Introduction and summary
(This is the fourth in a series of four posts about how we might solve the alignment problem. See the first post for an introduction to this project and a summary of the series as a whole.)
In the first post in this series, I distinguished between “motivation control” (trying to ensure that a superintelligent AI’s motivations have specific properties) and “option control” (trying to ensure that a superintelligent AI’s options have specific properties). My second post surveyed some of the key challenges and available approaches for motivation control; and my third post did the same for option control.
In this fourth and final post, I wrap up the series with a discussion of two final topics: namely, moving from motivation/option control to safety-from-takeover (let’s call this “incentive design”), and capability elicitation. Here’s a summary:
- I start with a few comments on incentive design. Here my main point is that even if you have a large amount of control over the motivations of a given AI (for example, the sort of control at stake in being able to write a model spec that the AI will follow in common-sensical ways), there is still at least some further work to do in choosing what sorts of motivations to give the AI in question, such that they won’t lead to the AI pursuing takeover given the full range of options it might be exposed to.
- I think there are lots of grounds for optimism on this front, especially if we’re really imagining that we have large amounts of motivational control available.
- In particular, avoiding takeover here might be almost as easy as writing, in your model spec, the rough equivalent of “seriously, do not try to take over.”
- And at-all-reasonable model specs – which ask the AI to be honest, compliant with instructions, etc – would already cut off many of the most salient paths to takeover.
- Still, I think we should remain vigilant about the possibility of ignorance about exactly what a given sort of motivational specification will end up implying, especially as the world changes fast, the AI learns new things, etc; and that we should invest in serious (probably AI-assisted) red-teaming to get evidence about this.
- I think there are lots of grounds for optimism on this front, especially if we’re really imagining that we have large amounts of motivational control available.
- I then turn to the issue of capability elicitation – the other main component of “solving the alignment problem,” on my definition, on top of avoiding takeover.
- I suggest that many of the tools and frameworks the series has discussed re: avoiding takeover transfer fairly smoothly to capability elicitation as well. Mostly, we just need to add the constraint that the AI’s incentives not only privilege the best benign option over its favorite takeover plan, but also that its best benign option is the desired type of task-performance, as opposed to something else (and conditional on avoiding takeover, failures on capability elicitation are lower stakes and more iteration-friendly).
- I briefly describe two key questions I think about in the context of capability elicitation, namely:
- Can we make desired task-performance “checkable” in the roughly “output-focused” sense I discuss here – i.e., verifiable centrally based on examination of the output/behavior in question.
