It's the crux between you and Ajeya, because you're relatively more in agreement on the other numbers. But I think that adopting the xpt numbers on these other variables would slow down your own timelines notably, because of the almost complete lack of increase in spending.
That said, if the forecasters agreed with your compute requirements, they would probably also forecast higher spending.
in terms of saving “disability-adjusted life years” or DALYs, "a case of HIV/AIDS can be prevented for $11, and a DALY gained for $1” by improving the safety of blood transfusions and distributing condoms
These numbers are wild compared to eg current givewell numbers. My guess would be that they're wrong, and if so, that this was a big part of why PEPFAR did comparatively better then expected. Or maybe that they were significantly less scalable (measured in cost of marginal life saved as a function of lives saved so far) than PEPFAR.
If the numbers were right, and you could save more lives than PEPFAR for 100x less money (or 30x (?) less after taking into account some falls in cost), I'm not sure I buy that the political feasibility of PEPFAR was greater than the much cheaper ask (a priori). At least I get very sympathetic to the then-economists.
(But again, I'd guess those numbers were probably wrong or unscalable?)
Incidentally, as its central estimate for algorithmic improvement, the takeoff speeds model uses AI and Efficiency's ~1.7x per year, and then halves it to ~1.3x per year (because todays' algorithmic progress might not generalize to TAI). If you're at 2x per year, then you should maybe increase the "returns to software" from 1.25 to ~3.5, which would cut the model's timelines by something like 3 years. (More on longer timelines, less on shorter timelines.)
Yeah sorry, I didn't mean to say this directly contradicted anything you said. It just felt like a good reference that might be helpful to you or other people reading the thread. (In retrospect, I should have said that and/or linked it in response to the mention in your top-level comment instead.)
(Also, personally, I do care about how much effort and selection is required to find good retrodictions like this, so in my book "I didn't look up the data on Google beforehand" is relevant info. But it would have been way more impressive if someone had been able to pull that off in 1890, and I agree this shouldn't be confused for that.)
Re "it was incorrect by an order of magnitude": that seems fine to me. If we could get that sort of precision for predicting TAI, that would be awesome and outperform any other prediction method I know about.
And, as I think Eliezer said (roughly), there don't seem to be many cases where new tech was predicted based on when some low-level metric would exceed the analogous metric in a biological system. [...] And the way in which machines perform tasks usually looks very different than how biological systems do it (bird vs. airplanes, etc.).
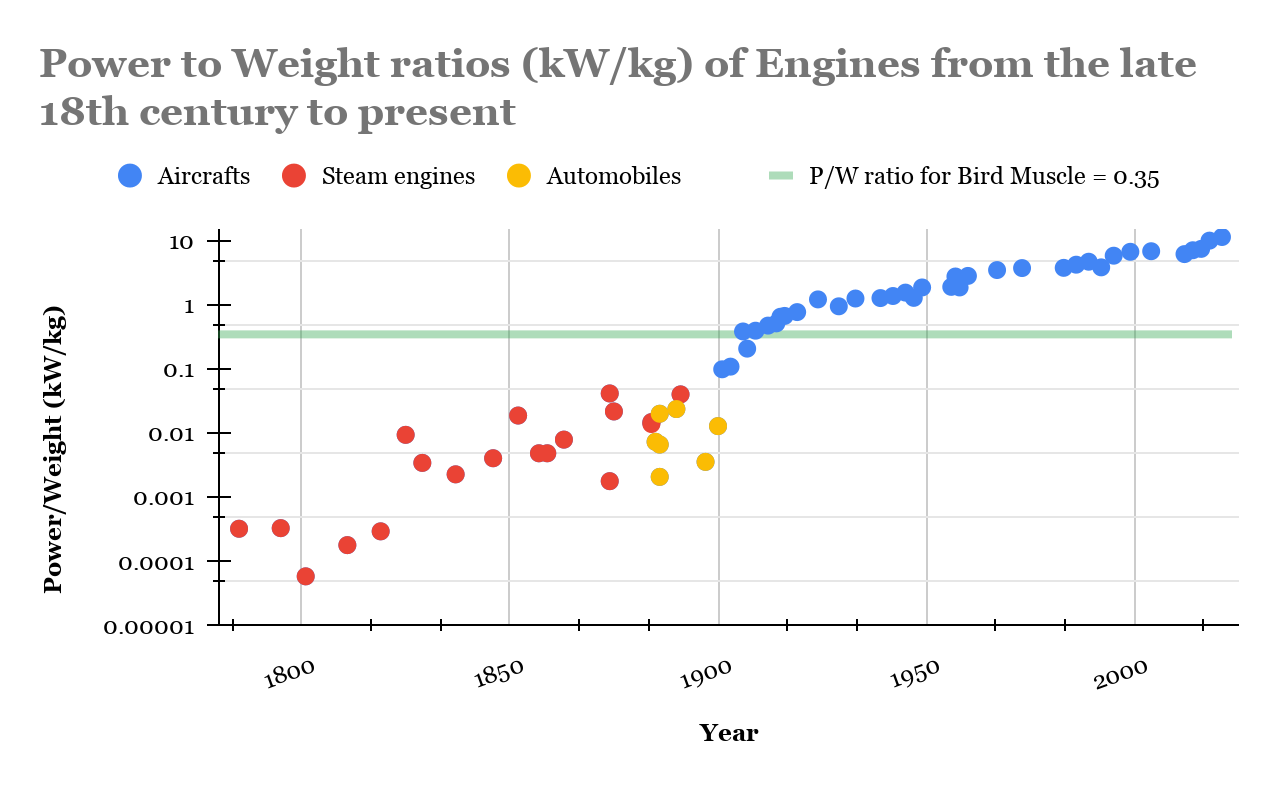
