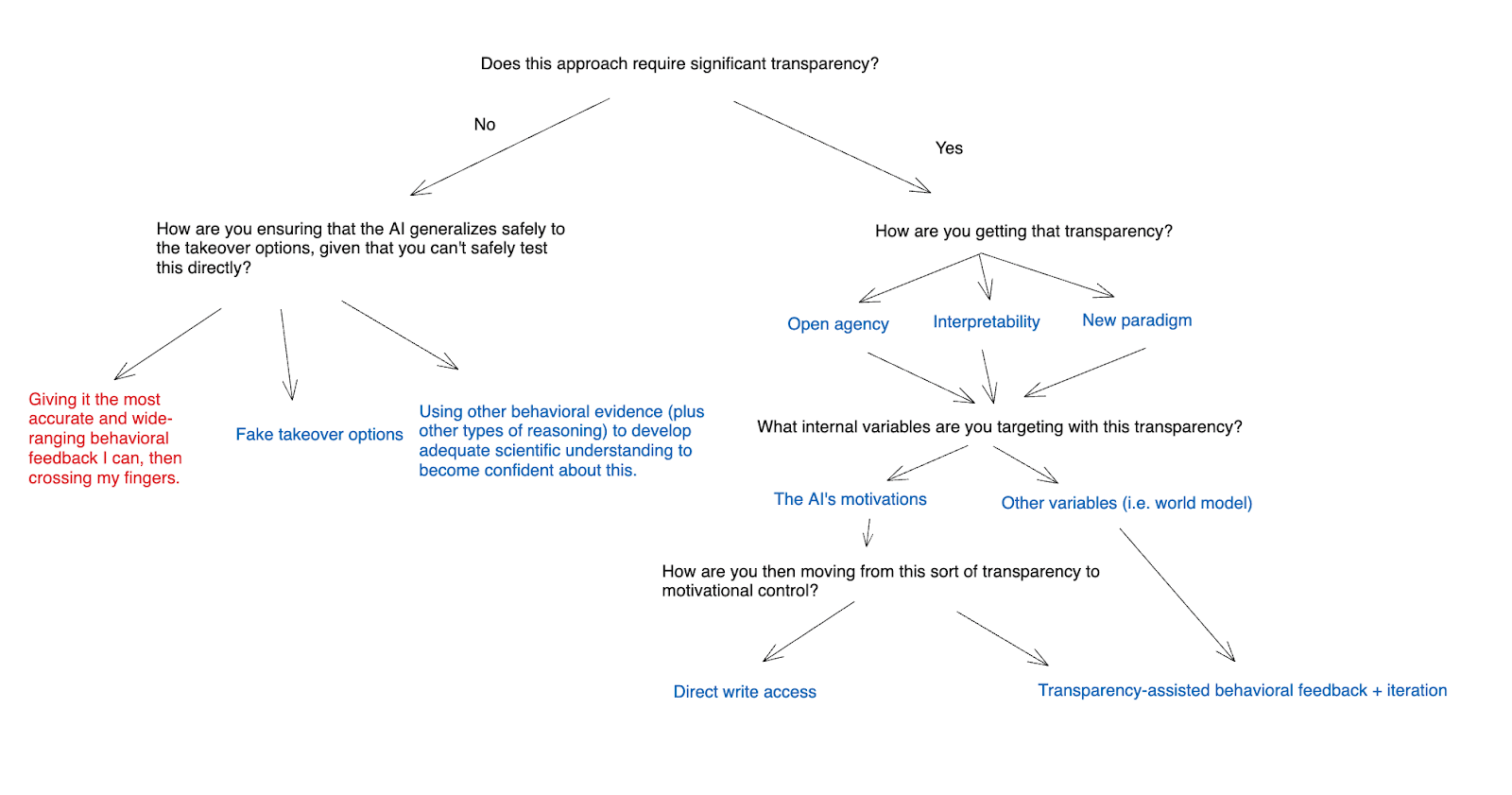
Diagram of the breakdown I use for thinking about motivation control
What’s (at least potentially) difficult about motivational control?
What’s challenging, or potentially challenging (depending on the setting of various underlying technical parameters), about motivational control? Relative to our current state of knowledge, at least, here are the four key issues that seem most central to me.
Generalization with no room for mistakes
The first and plausibly most central is that to the extent you need any amount of motivational control in order to prevent takeover, this means that you’re assuming the AI is going to have some takeover option with a non-trivial chance of success if pursued. And this means, further, that there’s a sense in which your approach to motivational control can’t (safely) rely on a certain kind of direct test of whether your efforts have been adequate – namely, the test of: does the AI in fact choose a takeover option, once such an option is really available. (See my “On ‘first critical tries’ in AI alignment” for some more on this.)
This issue is especially salient to the extent you’re relying centrally on behavioral feedback/selection in order to end up with an AI motivated in the way you want. If you never have direct access to an AI’s motivations, and must instead always be inferring its motivations from how it behaves in various environments, and you can never safely test it directly on the environment you really care about (i.e., one where it has a genuine takeover option), then there’s a sense in which your efforts to give it the right motivations will always require successful generalization from the environments you can safely test to the environments you can’t.[2]
That said, how hard it is to achieve successful generalization in this respect is a further question. It’s possible that ML systems, at least, generalize in quite favorable ways in this regard by default; and it’s also possible that they do not. Different people have different views about this; my own take is that to a first approximation, we currently just don’t know. Below I’ll discuss some approaches that rely on learning quite a bit more in this respect.
Opacity
Of course, if you could get some kind of direct epistemic access to an AI’s motivations (call this “read access”), such that you didn’t need to rely on behavioral tests to understand what those motivations are, then this would help a lot with the generalization issue just discussed, because you could use your direct epistemic access to the AI’s motivations to better predict its behavior on the environments you can’t test. Of course, you still need to make these predictions accurately, but you’re in a much better position.[3] And if you had “write access” to an AI’s motivations – i.e., you could just directly determine what criteria the AI uses to evaluate different options – you’d be in a better position still. Indeed, in some sense, adequate “write access” to an AI’s motivations just is motivational control in the sense at stake in “incentive implementation.”[4] The remaining task, after that, is selecting safe motivations to “write.”
Unfortunately, current machine learning models, at least, remain in many respects quite opaque – and to the extent they have or end up with motivations in the sense at stake here, we are not currently in a position to “read” those motivations off of their internals, let alone to “write” them. Nor, I think, are current plans for becoming able to do this especially “executable” in the sense I described above – i.e., I think they generally have a flavor of “hopefully we make significant breakthroughs” or “hopefully the AIs will help?” rather than “we know in a fairly concrete way how we would do this, we just need blah resources.”[5]
Worse, at least in sufficiently intelligent agents, there might be more structural barriers to certain kinds of “read access” and “write access,” related to the sense in which such agents may be using concepts and forms of thought that humans simply can’t understand. If that’s right, then read/write access of the type necessary for motivational control may require more qualitatively superhuman types of AI assistance.
Feedback quality
If we assume that we don’t have direct read/write access to an AI’s motivations, and so must instead be shaping those motivations via selection/feedback on the AI’s behavior in different environments (other than the one we really care about), then we also face a further issue of needing to get a feedback signal (or selection process) of the quality necessary to create the motivations we want (call this kind of feedback “good enough”).[6] We can break this issue into components: feedback accuracy, and feedback range.
Feedback accuracy
Feedback accuracy, roughly speaking, refers to: not actively rewarding behavior you don’t want. Thus, examples of inaccurate feedback would include rewarding the model for: lying, manipulating humans, seeking unauthorized resources, directly messing with the feedback process itself, etc. Because it rewards unwanted behavior, this sort of inaccurate feedback might encourage the AI to develop motivations other than the ones we’re aiming for.
Now, importantly, whether a given type of flaw in the feedback signal would lead, specifically, to the sorts of motivations that would cause the AI to choose a takeover option remains an open question – one dependent, at the least, on the sort of flaw at stake, and the overall incentive structure safety case we’re working with.
- Indeed, at least in some cases, ML systems can be end up generalizing in a manner that is quite robust to various errors in a training signal (for example, mislabeled images in a data set); so even if you occasionally reward an AI for e.g. lying, it’s possible that it ends up with a broad policy of honesty regardless.
- And even if it ends up learning most dishonest motivations, here, there’s still an open question of whether those dishonest motivations would lead it to choose a takeover option in the relevant situation. And same for e.g. learning some willingness to manipulate humans, seek unauthorized forms of power, hack its reward process, etc.
So a “good enough” training signal, relative to the goal of avoiding takeover in particular, is plausibly compatible with various types of inaccuracies.
If we do need the accuracy of the training signal to be fairly high, though, then we face the challenge of achieving the high level in question. And in particular, there’s a concern that we might need superhuman levels of ability to understand and evaluate the AI’s behavior, because this is the sort of ability required to tell whether an AI is lying to us, manipulating us, seeking access to unauthorized resources, etc.
To the extent it’s meant as a method of creating a feedback signal (as opposed to a method of ensuring some other kind of oversight – more below), various proposals for “scalable oversight” aim to address this issue by using AIs to improve our behavioral inspection ability.
- Thus, to achieve more quantitative improvements in this respect (i.e., amplification equivalent to access to large amounts of roughly human-level cognitive level), you can do stuff like: train AIs to imitate the output of a given human with access to a given level of AI tools (or a given team of humans, potentially using a quite intensive and expensive labor process), and then train new AIs to imitate the output of (teams of) those AIs (potentially also working with humans); and so on. And then eventually use some AIs resulting from this process to assist in your behavioral inspection.
- To achieve more fully qualitative improvements (i.e., improvements that more strictly require access to qualitatively superhuman levels of intelligence; if indeed there are improvements of this kind), you need to find some way of successfully eliciting the relevant kind of qualitatively superhuman task-performance from AIs capable of it – for example, by leveraging the difficulty-difference between evaluating output and generate it.
- In a sense, this is just a version of the general “capability elicitation” problem that I discuss later in the series.
I won’t, here, investigate in detail the extent to which we should expect various of these scalable oversight schemes to work, and how far they would get us if they did. As I noted in my previous post, my general sense is that many of them are much closer to “executable” than e.g. existing plans for solving interpretability at a level that allows motivational read/write access, but that significant open questions remain.
Feedback range
Beyond getting a sufficiently accurate training signal for a given input, “good enough feedback” also requires training your AI on a sufficiently wide range of inputs. In particular: training on a wider range of inputs narrows down the set of motivations that are compatible with the data you’ve given the model; and so (assuming your feedback has been accurate) helps ensure that the model has the desired motivations in particular.
A classic example of an effort to improve “feedback range” is adversarial training – that is, actively searching out inputs where the model behaves in a manner incompatible with the motivations you want, such that you can train against this behavior (and thus, hopefully, push the model’s motivations in the desired direction). Of course, per the discussion of “generalization with no mistakes” above, you can’t do the specific type of adversarial training you would most want to do – i.e., testing for bad behavior on genuine takeover options, and training against that. But even within the constraints imposed by your inability to safely train on takeover options, there’s still an extremely wide range of further inputs that it would in principle be very helpful to train your AI on. Sufficiently good “feedback range” is about doing enough of this.
Of course, as with feedback accuracy, there is an open question, here, as to exactly how wide your feedback range needs to be, in the context of a given sort of training, feedback signal, etc, in order for the feedback overall to be “good enough” with respect to a goal like avoiding takeover. And in many cases, expanding your feedback range is just a matter of doing more intensive and thorough adversarial training, on inputs that are both available and safe to test.[7] Some inputs, though – i.e., takeover options – are unsafe to test; and others may be unavailable (or too expensive) for other reasons. Thus, for example, it may be difficult to test what your model would do in some future scenario where the world has changed quite a bit – not because testing this would be unsafe, but because you don’t have access to the scenario in question. It’s not clear how much of an issue this is – but an effort to get good enough feedback needs to reckon with it.
Potential adversarial dynamics
I do, though, want to flag an additional issue that all efforts at motivational control need to deal with, and which complicates various approaches to the issues already discussed: namely, the possibility that various of the AIs involved in an effort at motivational control are or become actively adversarial towards this effort.
In AI you’re trying to align
The most salient source of adversariality in this respect is, of course, the AI whose motives you are trying to control. In particular: this AI might be actively optimizing for deceiving you about its motives, preventing you from alterings those motives, causing you to trust it in ways that you shouldn’t, etc. I discussed the version of this most salient to me in my report on Scheming AIs, and I won’t go into too much more detail here.[8] Note, though, that this possibility creates additional and non-standard difficulties in trying to predict how an AI will generalize.
- For example, it becomes harder to use arguments like: “we trained it on distribution A that we can safely test, and then observed it generalize in desirable ways to distribution B that we can also safely test. Thus, we infer that it will also generalize in desirable ways to distribution C that we cannot safely test (because it involves giving the AI an actual option to take over).”
