Aleksi Maunu
Comments38
I think the stated reasoning there by OP is that it's important to influence OpenAI's leadership's stance and OpenAI's work on AI existential safety. Do you think this is unreasonable?
To be fair I do think it makes a lot of sense to invoke nepotism here. I would be highly suspicious of the grant if I didn't happen to place a lot of trust in Holden Karnofsky and OP.
(feel free to not respond, I'm just curious)
I think if I was issuing grants, I would use misleading language in such a letter to make it less likely that the grantee organization can't get registered for some bureaucracy reasons. It's possible to mention that to the grantee in an email or call too to not cause any confusion. My guess would be that that's what happened here but that's just my 2 cents. I have no relevant expertise.
Thanks for the comment! I feel funny saying this without being the author, but feel like the rest of my comment is a bit cold in tone, so thought it's appropriate to add this :)
I lean more moral anti-realist but I struggle to see how the concept of "value alignment" and "decision-making quality" are not similarly orthogonal from a moral realist view than an anti-realist view.
Moral realist frame: "The more the institution is intending to do things according to the 'true moral view', the more it's value-aligned."
"The better the institutions's decision making process is at predictably leading to what they value, the better their 'decision-making quality' is."
I don't see why these couldn't be orthogonal in at least some cases. For example, a terrorist organization could be outstandingly good at producing outstandingly bad outcomes.
Still, it's true that the "value-aligned" term might not be the best, since some people seem to interpret it as a dog-whistle for "not following EA dogma enough" [link] (I don't, although might be mistaken). "Altruism" and "Effectiveness"as the x and y axes would suffer from the problem mentioned in the post that it could alienate people coming to work on IIDM from outside the EA community. For the y-axis, ideally I'd like some terms that make it easy to differentiate between beliefs common in EA that are uncontroversial ("let's value people's lives the same regardless of where they live"), and beliefs that are more controversial ("x-risk is the key moral priority of our times").
About the problematicness of " value-neutral": I thought the post gave enough space for the belief that institutions might be worse than neutral on average, marking statements implying the opposite as uncertain. For example crux (a) exists in this image to point out that if you disagree with it, you would come to a different conclusion about the effectiveness of (A).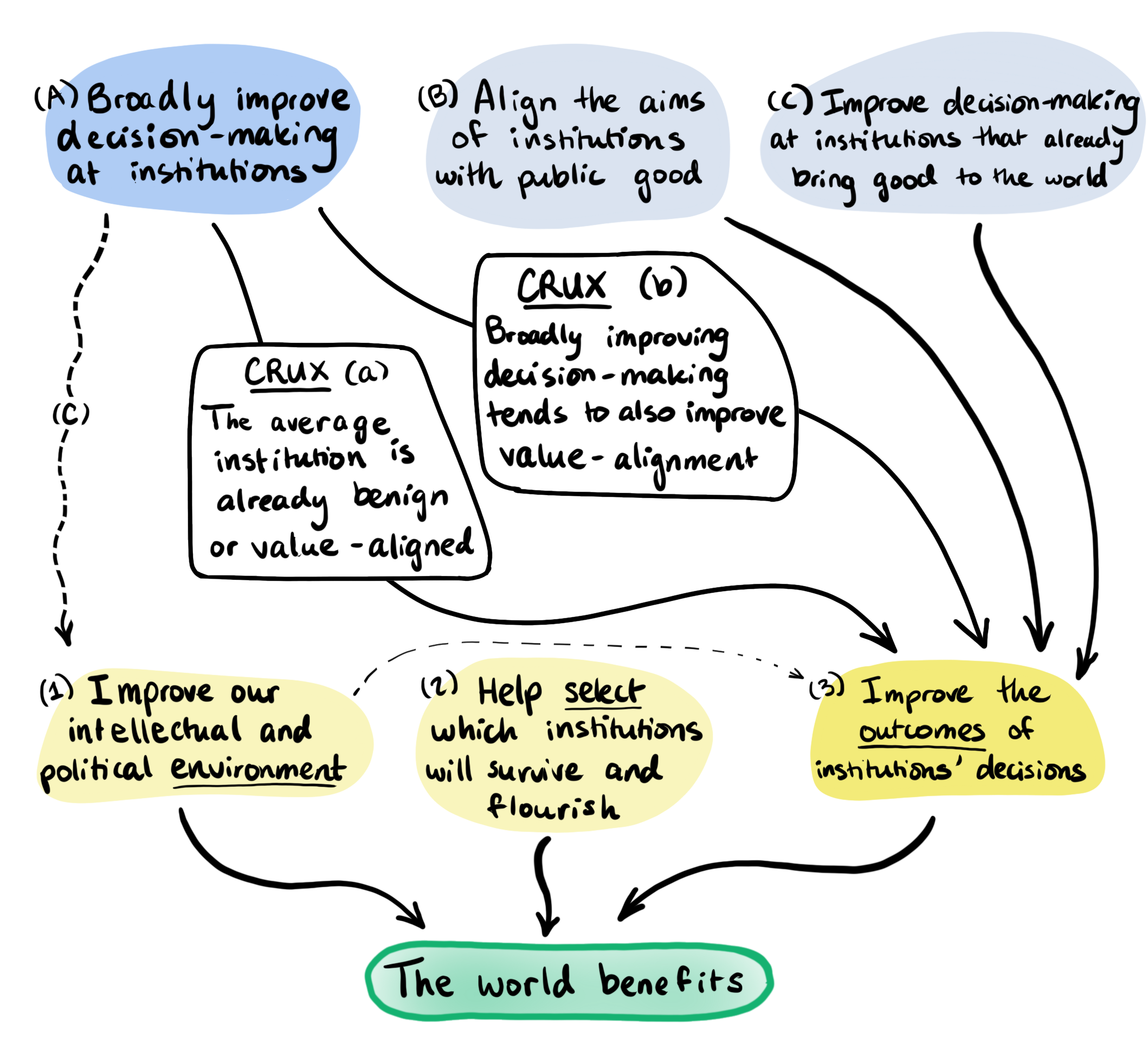
(I'm testing out writing more comments on the EA forum, feel free to say if it was helpful or not! I want to learn to spend less time on these. This took about 30 minutes.)
Does anyone have thoughts on
-
How does the FTX situation affect the EV of running such a survey? My first intuition is that running one while the situation's so fresh is worse than waiting a 3-6 months, but I can't properly articulate why.
-
What, if any, are some questions that should be added, changed, or removed given the FTX situation?
(After writing this I thought of one example where the goals are in conflict: permanent surveillance that stops the development of advanced AI systems. Thought I'd still post this in case others have similar thoughts. Would also be interested in hearing other examples.)
I'm assuming a reasonable interpretation of the proxy goal of safety means roughly this: "be reasonably sure that we can prevent AI systems we expect to be built from causing harm". Is this a good interpretation? If so, when is this proxy goal in conflict with the goal of having "things go great in the long run"?
I agree that it's epistemically good for people to not confuse proxy goals with goals, but in practice I have trouble thinking of situations where these two are in conflict. If we've ever succeeded in the first goal, it seems like making progress in the second goal should be much easier, and at that point it would make more sense to advocate using-AI-to-bring-a-good-future-ism.
Focusing on the proxy goal of AI safety seems also good for the reason that it makes sense across many moral views, while people are going to have different thoughts on what it means for things to "go great in the long run". Fleshing out those disagreements is important, but I would think there's time to do that when we're in a period of lower existential risk.
Anyone else not able to join the group through the link? 🤔 It just redirects me to the dashboard without adding me in