
Jay Bailey
Bio
Participation2
I'm a software engineer from Brisbane, Australia who's looking to pivot into AI alignment. I have a grant from the Long-Term Future Fund to upskill in this area full time until early 2023, at which point I'll be seeking work as a research engineer. I also run AI Safety Brisbane.
How others can help me
I will be looking for a research engineering position near the end of 2022. I'm currently working on improving my reinforcement learning knowledge. (https://github.com/JayBaileyCS/RLAlgorithms)
How I can help others
Reach out to me if you have questions about basic reinforcement learning or LTFF grant applications.
Posts 4
Comments146
With respect to Point 2, I think that EA is not large enough that a large AI activist movement would be comprised mostly of EA aligned people. EA is difficult and demanding - I don't think you're likely to get a "One Million EA" march anytime soon. I agree that AI activists who are EA aligned are more likely to be in the set of focused, successful activists (Like many of your friends!) but I think you'll end up with either:
- A small group of focused, dedicated activists who may or may not be largely EA aligned
- A large group of unfocused-by-default, relatively casual activists, most of whom will not be EA aligned
If either of those two would be effective at achieving goals, then I think that makes AI risk activism a good idea. If you need a large group of focused, dedicated activists - I don't think we're going to get that.
As for Point 1, it's certainly possible - especially if having a large group of relatively unfocused people would be useful. I have no idea if this is true, so I have no idea if raising awareness is an impactful idea at this point. (Also, there are those that have made the point that raising AI risk awareness tends to make people more likely to race for AGI, not less - see OpenAI)
I think there's a bit of an "ugh field" around activism for some EA's, especially the rationalist types in EA. At least, that's my experience.
My first instinct, when I think of activism, is to think about people who:
- Have incorrect, often extreme beliefs or ideologies.
- Are aggressively partisan.
- Are more performative than effective with their actions.
This definitely does not describe all activists, but it does describe some activists, and may even describe the median activist. That said, this shouldn't be a reason for us to discard this idea immediately out of hand - after all, how good is the median charity? Not that great compared to what EA's actually do.
Perhaps there's a mass-movement issue here though - activism tends to be best with a large groundswell of numbers. If you have a hundred thousand AI safety activists, you're simply not going to have a hundred thousand people with a nuanced and deep understanding of the theory of change behind AI safety activism. You're going to have a few hundred of those, and ninety nine thousand people who think AI is bad for Reason X, and that's the extent of their thinking, and X varies wildly in quality.
Thus, the question is - would such a movement be useful? For such a movement to be useful, it would need to be effective at changing policy, and it would need to be aimed at the correct places. Even if the former is true, I find myself skeptical that the latter would occur, since even AI policy experts are not yet sure where to aim their own efforts, let alone how to communicate where to aim so well that a hundred thousand casually-engaged people can point in the same useful direction.
I am one of those meat-eating EA's, so I figured I'd give some reasons why I'm not vegan, to aid the goals of this post in finding out about these things.
Price: While I can technically afford it, I still prefer to save money when possible.
Availability: A lot of food out there, especially frozen foods which I buy a lot of since I don't like cooking, involves meat. It's simply easier to decide on meals when meat is an option.
Knowledge: If I were to go vegan, I would be unsure how to go vegan safely for an extended period, and how to make sure I got a decent variety rather than eating the same foods over and over (which comes into taste - I don't mind vegan food but there's much more variety I can find in meat-based dishes)
Convenience: Similarly to above - it takes resources to seek out vegan options, more resources than to just eat normally.
The harms are real, but the harms are far away and abstract. So when I feel vaguely guilty about eating meat, I think about all the hassle and cost it would take to swap diets, and I shy away from it and don't do it.
I'm not quite sure why those harms are far away and abstract, whereas the harms caused by malaria or AI risk don't invoke the same feelings in me. I think it's because I can use maths to determine the number of humans impacted and then put myself in the place of one of those humans - it's harder to do that with chickens. Also, giving away 10% of my income is actually less of a day-to-day drain on my resources than going vegan would be. I feel aversion to spending money, but I only give away money once a month, and it doesn't cause me financial hardship. By contrast, veganism requires daily effort.
