Harrison Durland
Posts 18
Comments441
Topic contributions10
I was not a huge fan of the instrumental convergence paper, although I didn't have time to thoroughly review it. In short, it felt too slow in making its reasoning and conclusion clear, and once (I think?) I understood what it was saying, it felt quite nitpicky (or a borderline motte-and-bailey). In reality, I'm still unclear if/how it responds to the real-world applications of the reasoning (e.g., explaining why a system with a seemingly simple goal like calculating digits of pi would want to cause the extinction of humanity).
The summary in this forum post seems to help, but I really feel like the caveats identified in this post ("this paper simply argues that this would not be true of agents with randomly-initialized goals") is not made clear in the abstract.[1]
- ^
The abstract mentions "I find that, even if intrinsic desires are randomly selected [...]" but this does not at all read like a caveat, especially due to the use of "even if" (rather than just "if").
Sorry about the delayed reply, I saw this and accidentally removed the notification (and I guess didn't receive an email notification, contrary to my expectations) but forgot to reply. Responding to some of your points/questions:
One can note that AIXR is definitely falsifiable, the hard part is falsifying it and staying alive.
I mostly agree with the sentiment that "if someone predicts AIXR and is right then they may not be alive", although I do now think it's entirely plausible that we could survive long enough during a hypothetical AI takeover to say "ah yeah, we're almost certainly headed for extinction"—it's just too late to do anything about it. The problem is how to define "falsify": if you can't 100% prove anything, you can't 100% falsify anything; can the last person alive say with 100% confidence "yep, we're about to go extinct?" No, but I think most people would say that this outcome basically "falsifies" the claim "there is no AIXR," even prior to the final person being killed.
Knightian uncertainty makes more sense in some restricted scenarios especially related to self-confirming/self-denying predictions.
This is interesting; I had not previously considered the interaction between self-affecting predictions and (Knightian) "uncertainty." I'll have to think more about this, but as you say I do still think Knightian uncertainty (as I was taught it) does not make much sense.
This can apply as well to different people: If I believe that X has a very good reasoning process based on observations on Xs past reasoning, I might not want to/have to follow Xs entire train of thought before raising my probability of their conclusion.
Yes, this is the point I'm trying to get at with forecast legibility, although I'm a bit confused about how it builds on the previous sentence.
Some people have talked about probability distributions on probability distributions, in the case of a binary forecast that would be a function , which is…weird. Do I need to tack on the resilience to the distribution? Do I compute it out of the probability distribution on probability distributions? Perhaps the people talking about imprecise probabilities/infrabayesianism are onto something when they talk about convex sets of probability distributions as the correct objects instead of probability distributions per se.
Unfortunately I'm not sure I understand this paragraph (including the mathematical portion). Thus, I'm not sure how to explain my view of resilience better than what I've already written and the summary illustration: someone who says "my best estimate is currently 50%, but within 30 minutes I think there is a 50% chance that my best estimate will become 75% and a 50% chance that my best estimate becomes 25%" has a less-resilient belief compared to someone who says "my best estimate is currently 50%, and I do not think that will change within 30 minutes." I don't know how to calculate/quantify the level of resilience between the two, but we can obviously see there is a difference.
Epistemic status: I feel fairly confident about this but recognize I’m not putting in much effort to defend it and it can be easily misinterpreted.
I would probably just recommend not using the concept of neglectedness in this case, to be honest. The ITN framework is a nice heuristic (e.g., usually more neglected things benefit more from additional marginal contributions) but it is ultimately not very rigorous/logical except when contorted into a definitional equation (as many previous posts have explained). Importantly, in this case I think that focusing on neglectedness is likely to lead people astray, given that a change in neglectedness could equate to an increase in tractability.
Interesting. Perhaps we have quite different interpretations of what AGI would be able to do with some set of compute/cost and time limitations. I haven't had the chance yet to read the relevant aspects of your paper (I will try to do so over the weekend), but I suspect that we have very cruxy disagreements about the ability of a high-cost AGI—and perhaps even pre-general AI that can still aid R&D—to help overcome barriers in robotics, semiconductor design, and possibly even aspects of AI algorithm design.
Just to clarify, does your S-curve almost entirely rely on base rates of previous trends in technological development, or do you have a component in your model that says "there's some X% chance that conditional on the aforementioned progress (60% * 40%) we get intermediate/general AI that causes the chance of sufficiently rapid progress in everything else to be Y%, because AI could actually assist in the R&D and thus could have far greater returns to progress than most other technologies"?
I find this strange/curious. Is your preference more a matter of “Traditional interfaces have good features that a flowing interface would lack“ (or some other disadvantage to switching) or “The benefits of switching to a flowing interface would be relatively minor”?