This data shows that Shorty [hypothetical character introduced earlier in the post] was entirely correct about forecasting heavier-than-air flight. (For details about the data, see appendix.) Whether Shorty will also be correct about forecasting TAI remains to be seen.
In some sense, Shorty has already made two successful predictions: I started writing this argument before having any of this data; I just had an intuition that power-to-weight is the key variable for flight and that therefore we probably got flying machines shortly after having comparable power-to-weight as bird muscle. Halfway through the first draft, I googled and confirmed that yes, the Wright Flyer’s motor was close to bird muscle in power-to-weight. Then, while writing the second draft, I hired an RA, Amogh Nanjajjar, to collect more data and build this graph. As expected, there was a trend of power-to-weight improving over time, with flight happening right around the time bird-muscle parity was reached.
I think my biggest disagreement with the takeoff speeds model is just that it's conditional on things like: no coordinated delays, regulation, or exogenous events like war, and doesn't take into account model uncertainty.
Cool, I thought that was most of the explanation for the difference in the median. But I thought it shouldn't be enough to explain the 14x difference between 28% and 2% by 2030, because I think there should be a ≥20% chance that there are no significant coordinated delays, regulation, or relevant exogenous events if AI goes wild in the next 7 years. (And that model uncertainty should work to increase rather than decrease the probability, here.)
If you think robotics would definitely be necessary, then I can see how that would be significant.
But I think it's possible that we get a software-only singularity. Or more broadly, simultaneously having (i) AI improving algorithms (...improving AIs), (ii) a large fraction of the world's fab-capacity redirected to AI chips, and (iii) AIs helping with late-stage hardware stuff like chip-design. (I agree that it takes a long time to build new fabs.) This would simultaneously explain why robotics aren't necessary (before we have crazy good AI) and decrease the probability of regulatory delays, since the AIs would just need to be deployed inside a few companies. (I can see how regulation would by-default slow down some kinds of broad deployment, but it seems super unclear whether there will be regulation put in place to slow down R&D and internal deployment.)
My own distribution over the training FLOP for transformative AI is centered around ~10^32 FLOP using 2023 algorithms, with a standard deviation of about 3 OOM.
Thanks for the numbers!
For comparison, takeoffspeeds.com has an aggressive monte-carlo (with a median of 10^31 training FLOP) that yields a median of 2033.7 for 100% automation — and a p(TAI < 2030) of ~28%. That 28% is pretty radically different from your 2%. Do you know your biggest disagreements with that model?
