Co-authored by Sammet, Joshua P. S. and Wale, William.
Foreword
This report was written for the Policies for slowing down progress towards artificial general intelligence (AGI) case of the AI governance hackathon organized by Apart Research.
We are keen on receiving your thoughts and feedback on this proposal. We are considering publishing this on a more public platform such as arXiv, and therefore would love for you to point out potential issues and shortcomings with our proposal that we should further address in our article. If you think there are parts that need to be flushed out more to be understandable for the reader or any other things we should include to round it up, we are more than happy to hear your comments.
Introduction
In this paper, we propose a tax that affects the training of any model of sufficient size, and a concrete formula for implementing it. We explain why we think our framework is robust, future-proof and applicable in practice. We also give some concrete examples of how the formula would apply to current models, and demonstrate that it would heavily disincentivize work on ML models that could develop AGI-like capabilities, but not other useful narrow AI work that does not pose existential risks.
Currently, the most promising path towards AGI involves increasingly big networks with billions of parameters trained with huge amounts of text data. The most famous example being GPT-3, whose 175 billion parameters were trained on over 45 TB of text data[1]. The size of this data is what sets apart LLMs from both more narrow AI models developed before and classical high-performance computing. Most likely, any development of general or even humanoid AI will require large swathes of data, as the human body gathers 11 million bits per second (around 120 GB per day) to train its approx. 100 billion neurons[2]. Therefore, tackling the data usage of these models could be a promising approach to slowing down the progress of the development of new and more capable general AIs, without harming the development of models that pose no AGI risk.
The proposal aims to slow down the progress towards AGI and mitigate the associated existential risks. The funds collected through data taxation can be used to support broader societal goals, such as redistribution of wealth and investments in AI safety research. We also discuss how the proposal plays well with other current criticisms of the relationship between AI and copyright, and persons and their personal data, and how it could consequently levy those social currents for more widespread support.
The Data Taxation Mechanism
A challenge in devising an effective data tax formula lies in differentially disincentivizing the development of models that could lead to AGI without hindering the progress of other useful and narrow ML technologies. A simplistic approach, such as imposing a flat fee per byte of training data used could inadvertently discourage beneficial research that poses no AGI risk.
For instance, a study aimed at identifying the most common words in the English language across the entire internet would become prohibitively expensive under the naïve flat fee proposal, despite posing zero danger in terms of AGI development. Similarly, ML applications in medical imaging or genomics, which often rely on vast datasets, would also be adversely affected, even though they do not contribute to AGI risk.
To overcome the challenge of differentially disincentivizing AGI development without impeding progress in other beneficial narrow AI applications, we propose a data tax formula that incorporates not only the amount of training data used but also the number of parameters being updated during the training process. This approach effectively distinguishes between large models, such as GPT-3 [1], and smaller models, enabling our proposal to more accurately target projects that contribute to AGI advancements.
The Formula
The proposed formula for taxing the process of training a model from an initial state to a final state is:
With:
Where:
- : the fee for a given state, .
- : the number of parameters in the final model
- : the size of the dataset, given in bytes, that the initial model has been pre-trained on
- : the size of the dataset, given in bytes, that the model is being trained on in this instance
- : a constant factor, given in a specific currency per bytes, that varies by which type of data you are using. This constant should be continuously adjusted to ensure that future advancements made towards AGI are sufficiently taxed.
- and are to be specified functions
- : a constant determining a threshold that needs to be surpassed before taxes are imposed. This way people training small models, or people training models using small amounts of data, do not have to pay data taxes. This constant should be continuously adjusted to maintain the intended functionally in the future.
Once you have chosen and , and the constants and , this formula allows you to calculate the tax that any actor has to pay whenever they train a new ML model (or further train an existing one). The formula only takes as inputs the number of parameters of a model, the amount of data the model uses, and the type of data the model uses (its rough category).
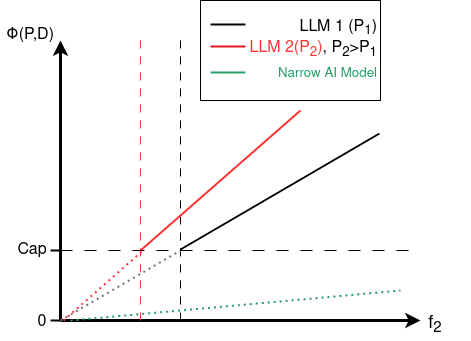
We will for this proposal pick the functions and to be linear, specifically of the form , and the appendix explains why we think linear functions might actually be the best option. But it also covers other alternative functions that potentially could do a better job at only penalizing advancements towards AGI, while not penalizing smaller models, more narrow models, or other ML systems that do not pose existential threats to society.