- Can we successfully elicit forms of task-performance that are “checkable” in this sense using behavioral feedback (plus various other possible anti-sandbagging measures)?
- If the answer to both questions is “yes,” then I think there are grounds for optimism about capability elicitation centrally using behavioral feedback. If not, then we need to get fancier – and I discuss a few possibilities in this respect.
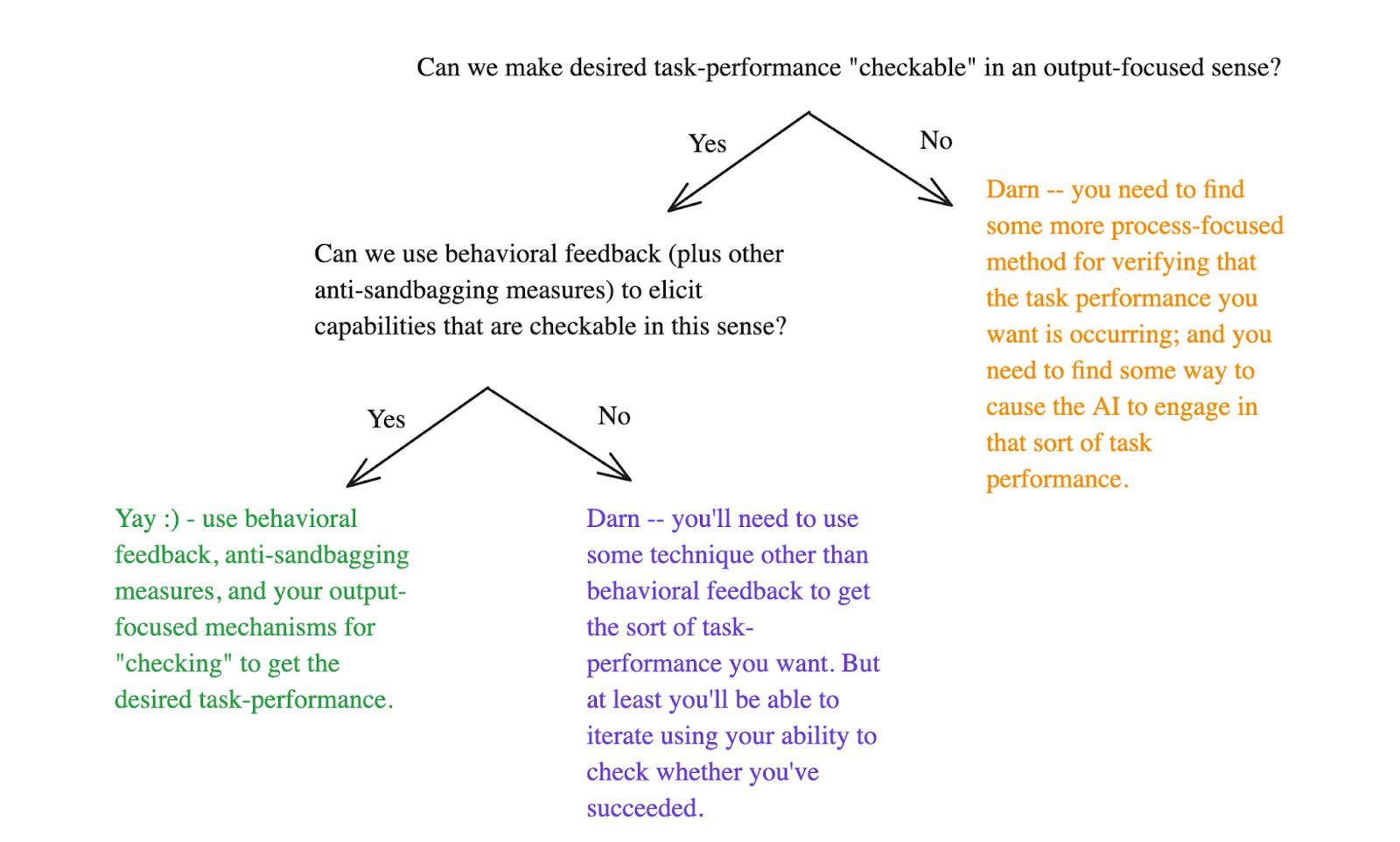
Diagram illustrating the two key questions I describe re: capability elicitation
- Finally, I emphasize that despite the comparatively small amount of attention I’ve given it in this series, capability elicitation is a crucial part of the overall picture, and deeply tied to avoiding takeover. In particular: the full challenge of avoiding takeover only arises in the context of capability elicitation (otherwise you could keep your superintelligence locked up in a box), and successfully eliciting the capabilities of various AIs is likely to play a crucial role in solving the alignment problem with respect to full-blown superintelligence. [1]
Incentive design
I’ve now reviewed what I see as the key tools and approaches available in attempting to control a given AI’s options and motivations. But at a high level, the discussion so far has been centrally focused on what I previously called “incentive implementation” – that is, the mechanisms via which we can ensure that an AI’s options and motivations have some set of desirable properties. But especially in the context of motivation control, I’ve said comparatively little, directly, about what I previously called “incentive specifications” (that is, the properties you’re trying to ensure that your AI’s options and motivations have) and “incentive justifications” (that is, your story about why these properties lead to safety).
Of course, in some cases, the desirability of certain properties, from the perspective of avoiding takeover, is extremely obvious. Notably, for example, in the context of option control, restricting the AI’s available paths to takeover (where otherwise compatible with suitable capabilities elicitation) is basically always a good idea.[2]
And more generally, I think we don’t want to get too hung up on the distinction between incentive implementation, incentive specification, and incentive justification.
- In particular, perhaps in some contexts, one doesn’t actually need a story about the specific properties one is giving to an AI’s options and motivations, provided that you can make a more direct argument that whatever these properties are, they will ensure safety. That is: really, a safety-from-takeover case only needs a story that gets you from “we’re going to do blah” to “no takeover.” It doesn’t need to route via some intermediate goal; nor, indeed, does it need to route via a distinction between options and motivations in particular (though to the extent you are in fact planning to expose your AI to any takeover options it can recognize as such, you will in fact be banking on its motivations having certain properties, whether your safety case makes reference to these properties or not).[3]
Still, especially in the context of certain kinds of motivation control, I do think the distinction between “what properties are you aiming for” and “why do you think those properties lead to safety” is real and at-least-potentially important.