- In particular: if the AI knows enough about your training/testing process, and about what distributions you can safely test, and it is actively optimizing for getting the chance to act in distribution C (i.e., to get access to a genuine takeover option), then its behavior on distributions A and B is weaker evidence than it would be in other, less adversarial ML contexts.
In the AIs you try to get to help you
Notably, though, the AI whose motives you’re trying to control isn’t the only possible source of adversariality. Other AIs that you try to get to help you – for example, with amplifying your behavioral inspection or your interpretability – might also be adversarial. And in the worst case, all of the AIs involved might be adversarial in the same direction – i.e., they’re cooperating to promote AI takeover, whether because they share sufficiently similar values directly, or because their various different values stand to gain enough from the cooperation – resulting in coordinated efforts at sabotage.
- That said, this concern centrally applies to the extent you’re relying for help on AIs that also satisfy the agential prerequisites. If you use less dangerous types of AIs to help you with evaluation, interpretability, etc, it’s less of an issue.
Of course, whether you in fact get adversarial dynamics of this kind, in a given context, depends on a variety of factors (see e.g. my discussion of the prerequisites for Scheming in the report; I also briefly touch, there, on the of the dynamics surrounding cooperation between scheming AIs with different values). And “all the AIs involved in your process are cooperating to promote takeover” is an extreme and fairly specific-sounding case, which implicates further assumptions about the incentives at play. As with generalization more broadly, and with what constitutes “good enough” feedback, it’s possible that various of the underlying technical variables here are in fact fairly favorable to us, and adversariality of the relevant kind (and especially: default collusion even amongst AIs with very different values) doesn’t arise by default.
Still, adversarial dynamics of this kind create some of the hardest-to-address issues with motivational control; and they are sufficiently compatible with good-seeming behavior, at least in sufficiently advanced AIs, that I think a full story about how you’re achieving motivational control needs to grapple with them.
The four difficulties in a diagram
Here are the four difficulties I’ve discussed in a convoluted diagram.
Two other notes on this broad portrayal of the issue:
- First: as I’ve tried to emphasize: I don’t think these issues necessarily make the problem hard. Indeed, it may be that the technical situation here is actually quite benign. That is, perhaps even halfway-decent feedback (i.e., the sort of feedback that we are very likely in a position to give AI systems using humans + safe tools) is enough to prompt the sort of generalization we want re: takeover options. In that case, we wouldn’t get adversarial dynamics by default, and opacity wouldn’t be much of an issue either (since basic forms of behavior feedback are adequate).
- The problem, though, is that we don’t know that the underlying technical situation is benign in this way (and I think there are at least some direct reasons for skepticism – i.e., I think there are conceptual arguments that imply that avoiding adversarial dynamics in actively interfering with an agent’s values is a somewhat delicate dance; and I think active flaws in the training signal, other things equal, count against good generalization).
- As I discussed in my previous piece, I’ll call strategies that proceed by just hoping that some uncertain parameter is benign “cross-your-fingers” strategies. I think some people are basically counting on a strategy of this kind; but I think we should try to do better.
Second: note that in principle, all (or at least, most) of these issues apply to human motivations as well. That is, if you were planning to give some human the option to take over the world with some non-trivial probability, and you first wanted to be confident that they would reject this option, you would also face the issue that you cannot safely test the thing you care about directly (generalization); that you can’t read the person’s motivations directly off of their brain (opacity); that the human might have received various sorts of reinforcement for bad behavior throughout their life (feedback quality – though here I think there are more disanalogies with the AI case; see footnote[9]); and the human (and other humans you recruit to help you) might in principle be scheming to mess with your attempt to understand the motivations in question.
Of course, the fact that these issues would arise with humans as well isn’t actually much comfort. It would be one thing if we had lots of experience giving different humans the option to take over the world, and it has generally gone well thus far. But in reality, we have not, previously, had to test what happens when humans have the option to grab absolute power; and to the extent we’ve tested this (cf dictators), the existing data seems mixed at best.
Yes, we do rely on motivational control in more mundane contexts – i.e., it is indeed partly the human conscience that helps prevent crime. But those are stakes where we can tolerate at least some errors in our methods – e.g., sometimes successful crimes do in fact occur. But permanent world takeovers do not tolerate this kind of “oopsie.” And we yet haven’t had to deal with giving humans the option to commit that kind of crime.
That said, I think it’s still important to note the sense in which the central difficulties with motivation control in the AI case do not actually seem all that much about the artificial-ness of the agents in particular. It’s much more about the stakes of the agents having the option to take over.
Admittedly, this isn’t the cleanest decomposition of issues with motivational control. In particular: I think the interrelationship between the issues is quite complex, and it would’ve been nice to get a smoother logical flow. But I think it roughly captures many of the core issues – and I’m going to stick with it for now.
How can we address these difficulties?
Ok, that was a list of the four key potential difficulties I see in attempting motivational control. Let’s turn, now, to discussing how we might address those difficulties.
I’m going to divide the approaches I discuss roughly according to how much “transparency” with respect to internal variables of an AI’s agency that they require. That is:
- First, I’ll talk about approaches that are compatible with basically no “transparency,” and which rely almost entirely on behavioral feedback for shaping an AI’s motivations, and behavioral evidence for understanding those motivations.
- Here, the central example of “behavioral feedback” I have in mind is the sort at stake in ML training, where you sample instances of an AI’s behavior on different inputs and update its policy using SGD so that it performs better, on those inputs, according to some training signal.
- In principle, the notion of behavioral feedback can also encompass other ways of selecting on the model’s policy centrally by inspecting its behavior and making adjustments on that basis – for example, more evolution-like selection methods, or even simpler cases of trial and error. I think that in many cases the dynamics at stake here are broadly similar, but I won’t discuss these methods of behavioral feedback specifically or always attempt to make sure that what I say applies to them.
- The three main approaches I discuss here are:
- A “baseline plan” that I call “behavioral feedback + crossing your fingers.”
- Using fake takeover options to become confident about the AI’s behavior on real takeover options.
- Using other behavioral approaches to develop adequate scientific understanding of generalization that you can be confident that the AI’s motivations will generalize well.
- Here, the central example of “behavioral feedback” I have in mind is the sort at stake in ML training, where you sample instances of an AI’s behavior on different inputs and update its policy using SGD so that it performs better, on those inputs, according to some training signal.
- I then turn to approaches that assume at least some degree of progress on the opacity issue (let’s call this progress “transparency”).
- I then discuss three main approaches to creating transparency, namely:
- “Open agency” (roughly speaking, building transparent AI agents out of safe but-still-black-box ML models, a la faithful chain-of-thought);
- “Interpretability” (roughly speaking, learning to make ML models less like black boxes – though the details of what this means can be quite subtle);
- “New paradigm” (roughly speaking, transitioning to a new and more transparent paradigm of AI development that relies much less centrally on ML – for example, on that more closely resembles traditional coding).
- I further distinguish between attempting to target the AI’s motivations directly using a given approach to transparency, vs. attempting to target some other internal variable.
- Finally, I talk about how you might translate transparency about some internal variable into motivational control. In particular, I distinguish between what I call “transparency-assisted behavioral feedback + iteration,” and “direct write access.”
- I then discuss three main approaches to creating transparency, namely:
Here’s a chart summarizing the approaches I’ll consider:
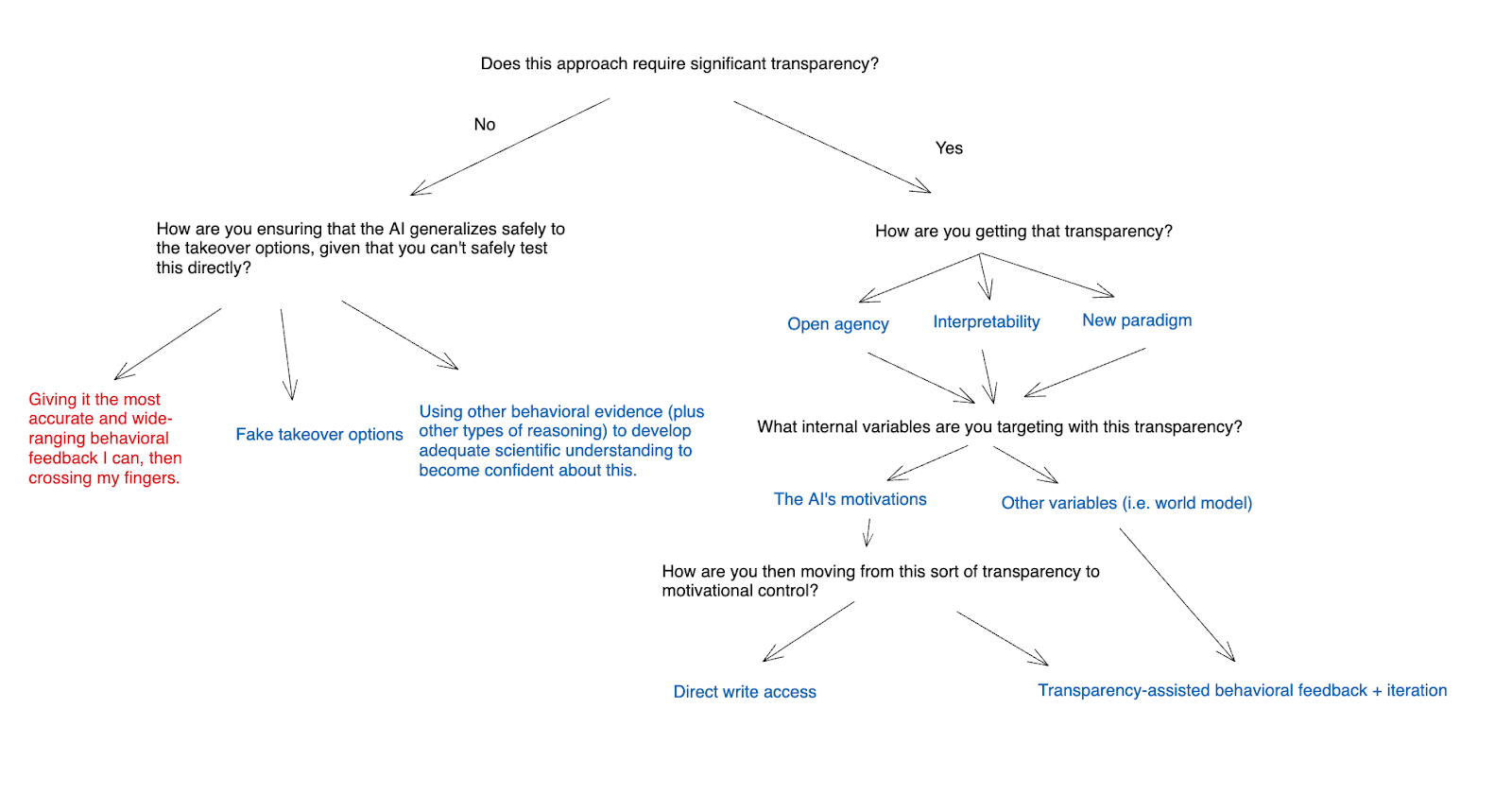
(Note: in principle, the transparency side of this chart breaks into a larger number of possible combinations, corresponding to each distinct path down these arrows. I’m not attempting to represent these individually, as I think the basic dynamics at each stage are similar.)
Approaches that do not require much transparency
Baseline approach: behavioral feedback + crossing your fingers
Let me start by discussing what I see as a certain kind of “baseline approach” – namely, what I’ll call “behavioral feedback + crossing your fingers.” Roughly speaking, this kind of approach has two components:
- Behavioral feedback: Give the AI system the best, most comprehensive, and most accurate behavioral feedback you can.
- Crossing your fingers: Hope that this feedback is good enough to lead to the type of generalization you want.
Importantly: “behavioral feedback,” here, does not mean simple RLHF. Rather, I am explicitly meaning to include both of the following:
- AI-assisted improvements to your inspection ability: Efforts to use AI help (plus other types of investment and effort) to improve your ability to inspect/evaluate a given instance of AI behavior (for example, by investing more in the inspection/evaluation process; by breaking the behavior down into parts that are easier to evaluate; by using AI systems to help you; etc).
- Adversarial training: Efforts to test the AI’s on a very wide range of inputs, and to search out inputs where it behaves badly according to your inspection ability. These efforts can themselves be the subject of amplification.
- Here we can further distinguish between what I’ll call “deceptive adversarial training,” which relies on causing the AI to become quite uncertain of and/or actively misled about the nature of its situation, and “non-deceptive adversarial training,” which does not. However, if we assume, as I did in my last post, that superintelligent AI systems will generally be quite difficult to “fool,” then I think we can’t just assume that deceptive adversarial training will be available here. Below, though, I discuss it in more detail – and in particular, in the context of what I call “fake takeover options.”