For example on the latter, do you not find it more difficult with the traditional UI to identify dropped arguments? Or suppose you are fairly knowledgeable about most of the topics but there’s just one specific branch of arguments you want to follow: do you find it easy to do that? (And more on the less-obvious side, do you think the current structure disincentivizes authors from deeply expanding on branches?)
On the former, I do think that there are benefits to having less-structured text (e.g., introductions/summaries and conclusions) and that most argument mapping is way too formal/rigid with its structure, but I think these issues could be addressed in the format I have in mind.
Thanks for posting this, Ted, it’s definitely made me think more about the potential barriers and the proper way to combine probability estimates.
One thing I was hoping you could clarify: In some of your comments and estimates, it seems like you are suggesting that it’s decently plausible(?)[1] we will “have AGI“ by 2043, it’s just that it won’t lead to transformative AGI before 2043 because the progress in robotics, semiconductors, and energy scaling will be too slow by 2043. However, it seems to me that once we have (expensive/physically-limited) AGI, this should be able to significantly help with the other things, at least over the span of 10 years. So my main question is: Does your model attach significantly higher probabilities to transformative AGI by 2053? Is it just that 2043 is right near the base of a rise in the cumulative probability curve?
- ^
I wasn’t clear if this is just 60%, or 60%*40%, or what. If you could clarify this, that would be helpful!
Are your referring to this format on LessWrong? If so I can’t say I’m particularly impressed, as it still seems to suffer from the problems of linear dialogue vs. a branching structure (e.g., it is hard to see where points have been dropped, it is harder to trace specific lines of argument). But I don’t recall seeing this, so thanks for the flag.
As for “I don’t think we could have predicted people…”, that’s missing my point(s). I’m partially saying “this comment thread seems like it should be a lesson/example of how text-blob comment-threads are inefficient in general.” However, even in this specific case Paul knew that he was laying out a multi-pronged criticism, and if the flow format existed he could have presented his claims that way, to make following the debate easier—assuming Ted would reply.
Ultimately, it just seems to me like it would be really logical to have a horizontal flow UI,[1] although I recognize I am a bit biased by my familiarity with such note taking methods from competitive debate.
- ^
In theory it need not be as strictly horizontal as I lay out; it could be a series of vertically nested claims, kept largely within one column—where the idea is that instead of replying to the entire comment you can just reply to specific blocks in the original comment (e.g., accessible in a drop down at the end of a specific argument block rather than the end of the entire comment).
Am I really the only person who thinks it's a bit crazy that we use this blobby comment thread as if it's the best way we have to organize disagreement/argumentation for audiences? I feel like we could almost certainly improve by using, e.g., a horizontal flow as is relatively standard in debate.[1]
With a generic example below:
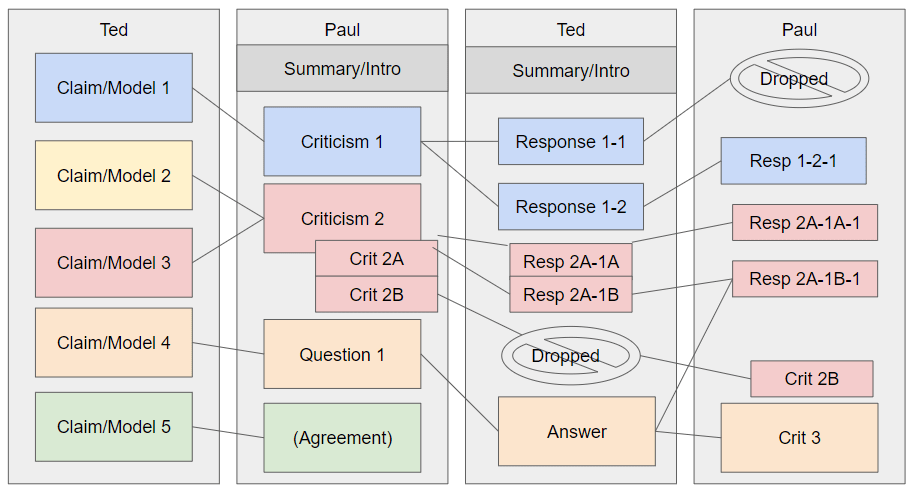
To be clear, the commentary could still incorporate non-block/prose text.
Alternatively, people could use something like Kialo.com. But surely there has to be something better than this comment thread, in terms of 1) ease of determining where points go unrefuted, 2) ease of quickly tracing all responses in specific branches (rather than having to skim through the entire blob to find any related responses), and 3) seeing claims side-by-side, rather than having to scroll back and forth to see the full text. (Quoting definitely helps with this, though!)
- ^
(Depending on the format: this is definitely standard in many policy debate leagues.)
I’m curious whether people (e.g., David, MIRI folk) think that LLMs now or in the near future would be able to substantially speed up this kind of theoretical safety work?