Feasibility
To make the formula even more concrete, we have several example calculations in the next section which also serve the purpose of demonstrating how the formula can be implemented in a way that penalizes LLMs very heavily, without non-negligibly penalizing smaller or narrower ML models.
Example Calculation
ChatGPT
ChatGPT was trained on 45 TB of text data and consists of 175 billion parameters [1]. For the sake of simplicity, we will assume a training from scratch, and being identity functions, and , i.e. one would have to pay for every kind of AI being trained.
If the aimed tax for such a model would be 1 billion $, one could easily derive a . In this case, we would have $, and Bytes.
Therefore,
$ = with
This can be reordered and yields
hence, .
Cancer-Net SCb
To illustrate the feasibility of such a penalty, i.e. that it does not hinder development of narrow AI models, this calculation can be done for other models. In this case, we choose Cancer-Net SCb, a model that detects skin cancer using images with 84% of accuracy [3].
In this scenario, , GB and we use the data type factor derived above, . One has to keep in mind that the data type factor for images should be even smaller, as images are significantly bigger in data size compared to text. However, with those variables and settings as in the ChatGPT example, we end up with a tax of
This simple and reduced example gives an idea how, even with a taxation for ChatGPT being 200 times the cost of a training run [4], the cost for a simple and narrow model is very low. This would be further ensured by introducing a above , exempting small models from taxation altogether. When introducing a cap or changing one of the functions , needs to be increased/ adapted slightly to maintain the taxation that is wished for a certain model size. However, the example calculation in this section gives a rough orientation of the size of the parameters and the feasibility.
Tracking and Enforcement
Comparable to other research areas that come with high risk, such as biotechnology, it could be required for researchers and programmers to write risk analysis for their projects. For normal models, this has to be neither complex nor exhaustive, as it could be a single PDF. The risk analysis document could be stored at the administrative office of the company or university to be shown during a control. For bigger models, a more elaborate risk analysis might be necessary, comparable with working with high infectious or deadly viruses.
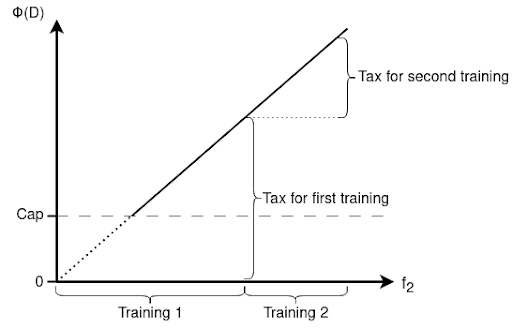
At simplest, the risk analysis document should contain the planned model size and amount of data expected to be utilized for training. All models must be tagged with the volume of data utilized during their training and the respective data type. When building upon an existing model, the amount of data previously used for training must be accounted for. This requirement is critical and must be enforced to avoid tax evasion by iteratively training large models with small datasets. These regulations aim to close potential loopholes and ensure that data taxes apply to any advancements made on pre-trained models, as illustrated in Figure 2.
Additional tracking of the actual data volumes could be done fairly easily using the logs of the GPUs itself. Most GPU servers already track the usage of their users and monitor occupancy of their system. It could be made mandatory to store those log files in a very reduced fashion, e.g., information on what network (or the storage path of its files) was run by whom, and how much data was put through the system. These log-files then have to be stored for at least a year and made accessible to authorities during controls. Deletion of the logging function from a GPU would be considered at least tax evasion in a very serious case and heavily penalized. For-profit providers of GPU clusters use similar mechanisms to calculate the cost for their customers already today.
The aforementioned monitoring could be combined with a lab book, as it is again common in chemical or biological research to track experiments. Here, the built architecture is described, its size is stated, and the amount of data is briefly stated. Making it mandatory for researchers, public as well as private, to keep a record of their experiments could also boost refection and lower the amount of necessary training runs in early stage development, perchance.
It might be ingenuous to trust each country to monitor the taxation formula and adapt in an honest and risk-aware manner. If that is the case, an international body could be instantiated to monitor and govern changes of the data taxation model. Similar to bodies like the World Trade Organization (WTO) or the Organization for the Prohibition of Chemical Weapons (OPCW), which is monitoring and enforcing states to abstain from chemical weapons. Such an organization, potentially under the roof of the United Nations, offers potential for negotiations on fine-tuning of the model or the exact redistribution scheme of the gathered taxes (see below). One potential name for such an organization could be “Organization for Monitoring Artificial Intelligence Progress (OMAIP)”.