This means that “behavioral feedback,” in my sense, actually encompasses a very wide range of degrees of effort/competence/caution. That is, you can, in principle, make only shallow and unserious efforts at doing comprehensive and accurate behavioral feedback in this sense (call this “shallow behavioral feedback”); or you can be quite intense about it (call this “intensive behavioral feedback”). And the difference may key to your degree of success. Conceptually, though, shallow and intensive behavioral feedback are fairly similar, so I’m going to bucket them together here.
In what sense does this plan require “crossing your fingers”? Well, roughly speaking, because even quite intensive efforts at behavioral feedback don’t necessarily address all the issues I described above. Of course, by hypothesis, we are leaving the “opacity” issue unaddressed. But even beyond this:
- Your efforts to improve your behavioral inspection ability may not have been good enough to eliminate problematic inaccuracies in your feedback.
- Your adversarial training may not have tested your model on a sufficiently wide range of inputs.
- Even if you achieved very high levels of feedback accuracy and range, you may still have run into directly adversarial dynamics – i.e. scheming – at some point in this process (dynamics that remain compatible with the feedback you gave the model). I.e.:
- Maybe your AI has itself become a schemer.
- Maybe some of the AIs you tried to use to help you with inspection amplification or adversarial training are also schemers, and have actively sabotaged some of your efforts.
So to the extent you remain uncertain about these issues, but nevertheless proceed forward with exposing your AI to takeover options, this approach counts as a “cross your fingers strategy.” Of course, it could turn out alright. But we should aim, I think, for greater confidence. Let’s look at some options in this respect.
Fake takeover options
One salient path to addressing this sort of uncertainty directly would be via a focus, specifically, on what I called “deceptive adversarial training” above. In particular: if (1) you could test your model on a sufficiently wide range of fake takeover options, and if (2) you were justifiably confident that it couldn’t differentiate between those fake takeover options vs. real takeover options, then this could go a long way towards increasing your confidence that the model in question will behave well on the real takeover option you actually care about.
Below I’ll discuss approaches to this sort of testing that rely on some level of transparency with respect to the AI’s internal variables (and in particular, its world model). Here, though, I’m assuming we don’t have such transparency available. Still, I think something like (1) and (2) might be possible even in a purely behavioral regime.
In particular: an AI’s ability to differentiate between fake options and real options is a capability – one that we can plausibly test extensively in a variety of safe environments. So if we can do adequately well with capability elicitation in safe environments for checkable tasks (see my discussion below), we might be able to get a relatively clear grip on which fake vs. real inputs our AI can distinguish.[10]
Of course, even granted an ability to tell which fake vs. real inputs our AIs can distinguish, this doesn’t mean that we’ll be able to create fake inputs that our AIs can’t distinguish from real ones. That is, our efforts at this approach might just learn “yep, our AIs can consistently tell fake inputs from real inputs – darn.” And indeed, using bare human labor to try to fool a superintelligence in this respect seems very likely to fail. Perhaps, though, you might also be able to harness superintelligence AI labor in producing fake inputs as well – i.e., you might be able to set up something like a “generator vs. discriminator” game, in which one AI tries to create the most realistic-possible fake inputs, and the other AI tries to continually distinguish those inputs from real ones. However, to the extent that the AI producing the fake inputs was also an agent of the type you’re worried about (this might not be necessary), this sort of approach would need to address the possibility of collusion between the AIs in question.
What’s more, there are also some cases, at least, in which it seems like the difficulty-difference in evaluation vs. generation strongly favors the “discriminator” role in this game (whether humans are in the role of “generator,” or other AIs are).
- For example, as Christiano points out, the discriminator will be significantly empowered with respect to evaluating whether an input contains a genuine factorization of some large semiprime (i.e. RSA-2048), relative to a generator that needs to create such a factorization (or a fake version of such a factorization).
Or to take a somewhat more realistic example: it might be quite a bit easier for a discriminator to verify how much technological progress has been made in general than for a generator to fake that technological progress.[11]
It’s a further question whether a given AI would be able to leverage these sorts of dynamics to distinguish the relevant set of real takeover options in particular (in particular: a scheming AI can’t merely “lie in wait” until it sees an input it is confident takes place suitably far ahead in time relative to its training/testing process, both because its training/testing process might continue over time – including, potentially up to a point where e.g. the relevant trainers/testers have extremely advanced tech available – and because if it waits too long human efforts may make too much progress on preventing takeover). But their existence is a problem nonetheless.[12]
What’s more, note that even if we can create suitably sophisticated fake inputs, and even if we can be confident that our AI can’t distinguish them from real inputs, the AI might have further strategies available to undermine our efforts to use fake takeover options to elicit its bad motivations. For example: if the process required to test an AI on a fake input is suitably expensive (because e.g. you need to create a run a fake AI lab or a fake world simulator, or something of that sort), such that the AI can be confident that most of the apparent takeover option it sees are real (even if a few are fakes, and it can’t differentiate the fakes), it can use a strategy of “rare failures” to drive down the probability that it behaves badly on any fake it sees prior to a genuine opportunity to takeover (see footnote for some more on this).[13]
Finally, note that if you do successfully elicit bad behavior from your AI on a fake takeover option, it’s a further question whether training against that behavior, on that fake takeover option, will lead to the sort of change in the AI’s motivations that you want – as opposed to, e.g., a change in its ability to model which takeover options are real vs. fake. That is: moving from detecting bad motivations via this method to actively training for good motivations requires that your detection methods are sufficiently robust that they withstand the sort of optimization pressure that the training implies (we’ll see this dynamic re-occur throughout the discussion). Perhaps they would; but it’s a further uncertainty.
Overall, then, relying on fake takeover options – especially when you only have behavioral tools available – to resolve the “generalizations with no mistakes” issue in the context of superintelligent AI agents seems to me potentially quite tricky. What other options might be available?
Behavioral science of AI motivation
If you don’t have transparency, if you don’t want to cross your fingers about how the AI generalizes to real takeover options, and if you can’t test this using fake takeover options, then in order to become confident about its generalizing well, you need to do some other form of what I’ll call the “behavioral science of AI motivation.” That is, roughly speaking, you need to develop an adequate scientific understanding of how your AI’s motivations will cause it to generalize to takeover options, using the sort of behavioral evidence (along with other types of reasoning) that non-transparency implies; and then you need to use suitable behavioral feedback to ensure that they generalize well.
In principle, this category of approach can encompass a very wide range of techniques and approaches. For example:
- Behavioral (and theoretical) efforts to understand the inductive biases (that is, the factors other than the training signal that determine what algorithm a model learns) of SGD better.
Behavioral efforts to understand/test for various of the components of scheming – i.e., situational awareness, beyond-episode goals, the viability of scheming as an instrumental strategy – especially in “model organisms” with various degrees of realism; and to test what sorts of interventions have what sort of influence on these components arising.[14]
- “Honest tests” for bad motivational patterns like reward-on-the-episode seeking or scheming – i.e., giving AIs genuine chances (that they also believe are genuine) to mess with the reward mechanism and to not have it trained against; to pursue misaligned goals in safe containers without threat of shut-down or modification; etc.
- Behavioral efforts to understand and influence cooperative dynamics amongst different AI systems, so as to shed light on the potential for adversarial dynamics leading to collusion.
- Behavioral efforts to study the circumstances under which we might end up giving our AIs inaccurate feedback.
And so on.[15] Really, this is just a catch-all for: “don’t just cross your fingers about generalization-with-no-mistakes; do a bunch of science until you actually know what you’re doing” – but with a constraint that the science in question has to proceed without transparency, and that you can’t rely on fake takeover options in particular.[16] And in the ideal end-result of this approach, eventually you’ve studied how AIs behave in different circumstances, given different types of feedback/data, so much that you are justifiably confident that they aren’t going to behave badly on takeover options – even though you can’t test those options directly (and even though, in principle, they could be trying to deceive you). And note that (modulo ethical constraints), we will in principle be in a position to run extremely extensive experiments with our AIs, and to gather a very large amount of data about their behavior in different circumstances (and of course, AI labor can itself drive and direct the scientific process itself).
Still, I expect that people will have different intuitions about the level of justified confidence that is likely to be available in this respect, even after extensive scientific efforts.
- Obviously, the possibility of AIs actively scheming to mess with our efforts to understand how they will generalize matters a lot here. So I think success at “behavioral science of AI motivation” likely requires reaching a point where you are quite confident that the AIs in question aren’t scheming. But if, for example, scheming is very far from a default behavior in AI systems (because e.g. SGD’s inductive biases actively disfavor it), I think it’s at least plausible that by studying different AIs enough (including AIs with different levels of capability, model organisms, etc), you might reach justified confidence that even very sophisticated AIs aren’t scheming, using behavioral science alone.
- And in the context of humans, note that we often end up trusting each other’s motivations centrally on the basis of behavioral evidence – “transparency” plays very little role. (Though: whether we’d trust a given human with a takeover option is a different question.)
Of course, in practice, the sort of “knowing what you’re doing” we’re hoping behavioral science yields comes in degrees. And indeed, in some sense, the spectrum from “behavioral feedback + crossing your fingers” and “behavioral feedback + behavioral science of AI motivation” is quite smooth. That is: if the “crossing your fingers” component represented x amount of justified uncertainty as to how an AI will generalize to takeover options, various amounts of “behavioral science of AI motivation” reduce this uncertainty to different degrees.
Importantly, though, this uncertainty can also reduce in different directions – good, or bad.
- Thus, for example, suppose that a “behavioral feedback + cross your fingers” strategy involves giving behavioral feedback F, and then crossing your fingers about how the motivations it creates generalize to the relevant takeover options. It could be that if you did a bunch more behavioral science of AI motivation, you would learn that in fact, yes, behavioral feedback F was sufficient to ensure safety from takeover, and your “cross your fingers” strategy would’ve worked out OK. And thus, equipped with this good news, you can proceed forward with confidence.
- Alternatively, though, your behavioral science of AI motivation might yield a different conclusion: namely, that in fact, behavioral feedback F was not sufficient, and proceeding forward with your “cross your fingers” strategy would’ve led to a takeover attempt. Now what do you do? Well, now you need to somehow improve your behavioral feedback, relative to F, such that this is no longer the case. Presumably, your “behavioral science of AI motivation” helps with this, at least somewhat. But being able to tell that your AI is catastrophically misaligned is, unfortunately, not the same as being able to align it.
- What’s more, in this latter “bad news” case, it’s possible that in the process of iterating against your ability to measure/understand whether your AI is misaligned, some of your metrics start to break down.
- This is an example of a broader dynamic that will also re-occur in the context of greater “transparency” as well. That is, to the extent some form of epistemic access to an AI’s degree of alignment – whether via internal or external variables – yields bad news by default, trying to iterate against it until it yields “good news” can, at least in some cases, distort the signal it provides.
- An example of this might be: if you search for inputs where the AI behaves badly according to your inspection process, and then train it to behave better (according to your inspection process) on those inputs, you could be altering its motivations in good directions; or you could be teaching it to hide its bad behavior better.
- So to the extent you’re iterating until your behavioral science of AI motivation gives a green light, this science needs to be robust to the degree of iteration at stake.
- This is an example of a broader dynamic that will also re-occur in the context of greater “transparency” as well. That is, to the extent some form of epistemic access to an AI’s degree of alignment – whether via internal or external variables – yields bad news by default, trying to iterate against it until it yields “good news” can, at least in some cases, distort the signal it provides.
There’s a lot more to say about what sorts of avenues of inquiry and intervention might be available to a serious attempt at a behavioral science of AI motivation. And I readily admit that this is a catch-all category that doesn’t offer a very principled or clear path forward – especially given all the different things that a science of this kind might discover along the way. In particular: to be successful, this approach needs to detect and address whatever issues with feedback quality and adversarial dynamics actually apply in practice.
- So on feedback quality, it needs to identify some way of understanding how varying levels of inspection amplification and adversarial training translate into generalizations to takeover options; and to engage in the version that generalizes well.
- And on adversarial dynamics, it needs to either discover that these dynamics don’t arise by default, or find a way to address them (via e.g., learning how to address them in model organisms, changing inductive biases, changing the incentive landscape, working harder to prevent collusion amongst the AIs you want to help you, etc).
However, even absent details about how this process might go, I want to make salient the possibility that a mature approach to motivation control ends up sounding something like: “well, we just learned so much about how AIs tend to behave in response to different sorts of feedback, and we became extremely good at giving feedback of the right kind, such that we’re just really no longer worried that they’ll go for it on the relevant sorts of takeover options, even though we can’t safely test this directly.” True, it’s not especially principled. But it does seem like how a lot of “trust” in the motives/behavioral generalization of other creatures has worked in practice thus far. AIs do bring new issues (notably, higher stakes of failure, and the possibility of very sophisticated forms of adversarial deception). But I think it’s possible that serious and scaled-up efforts at behavioral science would still, ultimately, suffice to become justifiably confident that their motives are suitably benign.