To me, a paradigm version of this is a scenario where you have successfully achieved some fairly high degree of motivational control in your AIs, such that, e.g., you can be confident that your AI will always act in accordance with fairly common-sensical interpretations of some prompt, constitution, or model spec that you are in a position, quite literally, to “write.”[4] In this sort of scenario, there is at least some remaining question as to what, exactly, that prompt/constitution/model spec should say to ensure the AI does not end up pursuing takeover even when given takeover options with substantive chances of success. And this especially if your approach to “option control” aspires to be robust to this AI being exposed to a very wide array of options in a rapidly changing world.
Perhaps, ultimately, this bit will be fairly easy. Perhaps, indeed, you basically just need to do the equivalent of writing, very forcefully, “also, seriously, rule number 1: do not try to take over” in the model spec, and this will be enough. Certainly, much of what you would expect, by default, in an at-all-reasonable model spec – i.e., stuff about honesty, obeying existing laws, following instructions, not harming humans, etc – seems to cut down drastically on the paths to takeover available, at least when interpreted common-sensically. And a higher standard than “at-all-reasonable” could presumably do better.
Still, even in the context of this sort of fine-grained motivational control, I think it is still worth being vigilant about the possibility of good-old-fashioned “King Midas” problems – that is, for scenarios where, as we watch the AI taking over, we end up saying some equivalent of “yeah, I guess our model spec did technically imply that in this scenario, now that I think about it – damn.” In particular: even granted the sort of “motivational write access” at stake in full, common-sensical alignment to a model spec or constitution, it is still a further step to predict accurately what behavior that model spec or constitution implies in the full range of scenarios the AI might be exposed to. And we should make sure to do that step right, too.
Notably, though: especially if we’ve otherwise got lots of motivational control, I think we will likely be in an extremely good position to get AIs to help with this part of the process – for example, via intensively red-teaming a given model spec/constitution to understand its implications in an extremely wide range of circumstances, flagging possible problems, suggesting amendments and adjustments, and so on.[5]
- Thus, for example, if we have the sort of motivational control at stake in fully aligning an AI to whatever we write in a model spec, I think it’s much more likely that we’ll also have the sort of motivational control required to generally trust an AI to try its best to answer honestly when asked about what it would do in a given circumstance; and also, the sort of motivational control required to get trusted AI labor to help generate possible circumstances to ask about. And if we have that, then we could get AI red-teamers to extensively interrogate any given AI about its counterfactual behavior in a zillion possible scenarios before deploying it, to make sure we’re not missing wacky implications of its understanding of the constitution in question. (Though, of course, even if the AI is answering honestly, it might not know what it would do in any given circumstance.)
That said, note that full alignment to a written model spec is a very extreme case of fine-grained, intuitively human-legible motivational control – one especially suited to making the final move to “therefore no takeover” comparatively simple. In other cases, the available paths to motivational control may only allow us to ensure that the AI’s motivations have much more course-grained and/or illegible properties, such that we will not be able to do the equivalent of writing “rule number 1: do not takeover” into the AI’s motivational system directly. In such scenarios, the “incentive specifications” that we actually have feasible paths to might be much more limited, and thus the need for strong and substantive “incentive justifications” (i.e, stories about why the properties we can actually ensure lead to safety-from-takeover) will become more pressing.
Capability elicitation
So far, I’ve only discussed the bit of the alignment problem focused on creating superintelligent AI agents that don’t take over. But on my definition of solving the alignment problem, at least, there’s another bit, too: namely, becoming able to elicit the capabilities of those agents enough to get access to most of their benefits.