Popular Support and Rhetorical Viability - Co-Opting Existing Movements and Ideas
The concept of data taxation has the potential to gain popular support and rhetorical viability by aligning with existing social movements and ideas that critique big AI models. Although the primary motivation behind our proposal is mitigating existential risks through slowing down the development of AGI, we think our proposal also meets the demands of these movements.
For instance, the widespread use of large generative image models like Stable Diffusion, Dalle-E, and Midjourney has raised concerns about potential copyright violations in the training data. One suggested solution is to classify the scraping of images from the internet for building these models as copyright infringement, and require actors that train these models to compensate the creators of the images they use. While the scope and objectives of this solution differ from our proposal, the underlying idea of imposing fees for using data aligns with our data taxation concept.
Furthermore, data taxing could address concerns related to AI-driven job displacement and rising unemployment. As AI technology advances and automates tasks previously performed by humans, many worry about the potential loss of employment opportunities. By implementing a data tax on the use of large AI models, governments can generate revenue that could be directed towards social programs, such as retraining initiatives, education, and a universal basic income (UBI). These programs would help workers adapt to the changing job market, learn new skills, and provide a financial safety net during the transition.
Aligning the data taxation proposal with these concerns may garner broader public support and create a more viable approach to AI governance. In our proposal, the collected taxes would be directed towards social programs rather than individual creators. By resonating with the concerns of existing movements, we believe our policy has the potential to gain traction and support in broader discussions about AI governance.
Redistribution of Collected Taxes
As mentioned in the introduction, slowing down progress of AGI development through taxation does not only offer the benefit of achieving the main goal, but incidentally creates additional resources which can be used in various ways.
As discussed in the “Popular support and rhetorical viability - co-opting existing movements and ideas” section, collected taxes could be used in a universal basic income scheme. The disruption caused in the job market is already expected with the recent deployments such as GPT-4 [5] and will most probably not become smaller in the future. Further, this might boost the acceptance of narrow AI being deployed into daily business life, as people would have the feeling to profit from it.
Another option would be redistribution of the taxed money into AI safety research. This could include research on AI alignment and existential risks, but also transparency, interpretability and reliability research. Research in the latter topics might strengthen our understanding of AI systems further, and allow us to more precisely define the boundary of AGI models and their potential risks.
A combination of the proposed redistribution methods is possible, or other usages such as funding societal programs in general. Redistribution of funds from high-income countries, where most of the AI companies have their headquarters, to low- and middle-income-countries might be a way to account for political and economic imbalance, that is especially strong in the IT sector. Such schemes could be discussed within the forum of an international organization, as described at the end of the section “Tracking and Enforcement”.
Addressing Challenges and Loopholes:
One possible tax evasion scheme could entail the slight alteration of a trained model to mark it as a new one. Such behavior, resembling the offense of colorable imitation, could be done by manually changing a single parameter after successful training. For sufficient deep and complex neural networks, such a change would not alter the performance much. However, just as minimal changes do not create a new mark in the case of colorable imitation, slightly changing a trained parameter does not create a new AI model.
To phrase it even more clearly, a new model could be defined as a network with initialized weights that are either all the same constants or randomly assigned in a comprehensible process.
Critics may argue that the proposed taxation scheme could further boost inequality. It might be impossible for new companies or groups from low-income-countries to catch up in even narrow AI development, since big narrow or non-risk AI models would be taxed, as it would be not possible to make AGI development financially unviable. Further, companies that already developed LLMs, e.g., OpenAI’s GPT-4, would have a strong market advantage as they cannot be taxed in hindsight. However, it's worth noting that huge inequalities in resource distribution are not a new development, especially in AI research. Using the tax scheme to redistribute funding, as mentioned in the section “Redistribution of collected taxes”, might help to make this gap even smaller than it is today.
Conclusion
The Data Taxation Mechanism is a novel proposal aimed at addressing the existential risks posed by the rapid development of AGI. By implementing a tax formula that takes into account the amount of training data, the number of parameters, and the type of data being used, this mechanism seeks to differentially disincentivize AGI development without hindering beneficial narrow AI research.
To ensure the success of this taxation scheme, tracking and enforcement measures such as risk analysis documentation, data usage logs, and lab books will be implemented. A possible pathway to oversee those measures by an international organization has been outlined.