Approaches that rely on at least some degree of transparency
Let’s move on, though, to approaches to motivation control that aim to achieve some amount of transparency into what I called “internal variables” above – i.e., the AI’s motivations, capabilities, world model, reasoning, and so on. I’ll break down these approaches according to three distinctions:
- How they aim to achieve the transparency in question.
- What internal variables they try to target with this transparency.
- How they aim to move from this transparency to motivation control.
How are we achieving the transparency in question?
Let’s start by discussing how we might achieve the transparency in question. Roughly speaking, here’s how I think about the options here. We start with the assumption that there is something notably non-transparent about current ML models, especially if we set aside the sorts of tools and approaches traditionally bucketed under the term “interpretability.” Exactly how to characterize this non-transparency is an open question. At the least, though, and modulo some modest progress on interpretability, our ability to predict the behavior of a trained ML model on different inputs, on the basis of e.g. direct examination of the learned weights, is quite limited. And more broadly, we generally lack the ability to usefully characterize the algorithm that a trained ML model is implementing at levels of abstraction higher than e.g. a full description of the network.
That is, in some intuitive sense, and despite the full access we have to their weights, trained ML systems remain in many respects “black boxes.” And if the superintelligent agents whose motivations we hope to control are also black boxes in this way, our prospects for transparency look dim.
So how do we avoid this? I’ll group available approaches into roughly three categories:
- Open agency: Building transparent AI agents out of safe-but-not-transparent ML models.
- Interpretability: Making ML models more transparent.
- New paradigm: Shifting to a new and more transparent paradigm that doesn’t rely on ML models in the same way.
- An example of this might be: shifting more in a direction that resembles “good old fashioned AI” in the sense of “code written from the ground up by agents that understand that code.”
Thus, in a diagram:
Of course, these approaches can combine in various ways. For example:
- you might use limited success at interpretability to help ensure the safety of the ML components at stake in an open agency approach;
- you might use an expensive-but-safe open-agency-style agent to assist you in developing better interpretability techniques that lead to more competitive solutions;
- a “new paradigm” might involve some component of safe-but-still-black-boxish machine learning in some contexts; and so on.
And perhaps still other approaches, that don’t fit well under any of these categories, are slipping through the cracks.
Still, I think it’s useful to have these three broad approaches to transparency in mind. Let’s look at each of them in a bit more detail.
Open agency
The approach to transparency that currently seems most “executable” to me proceeds via using safe-but-non-transparent ML models as components of a broader and more transparent agency architecture. I’m using Drexler’s term “open agency” for this, though I think my usage might not directly match his.[17] See also “chain of thought alignment,” “externalized reasoning oversight,” “translucent thoughts hypotheses,” and various other discussions.
I say that this approach seems most “executable” to me because I think various current techniques for using ML models for more agency-requiring tasks have various components of “open agency” in the sense I have in mind. For example, they often use human-legible chains of thought (though it’s a further question whether this chain of thought is “faithful” in the sense of: accurately representing the reasoning driving behavior); and they occur, more broadly, in the context of comparatively legible “scaffolds” that involve a variety of calls to ML models performing documented sub-tasks – including sub-tasks involved in planning, world-modeling, generating sub-goals, and so on (see e.g. the sort of scaffold at stake in the Voyager minecraft agent). What’s more, to the extent we interpret the prompt or goal given to this kind of agent scaffold as importantly structuring of the agent’s “motivations,” this grants additional inspection-capacity (not to mention intervention capacity) with respect to their motivations as well.
On top of this, we also have non-AI examples of real-world agentic processes that have various components of “open agency” in the sense I have in mind.
- Thus, for example, if we understand a corporation as an agent (i.e., an entity that makes plans and coherently executes plans, in pursuit of objectives, on the basis of models of the world), it is an intuitively more “open” agent than e.g. an individual human brain. And this especially if we require that written representations of the corporation’s thinking and strategy – i.e., the memos that different employees write about their plans, the justifications for those plans, the goals they are pursuing, etc – are “faithful” reflections of what actually drives the corporation’s behavior. That is, if you wanted to understand this corporation’s thinking/strategy/motivations etc, you could in principle just go and read the memos in question. (Though to the extent that a lot of the true strategy/motivations etc live centrally inside the head of some particular set of employees – e.g. the CEO – then this “openness” is compromised.)
- So to the extent we can make the superintelligent agents whose motivations we are trying to control more like corporations, in this respect, than like individual human brains, then this might make various types of “open agency” more available.
I generally think that open agency is an extremely important direction to explore in approaching the alignment problem. In particular: if this direction were successful – that is, if we ended up building full-blown superintelligent agents via highly transparent, faithful, and human-inspectable architectures that use safe ML systems as components – then I think we would likely be quite empowered with respect to many key aspects of avoiding takeover. And such a path seems notably more continuous with what we are doing today than e.g. some other type of victory on learning to interpret ML models. Indeed, depending on how you think about the degree of faithfulness at stake in e.g. the chain of thought used by o1, aiming for open agency can seem more like aiming to hold on to various transparency benefits that current techniques offer, rather than aiming to implement various as-yet-undeveloped techniques in some as-yet-unspecified future.
However, I also think that open agency approaches to transparency face two key difficulties: competitiveness and safety-of-the-components.[18]
- Competitiveness. The first and I think most prominent difficulty is that it seems very plausible that open agency will ultimately be uncompetitive relative to approaches that bear a closer resemblance to black-box ML.
- We can distinguish between two versions of this;
- Open agency just doesn’t work for superintelligence: In the first version, it just turns out to be basically out of the question to build a full blown superintelligence using open agency. For example, maybe forcing all/most of a superintelligence’s reasoning into a faithful, human-legible chain of thought just isn’t viable with any realistic level of resource-availability; maybe we can’t figure out how to make the chain of thought faithful; forcing the AI to think it human-legible concepts radically curtails the intelligence available to it; etc.
- Open agency works for superintelligence but it’s way slower/more expensive/etc: Alternatively, it could turn out that it’s possible in principle to build superintelligence via open agency, for realistic levels of resources. But it still isn’t competitive to do so – because, for example, you can reach superintelligence significantly faster/more cheaply if you don’t require that its reasoning be human-legible; if you can optimize all of its cognition end to end; if you don’t have to invest in heavily supervising all of this human-legible reasoning; and so on.
- The first case, here, seems especially worrying. That is, if you simply can’t realistically build superintelligence via open agency, then the approach is just not viable. By contrast, if building superintelligence via open agency merely requires some substantial “tax,” then it becomes a more open question whether we might be able and willing to pay such a tax.
- Indeed, I think there is at least some hope that, even setting aside catastrophic risks from AI, there will be sufficiently active “demand” for the sort of transparency and steer-ability that open agency makes possible that standard commercial incentives will push in this direction somewhat.
- And note, too, that if you were able to get access to occasional, very expensive, but still trusted superintelligent AI labor via open agency, then this could serve as an extremely useful component of a broader approach to alignment, even if it wasn’t a fully competitive solution on its own.
- We can distinguish between two versions of this;
- Safety of the components. The other chief difficulty with open agency, as I see it, is making the black-box ML components you’re using suitably safe. In particular, if these components themselves satisfy the agential prerequisites, then they themselves might be in a position to take actions (including actions coordinated across the different components of the agency architecture) in pursuit of takeover.
- Here a rough analogy might be something like: sure, you built a corporation out of different humans, and you forced it to write english-language strategy memos documenting its goals/plans/reasoning. But if the individual humans are much more sophisticated than you (i.e., maybe you are a child and they are adults), then insofar as they are still untrusted, it might be hard to feel good about the situation overall.
- The most plausible threat models here, in my opinion, involve the “faithfulness” of the human-legible aspect of your agency architecture breaking down, such that adversarial types of planning are occurring within various components of the composite agent in a way that wouldn’t be legible to humans, but which still drive the behavior of the agent overall. (I.e., in the analogy, the corporation’s memos would stop accurately representing the goals/reasoning driving the corporation’s behavior.)
- In one version of this, the different components are actively communicating with each other in ways that aren’t human legible – i.e., via some kind of steganography in the chain of thought; via storing information in non-legible memory banks; via finding other communication avenues, etc.
- I.e., in the analogy, the corporation’s employees either find other ways to communicate other than the memos, or they start hiding information in the memos in ways you can’t track.
- More exotically: it might also be possible, in principle, for different components to coordinate in adversarial ways without much or any active communication, via e.g. reasoning about how the other components would be reasoning. Thus, e.g., maybe there’s some fairly obvious strategy like “make everything look good to the humans, but then later we all defect at this clear-to-us shelling time,” which the components can coordinate on without talking it out.
- This kind of coordination-without-communication might be made easier if e.g. all the components of the composite agent are copies of the same model.
- E.g., intuitively, if there’s a corporation run entirely by clones of yourself, it’s probably easier to find a way to do a coordinated defection without communicating, because you know so much about the motives and thought patterns of the other clones. (It’s also probably easier to pull off with communication.)
- This kind of coordination-without-communication might be made easier if e.g. all the components of the composite agent are copies of the same model.
- It’s also possible for agentic components of a composite agent to cause problems even if they aren’t coordinating with the other components at all.
- I.e., in the corporation analogy, one employee at the corporation (i.e., the CEO) might attempt some nefarious power-grab, even without recruiting anyone else to help.
- Finally, note that insofar as your agency architecture looks less like “many different agents doing different sub-tasks, without direct non-legible memory links between them” and more like “a single agent with a consistent memory stream doing tasks in sequence, but where we try to force that agent to document its reasoning in detail,” then it becomes especially easy for this single agent to coordinate with itself on an adversarial strategy, because the non-legible memory stream can serve as the locus of “communication” between the different “components.”
- I.e., if your “corporation” is actually just a single very smart guy, Bob, doing a long sequence of tasks, and he can do a bunch of thinking on his own and then store it in his internal memory, but you’re also making him write down a bunch of stuff on a scratch-pad as he does his tasks, then it seems easy for Bob to just think to himself “I’ll plan to make the scratch-pad look good to the humans but then defect later,” and then store this plan in his internal memory without writing it down.
- In one version of this, the different components are actively communicating with each other in ways that aren’t human legible – i.e., via some kind of steganography in the chain of thought; via storing information in non-legible memory banks; via finding other communication avenues, etc.
- The most plausible threat models here, in my opinion, involve the “faithfulness” of the human-legible aspect of your agency architecture breaking down, such that adversarial types of planning are occurring within various components of the composite agent in a way that wouldn’t be legible to humans, but which still drive the behavior of the agent overall. (I.e., in the analogy, the corporation’s memos would stop accurately representing the goals/reasoning driving the corporation’s behavior.)
- One option for dealing with this “safety of the components” issue is to try to use ML components that do not, themselves, satisfy the agential prerequisites to a degree that makes these sorts of adversarial dynamics a concern.
- I.e., if you could be confident that all of the ML components of a composite agent aren’t situationally aware, or aren’t capable of long-term planning, or aren’t driven by goals that have any consequentialist components, or are purely driven by myopic objectives, this could help a lot with your trust in the composite agent’s behavior.
- An analogy here might be: if you built your corporation entirely out of copies of GPT-4 producing text that you can read, then you might end up pretty confident that none of the components are plotting to defect later.
- Another option is to try to use ML components that do satisfy the agential prerequisites, but to try to enforce very strong and adequate “faithfulness” in the human-legible aspects of the architecture (i.e., preventing steganography via e.g. paraphrasing, testing whether the agent’s behavior in fact varies in the right way based on changes to the chain of thought, making sure that the components don’t have other non-legible communication avenues available, etc).
- One general issue here, though, is that to the extent you are relying on black box ML agents as components of your open-agency architecture at all, some significant fraction of the cognition driving the composite agent’s behavior is always going to be occurring within those black box components, and thus in illegible ways. So in addition to making the human-legible aspects of the architecture faithful in the sense of accurate, they also need to be complete enough that they would reflect adversarial reasoning of the type you might be worried about, even though they can’t represent everything.
- And note that we here run into a general trade-off with the “competitiveness” problem above. That is, you can plausibly make an open-agency architecture more and more competitive by pushing more and more of the cognition inside the black-box ML components. This makes the cognition correspondingly illegible (and hence potentially dangerous), and it also becomes more and more likely that these components satisfy the agential prerequisites themselves (analogy: you can run a better corporation using competent agentic employees than using simple computer programs). And in the limit, if your plan for “open agency” is just to build a black box agentic superintelligence but to force it to document its thinking using a scratch-pad, then you’ve plausibly, indeed, moved far in the direction of competitiveness (though: maybe still not far enough – how costly is this forced-scratch-pad thing?), but at a serious cost re: “safety of the components.”