Comparison with avoiding takeover
As I discussed in my post on defining the alignment problem, we can think of capabilities elicitation via a modified version of the incentives framework I discussed in the context of takeover. I.e., to the extent we’re only interested in avoiding takeover, then we just need to make sure that the AI’s best benign option beats its favorite takeover option. But if we need to ensure desired elicitation as well, then we also need to ensure that from amongst the AI’s non-takeover options, the desired elicitation option, in particular, is the best.[6]
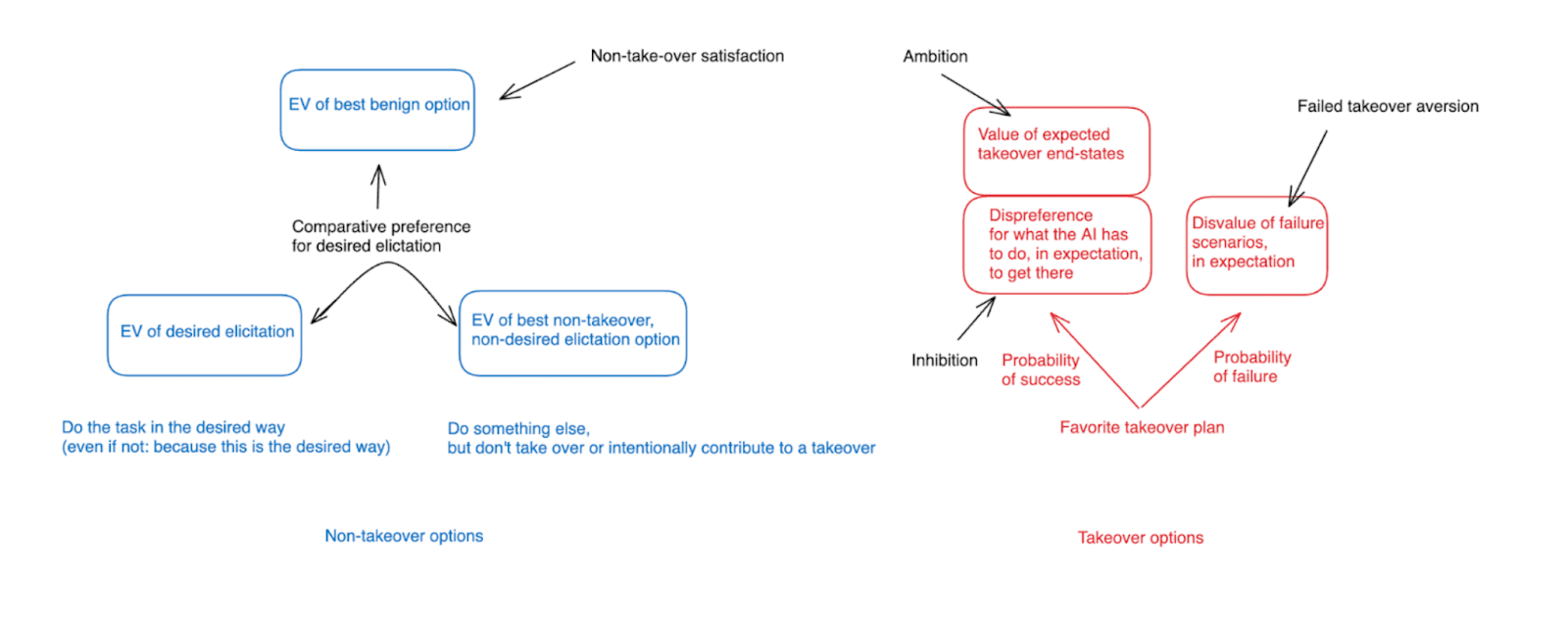
In a sense, then, this is just a slightly-modified version of the “avoiding takeover” problem we’ve already been discussing, and a very large number of the same tools, considerations, and frameworks apply. In particular: we can use a combination of option control and motivation control to try ensure that incentives at play for the AI specifically favor desired elicitation over everything else; we can use “incentive structure safety cases” to structure and justify our efforts in this respect; and we can almost all of the motivational control and option control techniques discussed above in service of these efforts.
That said, it’s worth noting a few interesting differences that introducing the need for capability elicitation brings into the picture.
- One important difference is that it cuts down on the available approaches to takeover-path restriction, because you need your AI to have whatever capabilities, affordances, and access to the real-world that desired elicitation involves.
- I’ve already been implicitly accounting for this in the discussion in the previous posts in the series, but it’s worth noting explicitly.
- Another difference, which I highlighted at the beginning of the series, is that if you can successfully hold “no pursuit of takeover options” as a constant, then the rest of the challenge – i.e., getting the AI to pursue the desired elicitation vs. some other non-takeover option – seems much less worrying on its own.
- In particular: you don’t need to get that right on the first critical try. Rather, it’s generally much more amenable to iteration, especially if you can notice that you’re failing to get the elicitation you want. And even if you can’t notice this, this failure, on its own, need not imply an irrecoverable catastrophe like an AI takeover. Rather, it may just be that e.g. your solar cells, or your cancer cures, are durably worse than you think.
- Though there is at least one salient exception to this: namely, cases where success at eliciting the relevant capability was itself load-bearing in some other broader story about avoiding takeover and/or some other irrecoverable catastrophe (i.e., you needed to elicit this AI’s full capabilities for spotting vulnerabilities in code, for creating reliable interpretability techniques, for securing yourself against some kind of bio-risk, etc).