The 1 OOM difference in training FLOP presumably doesn't explain that much. (Although maybe it's more, because takeoffspeeds.com talks about "AGI" and you talk about "TAI". On the other hand, maybe your bar for "transformative" is lower than 100% automation.)
Some related responses to stuff in your post:
The most likely cause of such a sudden acceleration seems to be that pre-superintelligent systems could accelerate technological progress. But, as I have just argued above, a rapid general acceleration of technological progress from pre-superintelligent AI seems very unlikely in the next few years.
You argued that AI labor would be small in comparison to all of human labor, if we got really good software in the next 4 years. But if we had recently gotten such insane gains in ML-capabilities, people would want to vastly increase investment in ML-research (and hardware production) relative to everything else in the world. Normally, labor spent on ML research would lag behind, because it takes a long time to teach a large number of humans the requisite skills. But for each skill, you'd only need to figure out how to teach AI about it once, and then all 10 million AIs would be able to do it. (There would certainly be some lag, here, too. Your posts says "lag for AI will likely be more than a year", which I'm sympathetic to, but there's time for that.)
When I google "total number of ml researchers", the largest number I see is 300k and I think the real answer is <100k. So I don't think a huge acceleration in AI-relevant technological progress before 2030 is out of the question.
(I think it's plausible we should actually be thinking about the best ML researchers rather than just counting up the total number. But I don't think it'd be crazy for AIs to meet that bar in the hypothetical you paint. Given the parallelizability of AI, it's both the case that (i) it's worth spending much more effort on teaching skills to AIs, and (ii) that it's possible for AIs to spend much more effective time on learning.)
Also, if the AIs are bottlenecked by motor skills, humans can do that part. When automating small parts of the total economy (like ML research or hardware production), there's room to get more humans into those industries to do all the necessary physical tasks. (And at the point when AI cognitive output is large compared to the entire human workforce, you can get a big boost in total world output by having humans switch into just doing manual labor, directed by AIs.)
However, my unconditional view is somewhat different. After considering all potential delays (including regulation, which I think is likely to be substantial) and model uncertainty, my overall median TAI timeline is somewhere between 20-30 years from now, with a long tail extending many decades into the future.
I can see how stuff like regulation would feature in many worlds, but it seems high variance and like it should allow for a significant probability of ~no delay.
Also, my intuition is that 2% is small enough in the relevant context that model uncertainty should push it up rather than down.
Of the remaining 5 %, around 70 % would eventually be reached by other civilisations, while 30 % would have remained empty in our absence.
I think the 70%/30% numbers are the relevant ones for comparing human colonization vs. extinction vs. misaligned AGI colonization. (Since 5% cuts the importance of everything equally.)
...assuming defensive dominance in space, where you get to keep space that you acquire first. I don't know what happens without that.
This would suggest that if we're indifferent between space being totally uncolonized and being colonized by a certain misaligned AGI and if we're indifferent between aliens and humans colonizing space: then preventing that AGI is ~3x as good as preventing extinction.
If we value aliens less than humans, it's less. If we value the AGI positively, it's also less. If we value the AGI negatively, it'd be more.
If AGI systems had goals that were cleanly separated from the rest of their cognition, such that they could learn and self-improve without risking any value drift (as long as the values-file wasn't modified), then there's a straightforward argument that you could stabilise and preserve that system's goals by just storing the values-file with enough redundancy and digital error correction.
So this would make section 6 mostly irrelevant. But I think most other sections remain relevant, insofar as people weren't already convinced that being able to build stable AGI systems would enable world-wide lock-in.
Therefore, it seems to me that most of your doc assumes we're in this scenario [without clean separation between values and other parts]?
I was mostly imagining this scenario as I was writing, so when relevant, examples/terminology/arguments will be taylored for that, yeah.
It's the crux between you and Ajeya, because you're relatively more in agreement on the other numbers. But I think that adopting the xpt numbers on these other variables would slow down your own timelines notably, because of the almost complete lack of increase in spending.
That said, if the forecasters agreed with your compute requirements, they would probably also forecast higher spending.