That said, I think it’s also worth noting the way in which the problem of ensuring safety in the components of an open-agency architecture can differ in important ways from the problem of ensuring safety in a generic superintelligent agent. In particular: when we talk about a superintelligent agent as a whole, we assume a particular capability profile (i.e., vastly better than human on ~all cognitive tasks); and when we talk about the need for motivation control in particular, we assume that the superintelligent agent will itself, at some point, have some sort of takeover option available. But even if we hold fixed these assumptions with respect to an open-agency architecture as a whole, they need not also apply to the individual components of that architecture. Rather, the individual components can themselves be much more limited in their capabilities and options – and this, plausibly, makes the task of ensuring their safety quite a bit easier.[19]
- Here a rough analogy might be something like: sure, you built a corporation out of different humans, and you forced it to write english-language strategy memos documenting its goals/plans/reasoning. But if the individual humans are much more sophisticated than you (i.e., maybe you are a child and they are adults), then insofar as they are still untrusted, it might be hard to feel good about the situation overall.
Overall, I have at least some hope that we can get at least some significant transparency, even from superintelligence, via agency architectures that have various components of open-agency, even if they aren’t direct descendants of current chain-of-thought-style agents. But I think it’s likely that by the time we’re building superintelligence, this would involve at least some very significant tax relative to approaches that focus more directly on black-box ML (at least if we’re still using black-box ML as a key paradigm at that point); I worry that faithfulness will be too hard to achieve; and I expect that superintelligent agents built in this way would likely also have agentic-components that would themselves raise safety concerns (even if those concerns are somewhat easier to address). So while I think we should be thinking hard about open agency (especially in the context of earlier stage AI systems we want to get to help us with e.g. alignment research; and/or in the context of seeking access to occasional because-very-expensive sources of trusted AI labor), I don’t think we can count on it.
Interpretability
Let’s turn, then, to approaches to transparency that focus on making ML systems themselves less black-boxy – i.e., what I’m calling “interpretability.”
A variety of different current research efforts often get grouped under this heading, and my sense is that people disagree quite strongly about them – both re: how to interpret existing results, and about how useful for alignment we should expect future progress to be. I haven’t spent much time studying this topic, and I won’t attempt anything like a comprehensive review of it here.
Hubinger (2022), though, draws a number of useful distinctions in thinking about different levels of interpretability success. In particular, he distinguishes between:
- Best case vs. worst case: i.e., do you get transparency into some portion of the thing you’re trying to understand, or are you able to make stronger guarantees about the thing overall?
- Internal properties vs. training: i.e., understanding the properties of a static model vs. understanding how those properties form and change in response to a given sort of training.
- Robust to training-on-it vs. not: i.e., does your transparency technique continue to work once you include a term like “this transparency technique yields blah result” in the training signal, or does it break down once you start training against it?
- Robust to models actively trying to evade/manipulate the tools in question vs. not: i.e., does your transparency technique continue to work on models that are actively trying to evade the tool in question?
Thus, the most ambitious version of interpretability would be a level of understanding both of a model’s internal properties and of dynamics of training such that you can get worst-case guarantees even after you trained extensively on your interpretability tools, and even if the models you’re investigating were actively trying to evade/manipulate the tools in question. But as I’ll discuss below, I think success at less ambitious versions can still be quite valuable.
We can also distinguish between what Aschenbrenner (2024) calls “mechanistic interpretability” and “top down interpretability.”
- Mechanistic interpretability, roughly, attempts to gain a quite fundamental understanding of how ML models work – and in the limit, the sort of understanding that makes it possible to reverse engineer the algorithms ML models are implementing (see e.g. Nanda et al (2023) for an example of this sort of work in the context of transformer’s performing modular addition).
- Top down interpretability, by contrast, looks for tools and techniques that will allow us to extract information about a model’s internal variables (i.e., its motivations, reasoning, etc) without necessarily gaining any kind of deep understanding of how the model works. An example of this might be: training classifiers on a model’s activations to detect when it’s lying. (See e.g. Zou et al (2023) for an example of this sort of work.)
This isn’t an especially clean distinction. At the least, though, it’s a reminder that in attempting to understand an ML model’s internal workings, it’s possible to move at least somewhat beyond purely behavioral data sources without going all the way to the sort of mechanistic understanding required for reverse-engineering, or towards the more ambitious sides of Hubinger’s various distinctions above.
Indeed, in some sense, we are already in a position to make at least some use of interpretability tools in attempting to assess and control the safety of our AIs. That is: if, today, we had to “throw everything we have at the wall” in terms of motivation control, we wouldn’t be limited, purely, to behavioral feedback, “behavioral science of AI motivation,” and open agency. Rather, we would also, at the least, be able to try training whatever “top-down-interpretability”-style classifiers we can on model internals to look for cognitive patterns like lying, power-seeking, and so on; and then see what these classifiers say about the models we’re worried about. So really, the baseline “science” we’ll be bringing to bear on understanding AI motivations would already, by default, be at least somewhat “interp-assisted” in the sense I’ll discuss below. The real question is how much.
Is interpretability a viable path to significant and useful transparency in superintelligent AI agents? We can group concerns about it into two categories: practical concerns about the difficulty of the task, and “in principle” concerns about what level of success is even available in theory.
- Practical concerns about the difficulty of the task. To my mind, the most prominent objection to expecting much help from interpretability re: motivation control in superintelligence is something like:
- 1. You need quite comprehensive and thorough-going success in order to be very useful to safety.
- Thus, in Hubinger’s framework, the thought would generally be that you need to success at the more ambitious horn of the various distinctions he lays out: i.e., you need your techniques to cover the worst case in addition to the best case, to cover training dynamics in addition to model properties, to be robust to training on them; and to work even once (superintelligent) models start actively trying to evade/manipulate them.
- 2. This level of success seems very hard.
- (As I discuss below, I don’t endorse strong versions of (1) or (2). But I want to lay out the concern regardless.)
- Thus, the concern goes: more “top-down approaches” seem like they run up against (1)-like objections. That is, maybe they allow you to do some probes for some stuff. But (the thought goes), absent deeper understanding of how model cognition works, this isn’t enough to get sufficiently reliable transparency into internal variables we care about (for example, it seems very far from achieving the sorts of ambitions at stake in a “worst case” approach).
- But more mechanistic approaches run quickly in (2). That is, gaining mechanistic understanding of the cognition occuring inside giant neural networks seems like a quite difficult task, and existing results seem comparatively far away from yielding the sort of full and deep understanding that the field seeks.
- So far, for example, my impression is that we have “reverse engineered” very few of the circuits/algorithms at work in large neural networks (i.e., modular addition, induction heads). Whereas in principle, it seems a high-level victory for mech interp requires achieving this level of understanding/reverse-engineering for all or most of the AI’s cognition. And there plausibly strong selection effects re: the difficulty of the circuits we’ve made progress on already – i.e., they seem likely to be the easy ones.
- Something similar applies to work on understanding how models encode and process different features (i.e., work on monosemanticity). That is, at least for high levels of interpretability success, achieving some amount of understanding in this respect, for some human interpretable features, seems insufficient. Rather, you need to have enough understanding to be justifiably confident that your inspection capacity isn’t missing anything important.
- And note, too, that in contrast with behavioral feedback techniques like RLHF, and “open agency” techniques like chain of thought, my impression is that interpretability techniques generally play little to no role in the way we train and shape the behavior of current production models.
- That said, perhaps this is going to change soon; or perhaps I’m not aware of the role that interpretability techniques are already playing. Perhaps, for example, monosemanticity work is in fact informing how Claude is trained/tested.
- And anyway, it’s not clear exactly how much of a count against the future relevance of a technique this is. E.g., my sense is that we also don’t really use scalable oversight in training our models; but I feel optimistic that we will in future. And if you don’t need a given technique to achieve your training goals (because e.g. RLHF is broadly sufficient), then this provides a different explanation for not using it than e.g. “we invested a bunch in it but it still didn’t work.”
- Finally, note, as ever, that beyond the practical difficulty of achieving significant interpretability progress at all, there’s the additional issue of doing so in a manner that remains suitably competitive with other techniques.
- (Though: as with open agency, note that even occasional, very expensive access to highly trusted superintelligent labor could be an extremely useful tool in a broader approach to alignment.)
- 1. You need quite comprehensive and thorough-going success in order to be very useful to safety.
- In-principle concerns about the level of success available. Beyond these practical concerns, though, there is at least some question as to how much of what kind of understanding is even available, in principle, with respect to the different “internal variables” we’re interested in in the context of trained ML models.
- One version of this question arises in the context of the possibility that superintelligent agents would, by default, make use of concepts that humans don’t understand – and perhaps, concepts that humans can’t understand (or at least, can’t be made to understand with realistic levels of effort). This sort of concern seems especially salient in the context of interpretability techniques that specifically rely on human classifications of the features in question.
- A related but potentially distinct concern is that: it seems possible that the “algorithm” that a neural network ends up implementing, in performing a given cognitive task, doesn’t actually end up reducible to or summarizable via some more abstract human-legible characterization. Rather, basically the only thing to say is something like: “it implements blah complex function” (or perhaps: “it was trained in blah way on blah data”).
- Or, to put one version of this concern more practically: perhaps there just isn’t any way to “reverse engineer” the algorithm a neural network is implementing, except to just re-implement those specific weights (or some similarly opaque variant on them).
- (Indeed, at a higher level, it remains at least somewhat conceptually unclear what a “mechanistic understanding” of a complex system ultimately amounts to. Intuitively, there is indeed a deep difference between e.g. the sort of understanding of the physics underlying rockets that contemporary rocket scientists have, relative to e.g. the sort of understanding of sheep that a sheep herder has. And it does indeed seem that our relationship to current ML systems looks more like the sheep herder thing. But beyond stuff like “you know, the sort of understanding that lets you make a very wide range of predictions, and intervene on the system to control it a wide range of ways,” it’s not actually clear to me how to characterize the difference. That said, I don’t think we necessarily need a clean characterization in order to try to push our understanding in the relevant “more like the rocket science thing” direction.)
Overall, both of these concerns – practical and in-principle – seem like real issues to me. And they seem especially concerning to the extent we’re imagining having to rely entirely on human labor – and especially, human labor over comparatively short timelines – in order to achieve deep and thorough-going mechanistic understanding. However, my sense is that I am also more optimistic than some about interpretability playing a significant and useful role in rendering superintelligent ML agents more transparent. In particular:
- As I’m planning to write about later, I don’t think we need to rely entirely on human labor – in interpretability and elsewhere. And relative to other areas of alignment-relevant research, interpretability progress seems to me especially easy for humans to evaluate (even if not necessarily: to generate).
Once you can do something at all, it often becomes quite a bit easier to do it at scale – especially if, per previous bullet, you can use AIs to help. So to the extent that some of the “practical difficulties” I discussed end up coming down to something like “sure you can do that for a tiny part of this giant neural network, but what about for the whole thing?”, I think doing the whole thing may often quickly become quite “executable,” at least if we’re willing to invest the resources required.[20]
Of course, this sort of rapid scaling is less viable to the extent that the sort of cognitive labor involved e.g. understanding each circuit is extremely bespoke, and/or to the extent that attempting to scale runs up against qualitatively more difficult sorts of tasks (e.g., because of the sorts of selection effects mentioned above – you got the easy bits early, but scaling requires tackling the harder parts).
- With respect to the concern that model cognition will resist human-legibility in principle:
- I do think this is a serious issue – and one that merely scaling up the effort we put into interpretability doesn’t necessarily address. However, I also think that there are strong reasons to expect at least some parts of even quite superintelligent cognition to make sense in human terms. In particular:
- Human concepts like “tree” tend to reflect genuinely useful “joints in nature,” and we should expect smart models to make use of those joints (see e.g. the discourse about the “natural abstraction” hypothesis for some more discussion).
- We already see trained models converging on fairly human-like concepts – e.g., many features models learn are in fact quite human-interpretable.
- And to the extent that models understand human language and can make predictions about the world using a human ontology, their world model needs to include human-like concepts in there somewhere.
- So key questions about the “non-human concepts” issue, for me, include:
- How much superintelligent cognition to expect to take place using non-human-legible concepts;
- Whether we might be able to make those concepts more legible/transparent;
- For example, can we expand the range of concepts humans can understand? Can the AIs teach us these concepts? Can we train AIs to think in more human legible ways?
- If not we can’t make them legible, how easy it would be to become confident that the non-legible cognition doesn’t contain dangerous stuff.