Furthermore, various alternatives of the redistribution of the collected tax to support social programs, AI safety research, or address imbalances in the IT sector were covered. Moreover, it was discussed how such implementations could strengthen public support and approval even more.
Additionally, possible malpractices such as the tax evasion scheme of slightly altering a model iteratively to stay beneath the tax threshold have been mentioned and addressed.
By extensively describing the taxation scheme, addressing potential challenges and loopholes, the Data Taxation Mechanism stands as a viable policy for slowing down progress towards AGI.
Appendix: Additional Mathematical Deliberations and the Term “Tax”
Mathematical Deliberations
What reasons are there for picking and to be linear, and what other options are there?
If one of our goals is to specifically target models that are large enough to create AGI-risk other functions than the linear choice for might be better . The linear choice already achieves our goal to some degree; larger models have to pay linearly larger fees, and model size tends to grow exponentially. However, if one wanted to target large models even more specifically, you could pick or to be convex functions with terms like or .
This might be beneficial because it could surgically target specific model sizes and make them infeasible to train, without harming the development of smaller models in the slightest, as the fee would start off negligible and grow slowly until it reached a certain point, after which it would quickly become very expensive. However, these functions also have some downsides. One such downside is that it has a smaller band where models are feasible to train but expensive.
This means that for the tax to be effective in achieving our goal, we need much higher levels of certainty about exactly how big models need to be in order to be dangerous. To illustrate this, you could imagine that we’ve determined that you need parameters to build AGI. And we’ve put to be such that the fee for a model with parameters and a given dataset is one trillion dollars, i.e. impossible to afford. But then someone makes some unexpected progress that allows your model to achieve AGI-level capabilities using only parameters. Then, if is linear, the fee would be reduced to 500 billion dollars, which should not make a qualitative difference. But, if instead is exponential or otherwise strongly convex, the fee might change rapidly, for example shrink by a factor of a million, and to train the model would cost almost nothing (fee-wise at least).
Another reason the linear function is good is because it is much easier to enforce, and reduces some issues with how someone who wanted to avoid paying taxes could partition the data they wanted to use into smaller chunks, and only use one chunk at a time.
If we look at
But take to be linear, it reduces to:
And if someone trains their model on partitioned data in multiple steps, we can just add up our function as we otherwise would. In other words, we could calculate the fee to be paid exactly, just by looking at the amount of new data added to a model. Without having to worry about anyone trying to dodge taxes by being clever about which order they use the data.
To lessen the bureaucratic burden for developing smaller AI models, function could be designed in an ReLU-like fashion. It would therefore yield zero until it reaches a defined threshold of parameters , i.e., .
This has the effect that the value is now permanently reduced by , which could be tackled using a piece-wise function such as
, for , and , for .
On the Term Taxation
The data tax we propose would fall under the concept of a Pigouvian tax [6], as it disincentivizes usage of large amounts of data or large models to slow down AGI research. It serves as a stop for actors to engage in an unrestricted race towards AGI, which could potentially lead to the development of unsafe or uncontrollable AI systems. This kind of tax is established for carbon emission taxation, as it is implemented in some countries such as Denmark [7] and proposed in the European Union [8].
As a result, even though payment will be based on data usage rather than revenue or profit, the term tax rather than fee will be used throughout this document to refer to the suggested method.
Sources as Footnotes
- ^
Cooper, Kindra. “OpenAI GPT-3: Everything You Need to Know.” Springboard Blog, 27 Oct. 2022, www.springboard.com/blog/data-science/machine-learning-gpt-3-open-ai.
- ^
“Information Theory | Definition, History, Examples, and Facts.” Encyclopedia Britannica, 25 Mar. 2023, www.britannica.com/science/information-theory/Physiology.
- ^
Lee, J.R.H., Pavlova, M., Famouri, M. et al. Cancer-Net SCa: tailored deep neural network designs for detection of skin cancer from dermoscopy images. BMC Med Imaging 22, 143 (2022). https://doi.org/10.1186/s12880-022-00871-w
- ^
Li, Chuan. “OpenAI’s GPT-3 Language Model: A Technical Overview.” Lambda Labs, 12 Aug. 2022, lambdalabs.com/blog/demystifying-gpt-3.
- ^
Eloundou, Tyna, et al. ‘GPTs Are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models’. ArXiv [Econ.GN], 2023, http://arxiv.org/abs/2303.10130. arXiv.
- ^
Kolstad, C. D. (2000). Environmental Economics. Oxford: Oxford University Press.