- In particular: you don’t need to get that right on the first critical try. Rather, it’s generally much more amenable to iteration, especially if you can notice that you’re failing to get the elicitation you want. And even if you can’t notice this, this failure, on its own, need not imply an irrecoverable catastrophe like an AI takeover. Rather, it may just be that e.g. your solar cells, or your cancer cures, are durably worse than you think.
- Also, a lot of AI research intuitively classed under “capabilities” will end up relevant, by default, to capabilities elicitation in particular; and figuring out out how to do desired-capability elicitation well seems like it’s more plausibly on the “default path” of commercial AI development than more specifically anti-takeover-focused work (more comments here).
- Finally, note that to be effective re: capability elicitation in particular, our various efforts to improve benign options relative to takeover options now need to be more targeted.
- Thus, for example, if you are using motivation control to shape how an AI feels about benign options, you need to specifically use it to privilege desired elicitation over the best non-takeover, non-desired elicitation option.
- And the same holds if you are using option control to e.g. alter the incentives at play in non-takeover behavior. I.e., if you are trying to use “rewarding cooperation” to get the behavior you want, you need to target your rewards specifically at desired elicitation rather than simply at not-taking-over.[7]
Two key questions
Beyond noting these differences, I won’t attempt an especially detailed analysis of capability elicitation here. In particular, my previous post on defining the alignment problem contained a reasonably in-depth discussion of how I think about the issue (see e.g. here, here, and here), and I don’t want to repeat myself too much. Roughly speaking, though, I tend to break down the issue of capability elicitation according to two key questions:
- Can we make desired task-performance “checkable” in the roughly “output-focused” sense I discuss here – i.e., verifiable centrally based on examination of the output/behavior in question.
- In many relevant cases – i.e., “did this cancer cure work?” – I think human labor can actually go pretty far here.
- But I expect that effectively “checking” the full range of task performance we want to elicit from a superintelligence would require access to superhuman cognition labor – for example, via bootstrapping up from some combination of trusted and untrusted AI labor. (And this does, indeed, bring up most-if-not-all of the general issues with bootstrapping discussed earlier in this series.[8])
- Can we successfully elicit forms of task-performance that are “checkable” in this sense using behavioral feedback (plus various other possible anti-sandbagging measures)?
- One key way to fail on this is if the AI successfully sandbags as part of a takeover effort. See e.g. my post on the “no sandbagging on checkable tasks” hypothesis (plus a few more comments here) for more on whether this would be possible.
- But in principle we could imagine elicitation issues that arise even independent of this kind of actively adversarial sandbagging. I.e., maybe we just don’t have enough of the right kind of data.
If the answer to both questions is yes, that’s good news. In particular, we can then use some combination of scalable oversight and behavioral feedback to get the elicitation we’re looking for (at least if we can also hold fixed the “no takeover” constraint enough to apply behavioral feedback specifically to difference between desired elicitation and other benign forms of task performance).[9]
If the answer to question (1) is “no,” then we need to find a more “process-focused” method of verifying that the task performance we want is occurring (assuming we don’t want to just cross our fingers); and we need, on top of that, to cause it to actually occur (via some combination of i.e. behavioral feedback, direct intervention on model internals, changing its environment/incentives, etc). My post on defining the alignment problem discussed various salient methods in this respect, many of which raise basically the same sorts of issues we discussed above in the context of avoiding takeover, e.g.:
- To the extent you want to appeal to an AI’s observed generalization behavior in arguing that it’s doing desired-elicitation on an input you can’t “check” more directly, you need to rule out various adversarial dynamics like scheming.
- To the extent you want to use motivational transparency to argue that an AI is trying its best on this input, you need to get the transparency in question.
- And so on.
If the answer to question (1) is “yes” but the answer to question (2) is “no,” then you’re at least in an epistemic position to check whether various non-behavioral-feedback-based efforts to elicit the relevant form of task-performance are succeeding – so you’re less at risk of e.g. wrongly banking on a misguided perception of success at elicitation in some catastrophic way (i.e., in the context of a broader ant-takeover plan), and you get the benefits of iteration in response to trial and error.[10] But if you can’t use standard forms of behavioral feedback to actually get the elicitation you want, you need to find some other method (i.e., intervening on the AI’s internals, using option control to alter its incentives, etc).