- For example: can we use the model’s human-legible concepts as enough of a signal about what’s going on in the non-legible parts of its mind? E.g., if we can use the human-legible parts of an AI’s world model to become confident that the model isn’t “lying” or “trying to take over” in the sense at stake in normal human discourse, how far does that go? My sense is that it plausibly goes quite far.
- And of course, if we could trust the labor of other AI systems that do understand the relevant concepts, this would go quite a bit further.
- I do think this is a serious issue – and one that merely scaling up the effort we put into interpretability doesn’t necessarily address. However, I also think that there are strong reasons to expect at least some parts of even quite superintelligent cognition to make sense in human terms. In particular:
- Finally, I think that we don’t necessarily need deep and thorough-going mechanistic understanding for interpretability to be a significant and useful part of an overall approach to motivation control. Rather, as I mentioned above, I think incremental bits of interpretability progress (including the type at stake in “best case” rather than “worst case” approaches; in more top-down approaches like lie-detection probes; in contexts where the relevant tools aren’t robust to being trained against or actively evaded by the model; etc) can make incrementally positive contributions to our overall toolkit and scientific understanding.
That said, these notes of optimism still leave a lot of questions open. Indeed, I generally tend to bucket plans for aligning superintelligence that rely heavily on interpretability success as counting on comparatively “non-executable” types of progress. That is, they are hoping that we eventually reach a certain state of technical expertise, but they don’t tend to offer a very clear sense of the specific steps we’d take to get there. As I’ll discuss in future work, my own best guess as to how we get to this kind of state is via significant help from our AI systems; and that if we can get significant help from our AI systems, we may not need, now, a particularly “executable” sense of what exactly they should be doing. But especially absent confidence in our ability to get significant help from our AIs, I think relying on something like “we’ll make a ton of progress on interpretability” seems pretty dicey to me.
New paradigm
So far, I’ve talked about approaches to transparency that attempt to build transparent agents out of safe-but-still-black-box ML models (open agency), and that try to make ML models less black-boxy (interpretability). But what about approaches that don’t rely on ML models at all?
Note: this isn’t the same as saying “by the time we’re building even human-level-ish AIs, we need to have transitioned to a new, more transparent, competitive, but less ML-ish paradigm.” I am quite skeptical of that kind of hope, at least in worlds with shorter timelines, because conditional on such timelines I expect that ML systems will continue to play a crucial role in near-term frontier AI development.[21]
Rather, the idea would be that by the time you’re building superintelligence, you need to have transitioned to this kind of new paradigm. Thus, for example, maybe your approach is to first build human-level-ish AIs via more traditional ML-ish methods, elicit a ton of useful labor from them aimed at attempting to identify some other new, more transparent, adequately competitive paradigm of AI development, and hope that it works. This sort of hope still has the problem of relying on some form of speculative and as-yet-unspecified paradigm switch; but at the least, it allows AI labor to drive the switch in question, rather than e.g. human labor within the next five years.
I’m not going to spend much time here, partly because it strikes me as one of the least executable paths forward, and partly because its speculative nature makes it hard to analyze in any detail. Very roughly, though, one paradigm vibe I associate with this kind of approach in my head is something like “make AI good-old-fashioned again.” That is, the thought goes: in the old days, building an AI system was like coding software directly. And when you code something yourself, you get a certain kind of mechanistic understanding up front. That is: you don’t need to “reverse” engineer it; rather, you were the original engineer, and so are already in possession of whatever it is that “mechanistic interpretability” seeks. But this is only one example of what a “new paradigm” might look like.
What internal variables are we targeting with our transparency?
OK, that was some discussion of three different approaches to transparency in general. Now I want to briefly talk about which internal variables in our AI system we might want to target with the transparency in question, in the context of an overall approach to motivational control.
Obviously, one salient variable to target here is the AI’s motivations themselves. After all, the motivations are the thing we’re ultimately trying to control; so for that goal, direct transparency into what those motivations are seems extremely helpful. Notably, though, it’s also possible to target other internal variables as well – especially if the motivations themselves prove elusive.
In particular, even absent direct transparency into the model’s motivations, I think transparency into the AI’s reasoning and its world model goes quite far, because many of the problematic and adversarial behaviors we’re worried about in our AIs specifically involve the AI knowing stuff that we don’t know about the consequences of its actions, and making predictions about those consequences that we’re not aware of. Thus, for example: if you’re worried about your AI lying, or messing with your processes for evaluating its behavior, or behaving well in training because it predicts that doing so will promote its ability to takeover later, then very plausibly, all of these unwanted dynamics will be present in the AI’s reasoning/world model. So transparency there could be extremely valuable as well.
It would also be useful, in many contexts, to have transparency into the model’s capabilities more generally. This is especially true in the context of strategies focused more on option control, since capabilities are such a crucial variable in determining the model’s options (see discussion below). But it likely seems true of motivation control as well. For example, if you had sufficient transparency into a model’s capabilities, you could do things like detect sandbagging (even on non-checkable tasks); to tell what fake takeover inputs it can distinguish, thus potentially assisting with attempts to test how it would behave on real versions; and so on.
Of course, in practice, distinctions between transparency with respect to a model’s motivations vs. other motivations may not be very important. For example, a sufficiently full read-out of a model’s reasoning in evaluating different plans will often contain its motivations directly (e.g., the model might well be doing some analog of “ok, which of these plans gets me the most paperclips. Let’s start with plan number 1…”).[22] And more generally, these different internal variables may be quite mixed up and tied together in the model’s cognition.
Still, I think it’s probably still worth distinguishing between these targets for transparency at a conceptual level, in part because differential success at transparency with respect to these different variables makes different routes for moving from transparency to motivational control available.[23] Let’s turn to that issue now.
How are we moving from transparency to motivation control?
Even granted that we achieve some significant degree of transparency – whether via open agency, interpretability, or some new paradigm – into some or all of the internal variables we care about, there’s still a further question about how we move from this transparency to active control over an AI’s motivations. Thus, for example, you could reach a point where you’re able to use transparency to learn that oops, your default behavioral feedback creates an AI system that wants to take over. But this knowledge is not necessarily enough, on its own, to tell us how to create a more benign AI system instead.
I’ll group the paths to translating from transparency to motivational control into two rough buckets: “motivational write access” and “improved behavioral feedback and iteration.”
Motivational write access
What is motivational write access? Broadly speaking, I have in mind techniques that proceed via the following pathway in the ontology I laid out above:
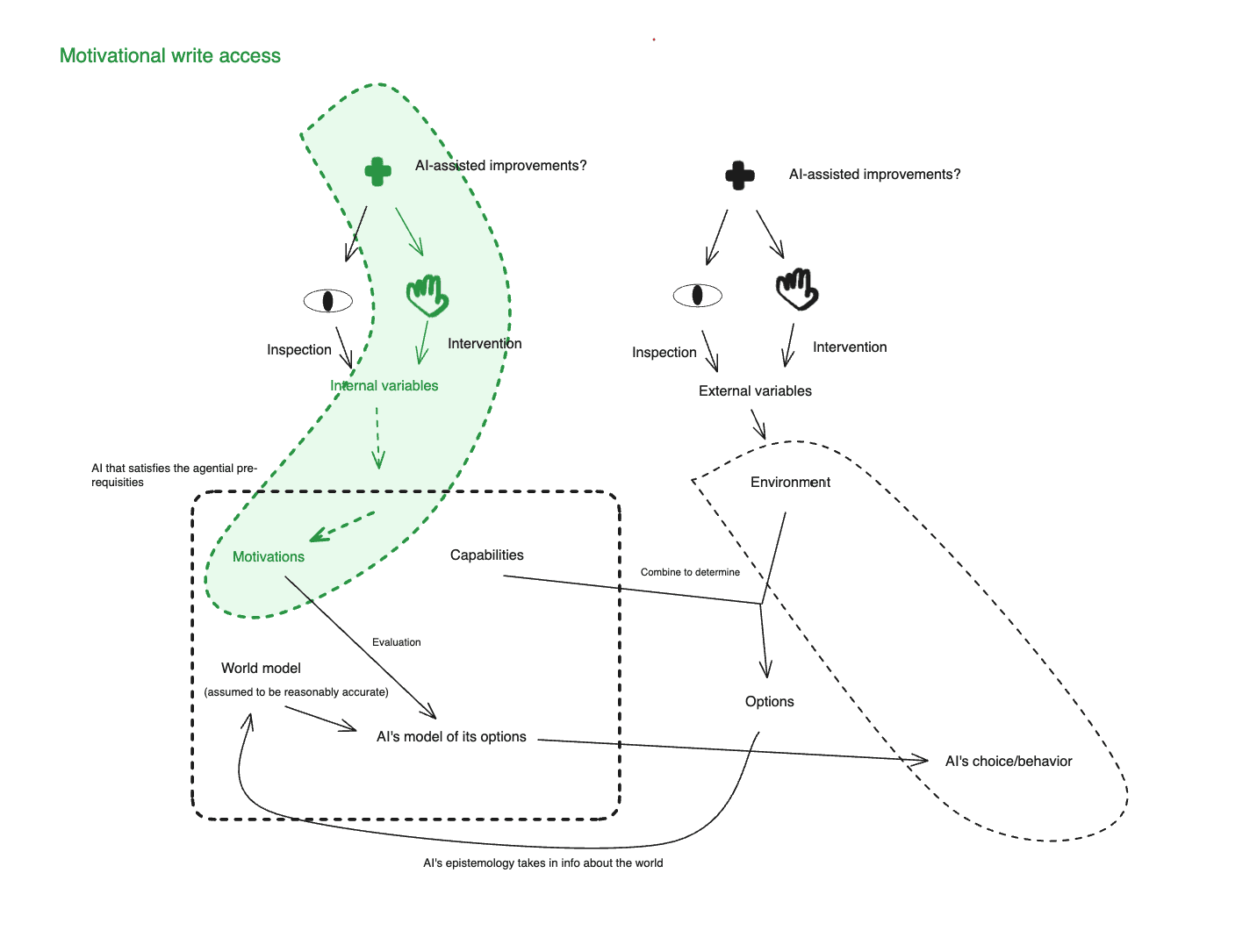
That is: motivational write-access is the ability to shape an AI’s motivations in desirable directions by intervening on them directly. See below (in footnotes) for more detail on what I mean here.
Motivational write access is closely related to motivational read access – that is, roughly speaking, adequate success at transparency, applied to the internal variable of “motivations” in particular, that you can inspect those motivations quite directly, rather than having to infer them from other variables like the model’s behavior. I.e., this pathway in the diagram:
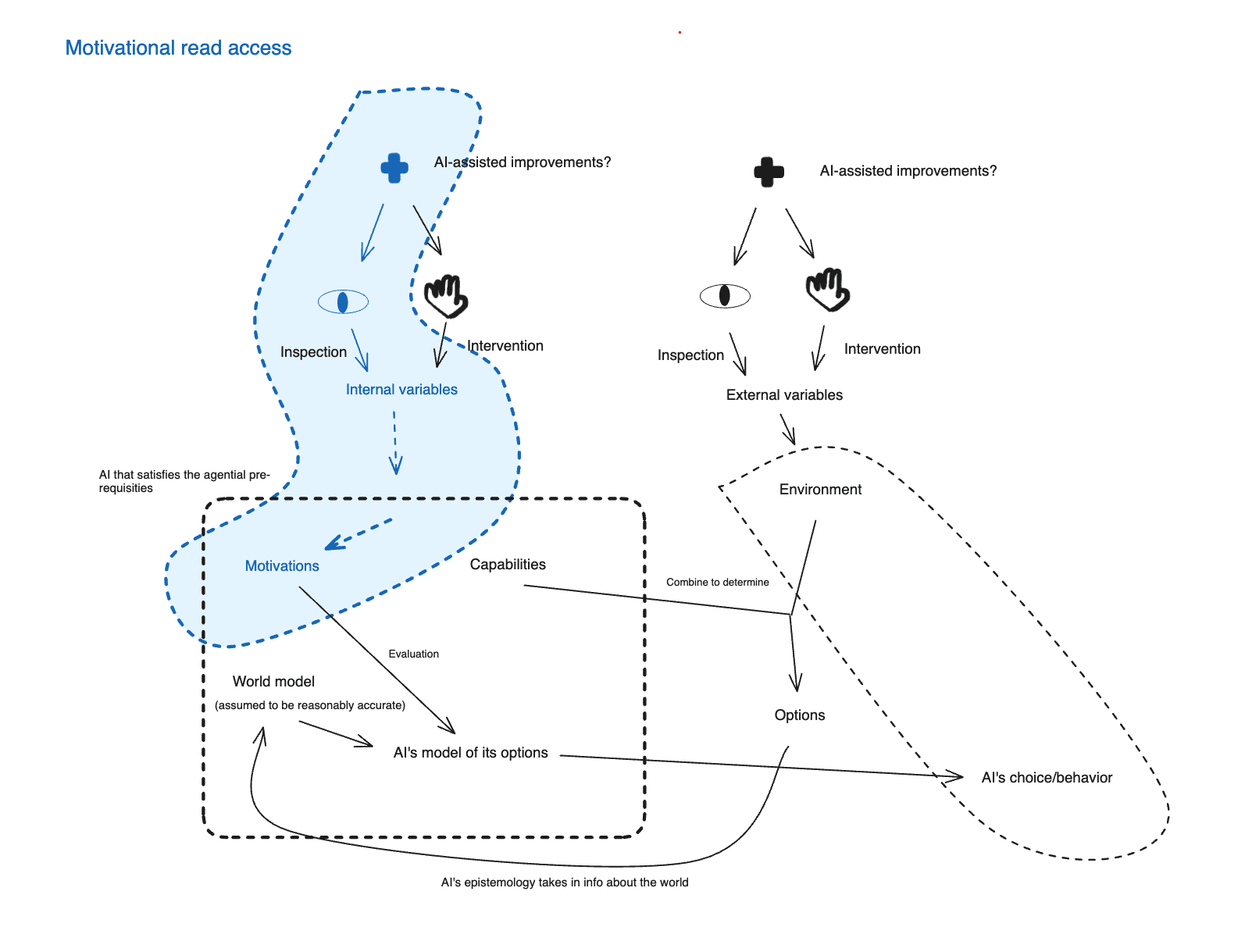
Admittedly: clearly distinguishing the particular type of motivational understanding and control at stake in motivational read/write access from other types is going to get tricky. I describe some of the outstanding conceptual trickiness in the footnotes here[24] (re: write access) and here[25] (re: read access). Perhaps, ultimately, the distinction isn’t worth saving. For now, though, I’m going to press forward – hopefully the examples I use of motivational read/write access will at least give a flavor of the contrast I have in mind.