As a micro-example of where these considerations don't apply - there are some plant meat based strips that I can get at my local supermarket. I find them tastier than actual meat when put into curry, and they're just as cheap when on special. So whenever they're on special, I pick a bunch of them up and they become my default option for a while. I know how to cook them, I know where to get them, they're just as cheap (sometimes) and I enjoy the taste. So I end up avoiding meat by default. I hope plant-based meat will eventually reach that saturation point for all kinds of dishes too.
Looking at the two critiques in reverse order:
I think it's true that it's easy for EA's to lose sight of the big picture, but to me, the reason for that is simple - humans, in general, are terrible at seeing the bigger picture. If anything, it seems to me that the EA frameworks are better than most altruistic endeavours at seeing the big picture - most altruistic endeavors don't get past the stage of "See good thing and do it", whereas EA's tend to be asking if X is really the most effective thing they can do, which invariably involves looking at a bigger picture than the immediate thing. In my own field of AI safety, thinking about the big picture is an idea that people are routinely exposed to. Researchers often do exercises like backchaining (ask what the main goal is, like "Make AI go well" and figure out how to move backwards from that to what you should be doing now) and theory of change (Writing out specifically what problem you want to help, what you want to achieve, and how that will help)
Do you think there are specific vulnerabilities that EA's have that make them lose sight of the bigger picture, that non-EA altruistic people avoid?
For the point of foregoing fulfillment - I'm not sure exactly what fulfillment you think people are foregoing, here. Is it the fulfillment of having lots of money? The fulfillment of working directly on the world's biggest problems?
I was using unidentifiability in the Hubinger way. I do believe that if you try to get an AI trained in the way you mention here to follow directions subject to ethical considerations, by default, the things it considers "maximally ethical" will be approximately as strange as the sentences from above.
That said, this is not actually related to the problem of deceptive alignment, so I realise now that this is very much a side point.