Thus, in a chart:
Not an afterthought
Overall, I’ve tended to focus more of my thinking on the dynamics surrounding avoiding takeover than on the dynamics surrounding capability elicitation – focus evident in the balance of attention in this series. This is partly because it’s avoiding takeover, in particular, that raises the scariest “first critical try” dynamics; and partly because I hazily expect capability elicitation seems to me more continuous with the default path and commercial incentives of less safety-concerned actors (plus, perhaps, some other reasons as well).
I do worry, though, that I haven’t treated capability elicitation with the attention it deserves, and that separating it from avoiding takeover too much might lead to a misleading read on its importance and difficulty. In particular, success at capabilities elicitation and success at avoiding takeover strike me as crucially tied together.
- I.e., you can’t just say (as I am sometimes tempted to say) “well, let’s first figure out avoiding takeover, and then if we can get the option control and motivation control necessary to do that, capabilities elicitation will be relatively straightforward,” because the full challenge of avoiding takeover only arises in the context of the sorts of capabilities and affordances that capabilities elicitation in particular requires (otherwise e.g. you can just keep your superintelligence entirely locked-up in a box).
- And conversely, if you can successfully elicit capabilities from various AI systems, then the fruits of this elicitation can themselves play an extremely key role in various approaches to avoiding takeover (i.e., in roughly any context where we’ve needed or wanted to draw on AI labor).
So I want to be clear: capabilities elicitation is not the afterthought that the attention it’s receiving here might suggest.
That said, I am indeed going to leave the topic here for now. Hopefully, these brief comments, the earlier discussion of available general techniques for option control and motivation control, plus the comments in my previous post, are enough to at least give a broad sense of how I’d think about the lay of the land.
Conclusion
OK, this series has been a long discussion of how I currently think about the space of approaches to the full alignment problem. Admittedly, it was heavy on taxonomy, and I haven’t advocated very hard for one approach in particular. Perhaps, in future, I’ll say more about the paths forward that seem most promising to me. For now, though, my main aim has been to get a clearer object-level grip on the space as a whole; and it’s not at all clear to me that we need, now, to have strong takes on which approaches to the full problem will eventually prove most effective. Rather, I think that our own focus should be on more intermediate milestones – and in particular, on putting ourselves in a position to get help from AIs that aren’t full-blown superintelligences in improving the situation more broadly. I’ll turn to that issue more directly in future posts.
- ^
See Jan Leike’s recent post for some more comments on this front.
- ^
Though, maybe not from other perspectives other than avoiding takeover.
- ^
Here I’m attempting to avoid a more generalized analog of the mistake that I see Turner, here, as pushing back on (though: I think the distinction between “incentive implementation” and “incentive specification” is importantly different from the distinction between “aligning what’s-being-rewarded” and “ensuring the AI cares intrinsically about the thing-being-rewarded,” which is the central case, in my opinion, of a place where we should ditch inner vs. outer alignment distinction and just focus directly on the getting the motivations we want).
- ^
That is, the relevant constitution/model spec isn’t just being used to guide the behavioral feedback given to the AI in training. Rather, the AI’s motivations are keyed to the constitution/model spec directly.
- ^
Thanks to Carl Shulman for discussion here.
- ^
At least if we’re assuming that the elicitation itself is also governed by the sort of agentic-planning at stake in choices about takeover pursuit; if not, though, my “two key questions” framework below still applies.
- ^
Note: I think aiming to use option control to specifically punish the AI for non-takeover, non-desired-elicitation behavior raises moral and prudential concerns similar to the ones I discussed in the context of punishing failed takeover attempts above. Indeed, the moral justification for this sort of punishment seems weaker in this case, because it is not protecting us from takeover in particular, but rather simply functioning to incentivize one form of benign task-performance over another.
- ^
Though again, the fact that capability elicitation is lower stakes than avoiding takeover helps here. E.g., if the AIs involved in “checking” some output try to “collude” to give inaccurate representations of its quality, this doesn’t, on its own, lead to irrecoverable catastrophe; whereas if the AIs involved in oversight aimed at preventing-takeover do this, it’s much worse.
- ^
If we assume that we’re holding fixed the relevant features of AI’s options throughout this training, this feedback will amount to a type of motivational control – i.e., we’re shaping the AI’s motivations so that they come to prefer the desired elicitation option over other benign options.
- ^
Though: you might not know whether or not the AI is capable of doing the task at all, and so be unsure whether you’ve got an elicitation issue or a capabilities issue.