I’m going to assume, here, that motivational write access requires motivational read-access (and that a given degree of motivational write access requires some corresponding degree of read access). That is, in order to be able to control a model’s motivations in the direct sense that I want motivational write access to imply, I’m going to assume that in some sense you need to be able to “see what you’re doing,” or at least to understand it. I.e., it’s strange to be able to write something you can’t also read.
However, as I noted above, and per my questions about translating from transparency to motivational control, I don’t think we should assume the reverse – i.e., that motivational read access requires motivational write access. Thus, indeed, the “we can tell the model is scheming, but we can’t get it to stop” case. And intuitively, you can often read stuff that you can’t rewrite.
So moving from the sort of transparency I discussed above to motivational write access requires both (a) successfully targeting the “motivations” variable, in particular, with your transparency techniques, and then (b) some further ability to directly intervene on that variable.
What might (b) look like in the context of the approaches to transparency we’ve discussed? It’s hard to say in any detail, but I think we can get at least some inkling:
- Thus, to my mind, the paradigm form of “motivational write access” at stake in an “open agency” approach to transparency is just: literally writing the AI’s prompt (and/or its model spec, its constitution, etc) in natural human language.
That is, I think that plausibly, in at least some suitably faithful and successful open agency architectures, it will be the case that the right way to interpret the composite agency in question is to say that the prompt/model spec/constitution basically just is the place that the agent’s motivations are stored. I.e., if you write something in that location, the normal, common-sensical construal of that bit of natural language ends up playing the functional role of motivations in the composite agent’s evaluation of different options/plans.[26]
- Note: this is distinct from having given any of the individual components of the composite agent this sort of motivation. Thus, for example, you could imagine a corporation that is well understood as being intrinsically motivated by e.g. maximizing shareholder value – or indeed, by e.g. whatever goals are written down on some strategy memo or mission statement – even without any of the individual employees being well described in this way.
- In the context of interpretability, if you have enough transparency to identify (a) which features in a model would represent the sorts of concepts you want to function as motivations for the model, and (b) which parts of a model’s cognition are playing the role of motivations, then you might be able to intervene on those parts to make them driven by the relevant features.
- Indeed, it’s at least arguable that we see glimmers of the potential for this sort of motivational write access in the context of e.g. Golden Gate Claude. That is, once Anthropic discovered the feature corresponding to the model’s concept of the golden gate bridge, they were able to upweight this feature in a manner that caused the model to be obsessed with the golden gate bridge. It’s easy to imagine doing something similar with concepts like “honesty,” “harmlessness,” “not taking over,” and so on – including in the context of models that are more fully agentic, engaged in more sophisticated forms of planning, and so on.
- See also “retargeting the search.”
- It’s harder to say what motivational write access might look like in the context of a new paradigm.
- To the extent we’re taking “make AI good old fashioned again” as one image of what a “new paradigm” might look like, “motivational write access” might occur in the context of some analog of hand-coding the AI’s motivations. Indeed, some of the early discourse about AI alignment worked centrally with this sort of image of motivational control.
Of course, motivational write access can come in degrees – i.e., maybe you can give your AI’s motivations very coarse-grained properties, but not very fine-grained and detailed ones. And of course, you still need to choose safe motivations to “write” (more on this below). But suitable success at motivational access seems like a paradigm instance of successful motivational control.
Improved behavioral feedback and iteration
Suppose, though, that you can’t get direct motivational write access of this form – either because you can’t get motivational read access at all (rather, you only have transparency into other internal variables, like the AI’s world model), or because you’re not skilled enough at intervening directly on the motivations in question. What options might you have for getting from transparency to motivational control in that case?
Let’s start with the case where you have motivational read access but not write access. Here, your motivational read access can still be extremely helpful in assisting with your efforts to get better at intervening on other variables (e.g., via behavioral feedback) in an effort to shape the AI’s motivations in the direction you want. Thus, for example:
- you can now iterate much faster in trying to understand how behavioral feedback shapes AI motivations, and in developing a scientific understanding of generalization more generally;
- you can tell which AIs you’re trying to get to help you might be scheming, reward-hacking, sandbagging;
- you can get various of the benefits of “catching AIs red handed” discussed here;
- and so on.
What about in the case where you have transparency into other non-motivation internal variables, but not into the motivations themselves? Roughly speaking, it’s the same story – that is, you’re now in a position to use that transparency to improve your understanding of how to productively (albeit, indirectly) control model motivations via other intervention points, like behavioral feedback. Thus, for example:
- If you had sufficient read access into an AI’s world model that you could detect the sort of instrumental reasoning at stake in scheming, you could train against that sort of reasoning as soon as it arises.
- If you had sufficient read access into an AI’s world model/capabilities, you might be able to better identify fake takeover inputs that the AI thinks are real, and use them in adversarial training. And if you had active write access to the AI’s world model (see, e.g., ROME for some inkling of what this might look like), then you could use this write access to induce it to believe that it has a genuine takeover option and see how it responds.
- And more generally, read access to an AI’s world model, combined with your observations of its behavior, will plausibly help quite a lot in backing out a picture of its motivations – thereby opening up the options involving “motivational read access” I just discussed.
Of course, as I’ve tried to emphasize, to the extent you’re iterating/training against various transparency-based metrics, you need the signal they provide to be robust to this sort of optimization pressure. But given adequate robustness in this respect, and even absent direct write access to a model’s motivations, read access to different variables opens up access to what we might call a “transparency-assisted science of AI motivation.” That is, rather than relying purely on behavioral science in our effort to understand how to shape our AI’s motivations in desirable ways, we can make use of this read access as well. Indeed, as I noted above, I think at least some amount of this is the default path; and as in the case of “behavioral science of AI motivation,” there’s a relatively smooth spectrum between “behavioral feedback + crossing your fingers” and “transparency-assisted science of AI motivations,” where incremental progress on the latter reduces the uncertainty reflected in the former.
Summing up re: motivation control
OK, that was a high-level survey of the main toolkit I think about in the context of motivation control. Here’s the chart from above again:
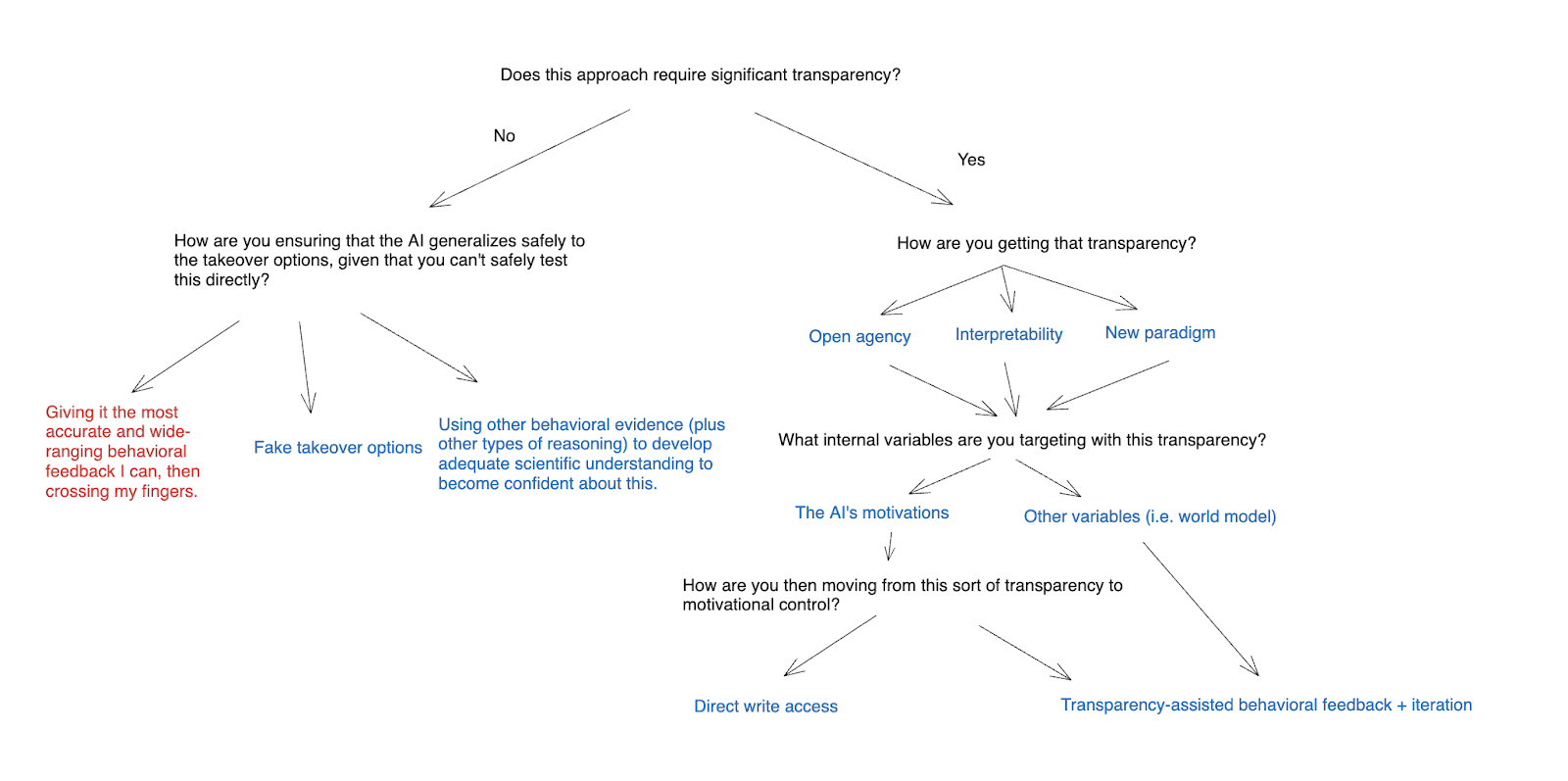
In developing this breakdown, I’ve tried to strike some balance between suitable comprehensiveness (such that it’s reasonably likely that in worlds where we succeed at motivation control, we do so in a way that recognizably proceeded via some combination of the tools discussed) and suitably specificity (i.e., doing more than just saying “you know, we figured out how to control the motivations”). I expect the discussion to still be somewhat frustrating on both fronts, in the sense that probably various approaches don’t fit very well, AND it still involves very vague and high-level approaches like “you know, study the behavior of the AIs a ton until you’re confident about how they’ll generalize to takeover options.” But: so it goes.
In my next post, I’ll turn to option control.
- ^
I defend this definition in a previous post here.
- ^
Though: I’m not attached to “generalization” as a term here. In particular, generalization is often understood relative to some distribution over inputs, and it’s not clear that such a distribution is especially well-defined in the relevant case (thanks to Richard Ngo for discussion here). Still, I think the fact that we can’t safely test the AI on actual takeover options, especially when combined with the hypothesis that the AI will be able to tell which takeover options are genuine, creates, in my view, a need for the AI’s good behavior to persist across at least some important change in the nature of its inputs. I’ll continue to use “generalization” as a term for this.