- ^
Reuters Staff. “Denmark Agrees Corporate Carbon Tax.” Reuters, 24 June 2022, www.reuters.com/markets/commodities/denmark-agrees-corporate-carbon-tax-government-2022-06-24.
- ^
Kanter, James. “Europe Considers New Taxes to Promote ‘Clean’ Energy.” The New York Times, 22 June 2010, www.nytimes.com/2010/06/23/business/energy-environment/23carbon.html?_r=2&ref=cap_and_trade.
Interesting idea – thanks for sharing and would be cool to see some further development.
I think there’s a crucial disanalogy between your proposal and the carbon emissions case, assuming your primary concern is x-risk. Pigouvian carbon taxes make sense because you have a huge number of emitters whose negative externality is each roughly proportional to the amount they emit. 1000 motorists collectively cause 1000 times the marginal harm, and thus collectively pay 1000 times as much, as 1 motorist. However, the first company to train GPT-n imposes a significant x-risk externality on the world by advancing the capabilities frontier, but each subsequent company that develops a similar or less powerful model imposes a somewhat lower externality. Once GPT-5 comes out, I don’t think charging 1bn (or whatever) to train models as powerful as, say, ChatGPT affects x-risk either way. Would be interested to hear whether you have a significantly different perspective, or if I've misunderstood your proposal.
I’m wondering whether it makes more sense to base a tax on some kind of dynamic measure of the “state-of-the-art” – e.g. any new model with at least 30% the parameter count of some SOTA model (currently, say, GPT4, which has on the order of 100tn parameters) must pay a levy proportional to how far over the threshold the new model is (these details are purely illustrative).
Moreover, especially if you have shorter timelines, the number of firms at any given time who have a realistic chance of winning the AGI race is probably less than five. Even if you widen this to "somehow meaningfully advance broad AI capabilities", I don't think it's more than 20(?)
A Pigouvian tax is very appealing when you have billions of decentralised actors each pursuing their own self-interest with negative externalities - in most reasonable models you get a (much) more socially efficient outcome through carbon taxation than direct regulation. For AGI though I honestly think it’s far more feasible and well-targeted to introduce international legislation along the lines of “if you want to train a model more powerful than [some measure of SOTA], you need formal permission from this international body” than to tax it – apart from the revenue argument, I don’t think you’ve made the case for why taxes are better.
That being said, as a redistributive proposal your tax makes a lot of sense (although a lot depends on whether economic impact scales roughly linearly with model size, whereas my guess is, again, that one pioneering firm advancing capabilities a little has a more significant economic effect than 100 laggards building more GPT-3s, certainly in terms of how much profit its developers would expect, because of returns to scale).
Also, my whole argument relies on the intuition that the cost to society (in terms of x-risk) of a given model is primarily a function of its size relative to the state of the art (and hence propensity to advance capabilities), rather than absolute size, at least until AGI arrives. Maybe on further thought I’d change my mind on this.
Thanks you for this feedback, and well put! I've been having somewhat similar thoughts in the back of my mind, and this clarifies many of those thoughts.
This is a good proposal to have out there, but needs work on talking about the weaknesses. A couple examples:
How would this be enforced? Global carbon taxes are a good analogue and have never gotten global traction. Linked to the cooperation problem between different countries, the hardware can just go to an AWS server in a permissive country.
From a technical side, I can break down a large model into sub-components and then ensemble them together. It will be tough to have definitions that avoid these kind of work-around and also don't affect legitimate use cases.
Thank you for the examples! Could you elaborate on the technical example of breaking down a large model into sub-components, then training each sub-components individually, and finally assembling it into a large model? Will such a method realistically be used to train AGI-level systems? I would think that the model needs to be sufficiently large during training to learn highly complex functions. Do you have any resources you could share that indicate that large models can be successfully trained this way?
This a unique, interesting and simple proposal I have not seen presented in academic form yet. With the development of the article, you'll of course need to change the framing of a few sections to introduce the idea, the viability, along with the multi-purpose potential of the proposal.
Despite unlikely effective enforcement of the policy, it seems like a valuable idea to publish. Combining it with newer work in GPU monitoring firmware (Shavit, 2023) and your own proposals for required GPU server tracking.
To comment on kpurens comment, carbon taxation was a non-political issue before it became contentious and if the lobbying hadn't hit as hard, it seems like there would be a larger chance for a global carbon tax. At the same time, compute governance seems more enforceable because of the centralization of data centers.
Thanks for the feedback and for sharing Yonadav Shavits paper!