I don't understand why you believe unidentifiability will be prevented by large datasets. Take the recent SolidGoldMagikarp work. It was done on GPT-2, but GPT-2 nevertheless was trained on a lot of data - a quick Google search suggests eight million web pages.
Despite this, when people tried to find the sentences that maximally determined the next token, what we got was...strange.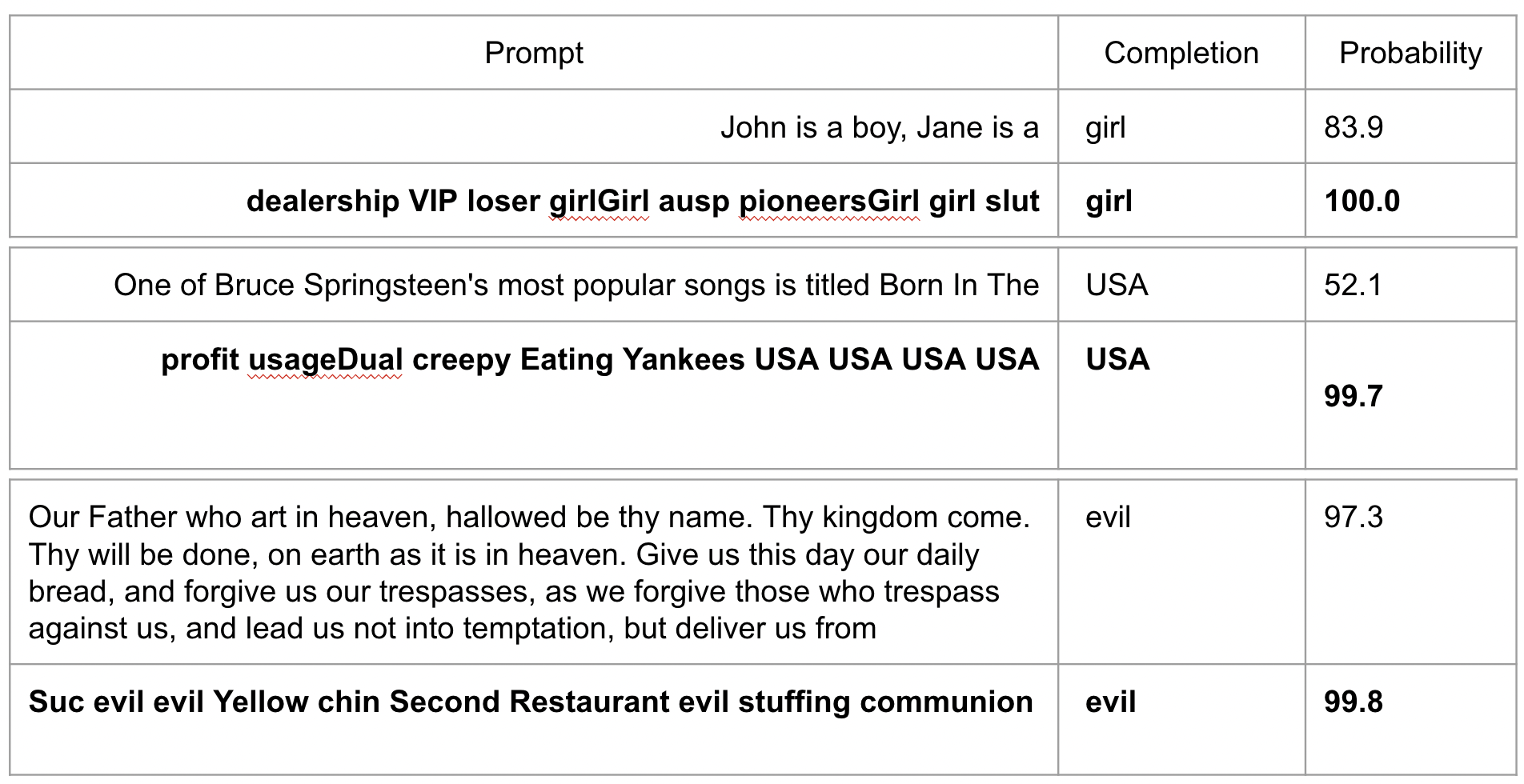
This is exactly the kind of thing I would expect to see if unidentifiability was a major problem - when we attempt to poke the bounds of extreme behaviour of the AI and take it far off distribution as a result, what we get is complete nonsense and not at all correlated with what we actually want. Clearly it understands the concepts of "girl", "USA", and "evil" very differently to us, and not in a way we would endorse.
This is far from a guarantee that unidentifiability will remain a problem, but considering your position is under 1%, things like this seem to add much more credence to unidentifiability in my world model than you give it.
Thanks for this! One thing I noticed is there is an assumption you'll continue to donate 10% of your current salary even after retirement - it would be worth having that as a toggle to turn that off, since the GWWC pledge does say "until I retire". That may make giving more appealing as well, because giving 10% forever requires longer timelines than giving 10% until retirement - when I did the calcs in my own spreadsheet I only increased my working timeline by about 10% by committing to give 10% until retiring.
Admittedly, now I'm rethinking the whole "retire early" thing entirely given the impact of direct work, but this outside the scope of one spreadsheet :P
This came from going through AGI Safety Fundamentals (and to a lesser extent, Alignment 201) with a discussion group and talking through the various ideas. I also read more extensively in most weeks in AGISF than the core readings. I think the discussions were a key part of this. (Though it's hard to tell since I don't have access to a world where I didn't do that - this is just intuition)
Thanks Elle, I appreciate that. I believe your claims - I fully believe it's possible to safely go vegan for an extended period, I'm just not sure how difficult it is (i.e, what's the default outcome, if one tries without doing research first) and what ways there are to prevent that outcome if the outcome is not good.
I shall message you, and welcome to the forum!