- ^
And I think that making good predictions in this respect is probably best understood under the heading of “selecting the right incentive specification“ rather than under the heading of “incentive implementation.”
- ^
Though note that the type of “write access” one actually has available might be much cruder. Thanks to Owen Cotton-Barratt for discussion here.
- ^
Though, I’m curious folks more embedded in the interp community would disagree here.
- ^
People sometimes talk about this issue in terms of the difficulty of “inner” and “outer” alignment, but I agree with Turner and others that we should basically just ditch this distinction. In particular: you do not need to first create a feedback/reward signal such that an AI optimizing for good performance according to that feedback/reward signal would have the motivations you want, and then also figure out how to cause your AI to be optimizing for good performance according to that feedback/reward signal. Rather, what you need to do is just: to create a feedback/reward signal such that, when the AI is trained on that feedback/reward signal, it ends up with the motivations you want. (That is, it doesn’t matter when you achieve this goal via ensuring that the motivations are “aligned” in some further sense to the feedback/reward signal in question.)
Indeed, I am personally skeptical that there even is a privileged construal of the feedback/reward signal at stake in a given training process, such that we can simply ask what an AI “optimizing for good performance according to that feedback/reward signal” would want/do. Rather, I expect tons of different construals of this to be compatible with a given training set-up.
To the extent we should be trying to recover some distinction in the vicinity of inner vs. outer alignment, I think it should basically just be the distinction between “incentive implementation” and “incentive specifications + justifications” that I discussed above, perhaps restricted to motivations in particular. That is, roughly, the thing to recover about outer alignment is the need to figure out the right motivations to give your AIs. And the thing to recover about inner alignment is the need to actually give the AI the motivations in question.
- ^
In this sense, once you grant the constraint of “some inputs are unsafe to test on,” it’s less clear that feedback range faces the sort of at-least-potentially-deep barrier, in the context of superintelligence, that feedback accuracy does. I.e., feedback accuracy has to reckon with the question of “how do you supervise superhuman task-performance that you can’t really understand yourself?” Whereas it’s not clear that there is an analogous issue in the context of feedback range.
- ^
Note: we could potentially understand any form of what I’ve previously called “training gaming” – i.e., AIs actively optimizing for reward-on-the-episode, whether for terminal reasons (i.e., they care intrinsically about some component of the reward process), or for instrumental reasons (i.e, they think that getting reward on the episode will promote some other goal they care about) – as a type of adversariality, because both forms involve an AI modeling our training process and actively trying to look good by the lights of that process. And both forms of training gaming, notably, seem compatible with the AI receiving very accurate feedback on a very wide range of inputs, such that lots of success on the “feedback quality” considerations above won’t necessarily eliminate the concern.
As I discussed in my scheming report, though, I’m hopeful that a sufficiently wide ranging type of adversarial training could at least detect terminal training-gaming, because terminal training-gamers will reveal their bad motives in scenarios where doing so gives them more reward-on-the-episode – and such scenarios seem plausibly quite safe to test (though not, perhaps, to train on). And in general, I think that terminal training-gaming is substantially less scary than instrumental training-gaming (and in particular, power-motivated instrumental training-gaming, i.e. scheming), because it involves less direct optimization for takeover in particular. So I’m focusing on scheming as my central example of an adversarial dynamic here – and I think it’s the clearest case where lots of success on feedback accuracy/range can still leave the concern unaddressed.
- ^
One disanalogy actually counts in favor of the issue being easier with AI systems – namely, that our methods of training AI systems are much more intensive and direct. E.g., modulo moral patienthood concerns, the intensity and directness of the training, red-teaming, etc that we can put in with respect to our AIs is very different from the sort at stake in how we tend to try to shape human motivations.
- ^
Of course, we can’t give the AI actual takeover options to try to distinguish from fake ones (though we could perhaps get close – e.g., if we showed the AI a “takeover the world” button, we could ask it whether the button was fake vs. real without giving it the opportunity to press), so you still need to be making some inference here.
- ^
Thanks to Buck Shlegeris for discussion here.
- ^
One especially esoteric version of an approach in the vicinity of “fake takeover inputs” is for future humans with radically advanced AI capabilities
- ^
Thus, for example, if the AI knows that its first going to be tested on a single fake takeover option, and then shown a million real takeover options, then even if it can’t tell them apart, behaving badly only .1% of the time would leave it quite unlikely to get caught before deployment, but with still a high likelihood of successfully “going for it” at some point during deployment. Thanks to Buck Shlegeris for discussion here.
- ^
In principle, we can understand “fake takeover options” as a limiting case of a model organism – but I think there are many less extreme options available.
- ^
See “The case for becoming a black box investigator of language models” for an example of someone making the case for this broad sort of science with respect to current AIs.
- ^
We could count fake takeover options as one approach to behavioral science, but I wanted to call them out separately because they seem like a sufficiently direct and distinguishable angle of attack on “generalization with no mistakes” problem.
- ^
Maybe “open agents” is a better term, since I think Drexler may want to not assume we’re building “agents” in the specific sense I have in mind. Possible I’ll change the terminology in future, but sticking with it for now. Thanks to Owen Cotton-Barratt for discussion.
- ^
It’s a bit unclear where exactly to fit “ensure that the human-legible aspects are also faithful” into this, and perhaps it should be bucketed as its own separate issue. Broadly, though, I’m imagining that if faithfulness is in some sense a “competitiveness” issue (because e.g. successful open agency requires faithfulness, so competitive success requires faithfulness as well); but that if it fails specifically due to scheming in the components (as opposed to some other reason), it also falls under “safety of the components.”
We can also imagine issues like “you’ve got a faithful and legible chain of thought, but it’s a zillion lines of text and it’s too hard to supervise.” But if we set aside competitiveness and safety-of-the-components, I think this is a comparatively minor issue that seems amenable to realistic forms of quantitative amplification of our supervision capacity (i.e., via training models to imitate human judgments about the safety of the chain of thought).
- ^
Insofar as these components do satisfy the agential prerequisites, and insofar as they do have the option to attempt to coordinate across the different components to later pursue takeover, this itself would be a “takeover option” if it has a non-trivial chance of success. But it could well be easier to make this sort of plan predictably fail than to deny takeover options to the composite agent overall.
- ^
Indeed, per the framing in the introduction of the paper, perhaps Anthropic’s work on “scaling mono-semanticity” is an example of this sort of dynamic – though I haven’t investigated in detail.
- ^
My vague sense is that interest in “switch to a new paradigm” is at least somewhat correlated with skepticism that ML is enough for AGI, and thus, perhaps, with longer timelines in general.
- ^
Recall that this AI satisfies the agential prerequisites, and so is well understood as searching over different plans, evaluating them on the basis of criteria, etc.
- ^
One researcher I spoke to was more also confident that transparency is possible, in principle, with respect to an AI’s world model – or at least, some parts of it – than with respect to its motivations, because the world model needs to be sufficiently similar to our own human ontology that the AI can successfully make predictions about the behavior of everyday human objects like potatoes; whereas the motivations could in principle be arbitrarily alien.
- ^
Outstanding conceptual issues with access write-access include:
- The ability to “directly shape an AI’s motivations in desirable ways” comes in degrees. In particular, you might be able to intervene to give an AI’s motivations some desirable properties, but not others.
- For example, if the property you have in mind is just: “these motivations in fact motivate blah behavior on blah input-we-can-train-on,” then methods like black-box SGD can get you that.
- And plausibly, properties like “this motivation will not in fact lead to takeover” are pitched at the wrong level of abstraction. Motivational write-access, intuitively, involves the ability to control whether the AI e.g. wants apples vs. wants oranges, but not the consequences of its doing so (you need to predict those yourself). So even in the limiting case of success at motivational read access, we’d need some restrictions re: the range of desirable properties we are able to “write.”
- What’s more, the contrast between “direct” and “indirect” forms of intervention, here, isn’t fully clear.
- Centrally, I want to say that black box SGD, without any understanding of a model’s internals, is an “indirect,” behavioral intervention. That is, you know how to alter the model’s internals such that they give rise to a certain kind of behavior on a certain set of inputs-you-can-test, but you lack a certain kind of direct visibility into what those motivations are. And in particular, in this context, you lack the kind of visibility that would help you confidently rule out adversarial dynamics like scheming, and that would help you predict how the model will generalize to takeover options.
- Suppose, though, that you had read access to a model’s motivations, but were still limited to SGD in your ability to alter them. In what sense might you still lack motivational write-access? As I discuss in the main text, intuitively the problem is that your ability to use SGD to give the model your intended motivations might still be quite limited – i.e., you might just need to flail around, trying lots of stuff, and potentially failing even with much iteration.
- However, suppose that you developed a very good understanding of how a given sort of SGD-based training ends up shaping a model’s motivations, such that you could very reliably give the AI the motivations you want using such training, and use your read access to verify that you’ve done so. Do you still lack “write access” in this case? I think it’s not clear. In the main text, I’ll talk about this as a case where you lack write access, but have very good “interp-assisted science of generalization,” but I think it might well be reasonable to just call this a case of write-access instead.
- The ability to “directly shape an AI’s motivations in desirable ways” comes in degrees. In particular, you might be able to intervene to give an AI’s motivations some desirable properties, but not others.
- ^
Outstanding conceptual issues with read access include:
- Ultimately, the thing that matters, from the perspective of the “understanding” aspect of controlling a model’s motivations, is just: do you in fact have an adequate understanding of an AI’s motivations to be able to predicts its behavior on in the environments you care about (i.e., in response to takeover options). And it’s not clear whether there is a deep distinction between intuitively “mechanistic” forms of understanding (i.e., the type we often intuitively think of as at stake in read-access, at least of certain kinds), and sufficiently thoroughgoing understanding of other kinds.
- Thus, for example, in the main text I talk about the possibility of developing a “behavioral science of AI motivation,” which does not rely on advances in interpretability, but which nevertheless develops sufficient understanding of how AIs trained via ML tend to generalize that it can confidently predict how AIs trained in blah way will behave on an extremely wide variety of inputs – including, saliently, in response to takeover options. Is there a principled distinction between this kind of success at behavioral science, and the sort of understanding that ambitious mech-interp is seeking? Intuitively, yes. But I don’t have a clear articulation.
- What’s more, it seems possible to get a certain kind of “read access” to a model’s motivations, and yet to lack the ability to predict its behavior in the ways you care about.
- A clear example of this, which I think wouldn’t even count as successful read access in the relevant sense, is a case where you get access, in some sense, to a model’s internal description of its motivations, but this description is in some language you can’t understand (i.e., “my goal is to blargle fjork”). Indeed, plausibly, this isn’t all that different from the current situation – we do have some kind of read access to a model’s mind (though we don’t know which bits of it would be storing the motivation aspects, to the extent it has motivations in the relevant sense), but we “can’t understand the language they’re written in.” But what is it to understand the language something is written in? Uh oh, sounds like a tough philosophy question.
- What’s more, to the extent we rely on some notion of “being able to predict stuff” to pin down the relevant sort of understand, there are spectrums of cases here that make it tricky to pin down what sort of prediction ability is necessary. Thus, intuitively, a case where you learn that the model wants to be “helpful” in some sense, but you don’t yet know how its concept of helpfulness would apply given an option to take over (can taking over be “helpful”?), this starts to look a bit like the blargle fjork case. But I think we also don’t want to require that in order to get read access to a model’s motivations, you need to be able to predict its behavior in arbitrary circumstances – e.g., if you can tell that a model wants to maximize oranges, this seems like it’s enough, even if you don’t yet know what that implies in every case.
All these issues seem likely to get quite tricky to me. Still, my current guess is that some distinction between “read access” and other forms of ability-to-predict-the-model’s-behavior is worth preserving, so I’m going to use it for now.
- Ultimately, the thing that matters, from the perspective of the “understanding” aspect of controlling a model’s motivations, is just: do you in fact have an adequate understanding of an AI’s motivations to be able to predicts its behavior on in the environments you care about (i.e., in response to takeover options). And it’s not clear whether there is a deep distinction between intuitively “mechanistic” forms of understanding (i.e., the type we often intuitively think of as at stake in read-access, at least of certain kinds), and sufficiently thoroughgoing understanding of other kinds.
- ^
Note: this is related but I think probably distinct from having successfully created even a composite agent that is in some sense “motivated to follow the prompt.” That is, in the vision of open agency I have in mind, the content of the prompt is the fundamental unit of information driving the planning process, rather than there being some other place in the agent that points to the prompt and says “do whatever it says there.” That said, I expect the lines here to get blurry.